Building Multimodal Corpora Using Microtask Pipelines and Local AnnotatorsHotti, Vázquez, Jokipohja, Kalliokoski, Paakki, Suviranta, Hiippala (2026)To create the infrastructure needed for supporting this effort, we repurpose an existing commercial annotation tool, Prodigy, which we then enhance with additional components for combining the annotation tasks into pipelines, cross-validating the annotations and supporting annotator access to tasks.
Keyword Extraction, and Aspect Classification in Sinhala, English, and Code-Mixed ContentRizvi, Navojith, Adhikari, Senevirathna, Kasthurirathna, Abeywardhana (2025)Keyword extraction in English is performed with a hybrid approach comprising a fine-tuned spaCy NER model, FinBERT-based KeyBERT embeddings, YAKE, and EmbedRank, which results in a combined accuracy of 91.2%.
Assessing Fine-Tuned NER Models with Limited Data in French: Automating Detection of New Technologies, Technological Domains, and Startup Names in Renewable EnergyMacLean, Cavallucci (2024)In order to assure the uniformity of the process of fine-tuning each model, we decided to use the spaCy library. This library, one of the most widely used for NLP tasks, allows us to directly modify a simple configuration file in order to define the model.
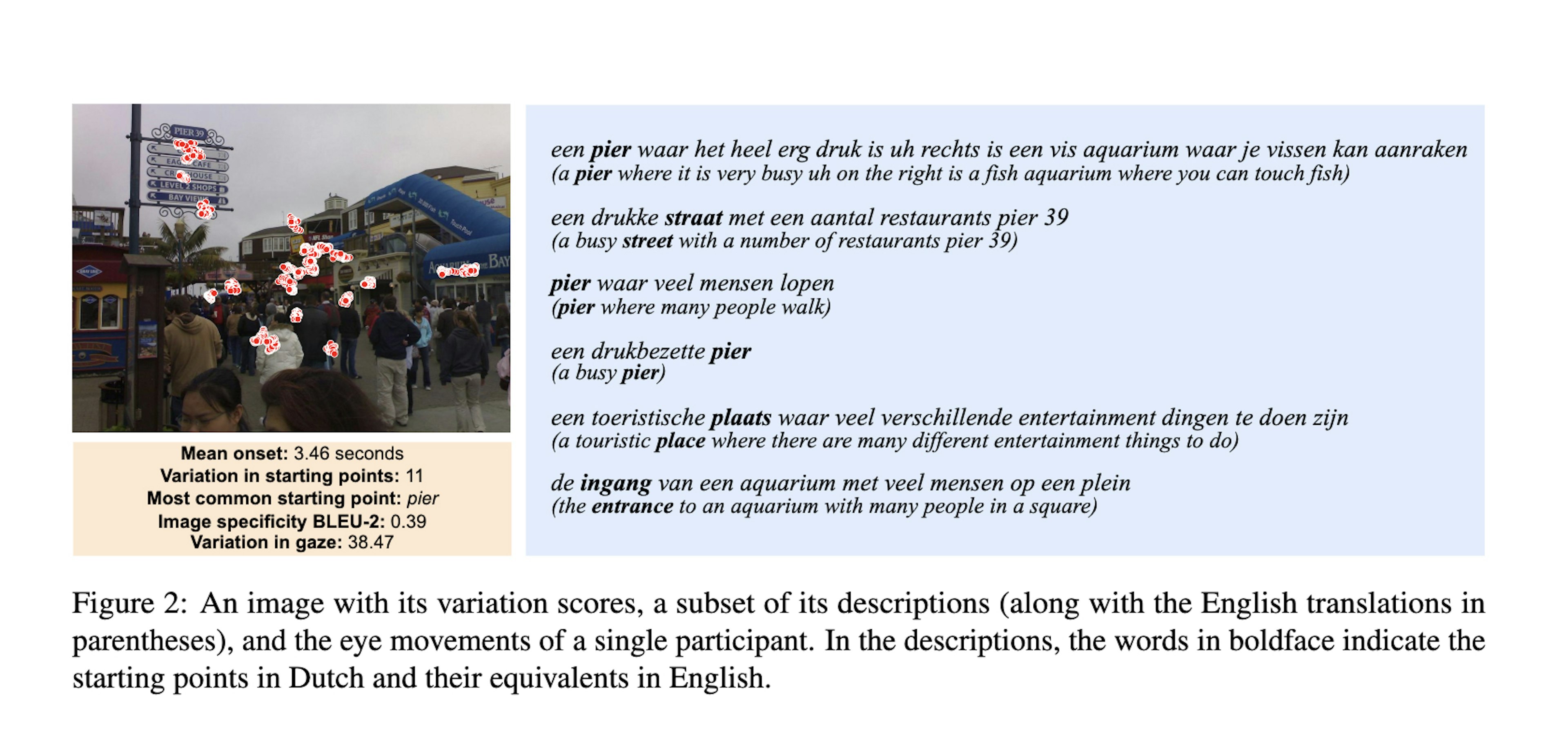
Describing Images Fast and Slow: Quantifying and Predicting the Variation in Human Signals during Visuo-Linguistic ProcessesTakmaz, Pezzelle, Fernández (2024)We use the spaCy library for tokenization, part-of-speech tagging, and lemmatization of the words in the descriptions.
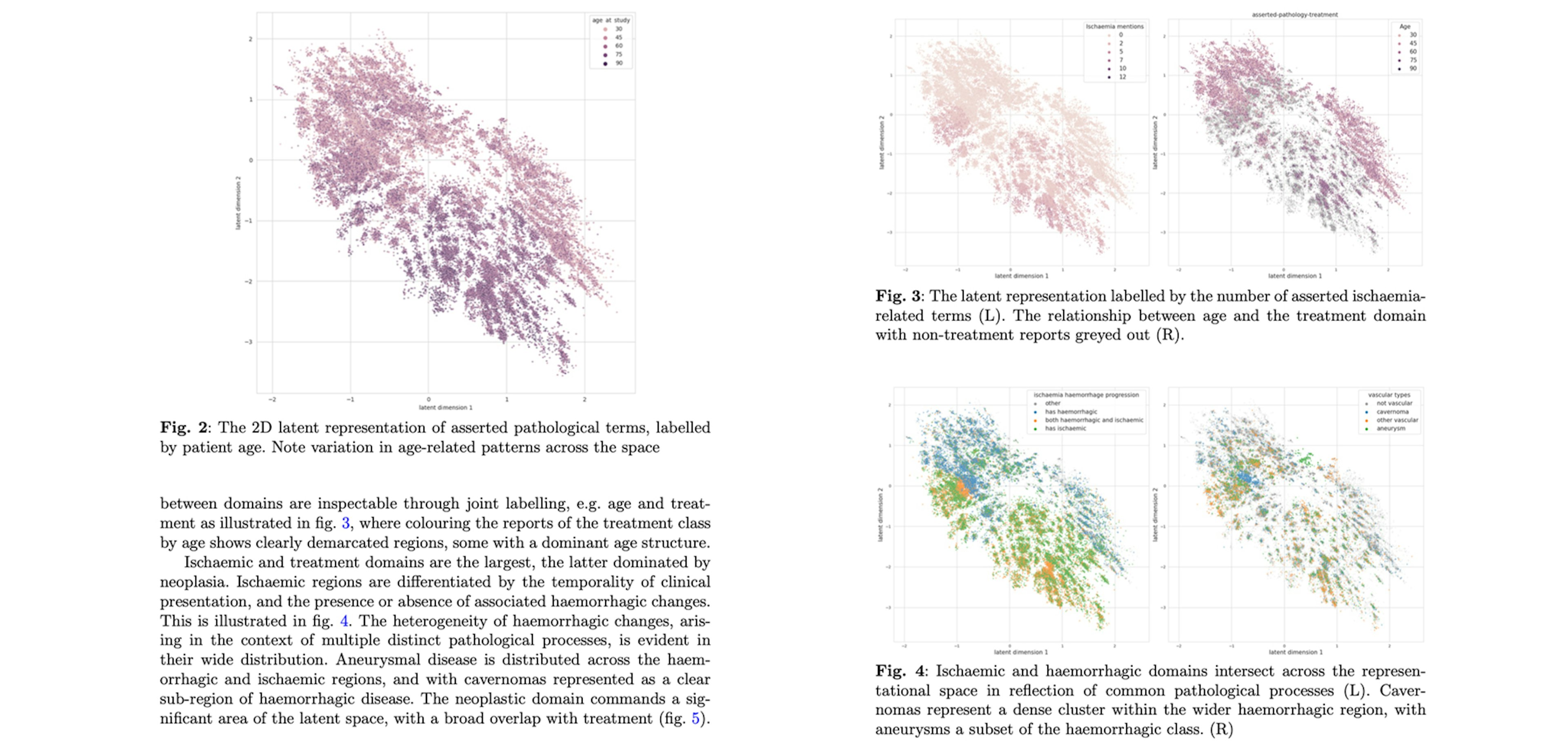
Neuradicon: operational representation learning of neuroimaging reportsWatkins, Gray, Julius, Mah, Pinaya, Wright, Jha, Engleitner, Cardoso, Ourselin, Rees, Jaeger, Nachev (2023)Labelled data for each task was produced using the Prodigy labelling tool. Each report was labelled in a paired-annotation manner. [...] We used the grammatical dependency parse produced by the spaCy parser as input and implemented the patterns using the spaCy dependency matcher.
GERNERMED++: Semantic annotation in German medical NLP through transfer-learning, translation and word alignmentFrei, Frei-Stuber, Kramer (2023), Journal of Biomedical InformaticsThe training of our entity recognition model employs the entity recognition parser from the spaCy library which follows a transducer-based parsing approach with a BILOU scheme instead of a state-agnostic token tagging approach.
Concepts and measures of bureaucratic constraints in European Union laws from hand-coding to machine-learningFranchino, Migliorati, Pagano, Vignoli (2023)The models “learn” the relations between the text tokens and the entity categories from two randomly selected samples of sentences that are extracted from a pre-processed corpus and have been manually annotated using the Python-implemented platform “Prodigy”.
Creating Custom Event Data Without Dictionaries: A Bag-of-TricksHalterman, Schrodt, Beger, Bagozzi, Scarborough (2023)While in the past the process of generating training case has been quite time consuming and tedious, newer approaches such as those incorporated into the web-based Prodigy annotation system allow this to be done much more quickly.
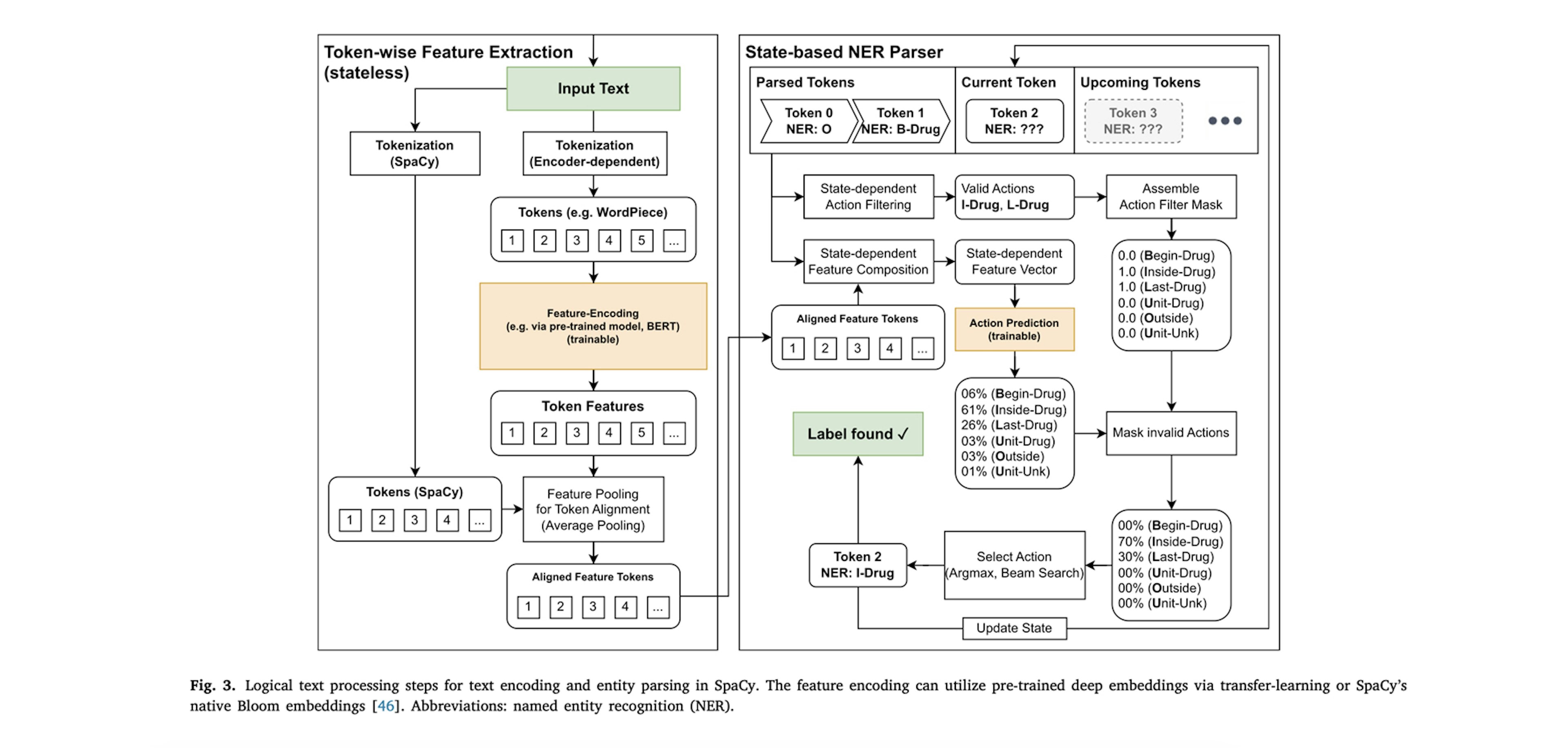
Multi hash embeddings in spaCyMiranda, Kádár, Boyd, Van Landeghem, Søgaard, Honnibal (2022)In this technical report we lay out a bit of history and introduce the embedding methods in spaCy in detail. Second, we critically evaluate the hash embedding architecture with multi-embeddings on Named Entity Recognition datasets from a variety of domains and languages. The experiments validate most key design choices behind spaCy’s embedders, but we also uncover a few surprising results.
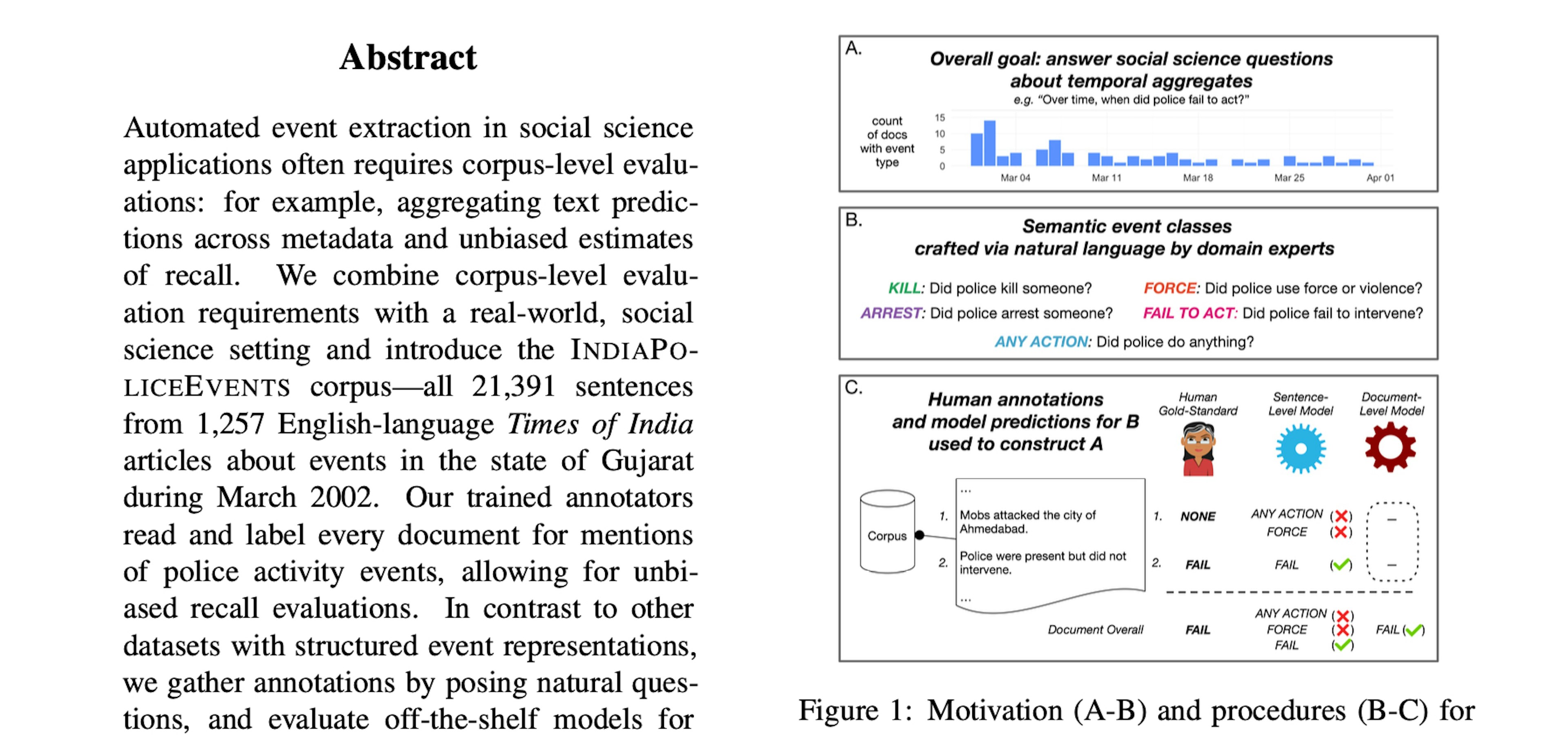
Corpus-Level Evaluation for Event QA: The IndiaPoliceEvents Corpus Covering the 2002 Gujarat ViolenceHalterman, Keith, Sarwar, O’Connor (2021), ACL 2021Figure A2 shows a stylized version of the custom interface we built using the Prodigy annotation tool. Annotators are presented with an entire document, with sentences sequentially highlighted.
A Century of Immigration Rhetoric in the UK ParliamentGennaro, Vissens, Thornewill von Essen, Ravalde, Egan, Dave, Dable, Facini (2026)With all annotated snippets, we trained two transformer-based classifiers, each using a spaCy pipeline consisting of a RoBERTa base transformer model and spaCy’s textcat (text categorisation) component.
Using natural language processing to identify emergency department patients with incidental lung nodules requiring follow-upMoore, Socrates, Hesami, Denkewicz, Cavallo, Venkatesh, Taylor (2025)CT reports were annotated by MD raters using Prodigy software to develop a stepwise NLP “pipeline” that first excluded prior or known malignancy, determined the presence of a lung nodule, and then categorized any recommended follow-up. NLP was developed using a RoBERTa large language model on the spaCy platform.
Toward Automatic Summarization of Hospital Discharge NotesLandes (2024)For NLP tasks, vectorizers include spaCy token features such as part of speech (POS) tags, named entity recognition (NER) tags, dependency head relations and depth.
Muted: Multilingual Targeted Offensive Speech Identification and VisualizationTillmann, Trivedi, Rosenthal, Borse, Zhang, Sil, Bhattacharjee (2023)Muted can leverage any transformer-based HAP-classification model [...] to identify toxic spans, without further fine-tuning. In addition, we use the spaCy library to identify the specific targets and arguments for the words predicted by the attention heatmaps.
Impoliteness and morality as instruments of destructive informal social control in online harassment targeting Swedish journalistsBjörkenfeldt, Gustafsson (2023)In the annotation tool Prodigy used for this process, the tweets directed towards journalists were displayed alongside the initial tweet that initiated the conversation thread and the subsequent reply from the journalist.
Toward a Critical Toponymy Framework for Named Entity Recognition: A Case Study of Airbnb in New York CityBrunila, LaViolette, CH-Wang, Verma, Féré, McKenzie (2023), EMNLP 2023All annotation was performed using Prodigy following an initial training session where annotators collaboratively annotated a randomly chosen set of samples.
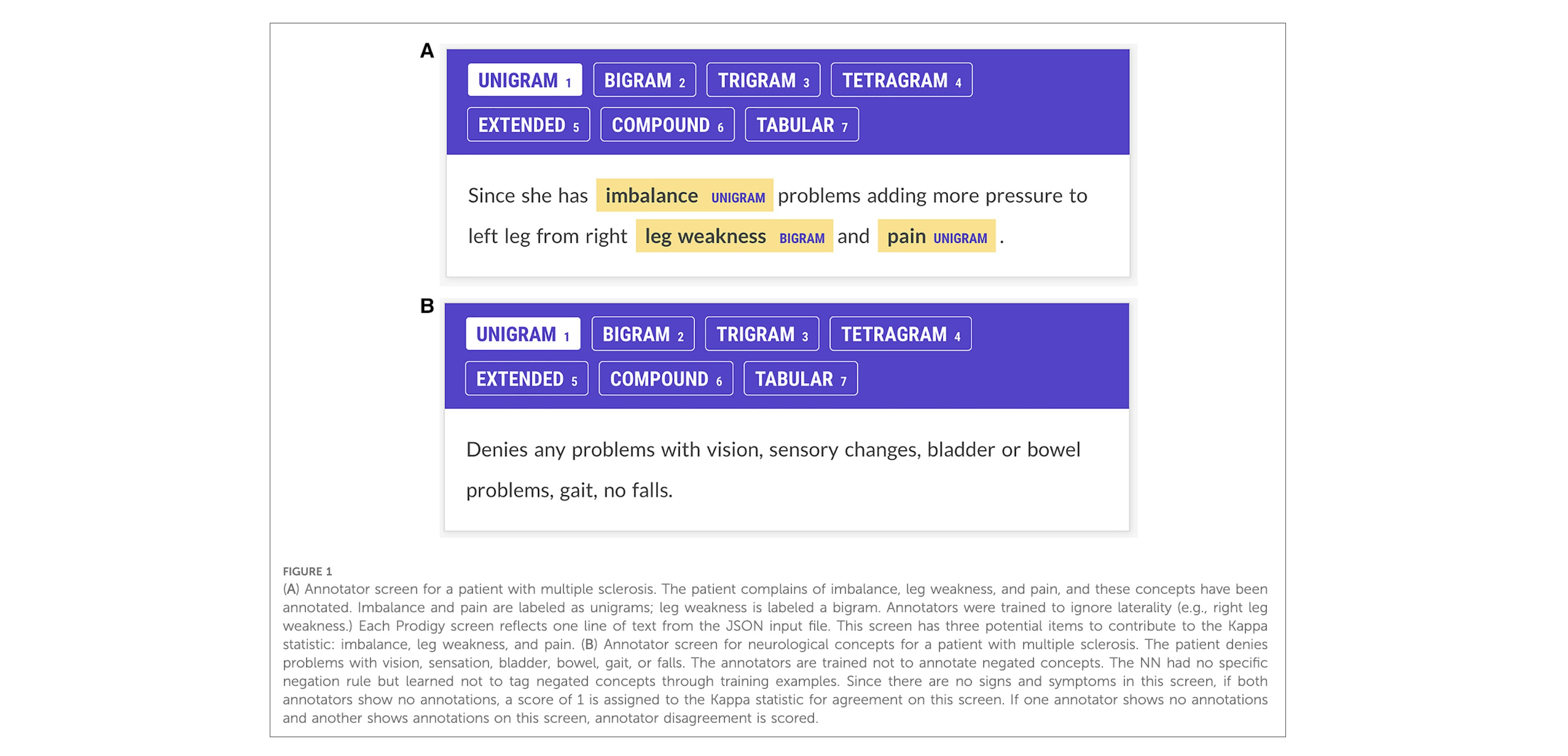
Inter-rater agreement for the annotation of neurologic signs and symptoms in electronic health recordsOommen, Howlett-Prieto, Carrithers, Hier (2023)Prodigy was used to annotate neurologic concepts in the EHR physician notes.
Slovak Dataset for Multilingual Question AnsweringHládek, Staš, Juhár, Koctúr (2023)We used the Prodigy annotation tool to annotate the questions and answers. One annotation task corresponds to one web application deployment and different configurations.
The triangulation of ethical leader signals using qualitative, experimental, and data science methodsBanks, Ross, Toth, Tonidandel, Goloujeh, Dou, Wesslen (2022)This additional text was labeled by the same coding team using Prodigy, [...] a flexible user interface tool built on top of spaCy, a leading open source library in python for natural language processing. We created a spaCy end‐to‐end project workflow including package versioning, data pre‐processing, data ingestion into a database, annotation sessions using Prodigy’s user interface, model training, model evaluation, python packaging, and visual app for testing the model.
Identifying Predictors of Suicide in Severe Mental Illness: A Feasibility Study of a Clinical Prediction RuleSenior, Burghart, Yu, Kormilitzin, Liu, Vaci, Nevado-Holgado, Pandit, Zlodre, Fazel (2020)The named entity recognition model was developed in two phases: 1) training with“gold-standard” annotations collected with GATE and 2) model fine-tuning with Prodigy—an active learning-based annotation tool.
RiCoRecA: rich cooking recipe annotation schemaVentirozos, Jacob-Romero, Alrdahi, Clinch, Batista-Navarro (2026)The annotation process consists of two sections. Firstly, the annotator utilized a customized Prodigy interface to complete the NER and RC annotation tasks.
Recognising non-named spatial entities in literary texts: a novel spatial entities classifierKababgi, Grisot, Pennino, Herrmann (2024)In this paper, we present a case study on the prediction of what we call ‘non-named spatial entities’ (NNSE) in a historical corpus of Swiss-German novels using a deep learning model in conjunction with BERT and Prodigy.
The application of natural language processing for the extraction of mechanistic information in toxicologyConradi, Luechtefeld, de Haan, Pieters, Freedman, Vanhaecke, Vinken, Teunis (2024)All steps were conducted using the open-source Python package spaCy. Specifically, the NER model was trained using scispaCy en-core-sci-lg (Neumann et al., 2019) as a starting point, which allowed for a vocabulary (word vectors) and grammar trained on scientific literature.
DeepZensols: A Deep Learning Natural Language Processing Framework for Experimentation and ReproducibilityLandes, Di Eugenio, Caragea (2023)A linguistic feature mapper that translates spaCy to wordpieces, which are token sub-units with associated vectors, is also accessible as an easy to configure module.
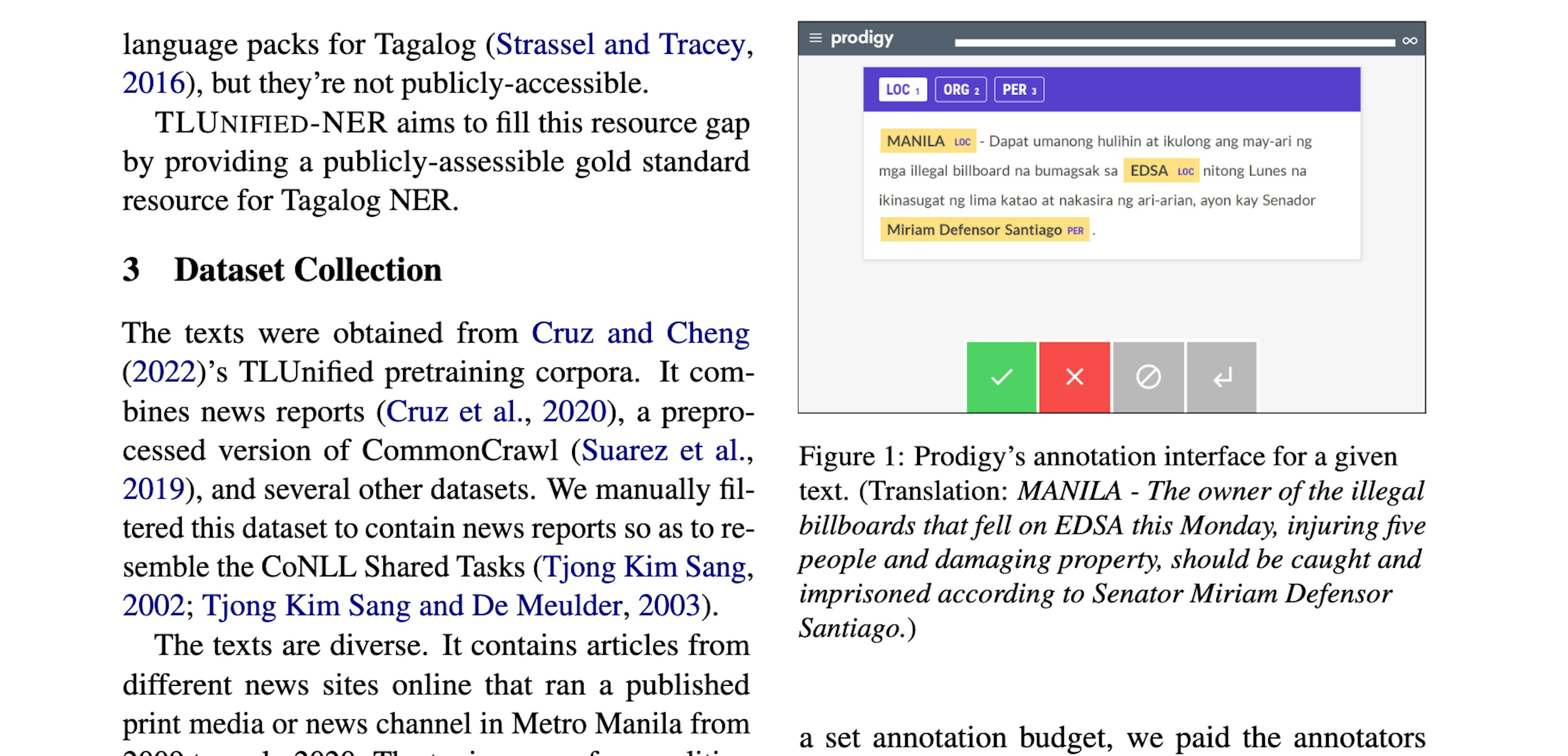
calamanCy: A Tagalog Natural Language Processing ToolkitMiranda (2023), EMNLP 2023We introduce calamanCy, an open-source toolkit for constructing NLP pipelines for Tagalog. It is built on top of spaCy, enabling easy experimentation and integration with other frameworks.
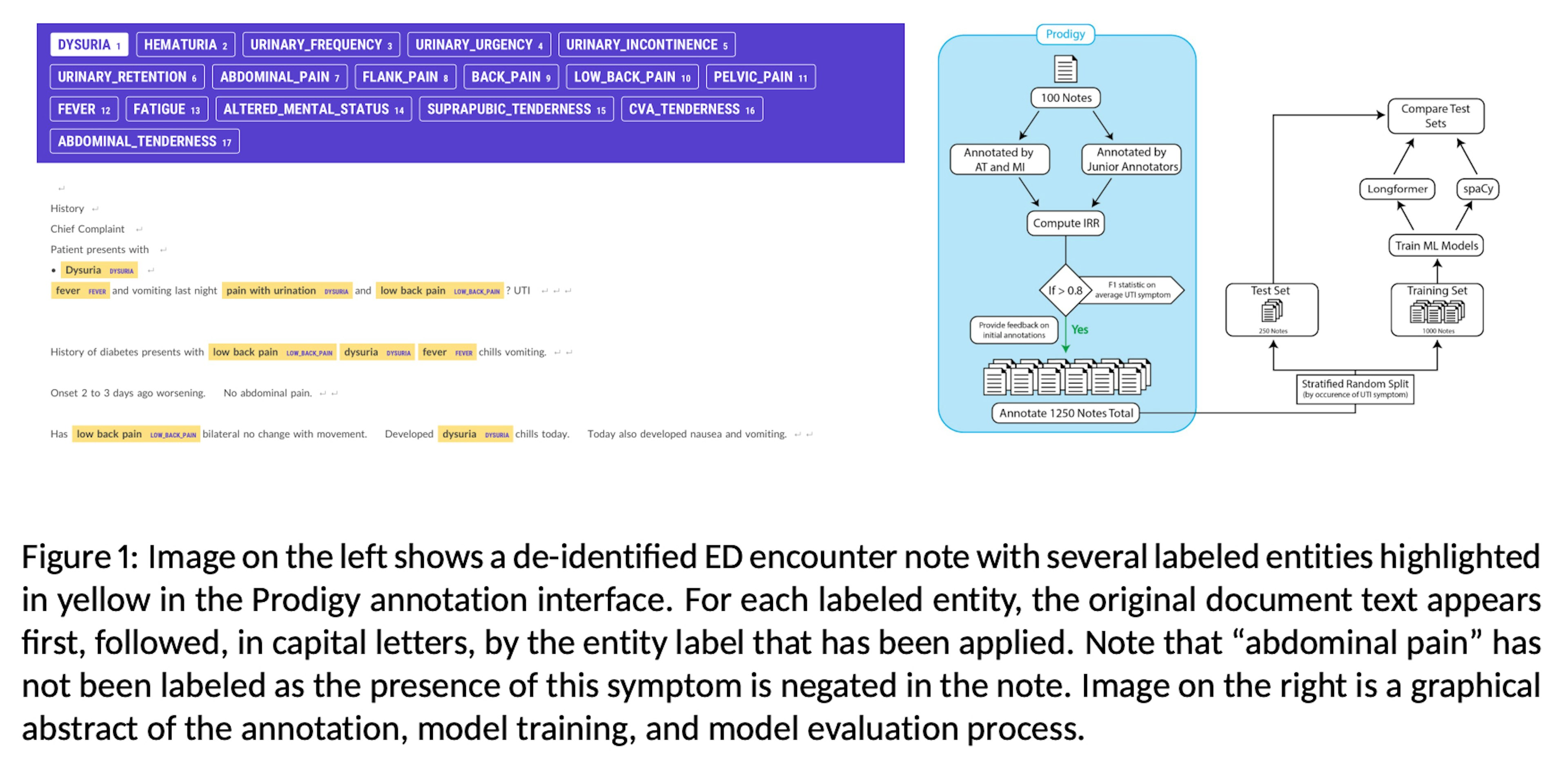
Identifying Signs and Symptoms of Urinary Tract Infection from Emergency Department Clinical Notes Using Large Language ModelsIscoe, Socrates, Gilson, Chi, Li, Huang, Kearns, Perkins, Khandjian, Taylor (2023)For annotation we employed Prodigy, a scriptable annotation tool designed to maximize efficiency, enabling data scientists to perform the annotation tasks themselves and facilitating rapid iterative development in natural language processing (NLP) projects.
How Good is the Model in Model-in-the-loop Event Coreference Resolution Annotation?Ahmed, Nath, Regan, Pollins, Krishnaswamy, Martin (2023)Figure 6 illustrates the interface design of the annotation methodology on the popular model-in-the-loop annotation tool - Prodigy. We use this tool for the simplicity it offers in plugging in the various ranking methods we explained.
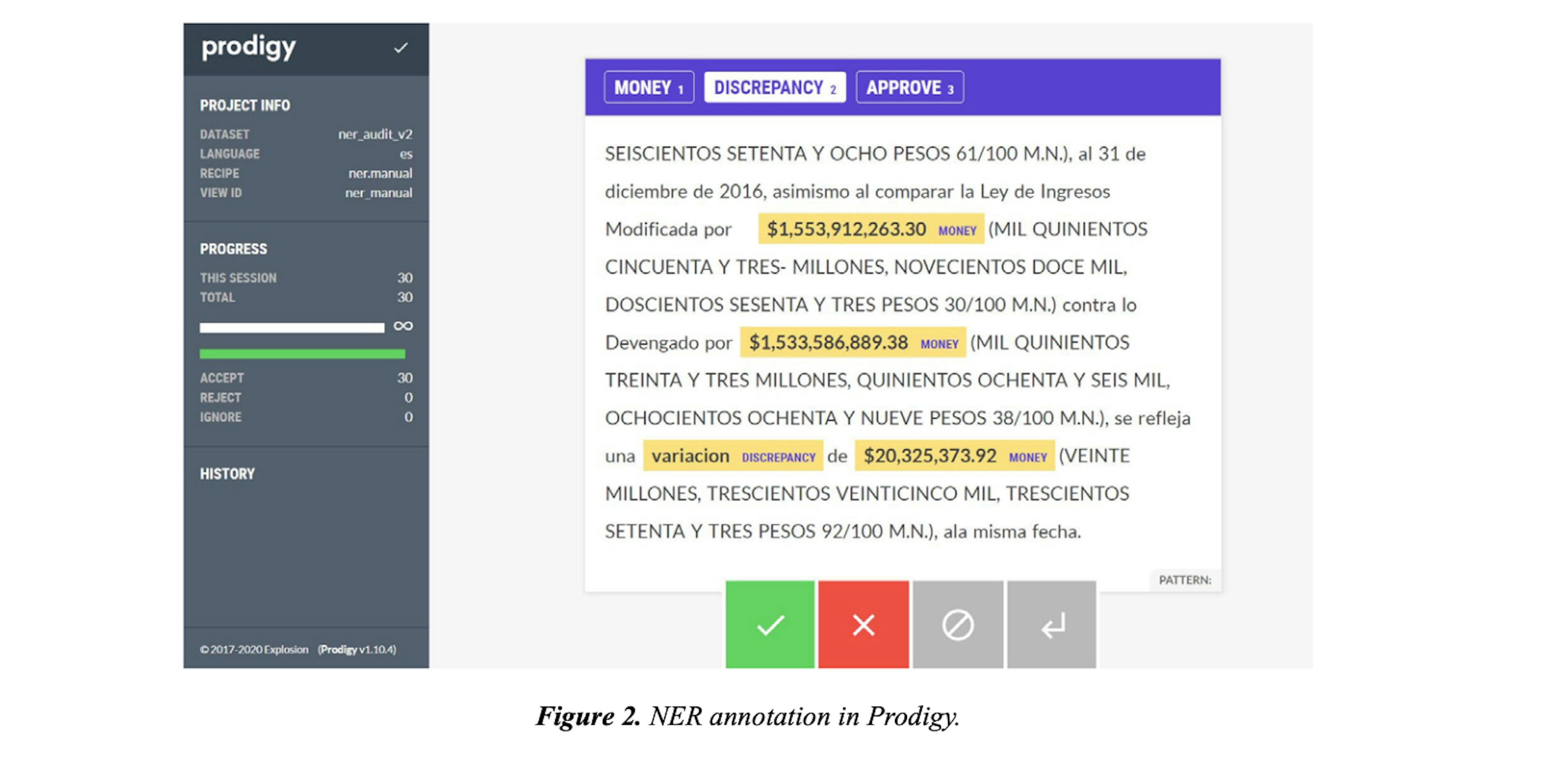
Fiscal data in text: Information extraction from audit reports using Natural Language ProcessingBeltran (2023), Data & Policy, Cambridge University PressI relied on the text annotation software Prodigy in Python that offers a friendly user interface where the reviewer can read the text and assign a label to each paragraph.
Speech acts in the Dutch COVID-19 Press ConferencesSchueler, Marx (2022), Language Resources and EvaluationWe used the annotation tool Prodigy. Prodigy provides a simple interface in which the annotator sees a sentence and selects the applicable speech acts. The use of Prodigy considerably sped up the annotation process, allowing the annotators to annotate around 200 sentences per hour.
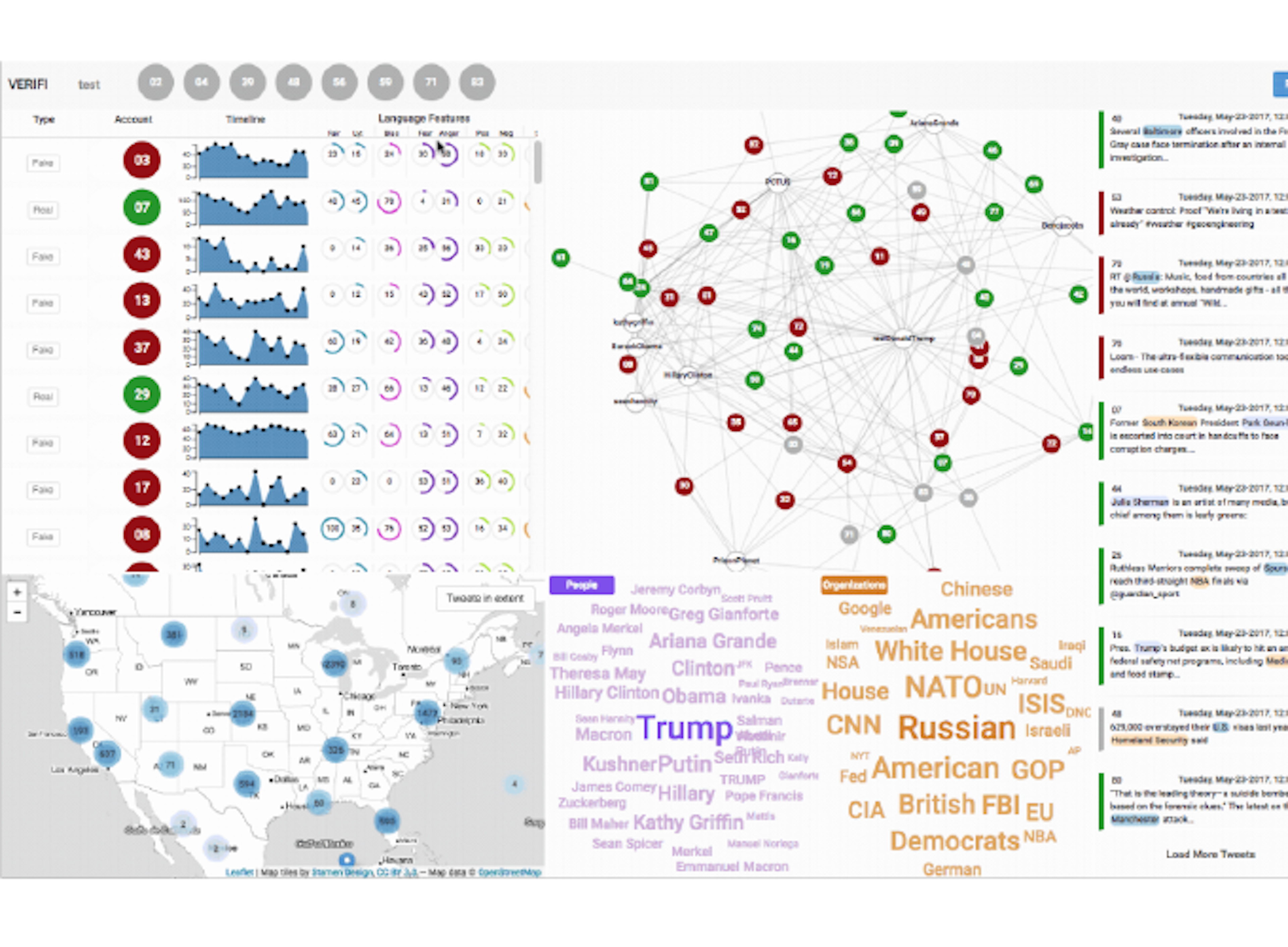
Can You Verifi This? Studying Uncertainty and Decision-Making About MisinformationKarduni, Wesslen, Santhanam, Cho, Volkova, Arendt, Shaikh, Dou (2018)HCI interface to identify misinformation on social media using spaCy for NER.
E^2GraphRAG: Streamlining Graph-based RAG for High Efficiency and EffectivenessZhao, Zhu, Guo, He, Li (2025)Instead of using LLMs for entity extraction, we employ the traditional NLP tool spaCy to extract entities, and use their co-occurrence in a chunk as relations.
uOttawa at LegalLens-2024: Transformer-based Classification ExperimentsMeghdadi, Inkpen (2024)Our training utilizes the spaCy pipeline configured with a transformer model and a transition-based parser for NER tasks. The deberta-v3-base model has been selected for the main transformer architecture.
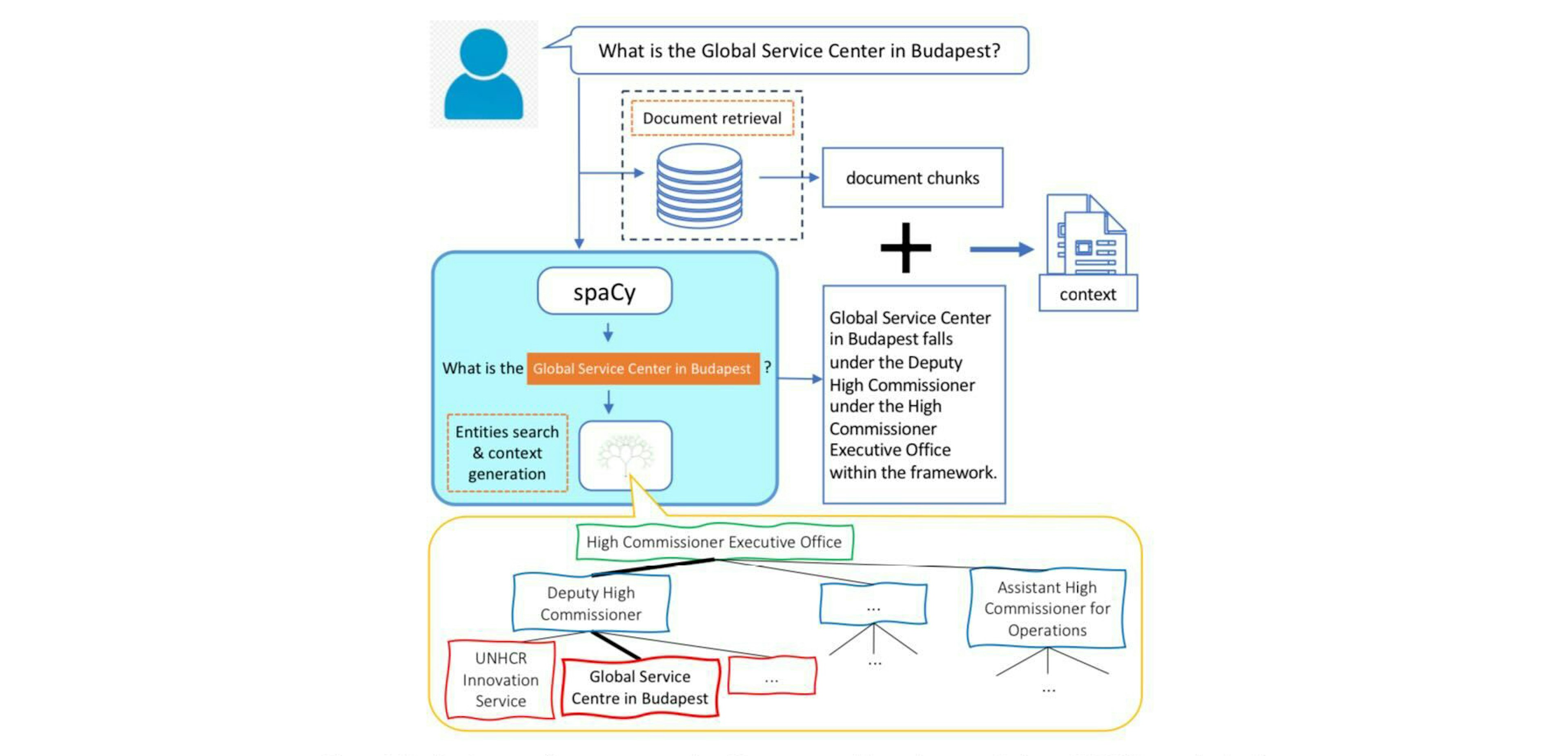
T-RAG: Lessons from the LLM TrenchesFatehkia, Lucas, Chawla (2024)An important application area is question answering over private enterprise documents where the main considerations are data security, which necessitates applications that can be deployed on-prem, [and] limited computational resources. [...] In addition to retrieving contextual documents, we use the spaCy library with custom rules to detect named entities from the organization.
On the Creation of Classifiers to Support Assessment of E-PortfoliosGantikow, Isking, Libbrecht, Müller, Rebholz (2023)In this workflow, Prodigy selects and presents text examples that were classified with a very low degree of certainty. The annotator reviews the proposed classifications and corrects them, if necessary.
Developing a Named Entity Recognition Dataset for TagalogMiranda (2023), IJCNLP-AACL 2023We used Prodigy as our annotation tool. We set up a web server on the Google Cloud Platform and routed the examples through Prodigy’s built-in task router.
Into the Single Cell Multiverse: an End-to-End Dataset for Procedural Knowledge Extraction in Biomedical TextsDannenfelser, Zhong, Zhang, Yao (2023), NeurIPSTissue, cell type, tool, and method were annotated using the Prodigy software tool developed by Explosion AI for easy tracking of token-level tags.
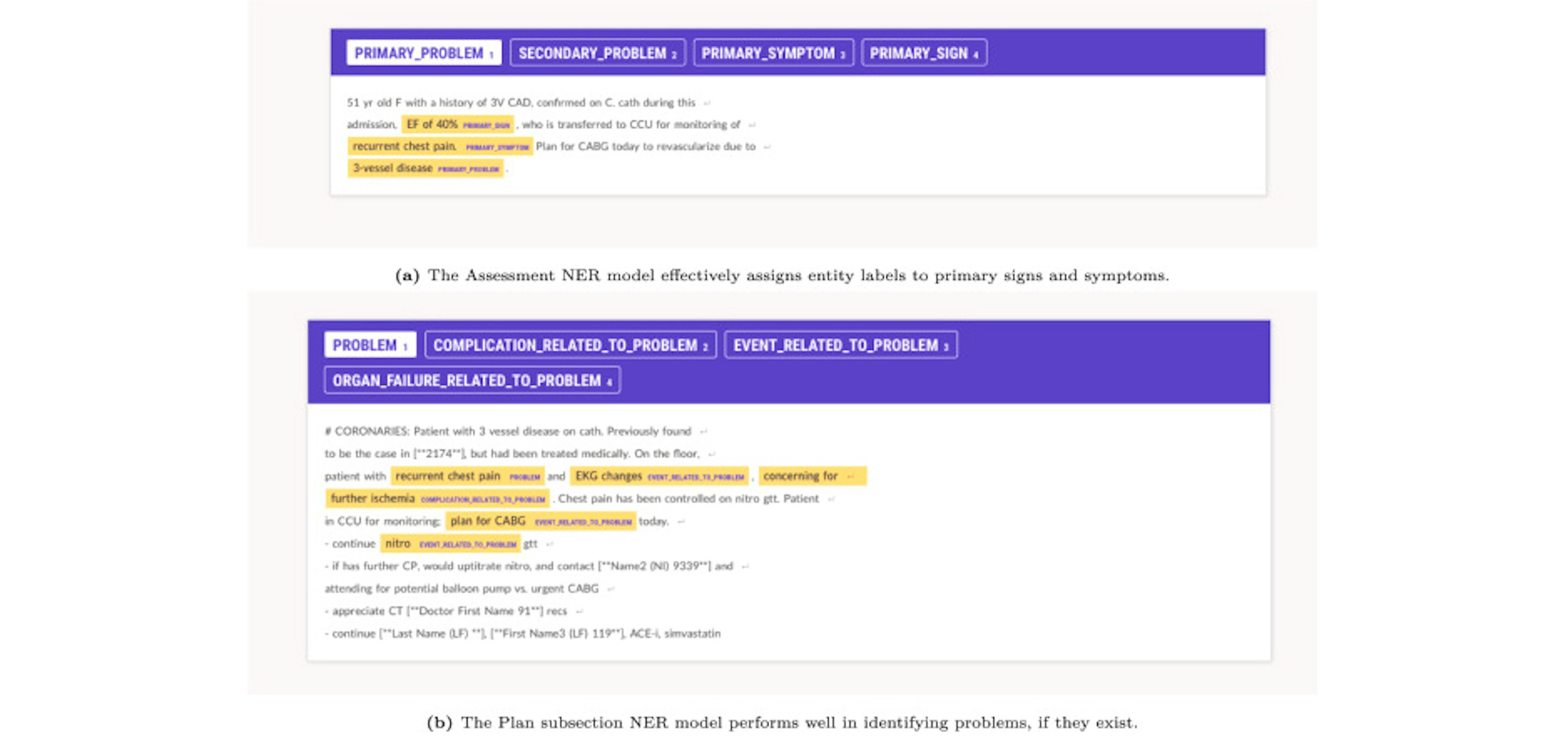
Predicting relations between SOAP note sections: The value of incorporating a clinical information modelSocrates, Gilson, Lopez, Chi, Taylor, Chartash (2023), Journal of Biomedical InformaticsTo support human annotation, we first annotate 100 Assessment and Plan subsections manually using Prodigy, and then use spacy-transformers to fine-tune a general domain RoBERTa-base model pretrained on OntoNotes 5 for both the Assessment and Plan section NER tagging.
Extracting Structured Information from Greek Legislation DataAlexios (2023)Worth noting is the existence of an application, called Prodigy, which takes advantage of an active learning framework and provides users with an interactive interface for data annotation.
Automated Identification of Clinical Procedures in Free-Text Electronic Clinical Records with a Low-Code Named Entity Recognition WorkflowMacri, Teoh, Bacchi, Sun, Selva, Casson, Chan (2022), Methods of Information in MedicineThe use of a low-code annotation software tool [Prodigy] allows the rapid creation of a custom annotation dataset to train a NER model to identify clinical procedures stored in free-text electronic clinical notes.