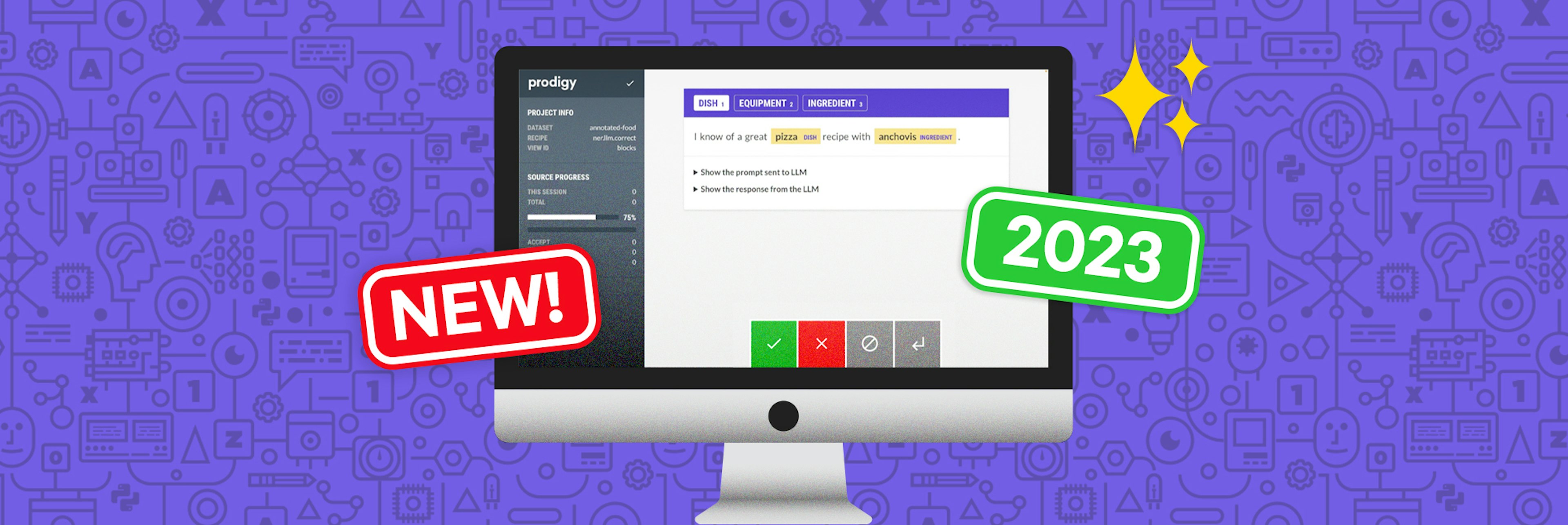
A recent trend for media companies is to explore how fields like Natural Language Processing (NLP) and Information Extraction (IE) can modularize content like a long-form article as reusable elements for different storytelling formats (e.g., a podcast, information graphic, or blog). This push is called modular journalism and many media companies are building towards it to automate customized stories to meet individual user needs for a variety of media forms.

At the same time, a push towards automating reusable content may incur significant reputational risks for media companies. Given audiences of potentially millions of global viewers, one wrong automation can lead to many dissatisfied news consumers. Therefore, model stakeholders like journalists and editors must trust and review AI models before deploying them for customer-facing content generation.
We’re very much aware of potential reputational risks… in media trust is everything… very easy to lose and hard to build up again.
— Anna Vissens, lead data scientist for the Guardian.
To facilitate trust, human-in-the-loop workflows are widespread in media applications as stakeholders require the ability to teach and to evaluate models through human-AI interfaces. For their AI projects, the Guardian’s data science team decided to use Prodigy, a modern annotation tool for creating training and evaluation data for human-in-the-loop machine learning.
 Try the live demo!
Try the live demo!
In a recent interview with Explosion, Anna Vissens, lead data scientist for the Guardian’s data science team, discussed how her team customized Prodigy to extract quote modules in news articles. Along the way, they developed stakeholder trust through iterative group discussions yielding well-defined annotation guidelines and tandem team learnings during their annotation process.
The Guardian data science team is a small team of six data scientists. Like Anna, the team has several members with backgrounds in natural sciences like physics along with many years of work experience in journalism.
The team needs flexible and programmatic tools that can enable them to test ideas for AI projects quickly, iterating on those that are successful and customizing the tool for their unique use cases.
The team also has a significant need for human-in-the-loop workflows. Their stakeholders are journalists and editors who want to understand and have insight into AI’s limitations.
The principle of human-in-the-loop [machine learning] is everywhere in journalism.
— Anna Vissens
Simple and intuitive model interfaces are critical for their stakeholders to annotate text in a quick and efficient manner for model learning.
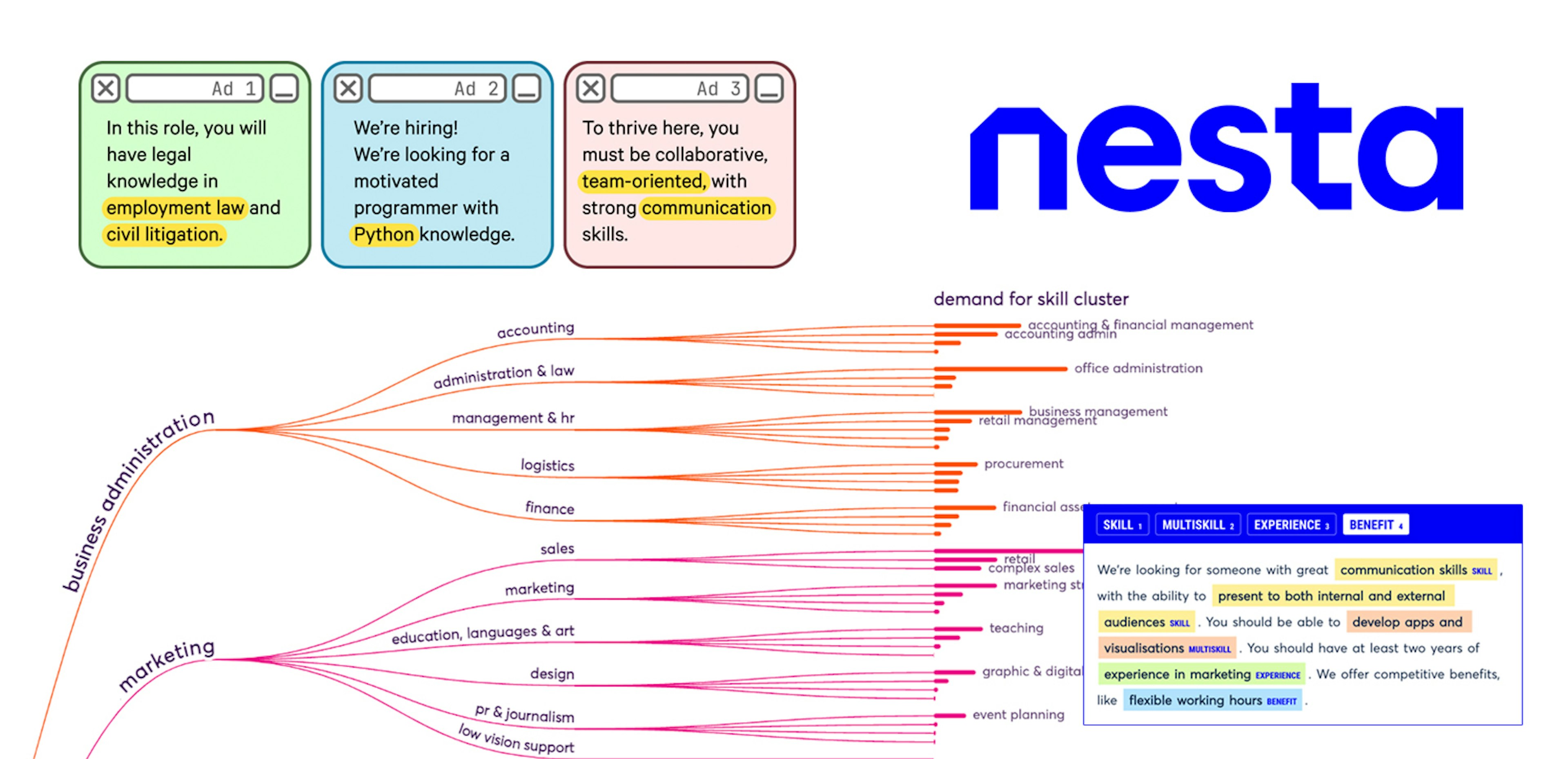
One example of a project Anna’s team is working on toward modular journalism comes from a collaboration with the Journalism AI initiative to extract quotes from articles.
Along with colleagues from the Agence France-Presse (AFP), the team used Prodigy to manually annotate more than 800 news articles to identify three parts of quotes:

The final step would include coreference resolution to define ambiguous references (e.g., pronouns like “he” or “she”). With such information, this model could structure data on quotes (e.g., what was the quote and who said it) to enable reuse of the quotes in different media formats.
The team developed a hybrid rules and model-based annotation workflow with Prodigy. For their initial approach, the team used regular expression rules to extract quotes by matching patterns along with spaCy’s dependency parser as candidate spans. The patterns were matched with domain knowledge of conventional ways to write about quotations (“someone said [quote]”, “someone told someone [quote]”, etc.).

However, they noticed problems with the rules. The exclusively rules-based system struggled on quotes outside of quotations, like quotation marks to indicate non-standard English terms such as “woke” or mottos. Further, quotation rules also wouldn’t identify the source or cue for the quote. So the team opted for Prodigy’s workflows for training named entity recognition (NER) models to train a model to handle these instances.
But before annotating, the team developed initial annotation guidelines based on The Guardian’s style guide. These guidelines defined what a quotation is and its three sub-components: source, cue, and content. Annotation guidelines like these are especially critical for projects with multiple annotators in order to ensure consistent results.
Annotation guidelines are instructions that describe the specific types of information that should be annotated for a task along with examples of each type. In a 2017 blog post, Professor of Digital Humanities Nils Reiter defines the goal of annotation guidelines as “given a theoretically described phenomenon or concept, describe it as generic as possible but as precise as necessary so that human annotators can annotate the concept or phenomenon in any text without … ambiguity issues.”
Creating annotation guidelines is an inherently iterative process: after drafting initial guidelines, it’s necessary to identify shortcomings with examples, update the guidelines, and repeat. Importantly, in each round, the same text should be annotated by multiple annotators independently. After each round, a group’s time is best spent discussing annotation disagreements, especially interesting, difficult, explanatory or flagged examples.
Many minor errors are due to annotators not paying attention or not having a clear definition. These can be easily fixed without modifying guidelines. However, other issues may highlight contradictions in guidelines and require group discussion to fix. Designing consistent annotation schemes is important for model training as they facilitate consistent signals in the data which makes it easier for the model to learn.
For more details, check out Matthew’s 2018 PyData Berlin talk on the “Machine Learning Hierarchy of Needs”:


After several rounds of annotations, the Guardian Data Science team developed a clearly defined set of guidelines with multiple examples.
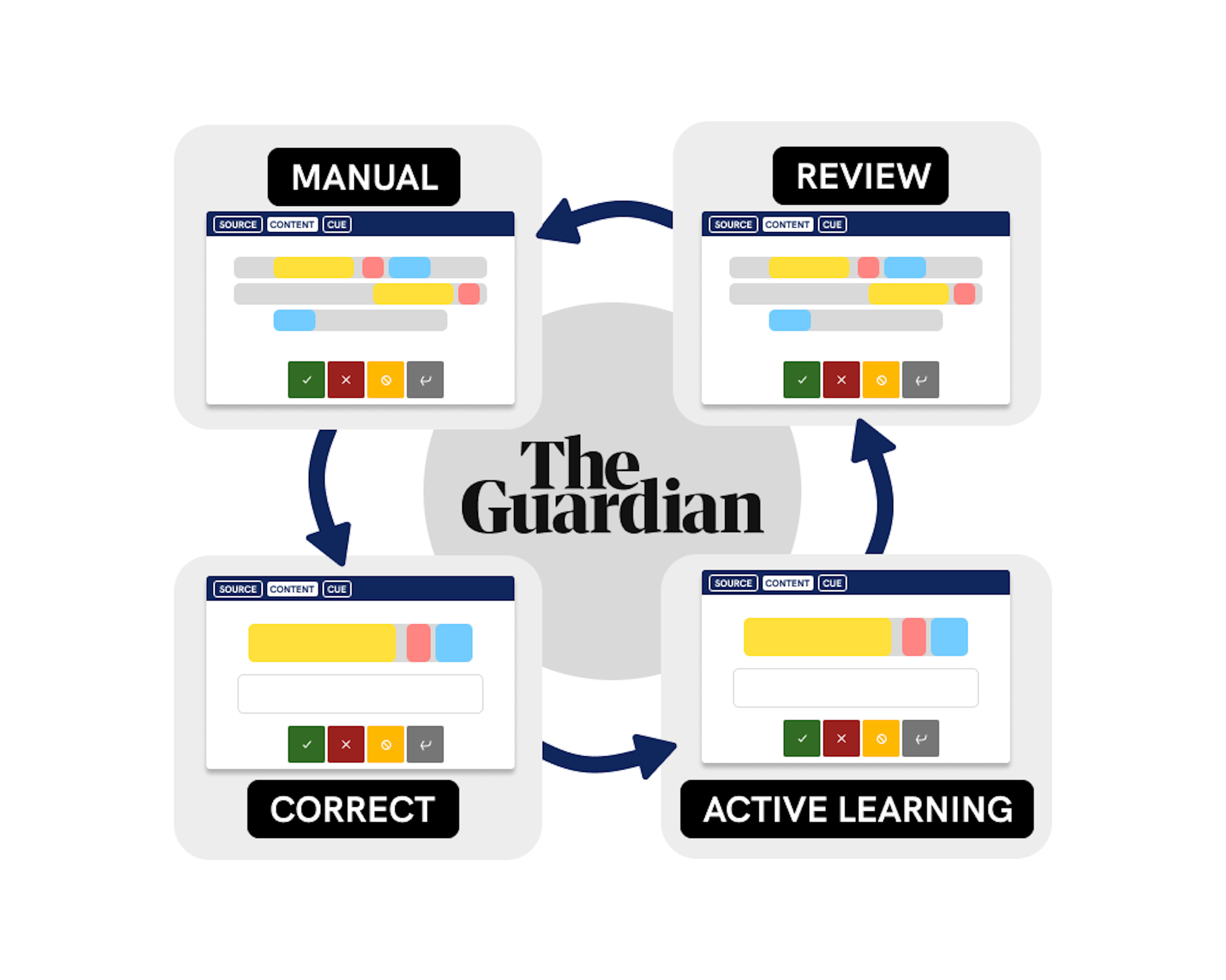
With the initial guidelines in place, the team then iterated on a quick annotation-to-training workflow with four custom Prodigy recipes:
quotes.manual: Mark entity spans in a text by highlighting them and selecting the respective labels. This recipe used rules as initial patterns to aid in faster corrections and train an initial model for other recipes.quotes.correct: Using the initial model from the previous step, manually verify and correct the model’s predictions to create gold-level annotations.quotes.teach (active learning): After re-training the model with the gold annotations, use active learning to focus further annotation and training on the most uncertain examples as scored by the model.quotes.mark (review): Review previously-annotated examples. This recipe would be used when needing to adjudicate on annotation with label conflicts.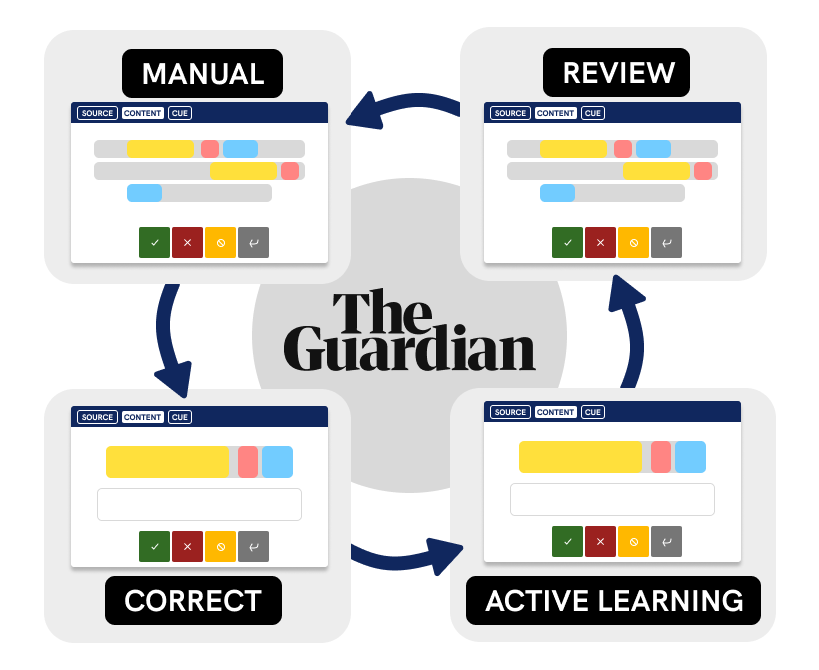
Anna and team also had initial challenges with trust and confidence for annotators. Recognizing these issues, the team modified Prodigy’s configuration (prodigy.json file) along with their custom recipes (e.g., recipe.py) to improve trust and user experience.

To do so, the team customized Prodigy’s user interface for their task in several ways. First, they added a flag functionality (see (C) in the Figure) for annotators to tag posts that needed further review. This would modify a field in the database for each annotation, enabling fast filtering for flagged annotations.
Second, they added custom HTML to display annotation guidelines via a help icon (A). In addition, they combined different Prodigy tasks using blocks to add free-form text box (F) to provide optional free form feedback.
In addition, the team also improved user experience by modifying designs like colors (D and E), adding/removing buttons (H), and even added keyboard shortcuts (B) to annotate faster. Because Prodigy is scriptable, the team could customize the interface as they saw fit.
To learn more about Prodigy, check out our video tutorial on training a NER model. The video shows an end-to-end workflow for training a named entity recognition model to recognize food ingredients from scratch, taking advantage of semi-automatic annotation with ner.manual and ner.correct, as well as modern transfer learning techniques.
We have also created Prodigy Shorts by Vincent D. Warmerdam, a playlist on our YouTube channel of quick lessons about Prodigy on topics like adding annotation instructions, setting custom label colors, and adding flag functionality.
The team’s model development also drove insight beyond their models. A major obstacle in developing their training corpus was how to handle the variety of different journalistic styles.
They discussed as a group multiple examples, including how to handle quotes in poems, messages, or even quoting their own thoughts. With each subsequent iteration, they revised and improved their guidelines and updated their expectations of the data and the model.
To ensure appropriate communication, the team used several collaborative tools like Slack, Google Chat, and Google Docs for maintaining the guidelines. Scaling annotations increases the need for dynamic communication between annotators and teammates in different workplaces (working-from-home, async) or different offices across the world. The team found a successful strategy using cloud-based documents that would ensure appropriate version control of guidelines while polling group members through Slack polls when questions emerged outside of meetings.
Eventually, they achieved acceptable model performance for all three quote parts (source, cue, and content), with the model predicting correctly in 89% of cases. Additionally, they found they improved model performance by ignoring their earlier annotations due to increased alignment between annotators later in the annotation process. Their iterative experimentation with their annotation process improved their collective knowledge so much they’ll even consider using this process to update their standard style guides in the future.
I like the idea that AI forces us to deconstruct our habits and understand how we do things, and what steps we take before telling the model what the rules are. By doing that we can sometimes identify necessary changes and improve our original ‘real life’ processes. That is why this type of experiment could also lead to changes in our style guide.
— Michaëla Cancela-Kieffer, AFP deputy news editor for editorial projects
Moving forward, Anna and the Guardian Data Science team have several long term goals.
First, they’ve started testing initial pilots of modular journalism pipelines like a Live Blog with named entity recognition filters. The Beta site allows users to filter content by NER identified entities in real time. The goal is to improve user experience with Live Blog by making news more navigable, and to evaluate wider adoption for real time events in fields like sports and politics.

A longer term goal is to use Prodigy to fine-tune spaCy NER models for entity types like organizations and people to a larger news-specific corpus. Anna and team think that “organizations are so wide” that’s its challenging to capture organization entities in different news contexts.
For example, sports teams that say “we” — does that mean the team? the fans? the city/community? Or alternatively, when articles use a person’s name as an adjective (e.g., Trump government or Biden administration), models pre-trained on general corpora may classify an organization as a person. The team believes that enhanced entities can then lead to better hierarchical entity structures across multiple domains.
Last, Explosion and the Guardian are teaming up to develop an NLP system for detecting and linking person and company names and their relationships to support investigative journalists. We’re excited about the opportunities of this collaboration so be on the lookout for future posts from Explosion about our collaboration!