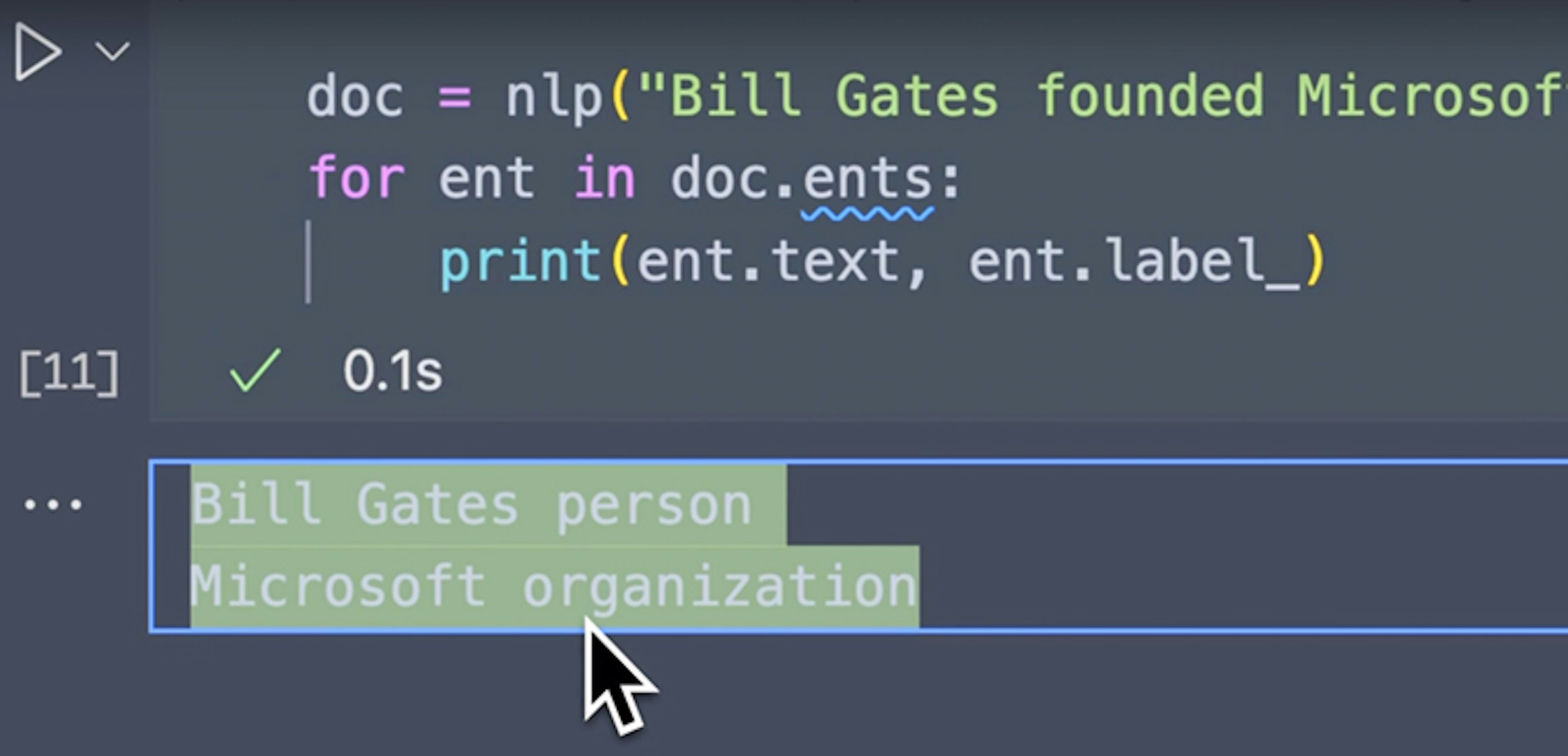
Zero-Shot NER with GliNER and spaCy Python Tutorials for Digital HumanitiesTutorial by WJB Mattingly on how to integrate the generalist GLiNER model for Named Entity Recognition with spaCy's versatile NLP environment.
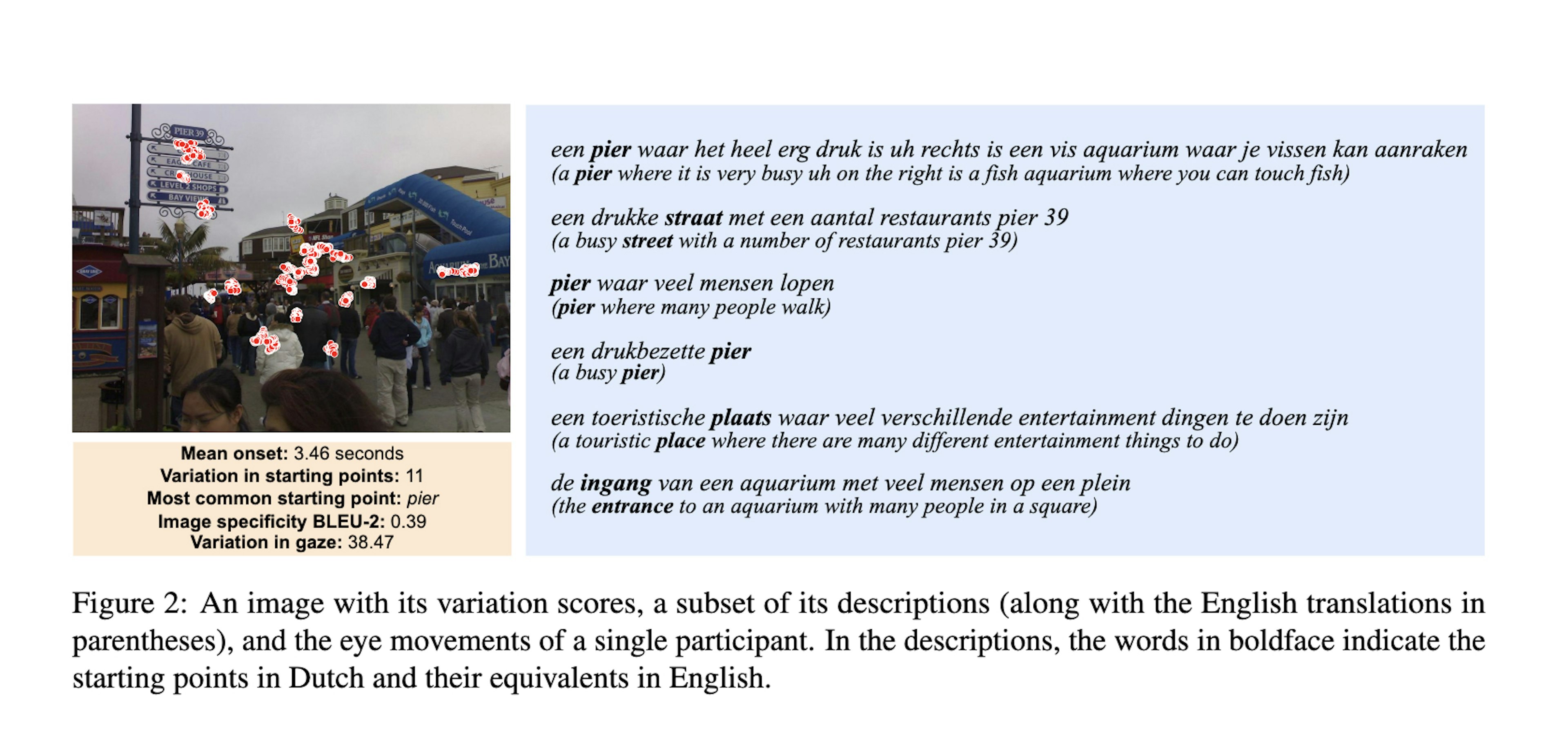
Describing Images Fast and Slow: Quantifying and Predicting the Variation in Human Signals during Visuo-Linguistic ProcessesTakmaz, Pezzelle, Fernández (2024)We use the spaCy library for tokenization, part-of-speech tagging, and lemmatization of the words in the descriptions.
Herding LLMs Towards Structured NLPGlobal AI ConferenceThis talk shows how we integrate LLMs into spaCy, leveraging its modular and customizable framework. This allows for cheaper, faster and more robust NLP - driven by cutting-edge LLMs, without compromising on having structured, validated data.
Launching the Explosion Merch StoreSpread the love and support us and our open-source work with some of our unique, custom-designed swag. All orders come with free shipping and stickers!
GERNERMED++: Semantic annotation in German medical NLP through transfer-learning, translation and word alignmentFrei, Frei-Stuber, Kramer (2023), Journal of Biomedical InformaticsThe training of our entity recognition model employs the entity recognition parser from the spaCy library which follows a transducer-based parsing approach with a BILOU scheme instead of a state-agnostic token tagging approach.
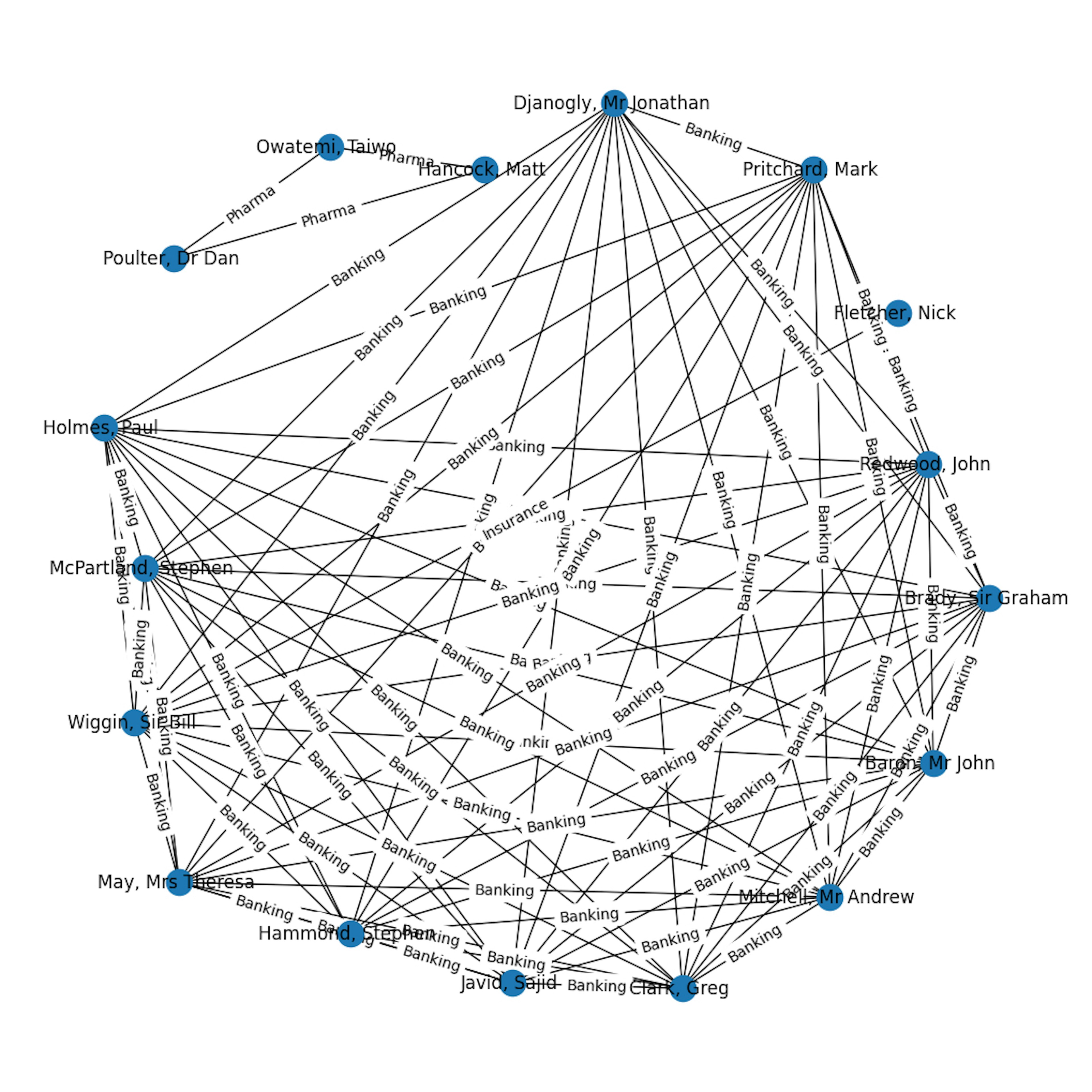
MP Interests Tracker: Utilising GenAI to uncover insights in the UK Register of Financial InterestJournalismAI BlogProject from teams at The Times and BBC using spacy-llm to make complex financial interests data more accessible.
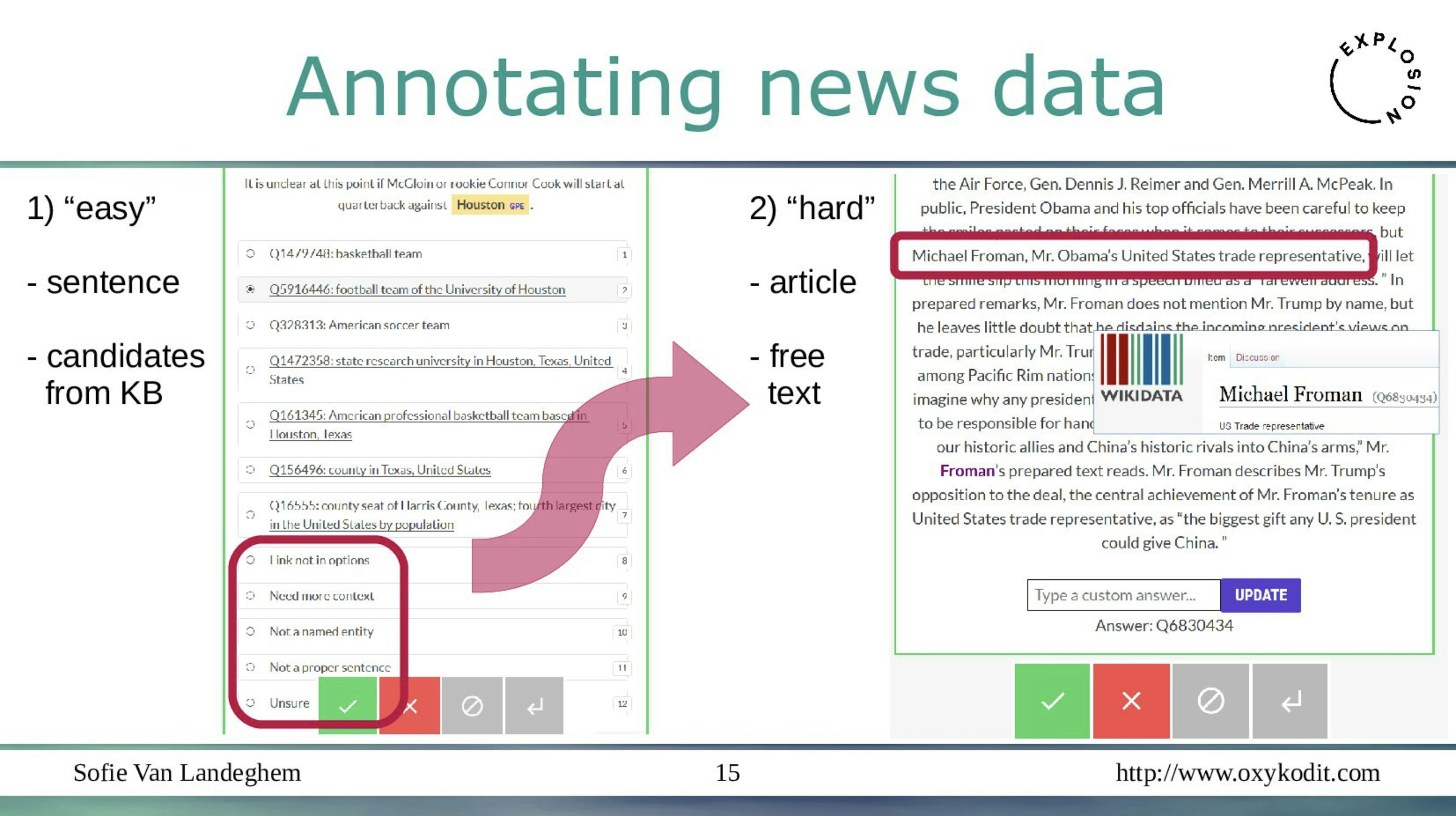
How Good is the Model in Model-in-the-loop Event Coreference Resolution Annotation?Ahmed, Nath, Regan, Pollins, Krishnaswamy, Martin (2023)Figure 6 illustrates the interface design of the annotation methodology on the popular model-in-the-loop annotation tool - Prodigy. We use this tool for the simplicity it offers in plugging in the various ranking methods we explained.
Newsletter May 2023We got so much amazing feedback from the spaCy user survey, thank you all for your contributions! The most requested feature was spaCy integration with LLMs, which is why we’re so excited to announce spacy-llm!
You are what you read: Building a personal internet front-page with spaCy and ProdigyPyCon DE & PyData Berlin
The Tale of Bloom Embeddings and Unseen EntitiesThe default Bloom embedding layer in spaCy is unconventional, but very powerful and efficient. We wrote about it before and showed the advantages it provides in terms of memory efficiency for our floret embeddings. Now we have released the first technical report by Explosion, where we explain Bloom embeddings in more detail and rigorously compare them to traditional embeddings. In this post we'll highlight some of our results with a special focus on unseen entities.
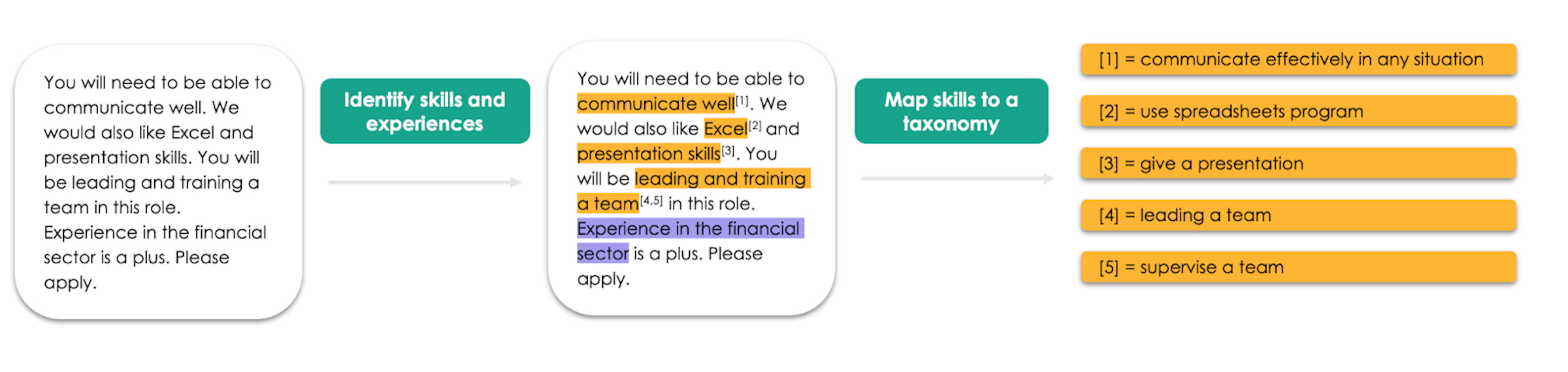
The Nesta Skills Extractor LibraryEconomic Statistics Centre of ExcellenceA new library for extracting skills from job adverts and mapping them to a taxonomy of your choice, built on top of spaCy.
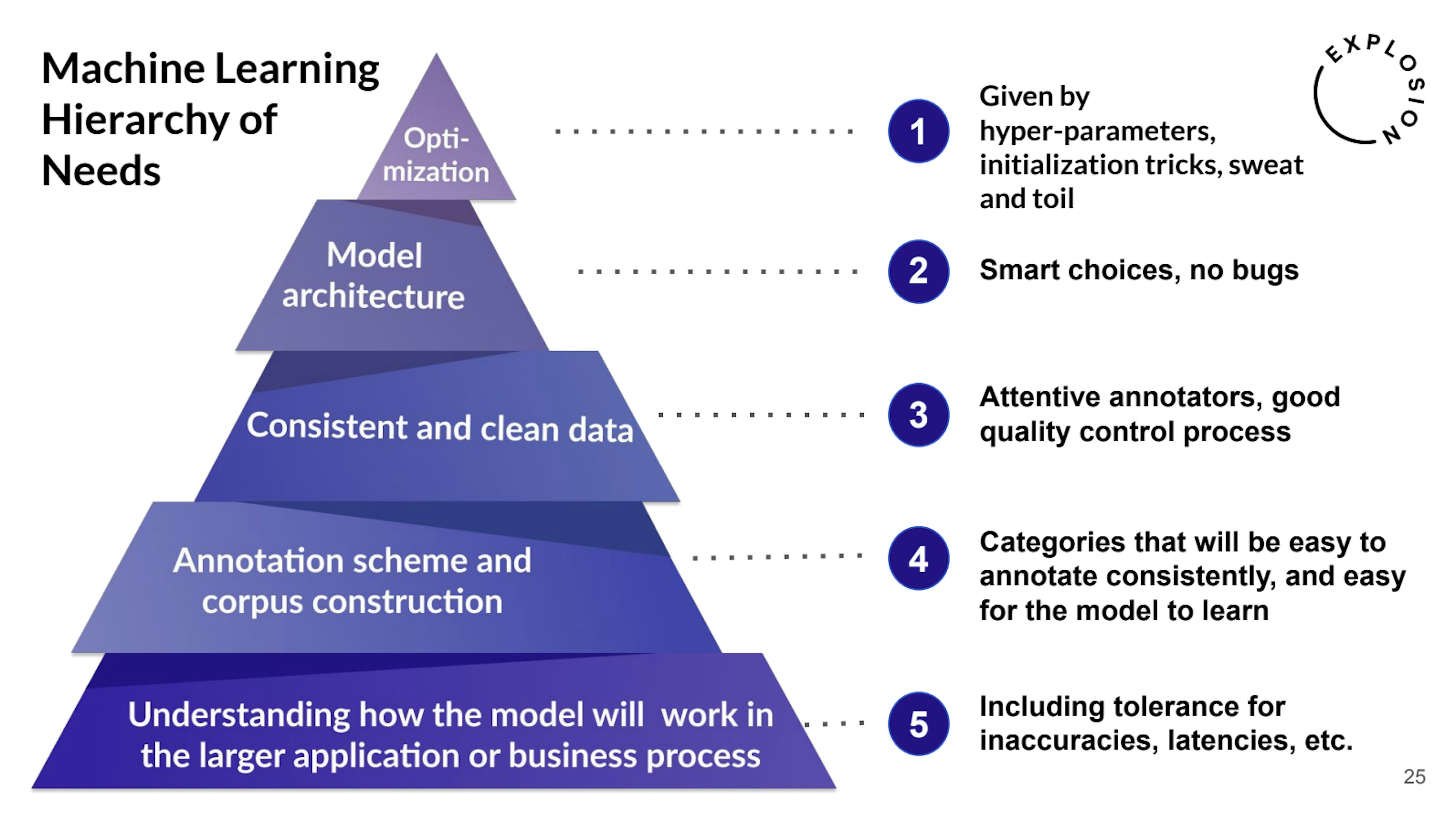
Setting your ML project up for success“What can you do to maximize probability of success for your Machine Learning solution? Throughout my 15 years as data scientist in academia, big pharma and through consulting, one common theme has emerged: the most reliable predictor of success for any NLP or ML-based solution is whether or not you involve the data science team early on.”
Coreference Resolution in spaCyIn everyday conversation, we use pronouns or other expressions to refer to entities in many different ways, but we effortlessly understand these references. In NLP this is a challenging problem known as Coreference Resolution. In this video, we’ll show how to train spaCy’s new component for Coreference Resolution and how to apply the pipeline to resolve references in a text.
End-to-end Neural Coreference Resolution in spaCyCoreference resolution is the problem of resolving entities in texts to references such as pronouns. Even if you've never heard of it, it's something we all do constantly every day, and is a key to understanding natural language. We recently added an experimental implementation of an end-to-end neural coreference component to spaCy. This post explains the architecture of our model in detail.
Introducing spaCy v3.4spaCy v3.4 brings typing and speed improvements along with new vectors for English CNN pipelines and new trained pipelines for Croatian.
Introducing spaCy v3.3spaCy v3.3 improves the speed of core pipeline components, adds a new trainable lemmatizer, and introduces trained pipelines for Finnish, Korean and Swedish.
Introducing spaCy Tailored PipelinesExplosion is pleased to announce a new development services offering, spaCy Tailored Pipelines. We’ll build you a custom natural language processing pipeline, delivered in a standardized format using spaCy’s projects system.
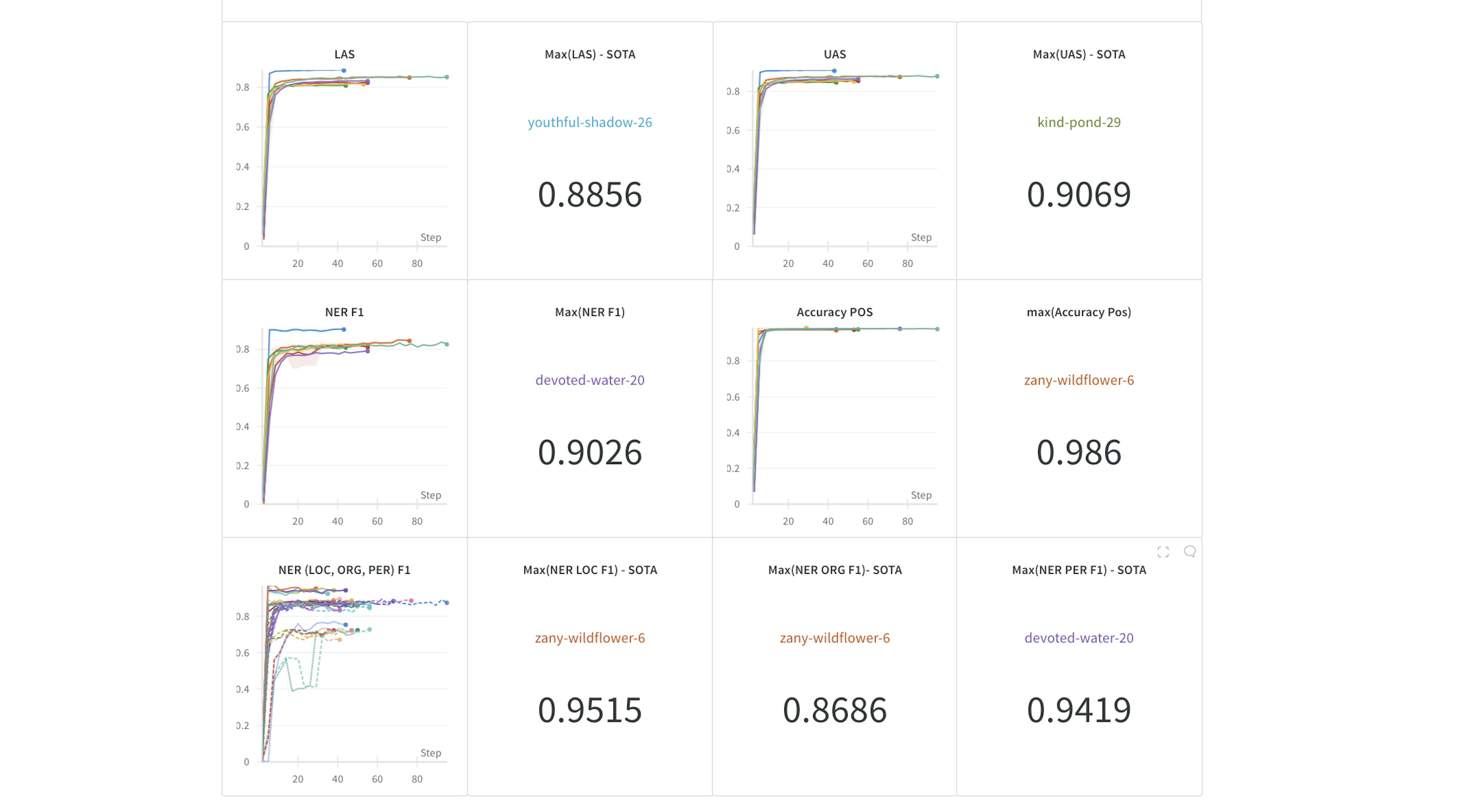
Universal Dependencies v2.5 Benchmarks for spaCyWe present Universal Dependencies v2.5 benchmarks for spaCy v3.2 that show the competitive performance of spaCy in a direct comparison with Stanza and Trankit using the end-to-end evaluation from the CoNLL 2018 Shared Task.
Introducing spaCy v3.2spaCy v3.2 features usability improvements for custom training and scoring, improved performance and support for floret, our new fastText word vectors algorithm.
Introducing spaCy v2.3spaCy now speaks Chinese, Japanese, Danish, Polish and Romanian! Version 2.3 of the spaCy Natural Language Processing library adds models for five new languages. We've also updated all 15 model families with word vectors and improved accuracy, while also decreasing model size and loading times for models with vectors.
Using spaCy with Hugging Face TransformersPyCon IndiaTransformer models like BERT have set a new standard for accuracy on almost every NLP leaderboard. However, these models are very new, and most of the software ecosystem surrounding them is oriented towards the many opportunities for further research. In this talk, Matt describes how you can now use these models in spaCy to work on real problems and the many opportunities transfer learningfor production NLP, regardless of which software packages you choose.
Introducing spaCy v2.1Version 2.1 of the spaCy Natural Language Processing library includes a huge number of features, improvements and bug fixes. In this post, we highlight some of the things we're especially pleased with, and explain some of the most challenging parts of preparing this big release.
What 1.2 million parliamentary speeches can teach us about gender representationThe PuddingAnalysis of parliamentary speeches using spaCy.
Training a new entity type with Prodigy – annotation powered by active learningIn this video, we’ll show you how to use Prodigy to train a phrase recognition system for a new concept. Specifically, we’ll train a model to detect references to drugs, using text from Reddit.
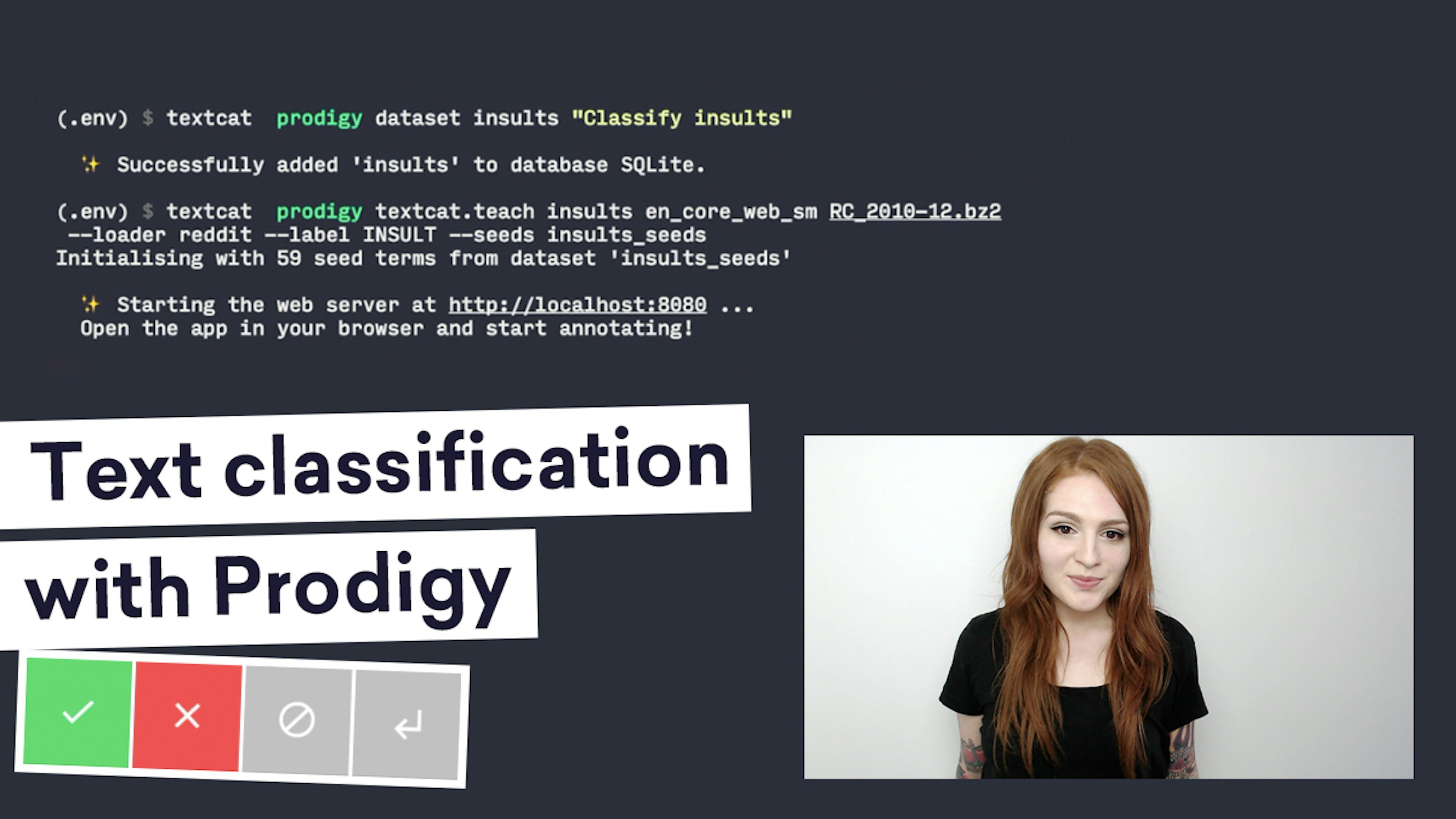
Training an insults classifier with Prodigy in ~1 hourIn this video, we’ll show you how to use Prodigy to train a classifier to detect disparaging or insulting comments. Prodigy makes text classification particularly powerful, because you can try out new ideas very quickly.
Multi-threading spaCy's parser and named entity recognizerIn v0.100.3, we quietly rolled out support for GIL-free multi-threading for spaCy's syntactic dependency parsing and named entity recognition models. Because these models take up a lot of memory, we've wanted to release the global interpretter lock (GIL) around them for a long time. When we finally did, it seemed a little too good to be true, so we delayed celebration — and then quickly moved on to other things. It's now past time for a write-up.
Introducing spaCyComputers don't understand text. This is unfortunate, because that's what the web almost entirely consists of. We want to recommend people text based on other text they liked. We want to shorten text to display it on a mobile screen. We want to aggregate it, link it, filter it, categorise it, generate it and correct it. spaCy provides a library of utility functions that help programmers build such products.
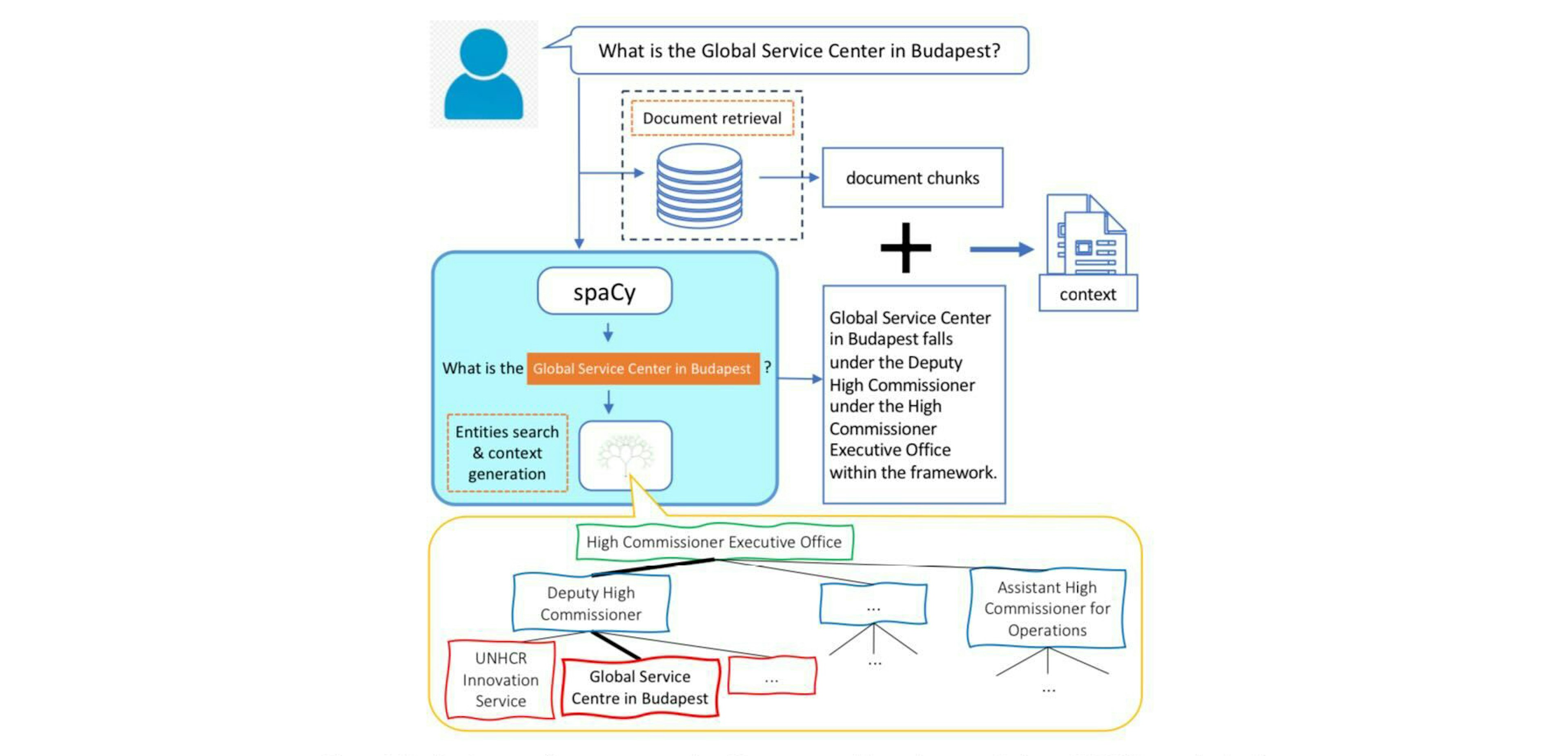
Constructing a knowledge base with spaCy and spacy-llmMantisNLP BlogThis blog post shows how to use spaCy and LLMs to extract entities and relationships from text and quickly tackle the complex problem of constructing a knowledge base graph from a corpus.
KAZU v1.5A biomedical NLP framework designed to handle production workloads, built by AstraZeneca and Korea University and using spaCy under the hood.
On the Creation of Classifiers to Support Assessment of E-PortfoliosGantikow, Isking, Libbrecht, Müller, Rebholz (2023)In this workflow, Prodigy selects and presents text examples that were classified with a very low degree of certainty. The annotator reviews the proposed classifications and corrects them, if necessary.
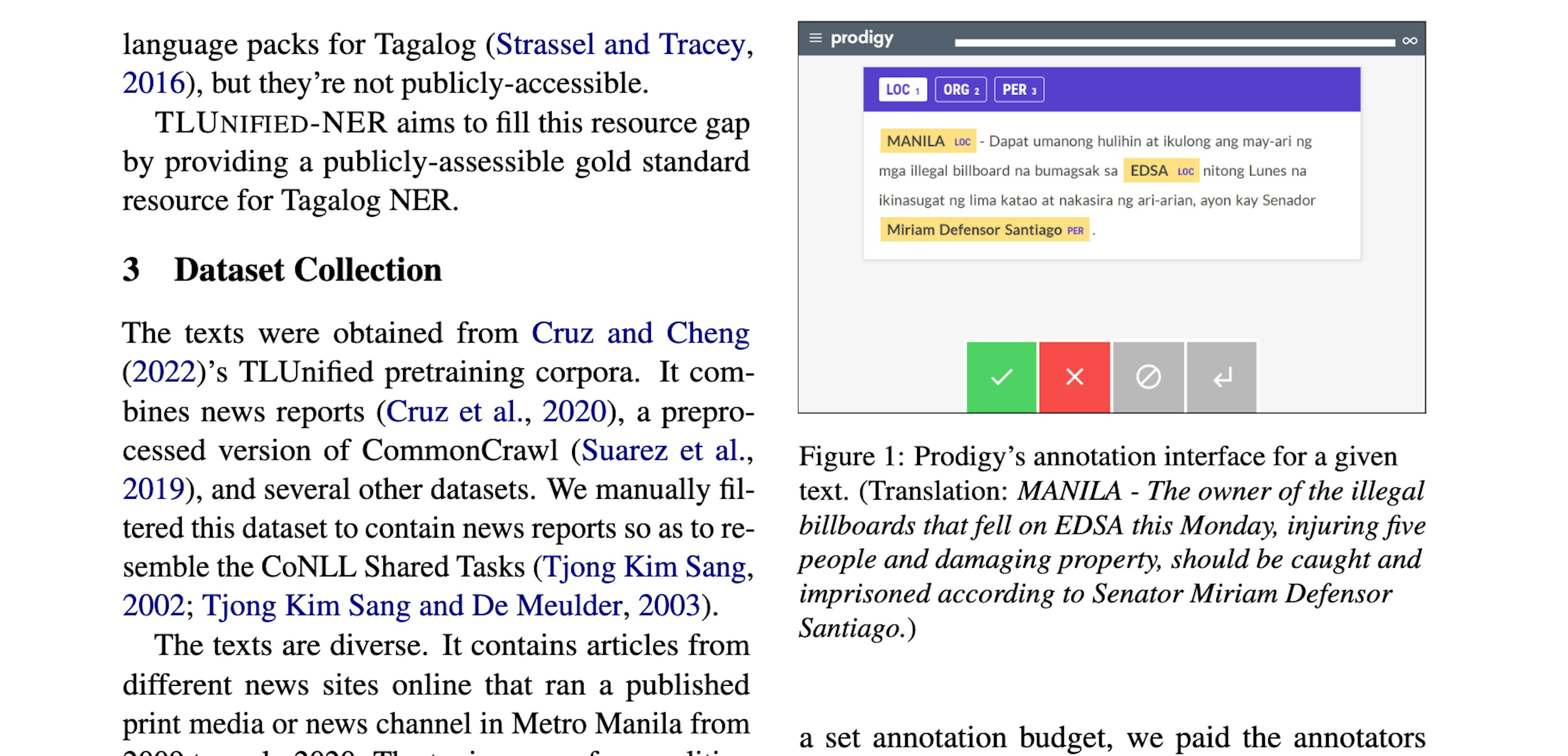
calamanCy: A Tagalog Natural Language Processing ToolkitMiranda (2023), EMNLP 2023We introduce calamanCy, an open-source toolkit for constructing NLP pipelines for Tagalog. It is built on top of spaCy, enabling easy experimentation and integration with other frameworks.
🦙 spacy-llm v0.5.0Sep 8, 2023Improved user API and novel Chain-of-Thought prompting for more accurate NER
Large Language Models: From Prototype to ProductionEuroPython KeynoteLarge Language Models (LLMs) have shown some impressive capabilities and their impact is the topic of the moment. In this talk, Ines presents visions for NLP in the age of LLMs and a pragmatic, practical approach for how to use Large Language Models to ship more successful NLP projects from prototype to production today.
Efficient Information Extraction From Text With spaCyJetBrains PyCharmThis webinar takes you through building a spaCy project that uses a named entity recognition (NER) model to extract entities of interest from restaurant reviews, like prices, opening hours and ratings.
Creating Custom Event Data Without Dictionaries: A Bag-of-TricksHalterman, Schrodt, Beger, Bagozzi, Scarborough (2023)While in the past the process of generating training case has been quite time consuming and tedious, newer approaches such as those incorporated into the web-based Prodigy annotation system allow this to be done much more quickly.
Towards a Tagalog NLP pipelineIn this blog post, Lj talks about how he built an NER pipeline for Tagalog, the gold-standard dataset, benchmarking results, and his hopes for the future of Tagalog NLP.
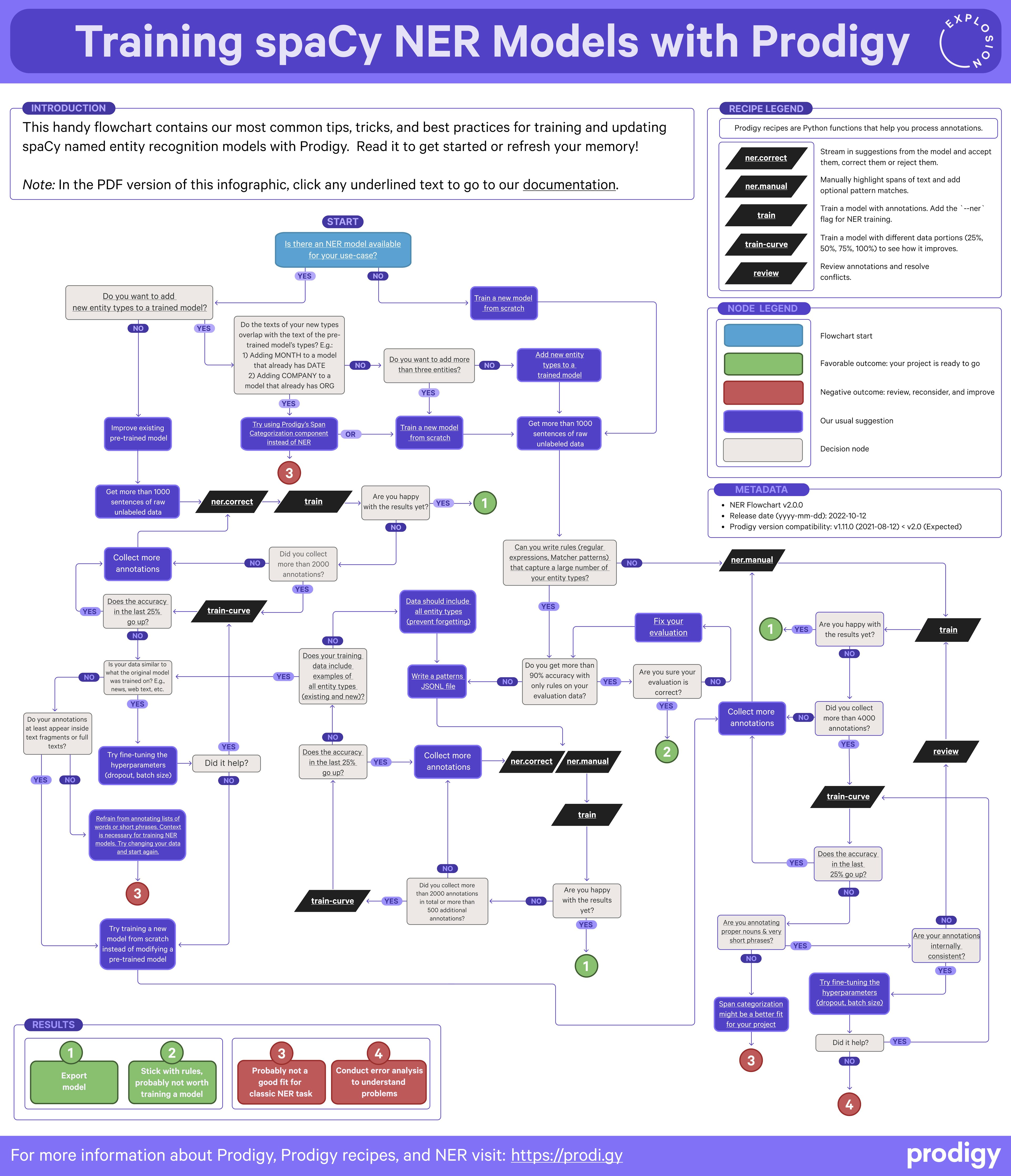
Training spaCy NER Models with ProdigyThis handy flowchart contains our most common tips, tricks, and best practices for training and updating spaCy named entity recognition models with Prodigy.
Multi hash embeddings in spaCyMiranda, Kádár, Boyd, Van Landeghem, Søgaard, Honnibal (2022)In this technical report we lay out a bit of history and introduce the embedding methods in spaCy in detail. Second, we critically evaluate the hash embedding architecture with multi-embeddings on Named Entity Recognition datasets from a variety of domains and languages. The experiments validate most key design choices behind spaCy’s embedders, but we also uncover a few surprising results.
spaCy behind the scenes: library patterns & design concepts explainedDeveloper productivity has been central to our design of spaCy, both in smaller decisions and some of the bigger architectural questions. We believe in embracing the complexities of machine learning, not hiding it away under leaky abstractions, while also maintaining the developer experience. Read on to learn some of the design patterns within the library, how we've implemented them, and most importantly, why.
Introducing Span Categorization in Prodigy and spaCyIn this video, we’ll show you how to use Prodigy for spaCy’s Span Categorizer. We’ll be annotating food recipes and looking into ways to help with consistent annotations and speed up the process with patterns and temporary models.
Compact word vectors with Bloom embeddingsAn introduction to the compact word vectors with Bloom embeddings used in Thinc, spaCy and floret.
When Women Make HeadlinesThe PuddingUsing spaCy and other packages from the NLP ecosystem for analyzing more than 382,000 headlines to see how women are represented (or misrepresented) in the news.
Neural edit-tree lemmatization for spaCyWe are happy to introduce a new, experimental, machine learning-based lemmatizer that posts accuracies above 95% for many languages. This lemmatizer learns to predict lemmatization rules from a corpus of examples and removes the need to write an exhaustive set of per-language lemmatization rules.
Reproducible spaCy NLP Experiments with Weights & BiasesWeights & Biases BlogThis tutorial will show how to add Weights & Biases to any spaCy NLP project to track your experiments, save model checkpoints, and version your datasets.
How We Found Pricey Provisions in New Jersey Police ContractsProPublicaProPublica and the Asbury Park Press scoured hundreds of police union agreements for details on publicly funded payouts to cops, using spaCy under the hood.
Introducing spaCy v3.0spaCy v3.0 is a huge release! It features new transformer-based pipelines that get spaCy's accuracy right up to the current state-of-the-art, and a new workflow system to help you take projects from prototype to production. It's much easier to configure and train your pipeline, and there are lots of new and improved integrations with the rest of the NLP ecosystem.
Explosion in 2019: Our Year in ReviewAs 2019 draws to a close and we step into the 2020s, we thought we’d take a look back at the year and all we’ve accomplished. And we realized we had so much that we could give you a month-by-month rundown of everything that happened.
spaCy meets Transformers: Fine-tune BERT, XLNet and GPT-2Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. You can now use these models in spaCy, via a new interface library we've developed that connects spaCy to Hugging Face's awesome implementations.
spaCy IRL 2019: 2 days of NLP in BerlinWe were pleased to invite the spaCy community and other folks working on Natural Language Processing to Berlin this summer for a small and intimate event.
FAQ #1: Tips & tricks for NLP, annotation & training with Prodigy and spaCyIn this video, Ines talks about a few frequently asked questions and shares some general tips and tricks for how to structure your NLP annotation projects, how to design your label schemes and how to solve common problems.
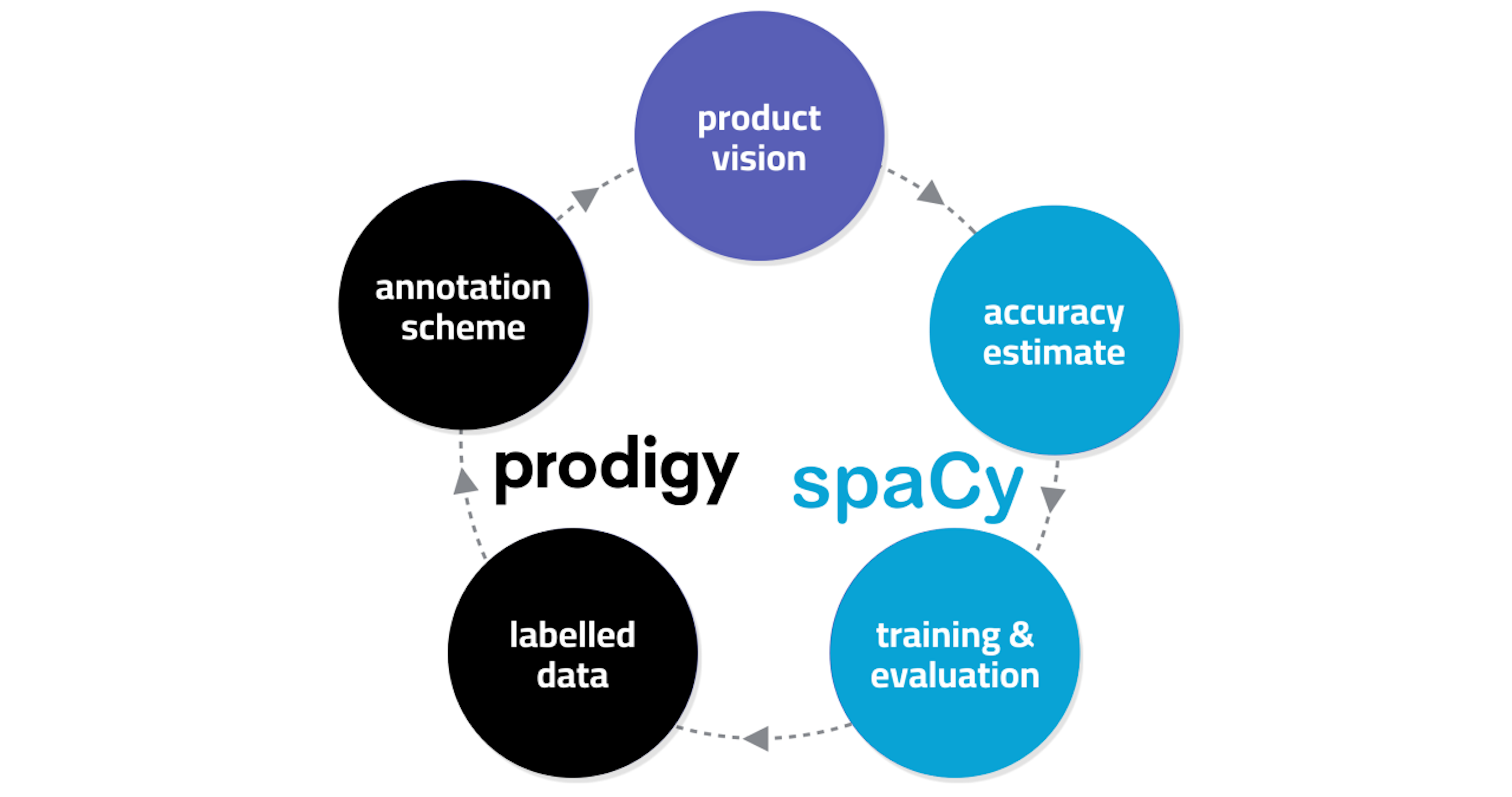
Building new NLP solutions with spaCy and ProdigyPyData Berlin“Commercial machine learning projects are currently like start-ups: many projects fail, but some are extremely successful, justifying the total investment. While some people will tell you to embrace failure, I say failure sucks — so what can we do to fight it? In this talk, I will discuss how to address some of the most likely causes of failure for new NLP projects.”
More than a Million Pro-Repeal Net Neutrality Comments were Likely FakedHackernoonAnalysis of net neutrality comments by Jeff Kao using spaCy for word vectors.
Pseudo-rehearsal: A simple solution to catastrophic forgetting for NLPSometimes you want to fine-tune a pre-trained model to add a new label or correct some specific errors. This can introduce the "catastrophic forgetting" problem. Pseudo-rehearsal is a good solution: use the original model to label examples, and mix them through your fine-tuning updates.
spaCy now speaks GermanMany people have asked us to make spaCy available for their language. Being based in Berlin, German was an obvious choice for our first second language. Now spaCy can do all the cool things you use for processing English on German text too. But more importantly, teaching spaCy to speak German required us to drop some comfortable but English-specific assumptions about how language works and made spaCy fit to learn more languages in the future.
T-RAG: Lessons from the LLM TrenchesFatehkia, Lucas, Chawla (2024)An important application area is question answering over private enterprise documents where the main considerations are data security, which necessitates applications that can be deployed on-prem, [and] limited computational resources. [...] In addition to retrieving contextual documents, we use the spaCy library with custom rules to detect named entities from the organization.
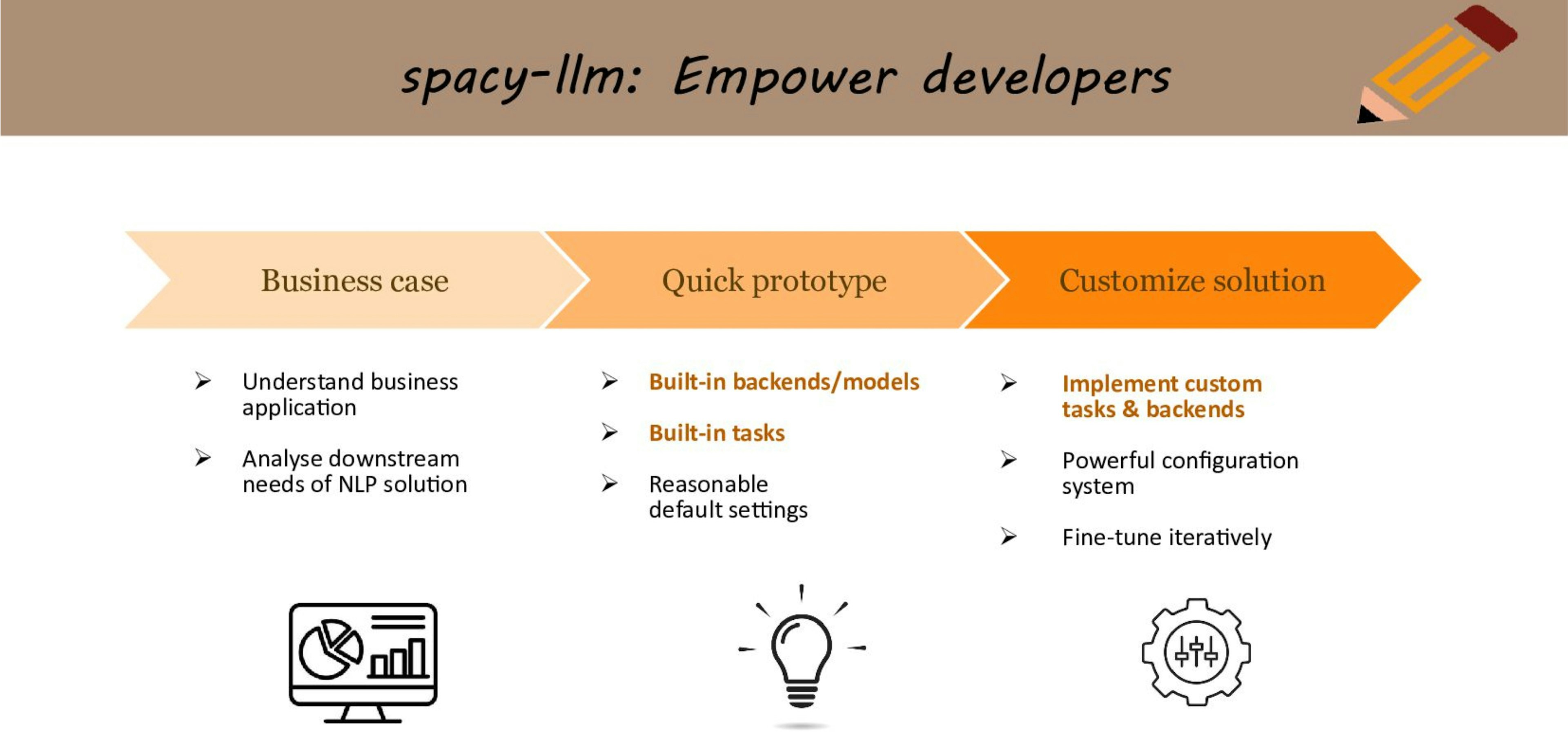
spacy-llm: From quick prototyping with LLMs to more reliable and efficient NLP solutionsAstraZeneca NLP Community of PracticeLLMs are paving the way for fast prototyping of NLP applications. Here, Sofie showcases how to build a structured NLP pipeline to mine clinical trials, using spaCy and spacy-llm. Moving beyond a fast prototype, she offers pragmatic solutions to make the pipeline more reliable and cost efficient.
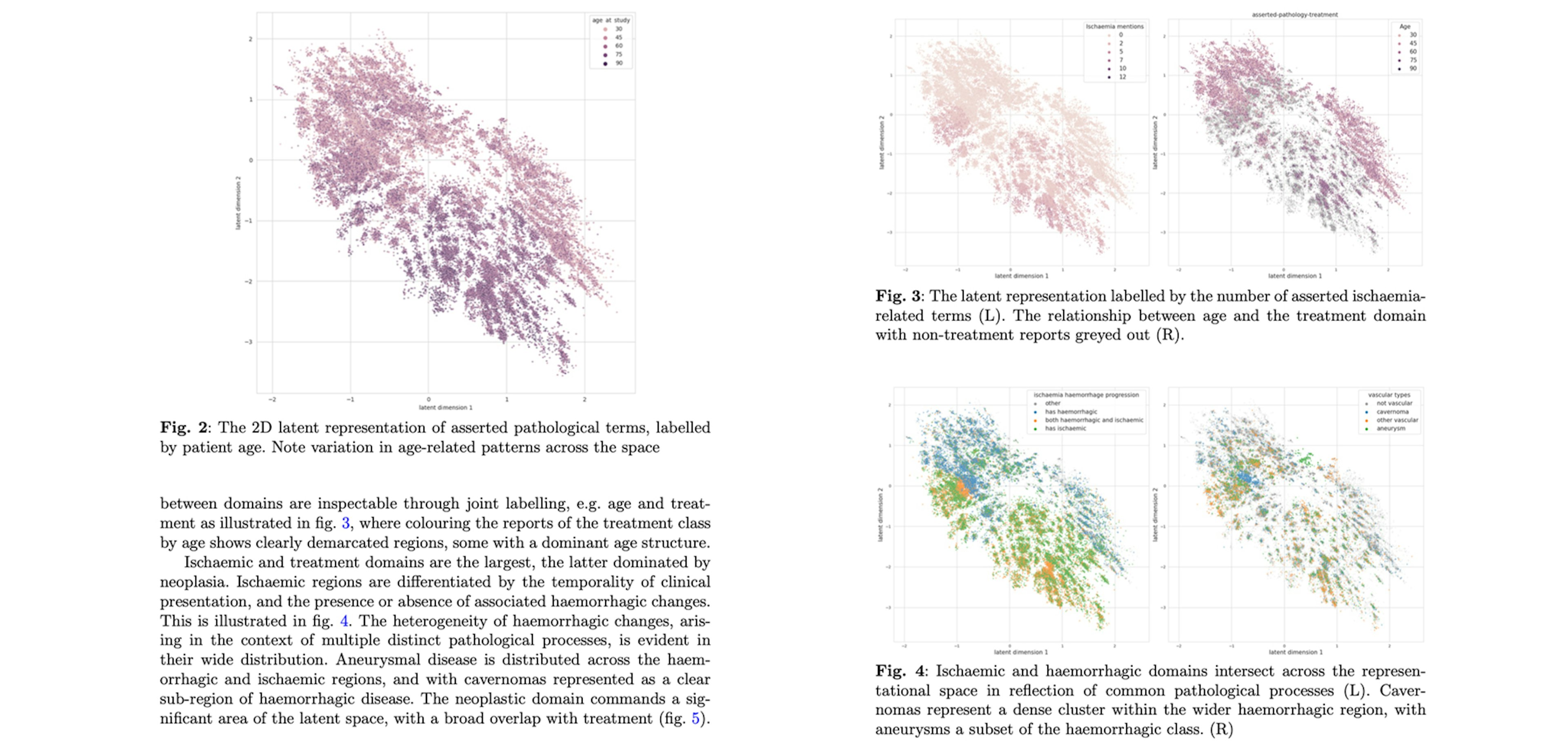
Neuradicon: operational representation learning of neuroimaging reportsWatkins, Gray, Julius, Mah, Pinaya, Wright, Jha, Engleitner, Cardoso, Ourselin, Rees, Jaeger, Nachev (2023)Labelled data for each task was produced using the Prodigy labelling tool. Each report was labelled in a paired-annotation manner. [...] We used the grammatical dependency parse produced by the spaCy parser as input and implemented the patterns using the spaCy dependency matcher.
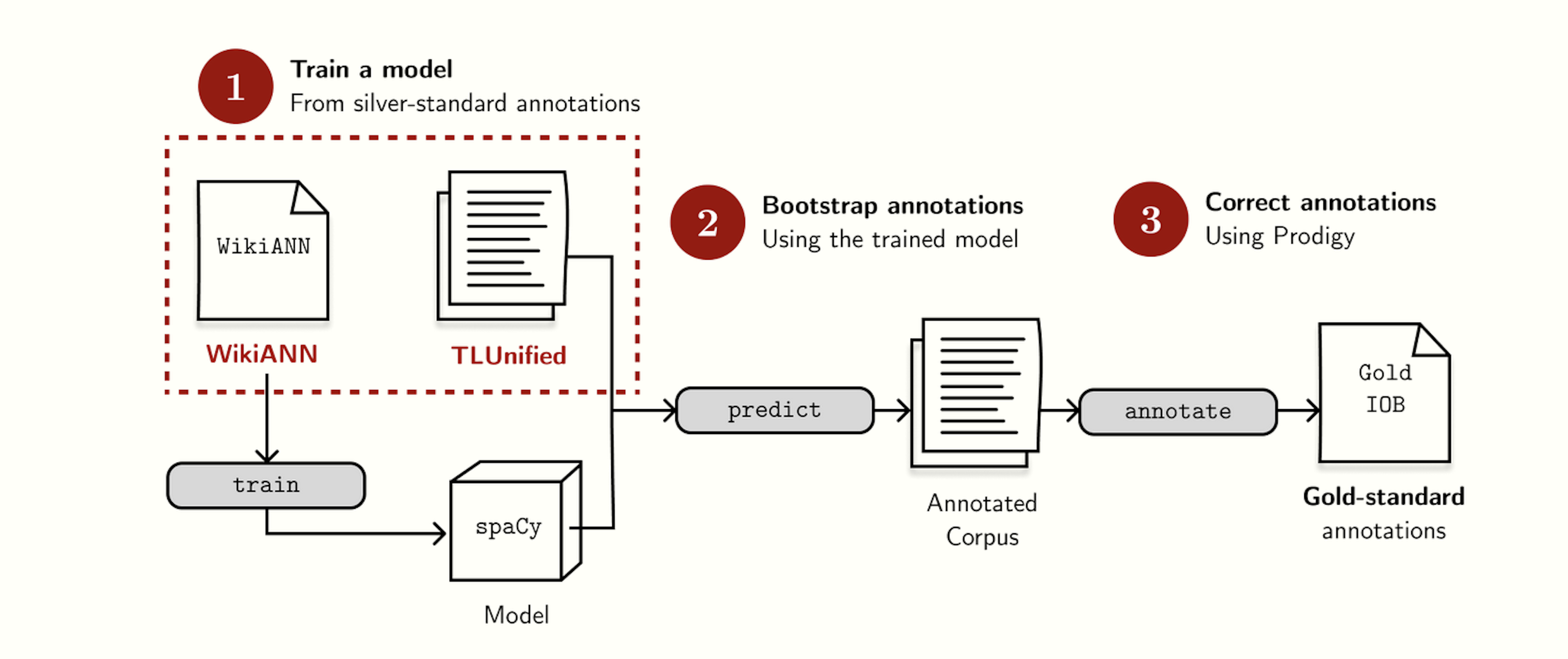
Developing a Named Entity Recognition Dataset for TagalogMiranda (2023), IJCNLP-AACL 2023We used Prodigy as our annotation tool. We set up a web server on the Google Cloud Platform and routed the examples through Prodigy’s built-in task router.
scispacy v0.5.3A Python package containing spaCy models for processing biomedical, scientific or clinical text, developed by AI2.
Introducing spaCy v3.6spaCy v3.6 introduces the span finder component and trained pipelines for Slovenian.
SpanCat with spaCy and Prodigy on real dataYouTube series by WJB Mattingly showing an end-to-end project, from cultivating and annotating data to training, testing and visualizing a model.
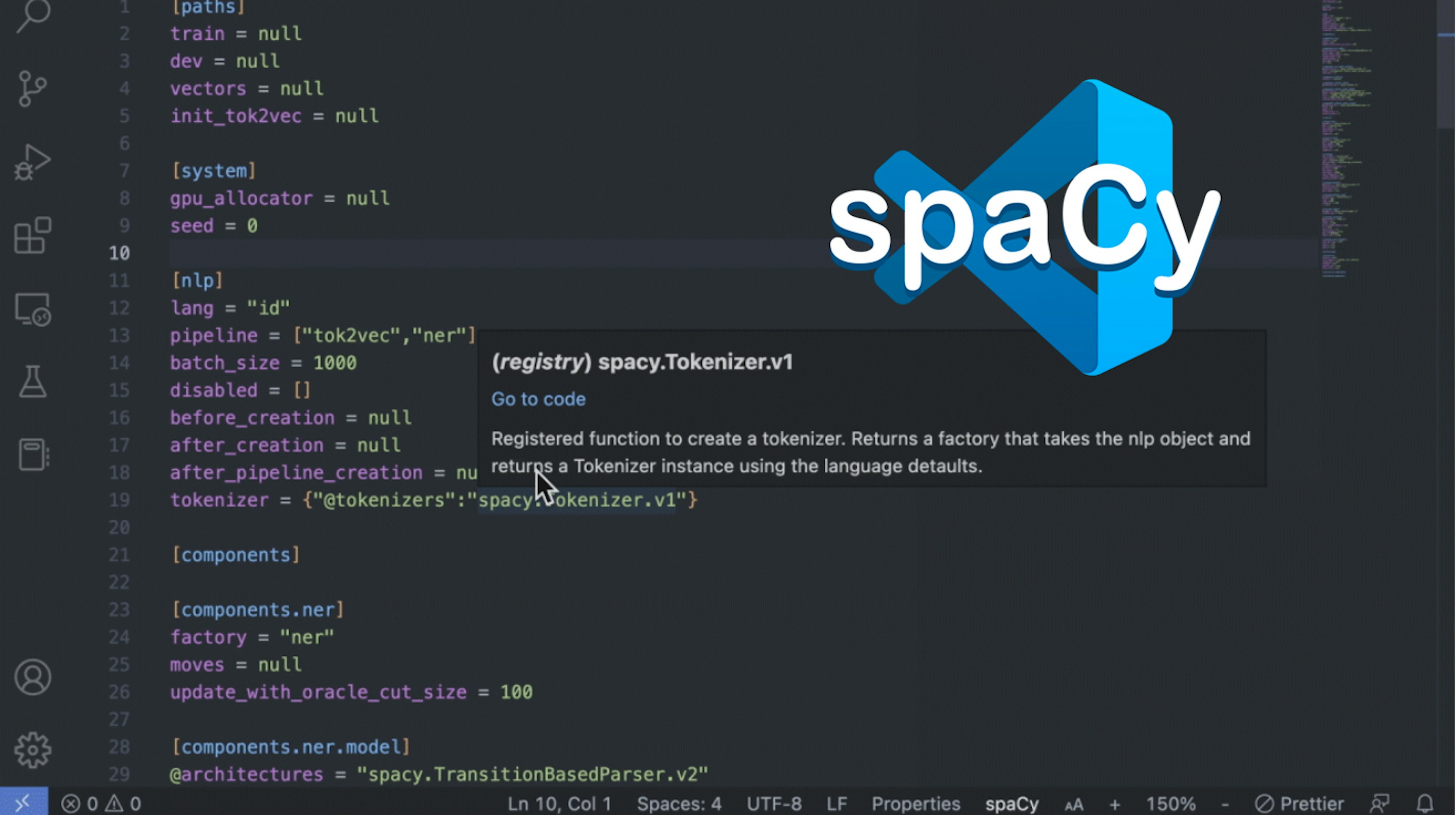
spaCy Plugin for VSCodeThe spaCy VSCode Extension provides additional tooling and features for working with spaCy’s config files. Version 1.0.0 includes hover descriptions for registry functions, variables, and section names within the config as an installable extension.
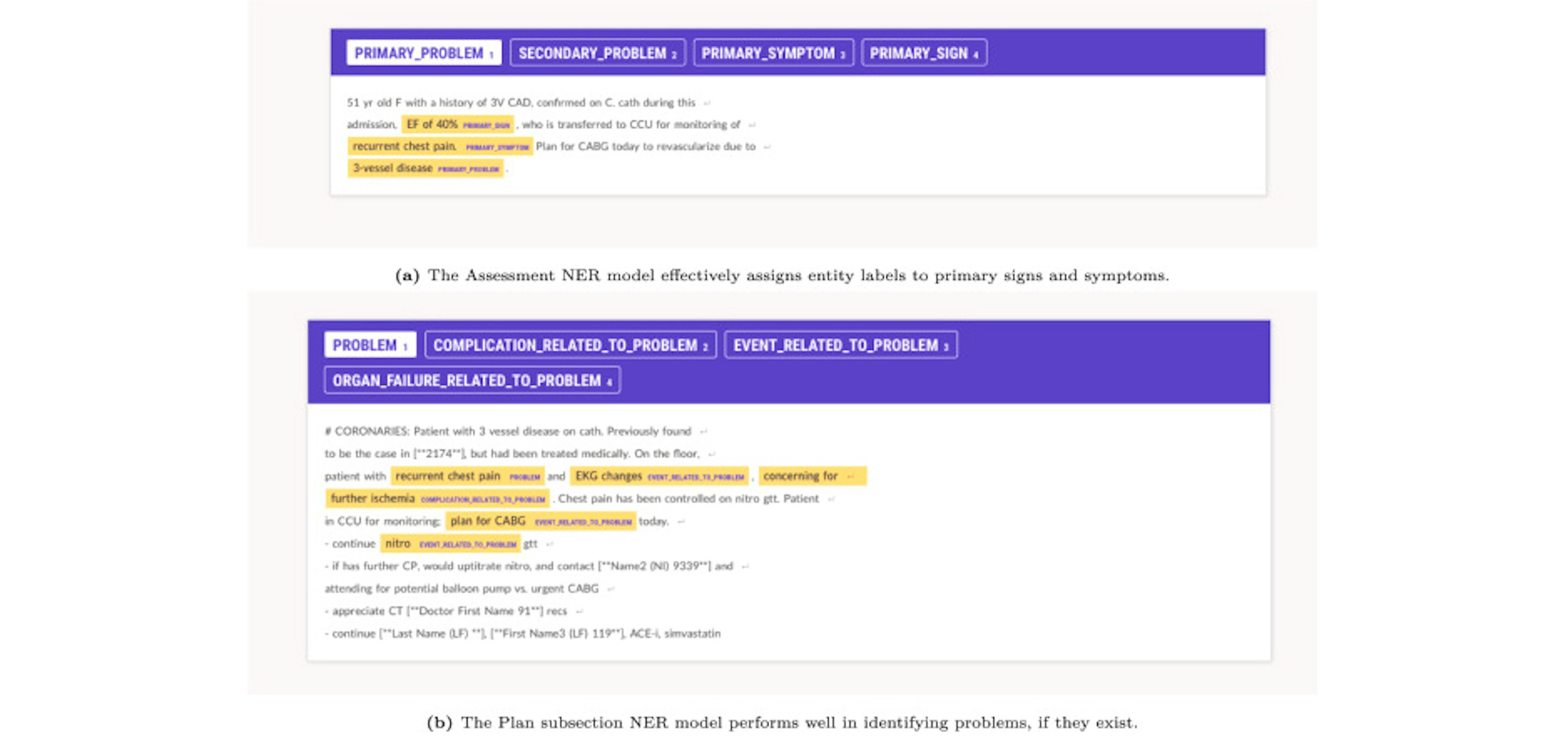
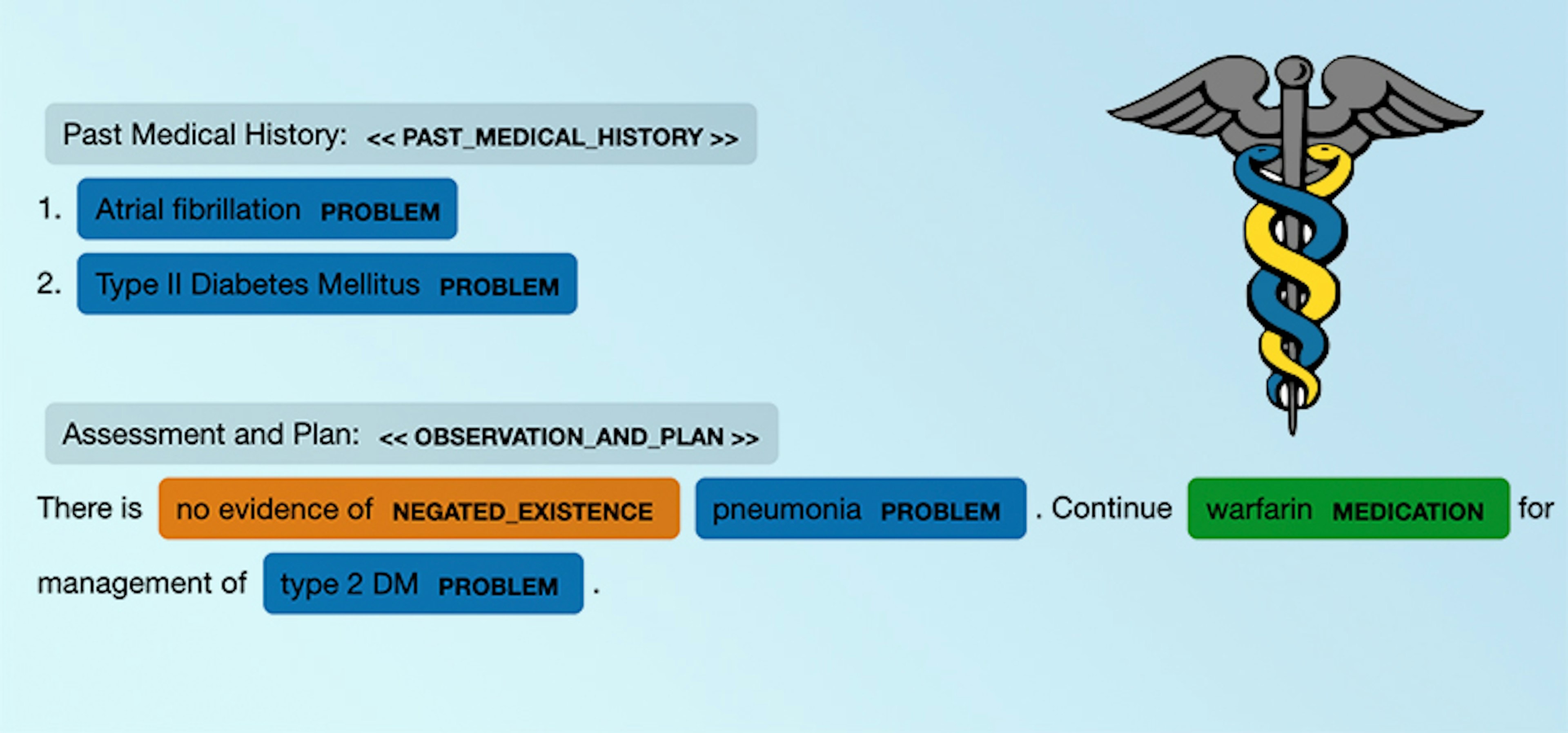
Predicting relations between SOAP note sections: The value of incorporating a clinical information modelSocrates, Gilson, Lopez, Chi, Taylor, Chartash (2023), Journal of Biomedical InformaticsTo support human annotation, we first annotate 100 Assessment and Plan subsections manually using Prodigy, and then use spacy-transformers to fine-tune a general domain RoBERTa-base model pretrained on OntoNotes 5 for both the Assessment and Plan section NER tagging.
textaCy v0.13.0Utility library for NLP tasks before and after spaCy, including preprocessing, normalization and additional information extraction features.
Introducing spaCy v3.5spaCy v3.5 introduces new CLI commands, fuzzy matching, improvements for entity linking and more.
Reflections on a year of spaCy consulting at ExplosionIn this post, Peter shares some lessons learned from chatting with practitioners about their NLP challenges, developing production-ready NLP pipelines for clients, and working with an open-source development team.
The triangulation of ethical leader signals using qualitative, experimental, and data science methodsBanks, Ross, Toth, Tonidandel, Goloujeh, Dou, Wesslen (2022)This additional text was labeled by the same coding team using Prodigy, [...] a flexible user interface tool built on top of spaCy, a leading open source library in python for natural language processing. We created a spaCy end‐to‐end project workflow including package versioning, data pre‐processing, data ingestion into a database, annotation sessions using Prodigy’s user interface, model training, model evaluation, python packaging, and visual app for testing the model.
floret: lightweight, robust word vectorsAn exploration of floret vectors: lightweight vectors for noisy data, novel words, rich morphology and more.
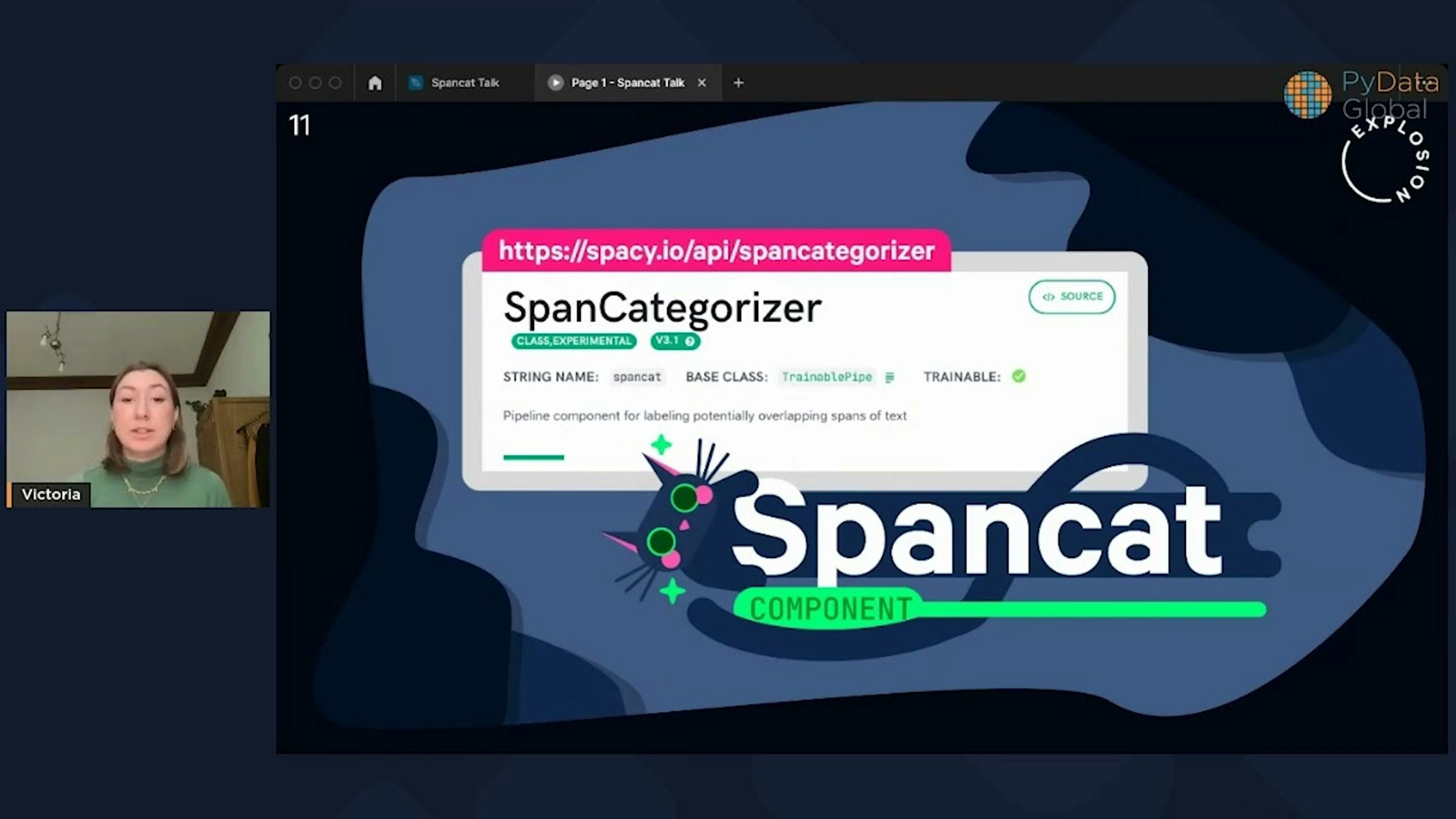
Spancat: a new approach for span labelingThe SpanCategorizer is a spaCy component that answers the NLP community's need to have structured annotation for a wide variety of labeled spans, including long phrases, non-named entities, or overlapping annotations. In this blog post, we're excited to talk more about spancat and showcase new features to help with your span labeling needs!
Explosion in 2021: Our Year in ReviewThe year 2021 is coming to an end, and like the previous year, it was shaped by unique challenges that impacted our work together. For Explosion, it was a very productive year. We found an investor that fits our strategy, the work on Prodigy Teams is in full swing, and the team has grown a lot. So here's our look back at our highlights of the year 2021.
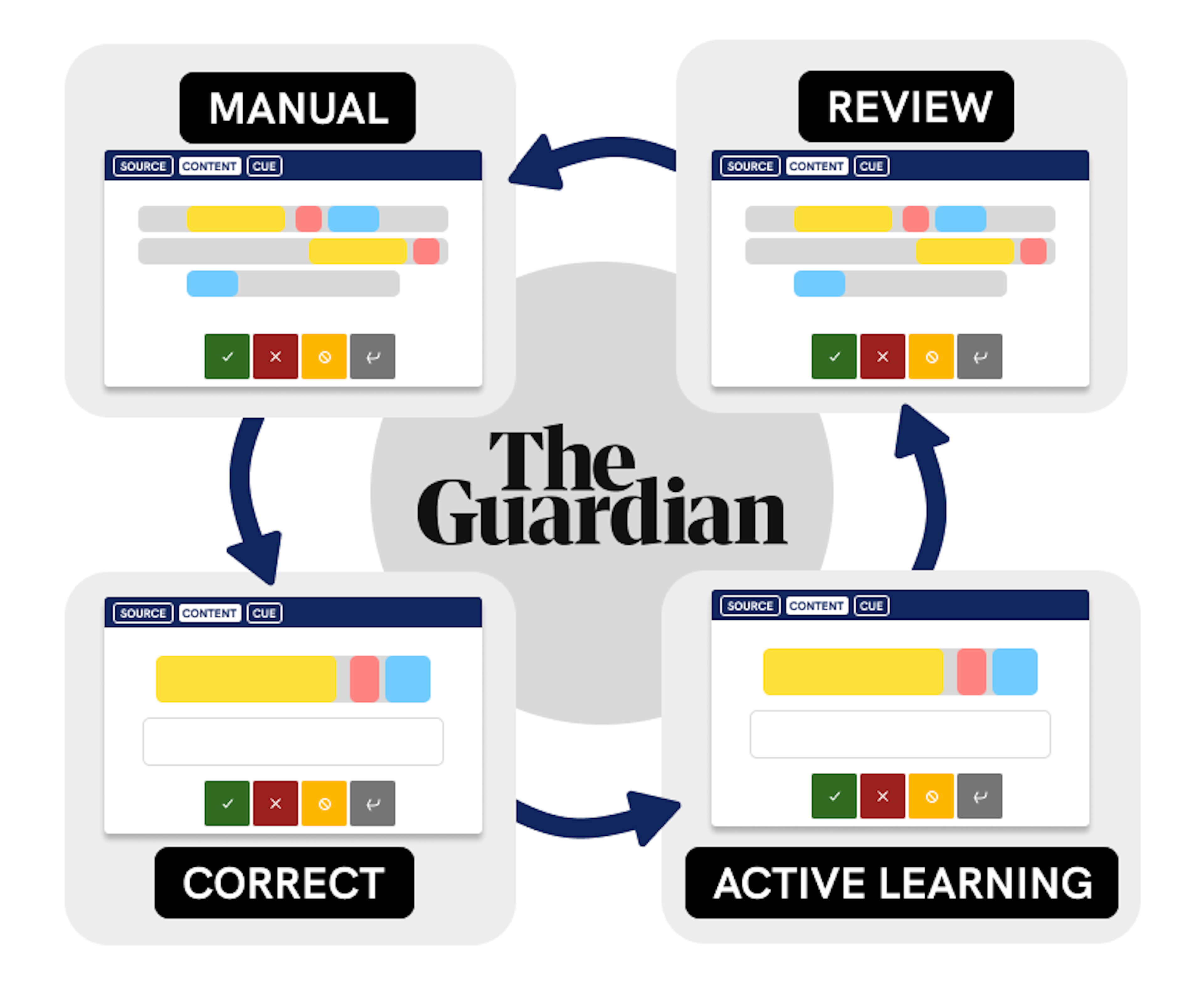
Talking sense: using machine learning to understand quotesThe Guardian BlogHow the Guardian uses spaCy and Prodigy to train a machine learning model that helps extract quotes from news articles and match them to the correct source.
🌸 floret v0.10.0Oct 27, 2021fastText + Bloom embeddings for compact, full-coverage vectors with spaCy
Welcome spaCy to the Hugging Face HubHugging Face BlogHugging Face makes it really easy to share your spaCy pipelines with the community! With a single command, you can upload any pipeline package, with a pretty model card and all required metadata auto-generated for you.
spaCy v3: Custom trainable relation extraction componentspaCy v3.0 features new transformer-based pipelines that get spaCy’s accuracy right up to the current state-of-the-art, and a new training config and workflow system to help you take projects from prototype to production. In this video, Sofie shows you how to apply all these new features when implementing a custom trainable component from scratch.
Explosion in 2020: Our Year in ReviewWhile 2020 hasn’t been easy for anyone, at Explosion we’ve considered ourselves relatively fortunate in this most interesting year. We’ve always worked remotely, so we’ve been able to take both pride and comfort in continuing to ship good software. Here’s a look back at what we’ve been up to.
Explosion awarded META Seal of RecognitionWe’re proud to accept the META Seal of Recognition at META-FORUM in Brussels, along with Mozilla. The META-FORUM is an international conference series backed by the European Union on powerful and innovative Language Technologies for a multilingual information society.
Millennials Kill EverythingThe PuddingAnalysis on media reporting of millenials using spaCy. From napkins to marriage to Applebees, just looking at headlines you’d guess that for the past decade the millennial generation’s been on a rampage.
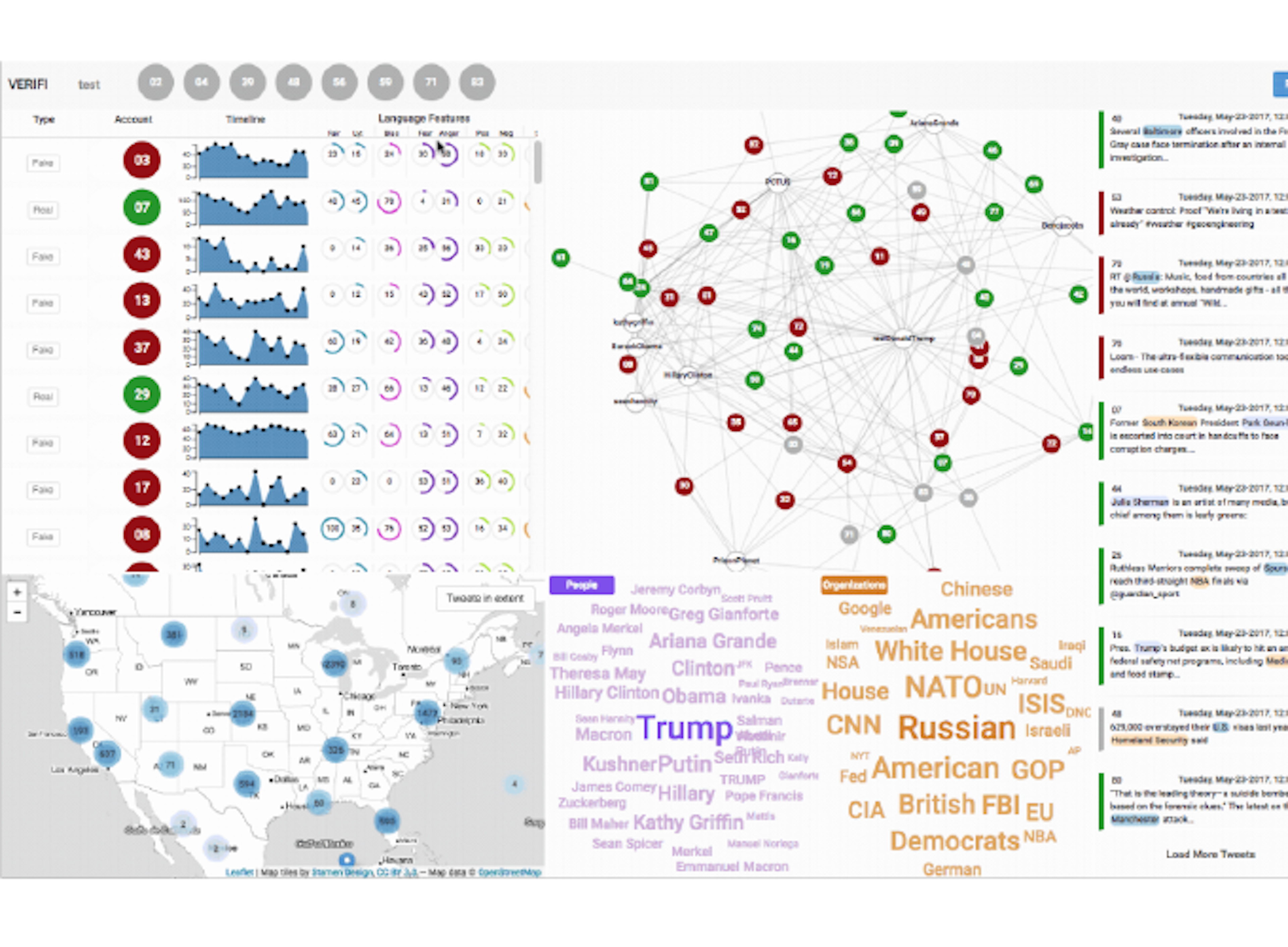
Can You Verifi This? Studying Uncertainty and Decision-Making About MisinformationKarduni, Wesslen, Santhanam, Cho, Volkova, Arendt, Shaikh, Dou (2018)HCI interface to identify misinformation on social media using spaCy for NER.
spaCy’s entity recognition model: incremental parsing with Bloom embeddings & residual CNNsspaCy v2.0’s Named Entity Recognition system features a sophisticated word embedding strategy using subword features and "Bloom" embeddings, a deep convolutional neural network with residual connections, and a novel transition-based approach to named entity parsing.
Reflections on running spaCy: commercial open-source NLPines.ioAs more and more people and companies are getting involved with open-source software, balancing the expectations of an open community and a traditional provider vs. consumer relationship is becoming increasingly difficult. Are maintainers becoming too authoritarian? Are users becoming too demanding? Are large companies selling out open-source?
Sense2vec with spaCy and GensimIf you were doing text analytics in 2015, you were probably using word2vec. Sense2vec (Trask et. al, 2015) is a new twist on word2vec that lets you learn more interesting, detailed and context-sensitive word vectors. This post motivates the idea, explains our implementation, and comes with an interactive demo that we've found surprisingly addictive.
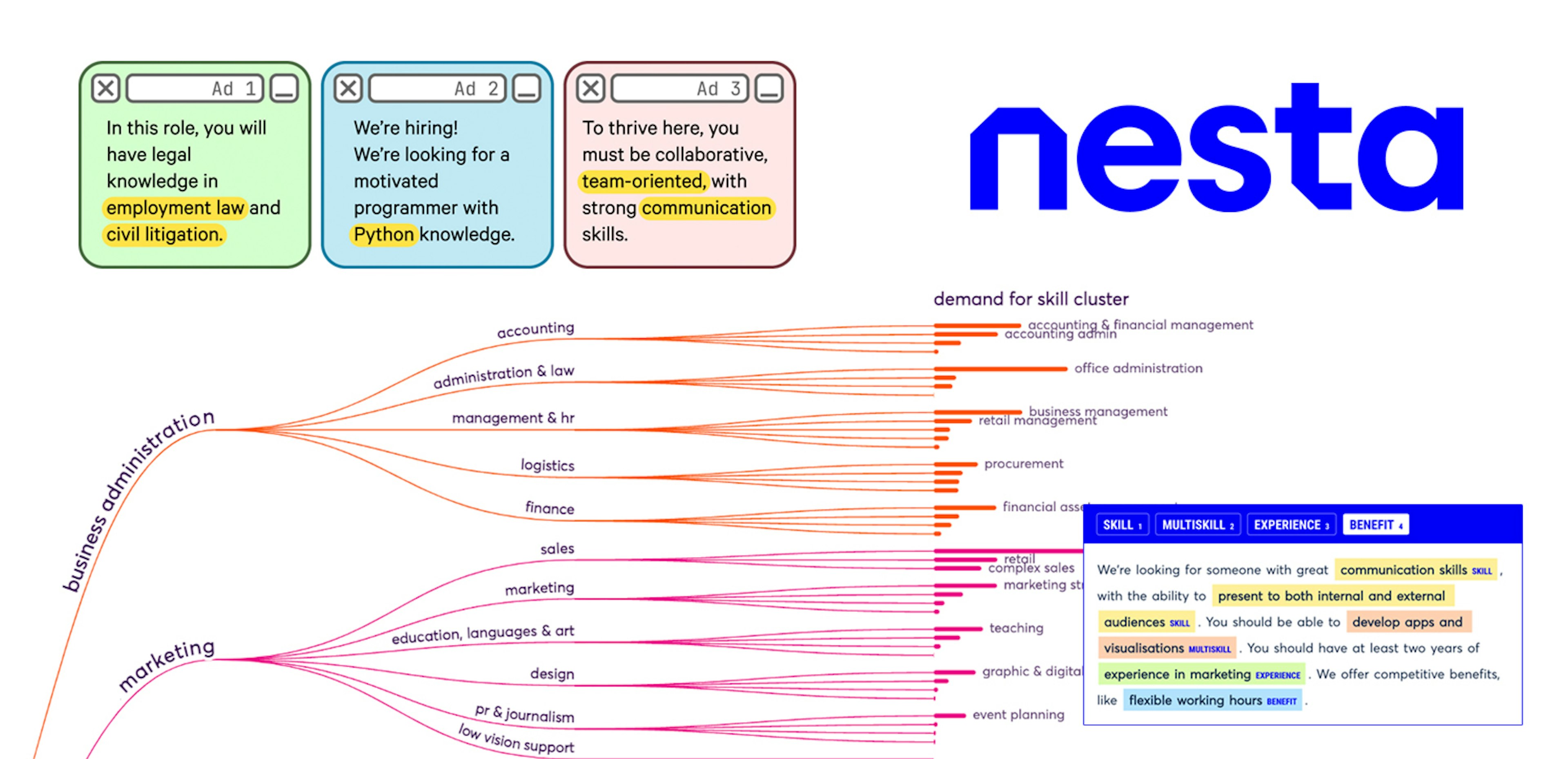
How Nesta uses NLP to process 7m job ads and shed light on the UK’s labor marketA case study on Nesta’s workflow for extracting 7 million job ads to better understand UK skill demand, using a custom mapping step to match skills to any government taxonomy.
Microsoft Presidio v2.2.352Context aware, pluggable and customizable PII de-identification and anonymization service for text and images, featuring a spaCy back-end.
Who said what: using machine learning to correctly attribute quotesThe Guardian Engineering BlogHow the Guardian uses spaCy and Prodigy to train a custom coreference resolution model.
State-of-the-Art Transformer Pipelines in spaCyaiGrunnIn this talk, we will show you how you can use transformer models (from pretrained models such as XLM-RoBERTa to large language models like Llama2) to create state-of-the-art annotation pipelines for text annotation tasks such as named entity recognition.
Newsletter September 2023The latest edition of our newsletter, featuring our plans for premium models, LLMs, chain-of-thought prompting, upcoming events and talks, and exciting new Prodigy features. Plus exclusive discounts!
🦙 spacy-llm v0.3.0Jun 14, 2023Cohere, Anthropic, OpenLLaMa, StableLM, logging, streamlit demo, lemmatization task
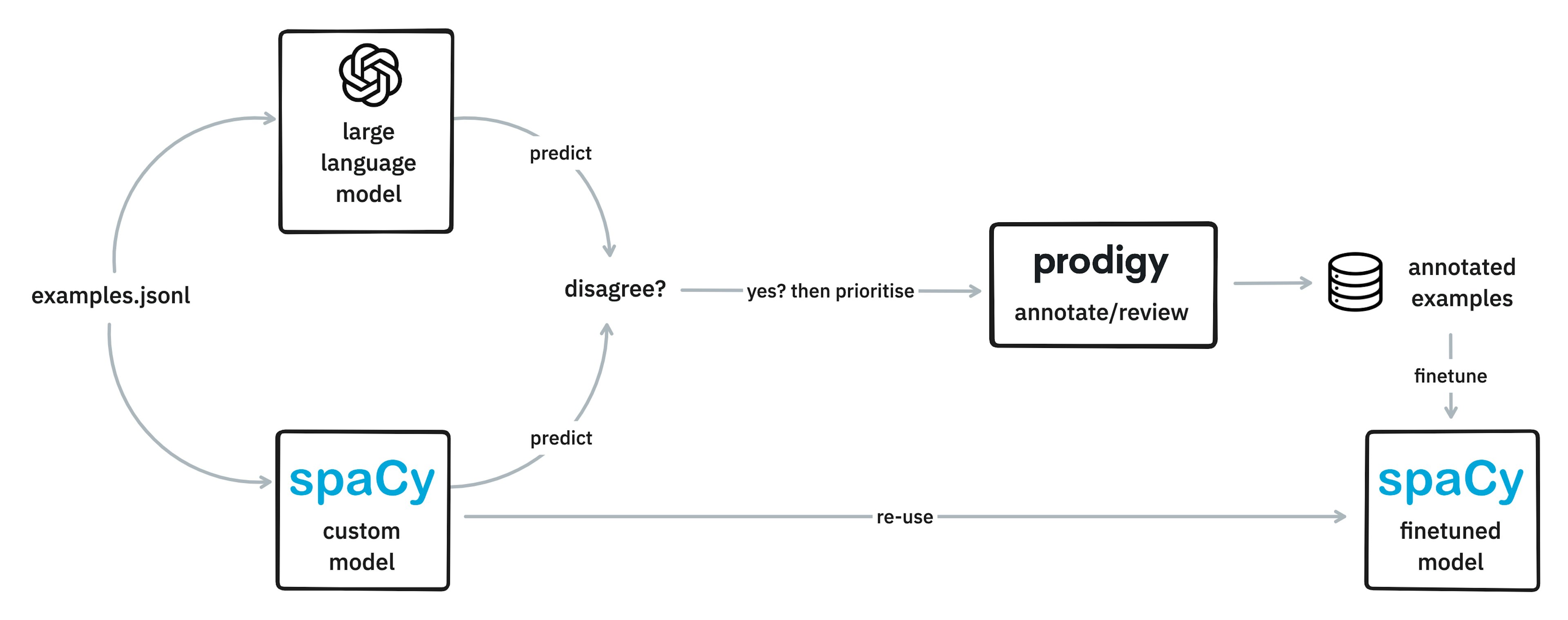
Large Disagreement Modelling“In this blogpost I’d like to talk about large language models. There’s a bunch of hype, sure, but there’s also an opportunity to revisit one of my favourite machine learning techniques: disagreement.”
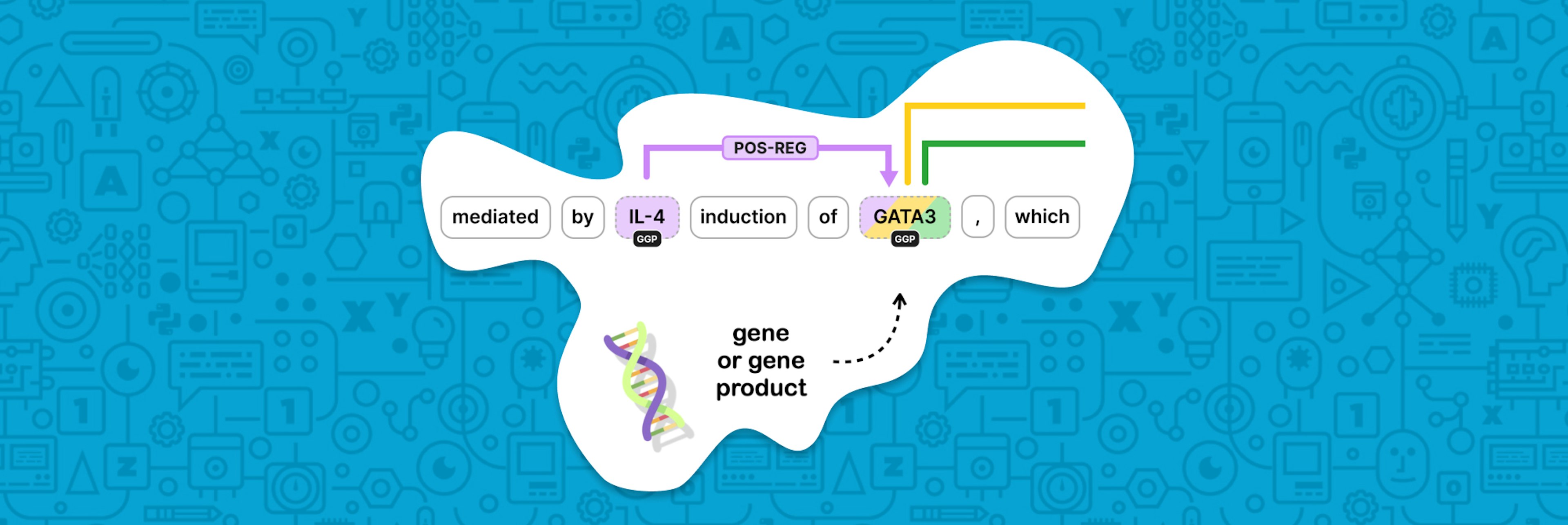
Implementing a custom trainable component for relation extractionRelation extraction refers to the process of predicting and labeling semantic relationships between named entities. In this blog post, we'll go over the process of building a custom relation extraction component using spaCy and Thinc. We'll also add a Hugging Face transformer to improve performance at the end of the post. You'll see how you can utilize Thinc's flexible and customizable system to build an NLP pipeline for biomedical relation extraction.
Rulers, NER, and data iterationAbout the power of Rules + ML and the importance of iteration on your pipeline and your data.
Explosion in 2022: Our Year in ReviewIt's been another exciting year at Explosion! We've developed a new end-to-end neural coref component for spaCy, improved the speed of our CNN pipelines up to 60%, and published new pre-trained pipelines for Finnish, Korean, Swedish and Croatian. We've also released several updates to Prodigy and introduced new recipes to kickstart annotation with zero- or few-shot learning.
Is it possible to have entities within entities within entities?PyData Global 2022Named entity recognition models might not be able to handle a wide variety of spans, but Spancat certainly can! Dive into named entity recognition, its limitations, and how we’ve solved them with a solution-focused talk and practical applications.
How the Guardian approaches quote extraction with NLPA case study of the Guardian's spaCy-Prodigy workflow to modularize quote extraction for content creation. This study includes iterative annotation guidelines and custom interface functionality.
Introducing Holmes 4.0A few weeks ago we released version 4.0 of Holmes, which we are now able to offer under a permissive MIT license. Holmes is a library in the spaCy Universe that runs on top of spaCy and enables information extraction and intelligent search, currently for English and German. Holmes goes beyond simple matching algorithms and allows you to look for a specified idea or ideas in a corpus of documents.
Diary of a spaCy project: Predicting GitHub TagsMany people assume that working on an NLP project involves a lot of machine learning. Our experience is that it's much less about flowing tensors, and more about making a tailored solution. This blogposts demonstrates how a typical spaCy project could be initiated, implemented and executed towards a custom solution.
Applied Language TechnologyExtensive online course on applied language technology with spaCy by Tuomo Hiippala, designed for students new to NLP and programming.
Healthsea: an end-to-end spaCy pipeline for exploring health supplement effectsCreate better access to health with machine learning and natural language processing. Read about our journey of developing Healthsea, an end-to-end spaCy pipeline for analyzing user reviews to supplement products and extracting potential effects on health.
spaCy v3's project and config systems are pretty greatThe road to production has become increasingly harder. Machine Learning Engineers who turn prototypes into production-ready software face difficulties with the lack of tooling and best-practices. spaCy v3, with its configuration and project system, introduced a way to solve this problem. Here's my take on how it works, and how it can ramp-up your team!
🛸 spacy-transformers v1.1.0Oct 18, 2021Better serialization, full ModelOutput, mixed-precision training and more
Introducing spaCy v3.1It’s been great to see the adoption of spaCy v3, which introduced transformer-based pipelines, a new training system and more. Version 3.1 adds more on top of it, including the ability to use predicted annotations during training, a component for predicting arbitrary and overlapping spans and new pipelines for Catalan and Danish.
spaCy v3: Design concepts explained (behind the scenes)In this video, Ines shows you some of the new design concepts and explain what’s going on under the hood, how we’ve implemented them and most importantly, why.
The Physical Traits that Define Men and Women in LiteratureThe PuddingAnalysis of physical traits most tied to gender in literature using spaCy.
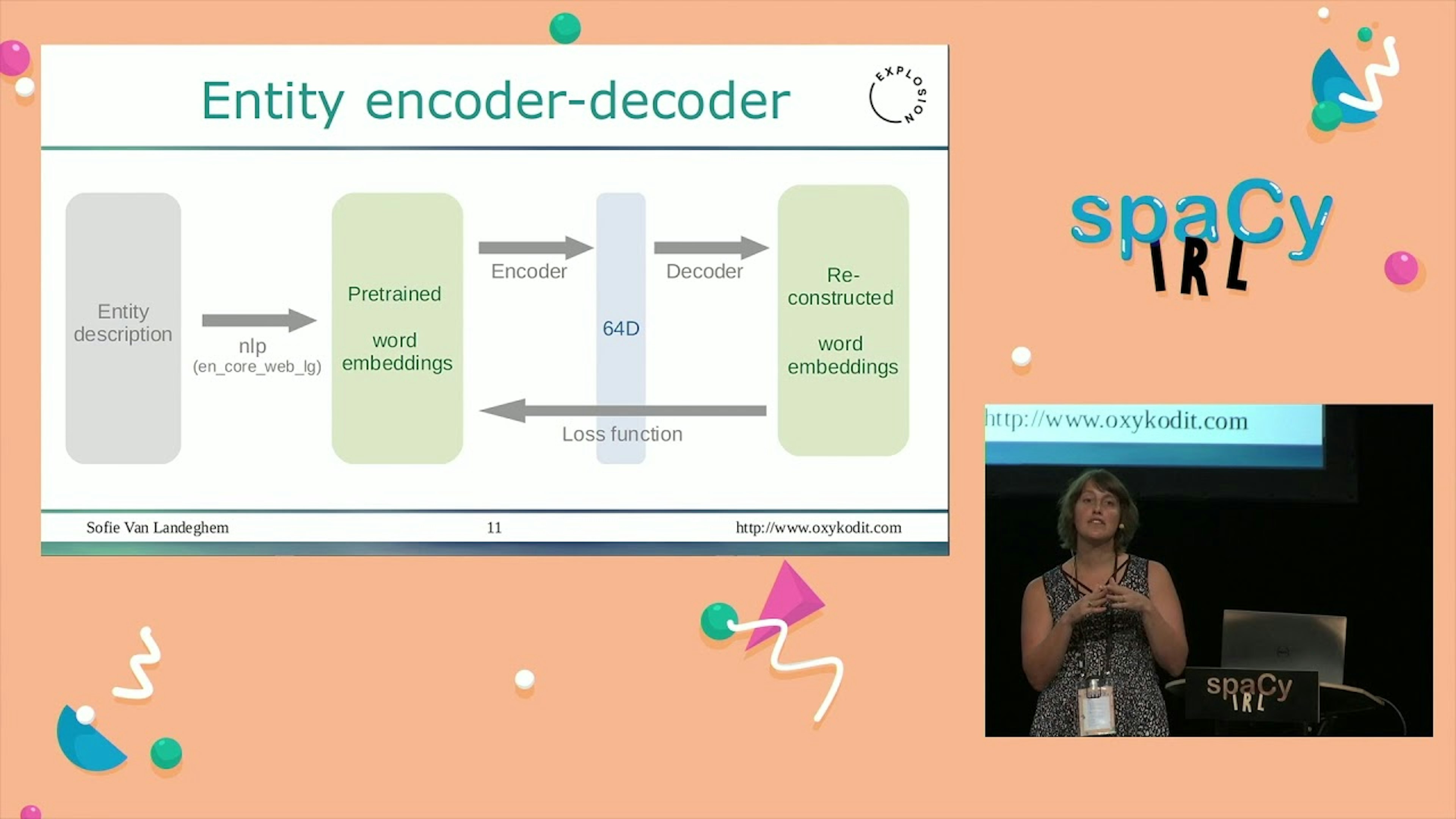
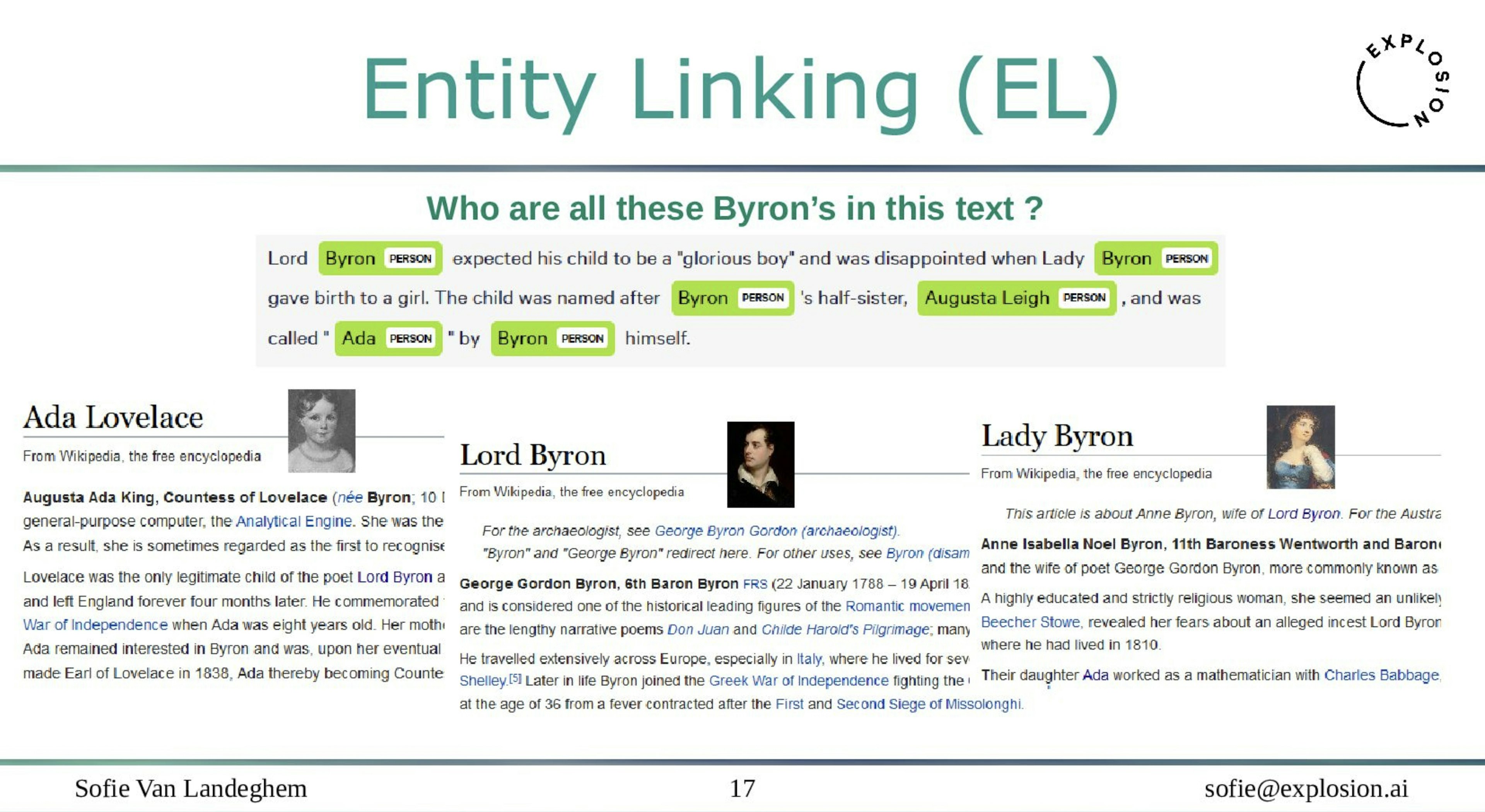
Training a custom entity linking model with spaCyIn this video, we show you how to create a custom Entity Linking model in spaCy to disambiguate different mentions of the person “Emerson” to unique identifiers in a knowledge base.
sense2vec reloaded: contextually-keyed word vectorsIn 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. That work is now due for an update. In this post, we present a new version and a demo NER project that we trained to usable accuracy in just a few hours.
Introducing spaCy v2.2Version 2.2 of the spaCy Natural Language Processing library is leaner, cleaner and even more user-friendly. In addition to new model packages and features for training, evaluation and serialization, we've made lots of bug fixes, improved debugging and error handling, and greatly reduced the size of the library on disk.
Intro to NLP with spaCy (1): Detecting programming languagesIn this new video series, data science instructor Vincent Warmerdam gets started with spaCy, an open-source library for Natural Language Processing in Python. His mission: building a system to automatically detect programming languages in large volumes of text.
Advanced NLP with spaCy: A free online courseIn this free and interactive online course, you’ll learn how to use spaCy to build advanced natural language understanding systems, using both rule-based and machine learning approaches.
The process: Transforming spaCy’s docsIncrement MagazineMaking your documentation work for users with vastly different needs is a challenge. Here’s how spaCy, an open-source library for natural language processing, did it.
Explosion in 2017: Our Year in ReviewWe founded Explosion in October 2016, so this was our first full calendar year in operation. We set ourselves ambitious goals this year, and we're very happy with how we achieved them. Here's what we got done.
Introducing custom pipelines and extensions for spaCy v2.0As the release candidate for spaCy v2.0 gets closer, we've been excited to implement some of the last outstanding features. One of the best improvements is a new system for adding pipeline components and registering extensions to the Doc, Span and Token objects. In this post, we'll introduce you to the new functionality, and finish with an example extension package, spacymoji.
spaCy v1.0: Deep Learning with custom pipelines and KerasI'm pleased to announce the 1.0 release of spaCy, the fastest NLP library in the world. By far the best part of the 1.0 release is a new system for integrating custom models into spaCy. This post introduces you to the changes, and shows you how to use the new custom pipeline functionality to add a Keras-powered LSTM sentiment analysis model into a spaCy pipeline.
How spaCy WorksThis post was pushed out in a hurry, immediately after spaCy was released. It explains some of how spaCy is designed and implemented, and provides some quick notes explaining which algorithms were used. The post pre-dates spaCy's named entity recogniser, but it provides some detail about the tokenisation algorithm, general design, and efficiency concerns.