Explosion builds developer tools for AI, Machine Learning and Natural Language Processing. →
Consulting
Consulting





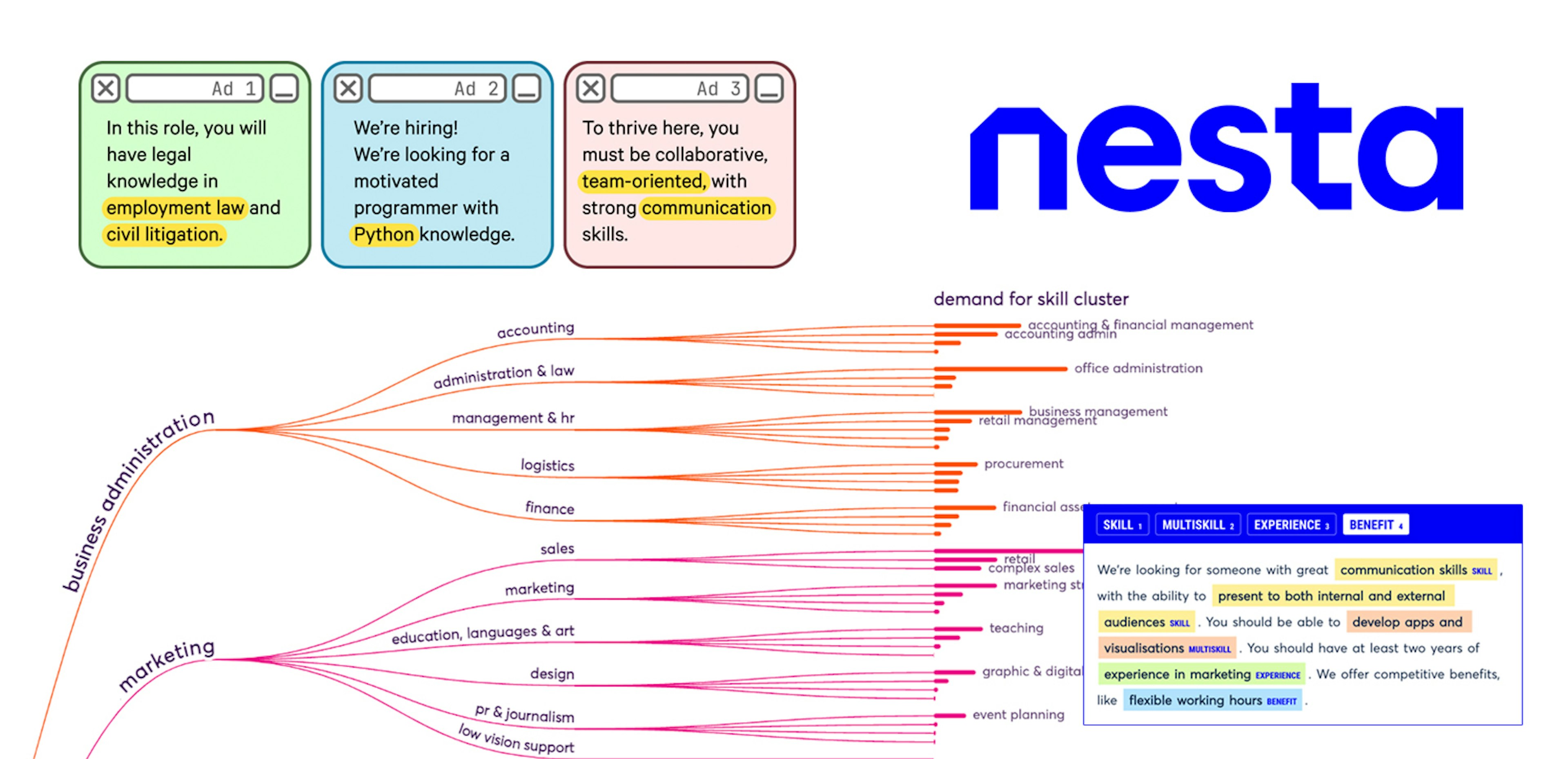
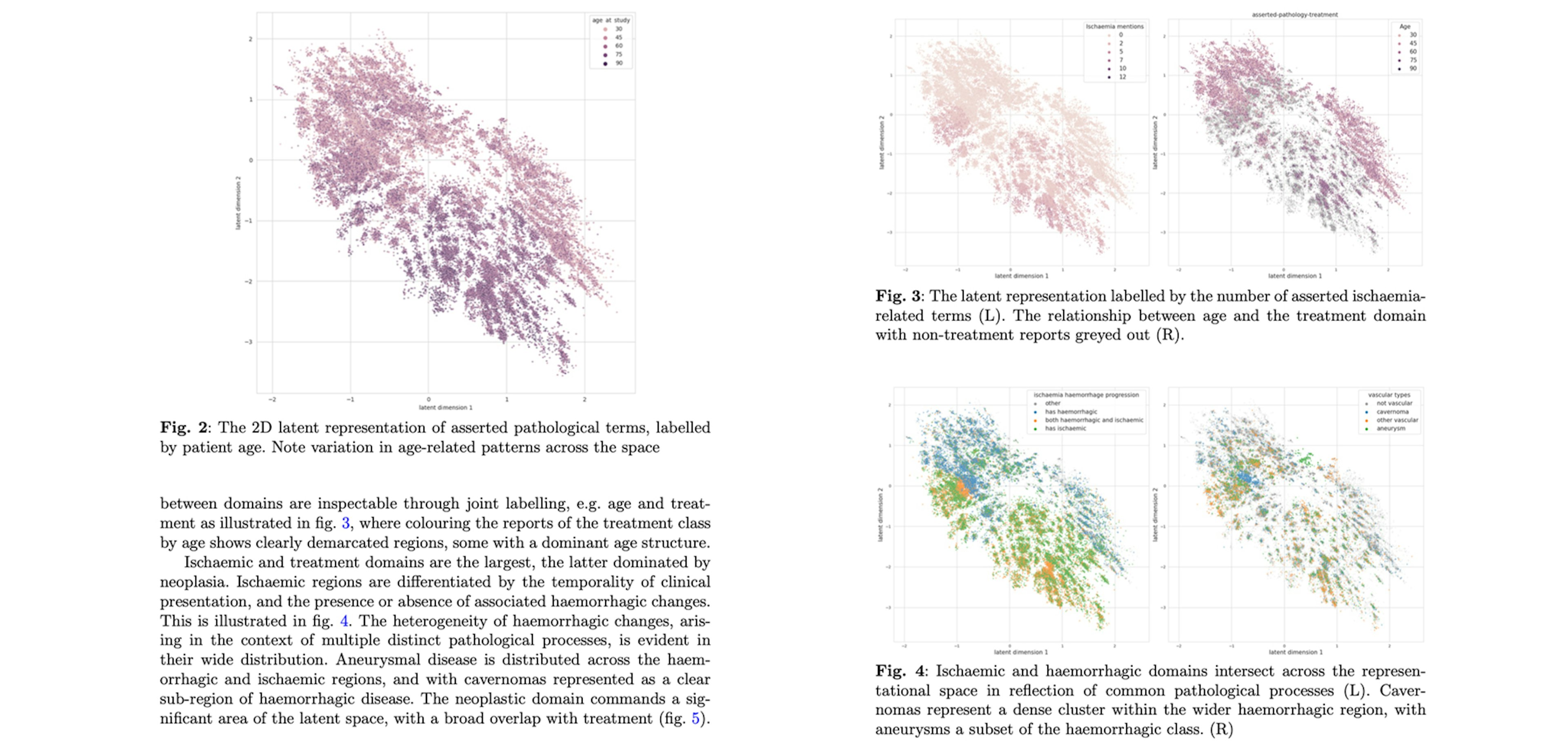





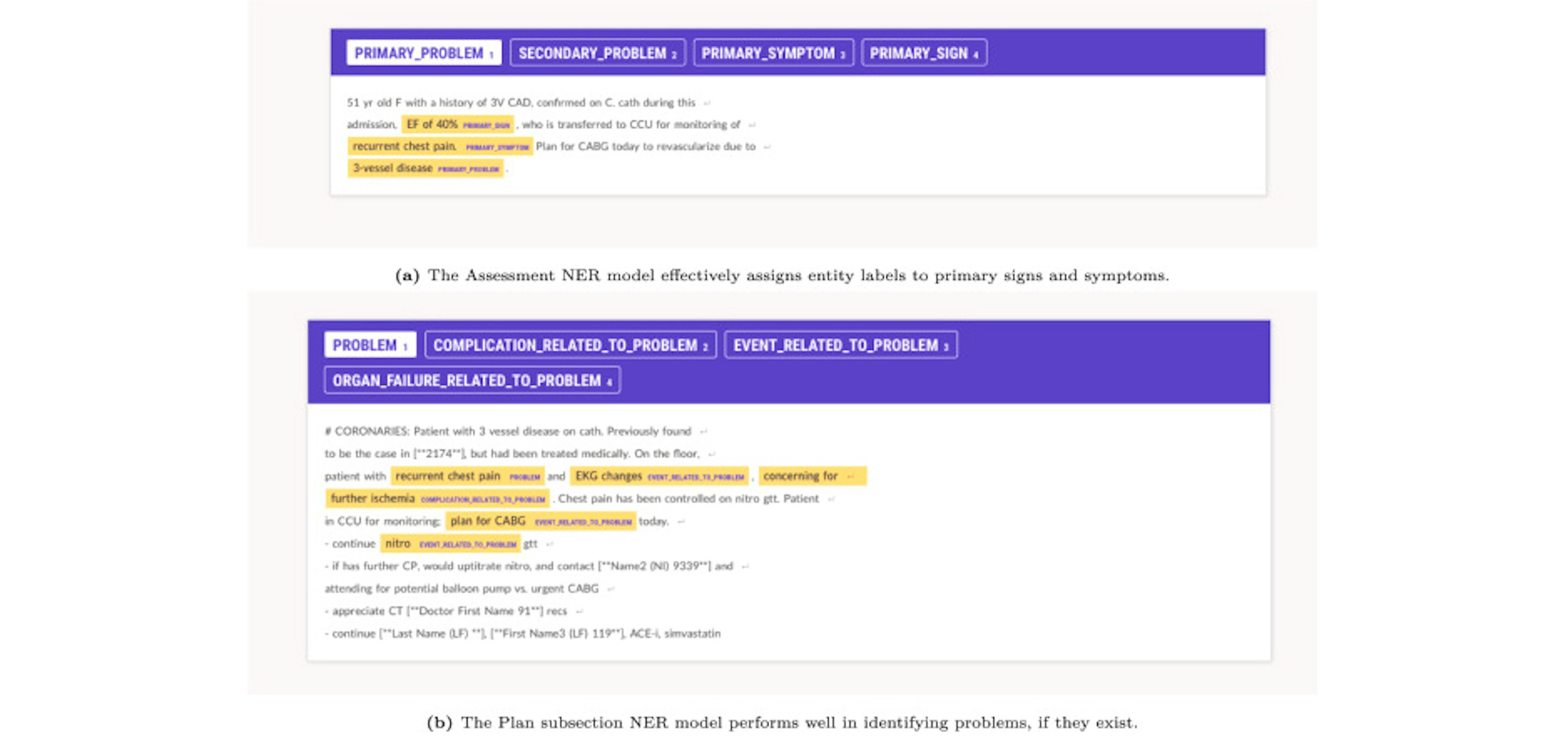
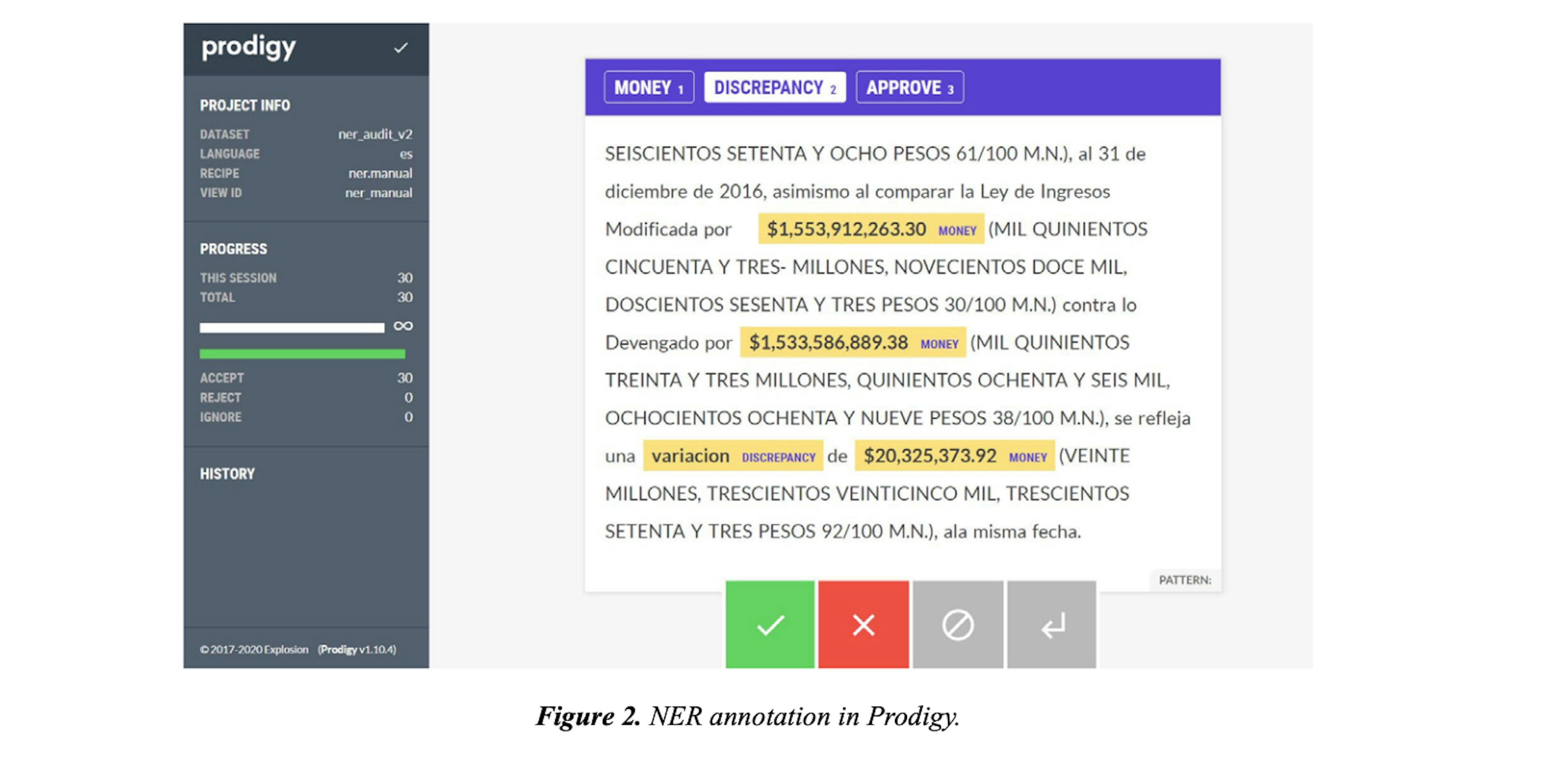
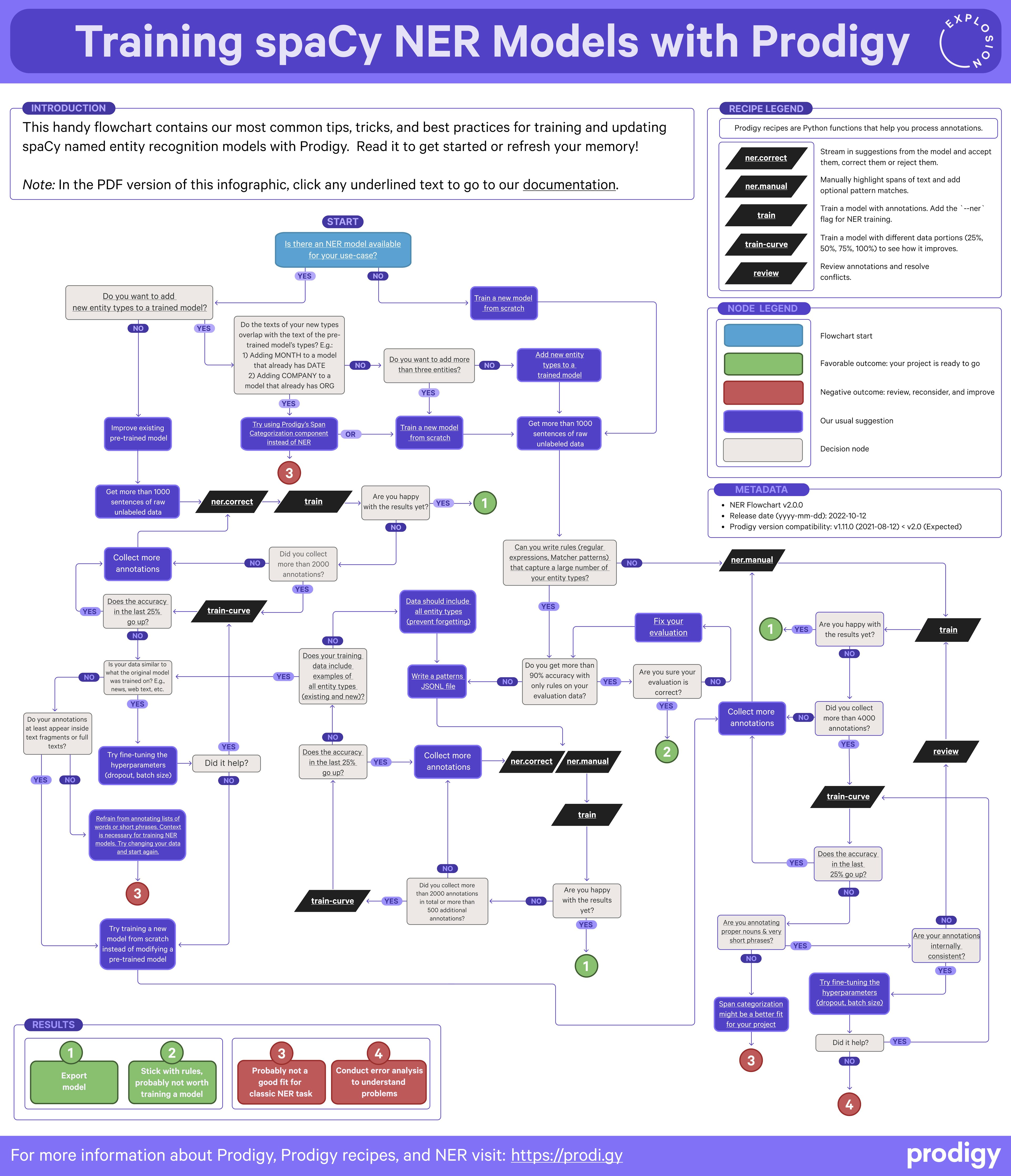








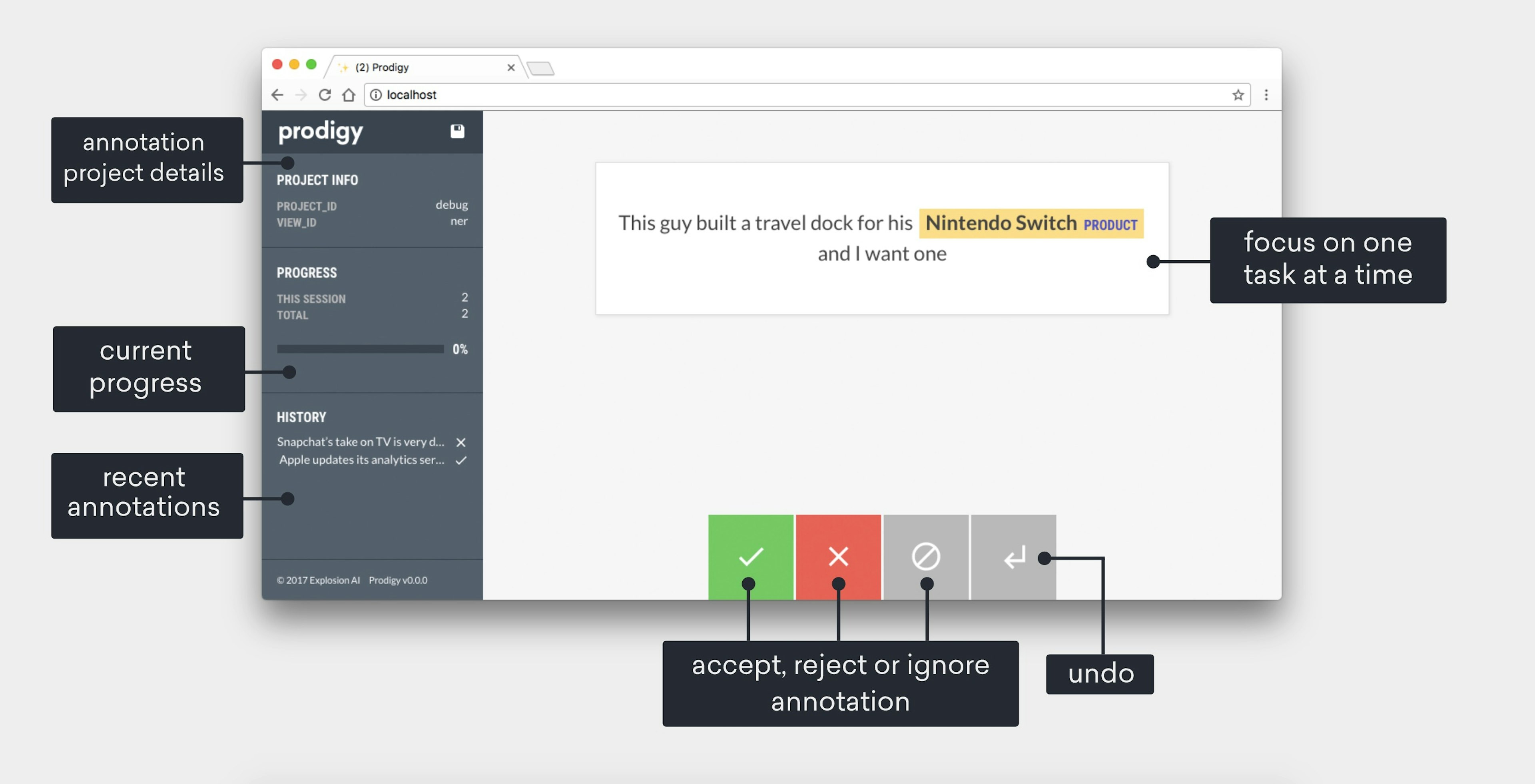







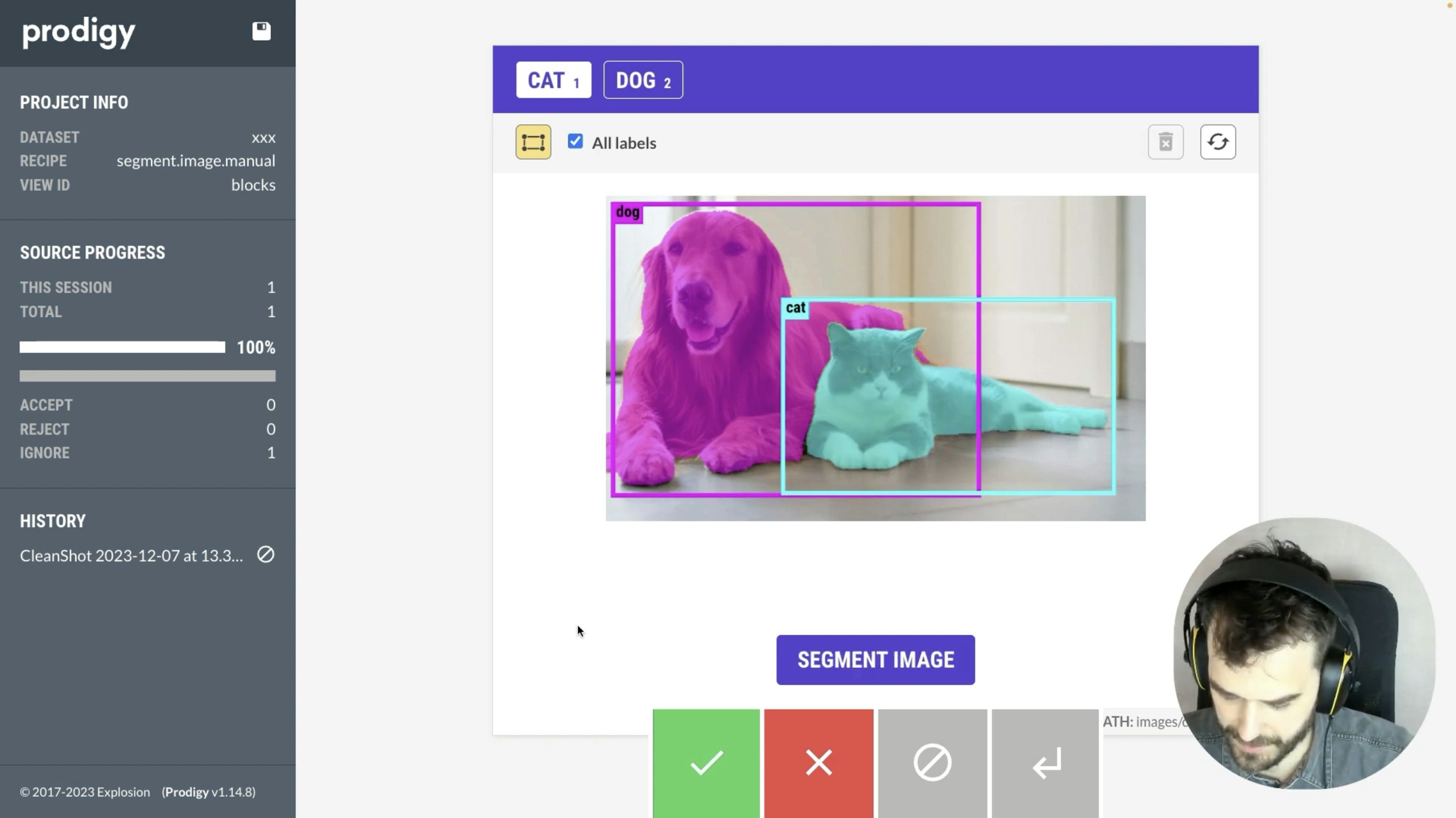


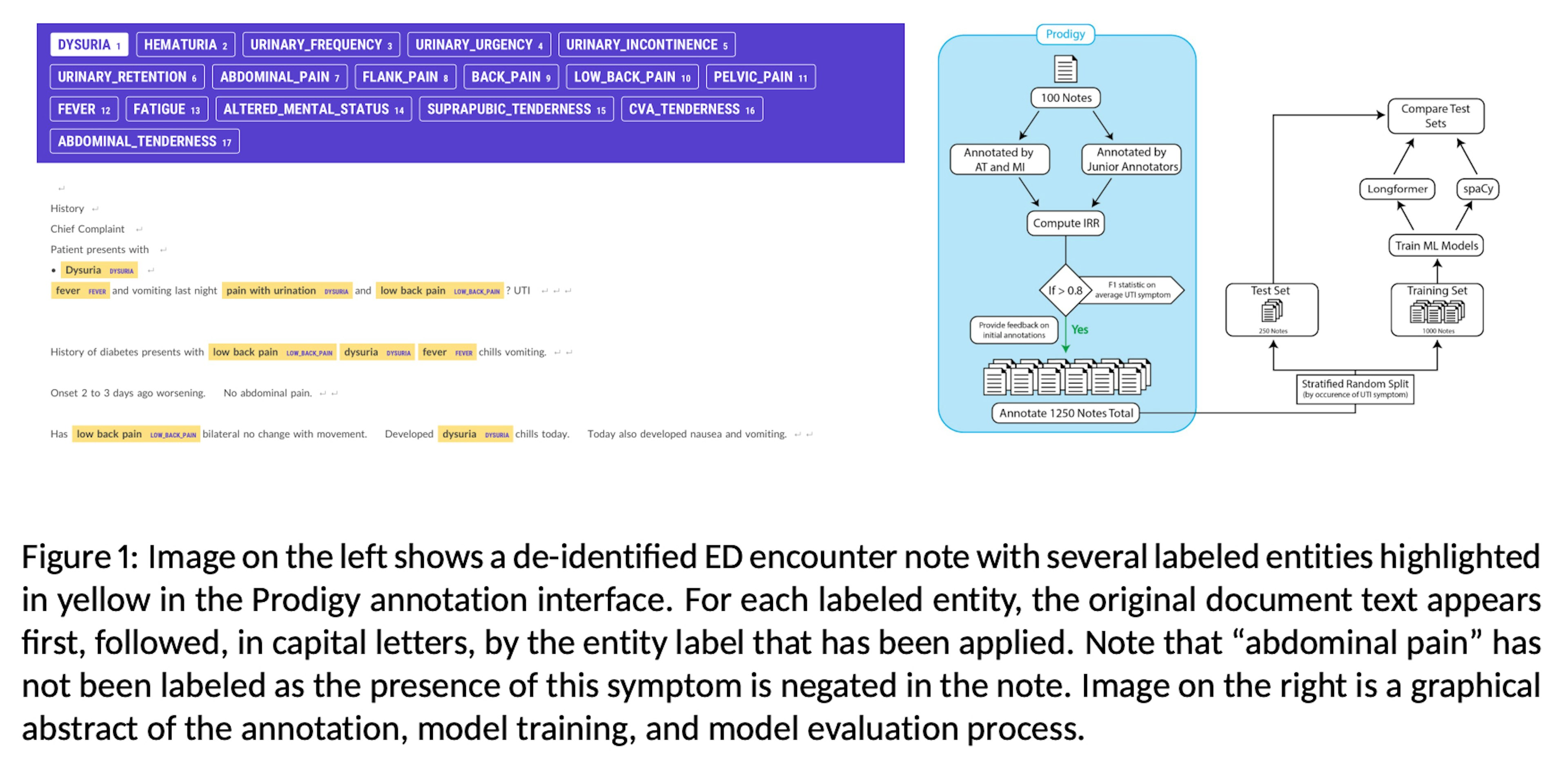
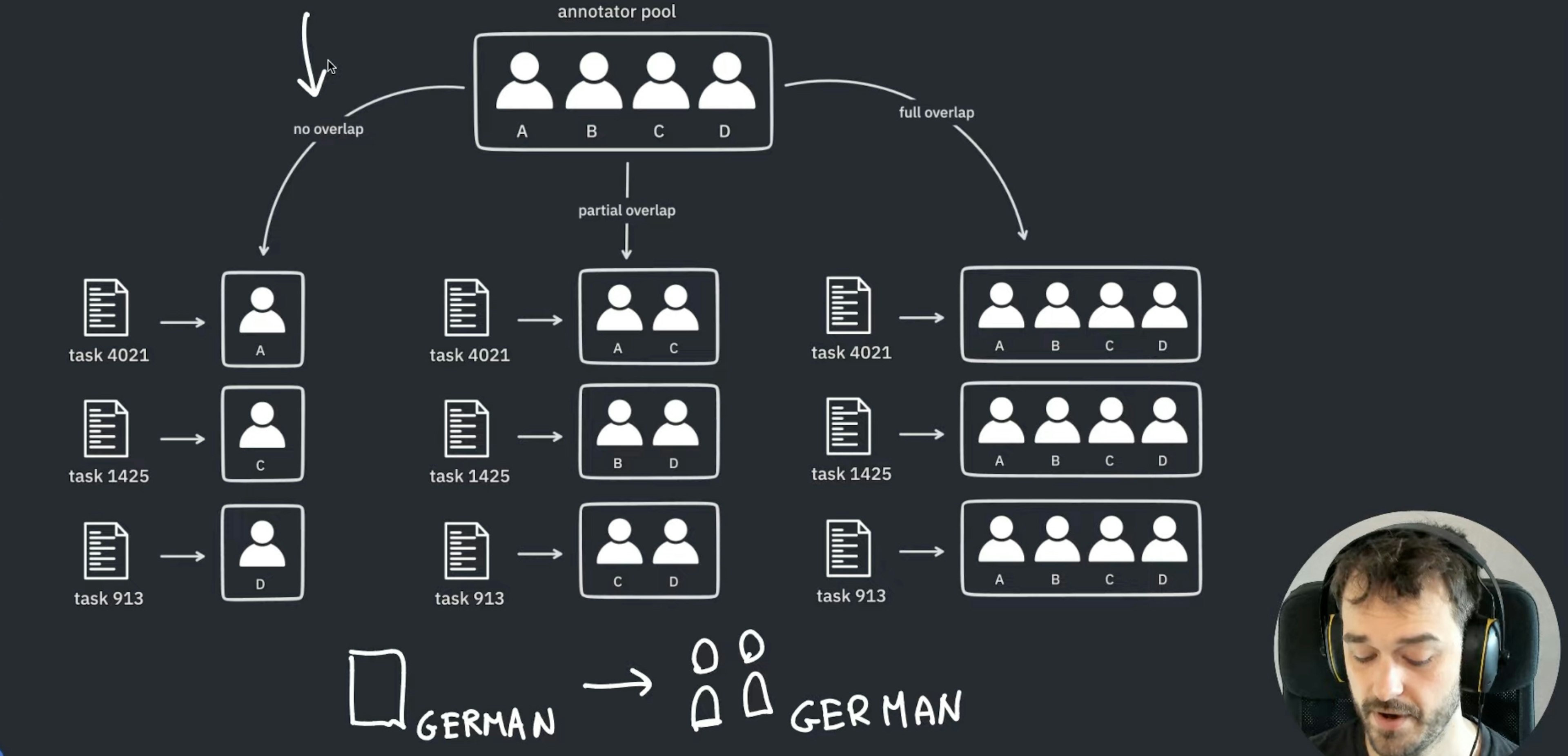
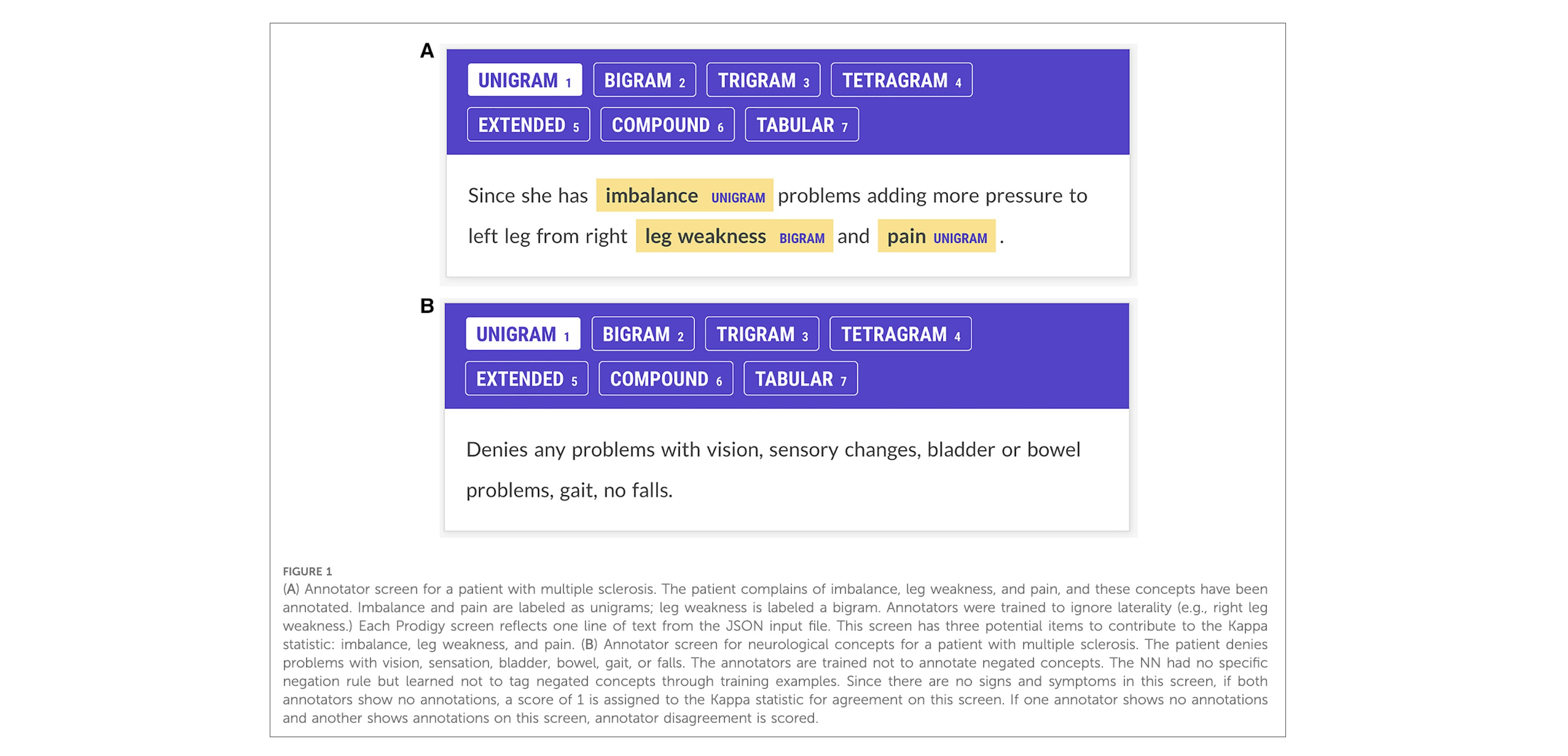
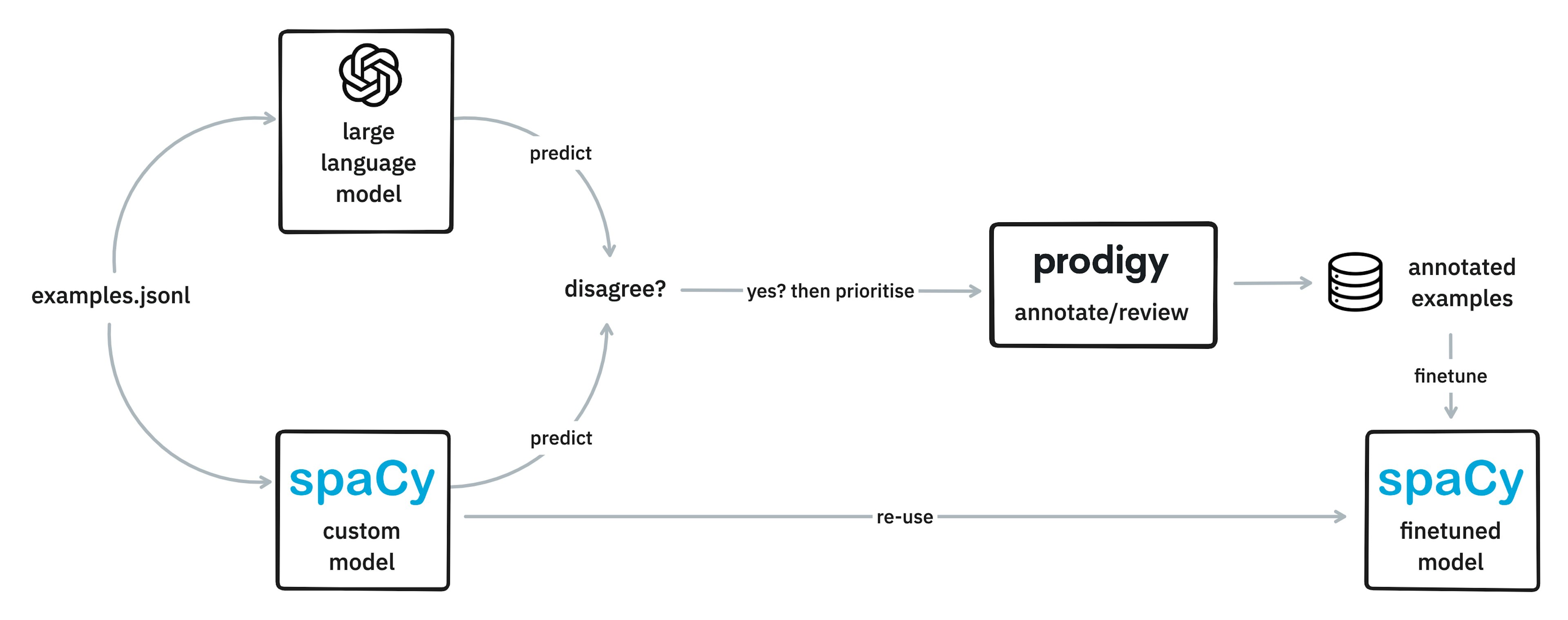

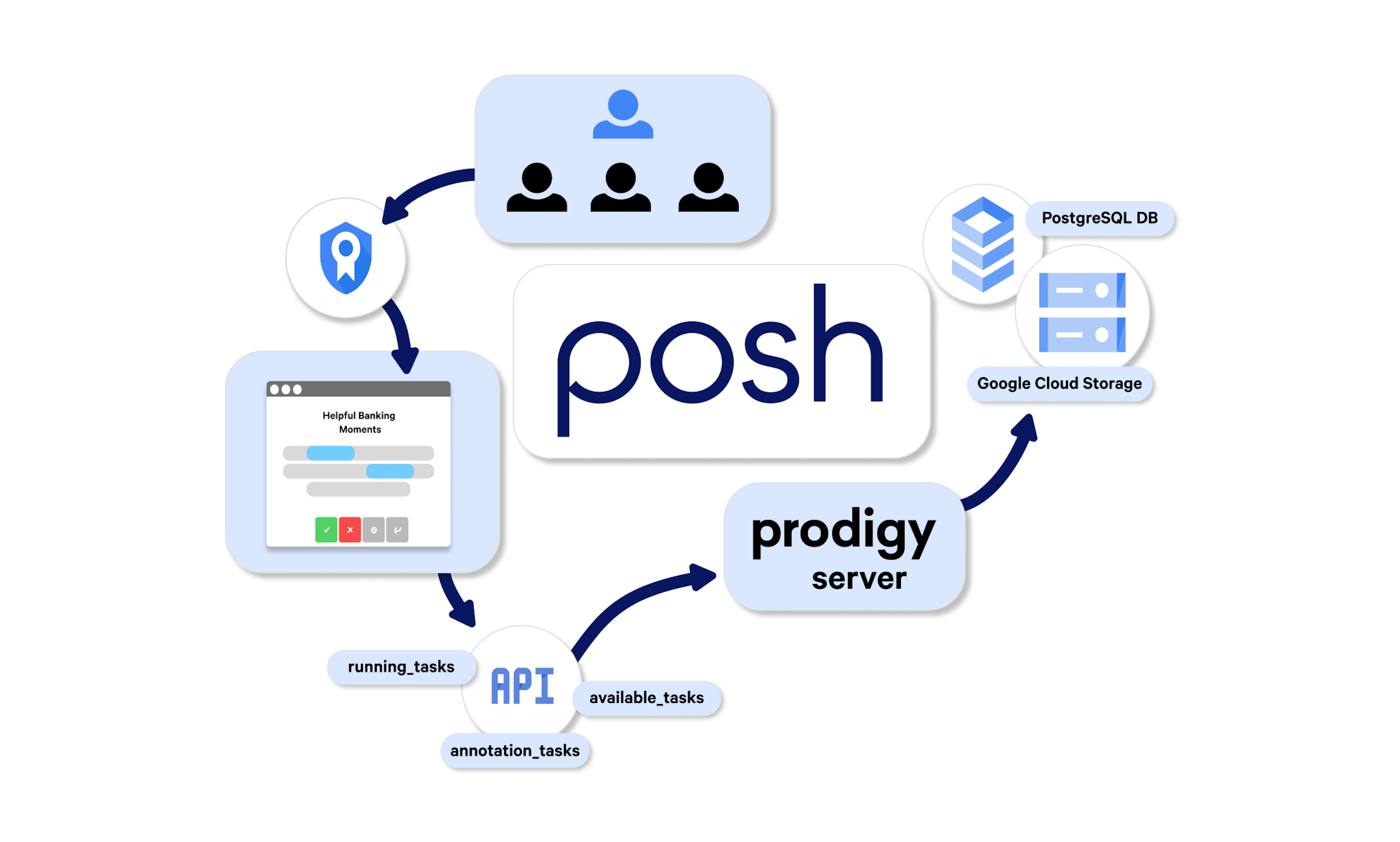

















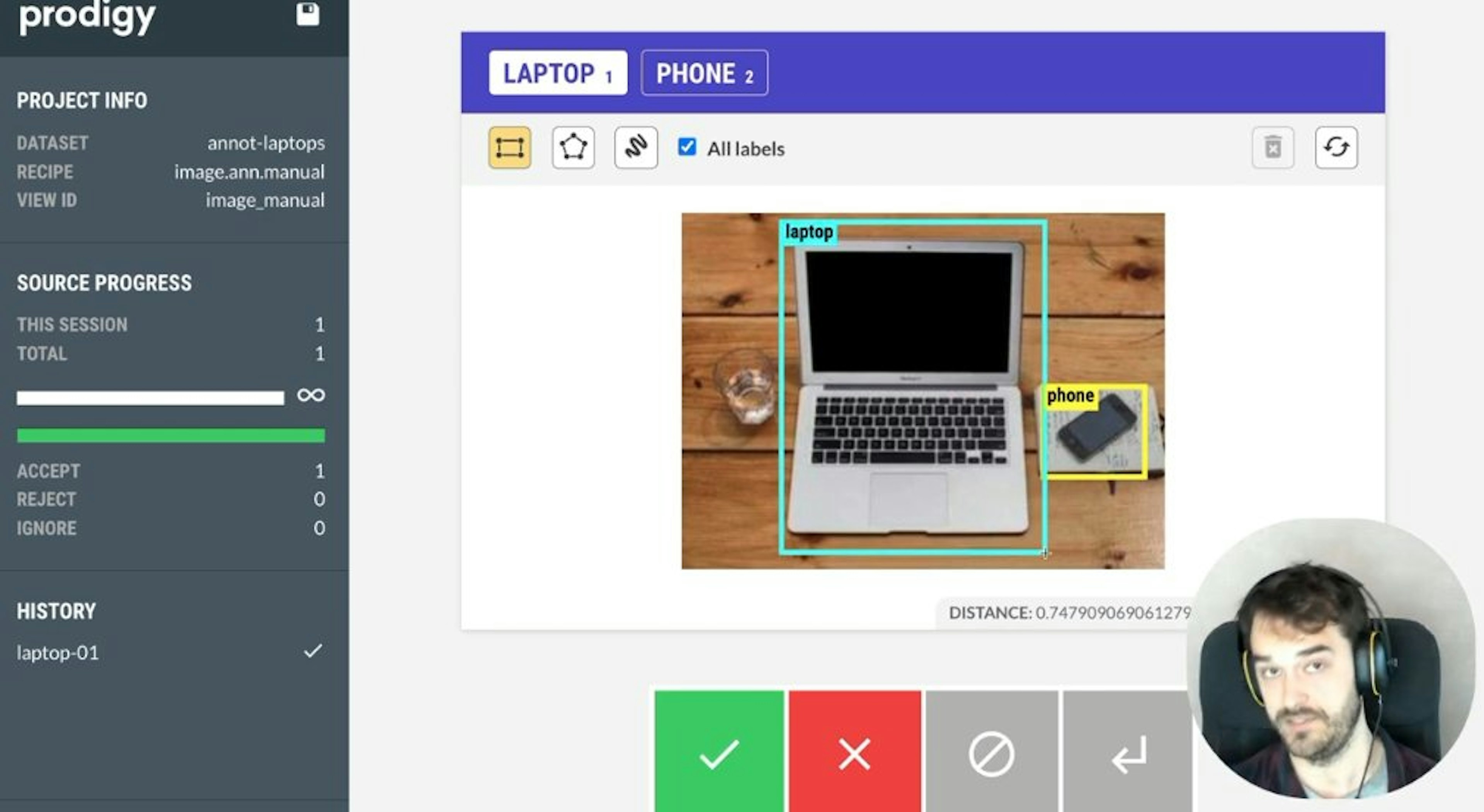






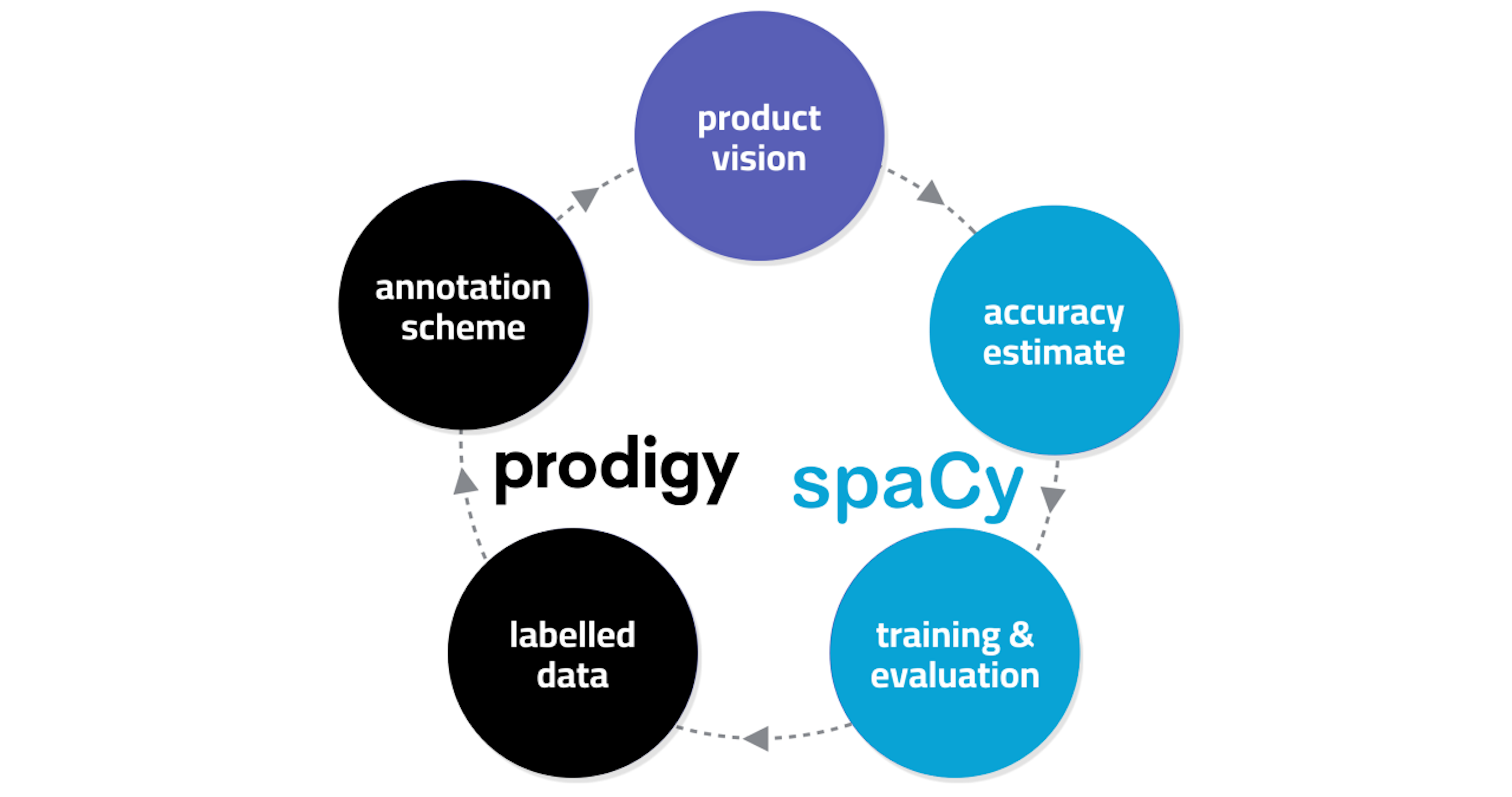
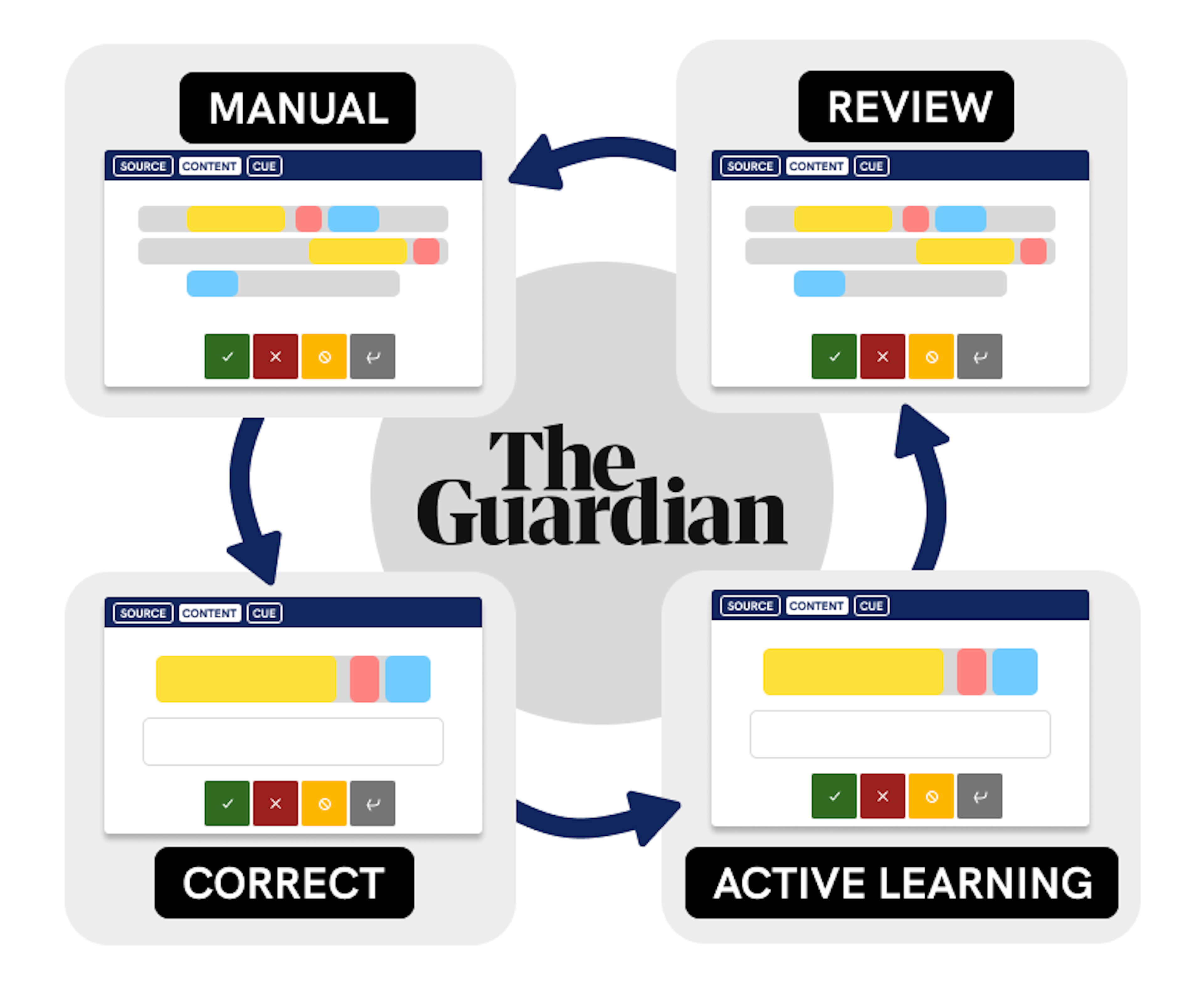













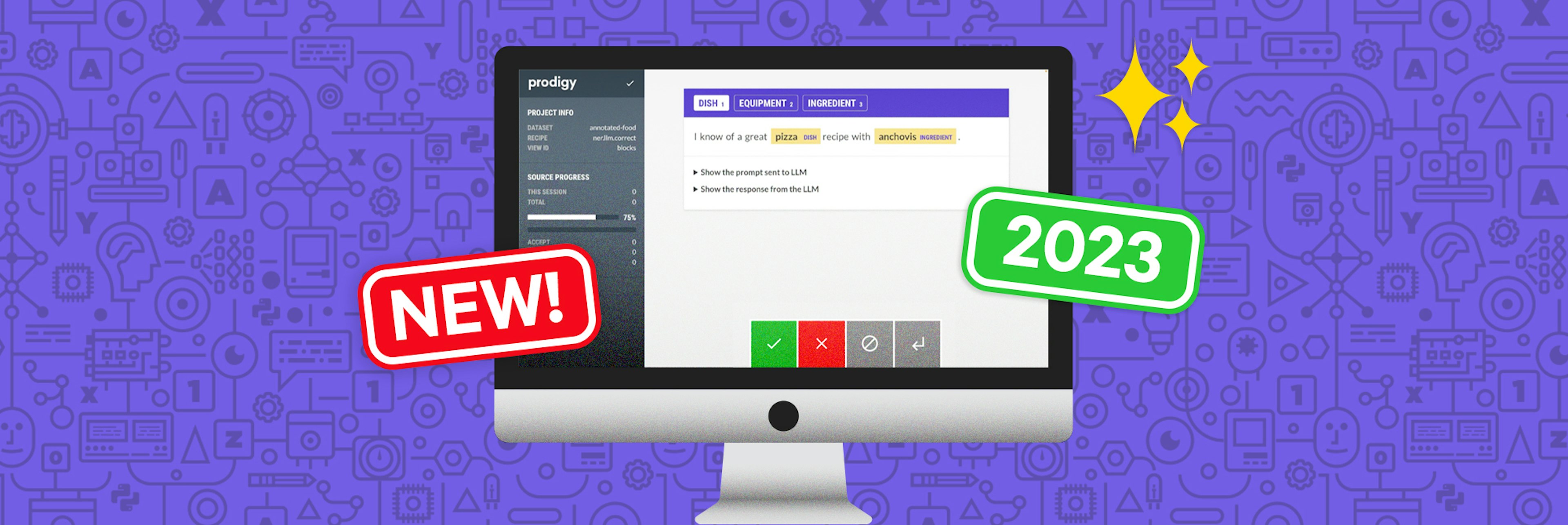
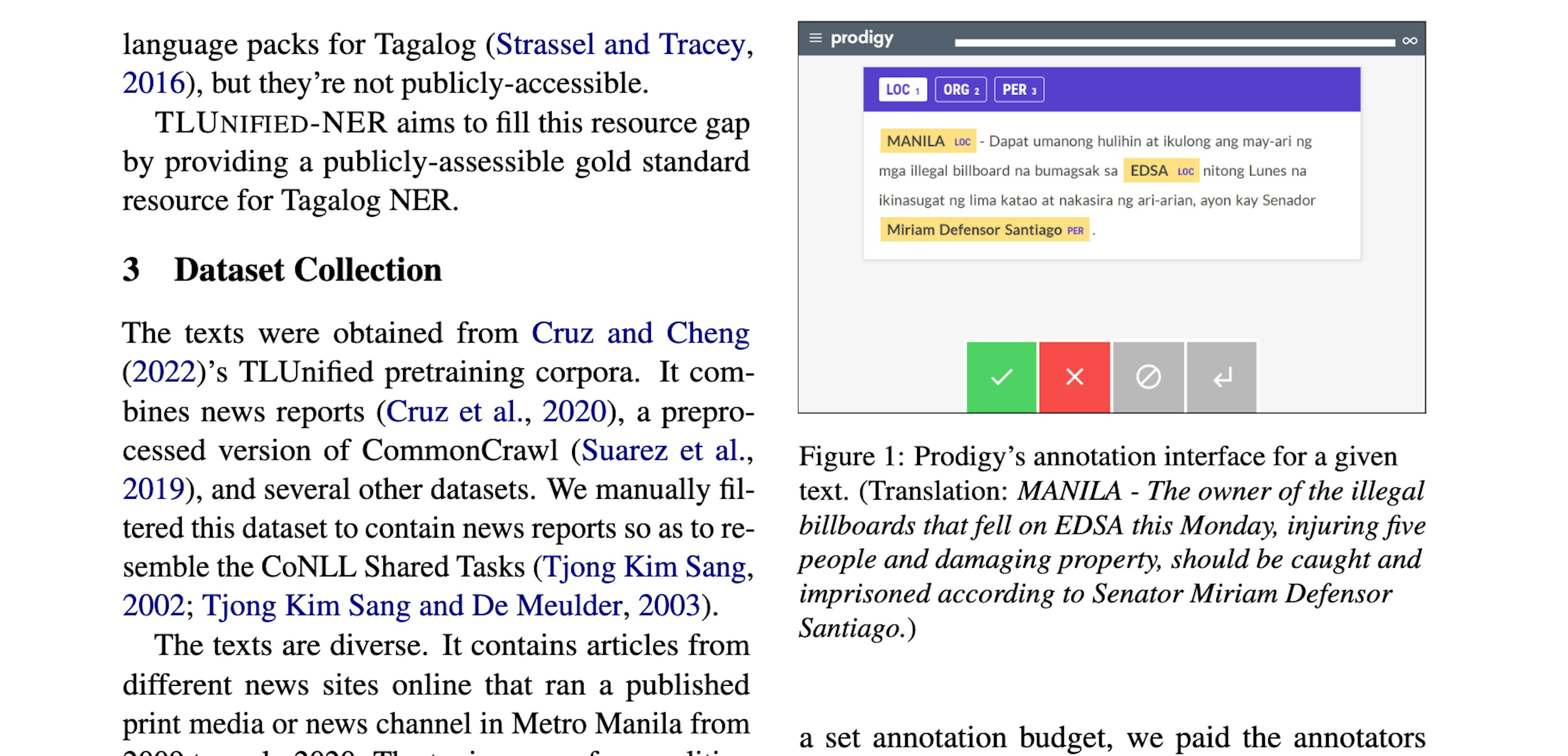
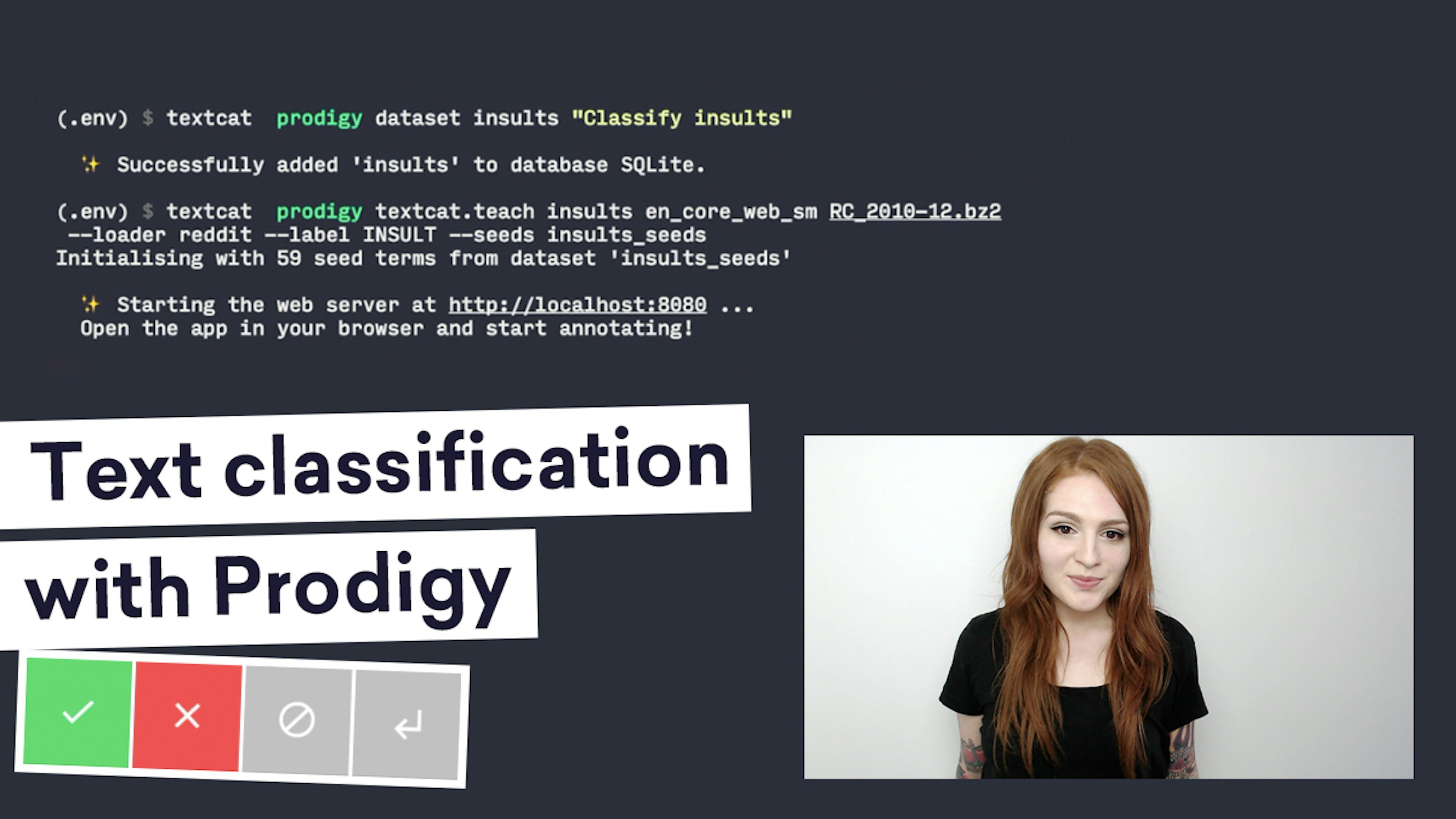
✨ prodigy v1.14.5
Toggle for character vs. token highlighting, CSS and JS from local and remote paths
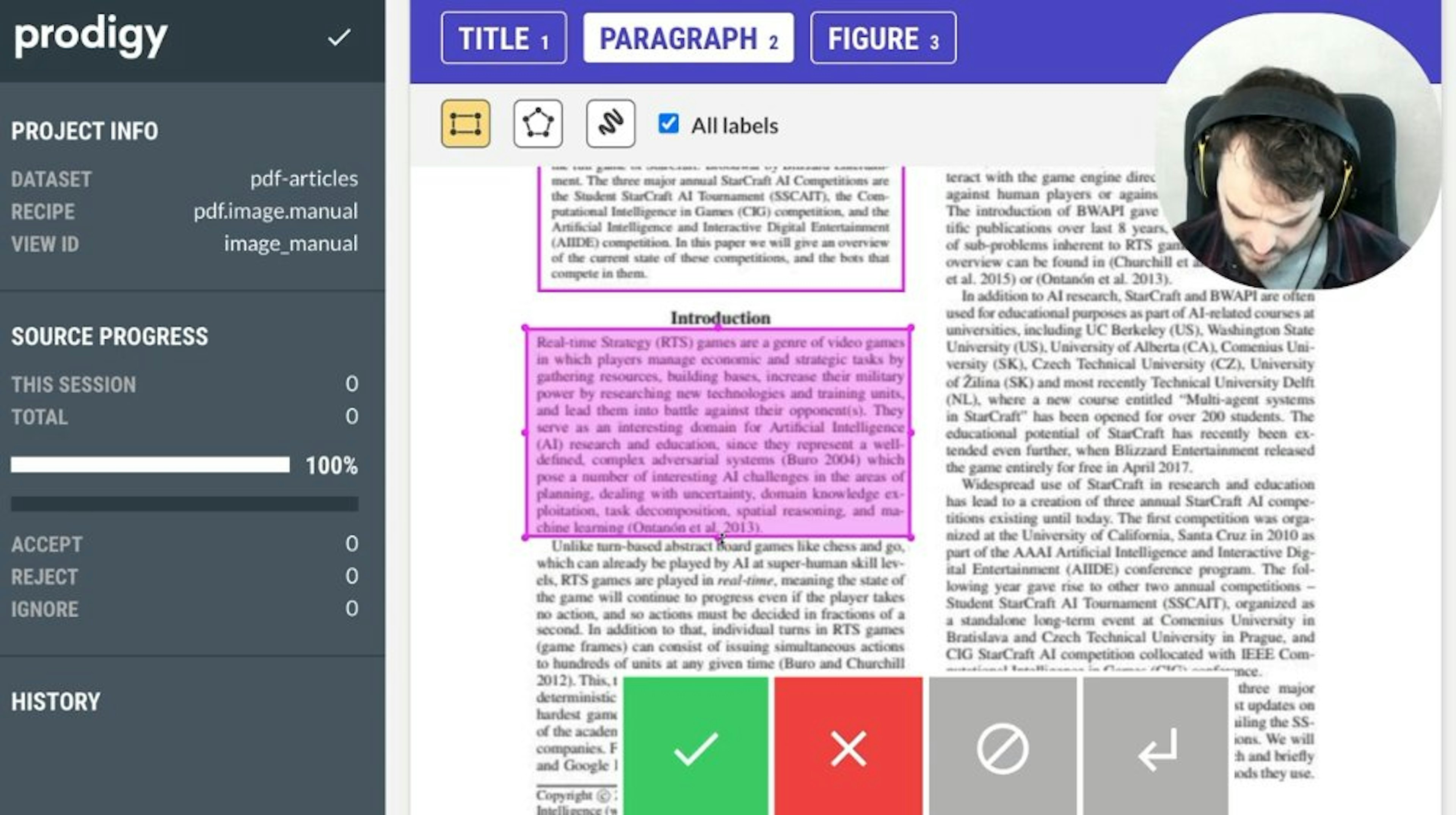
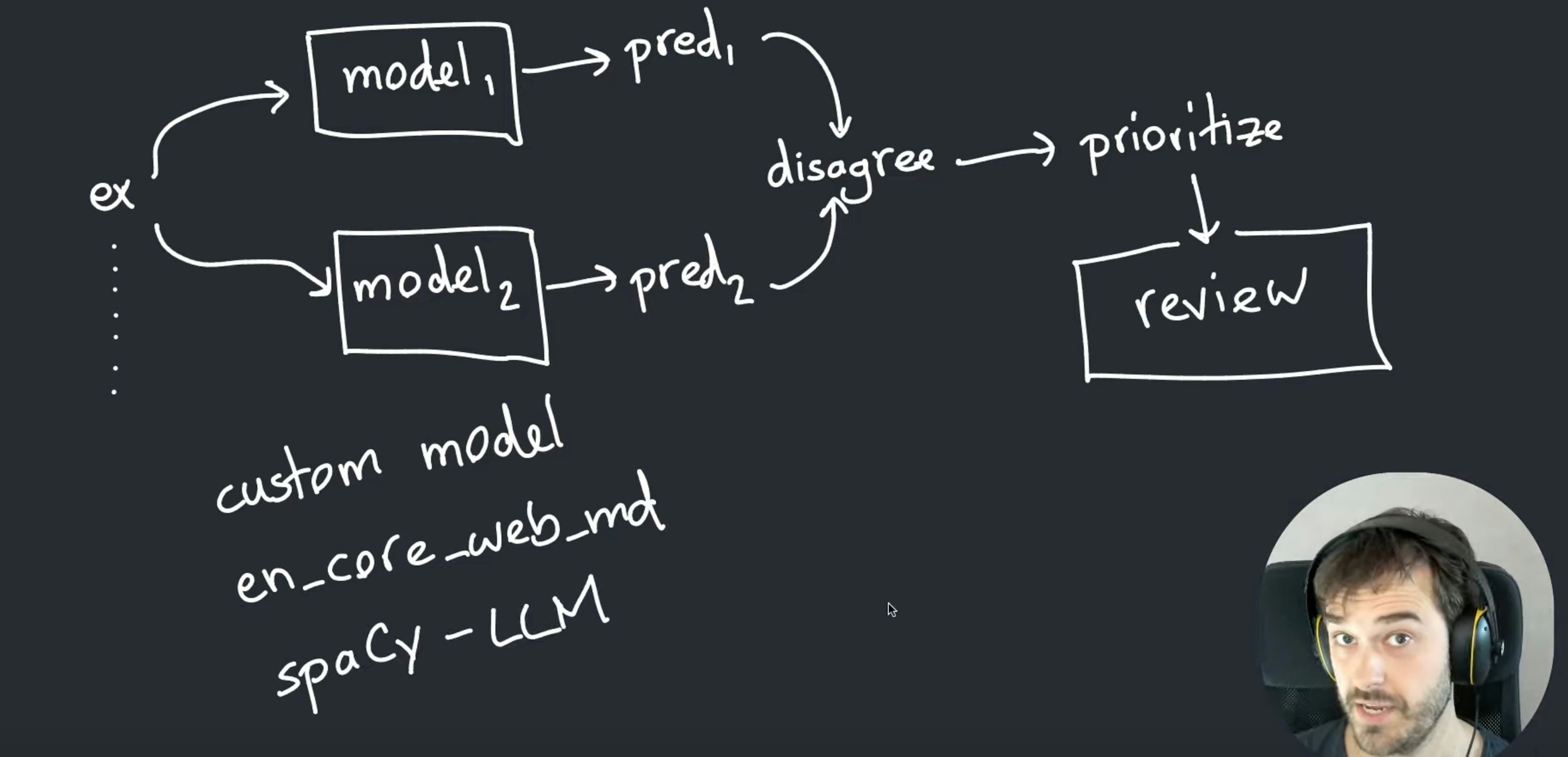
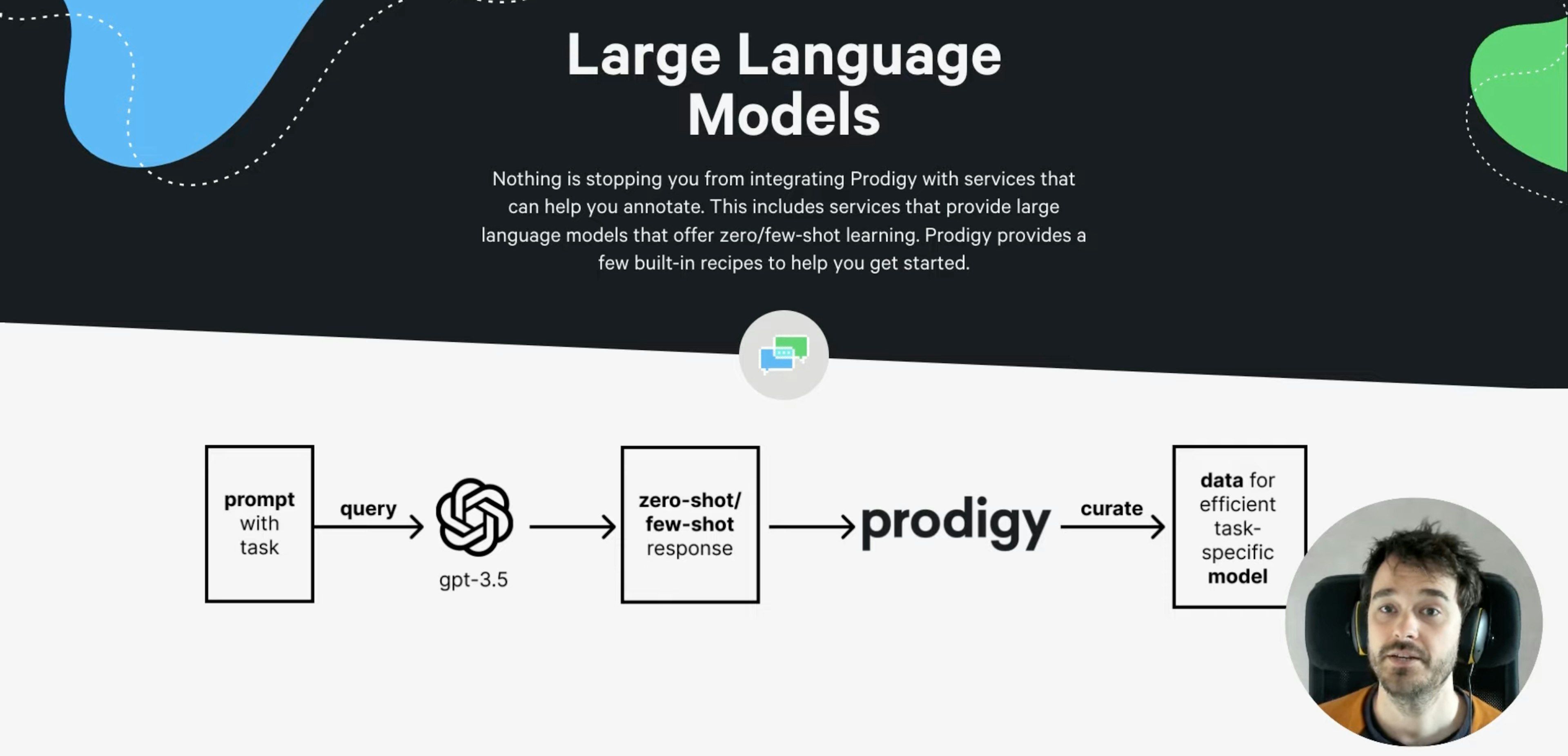



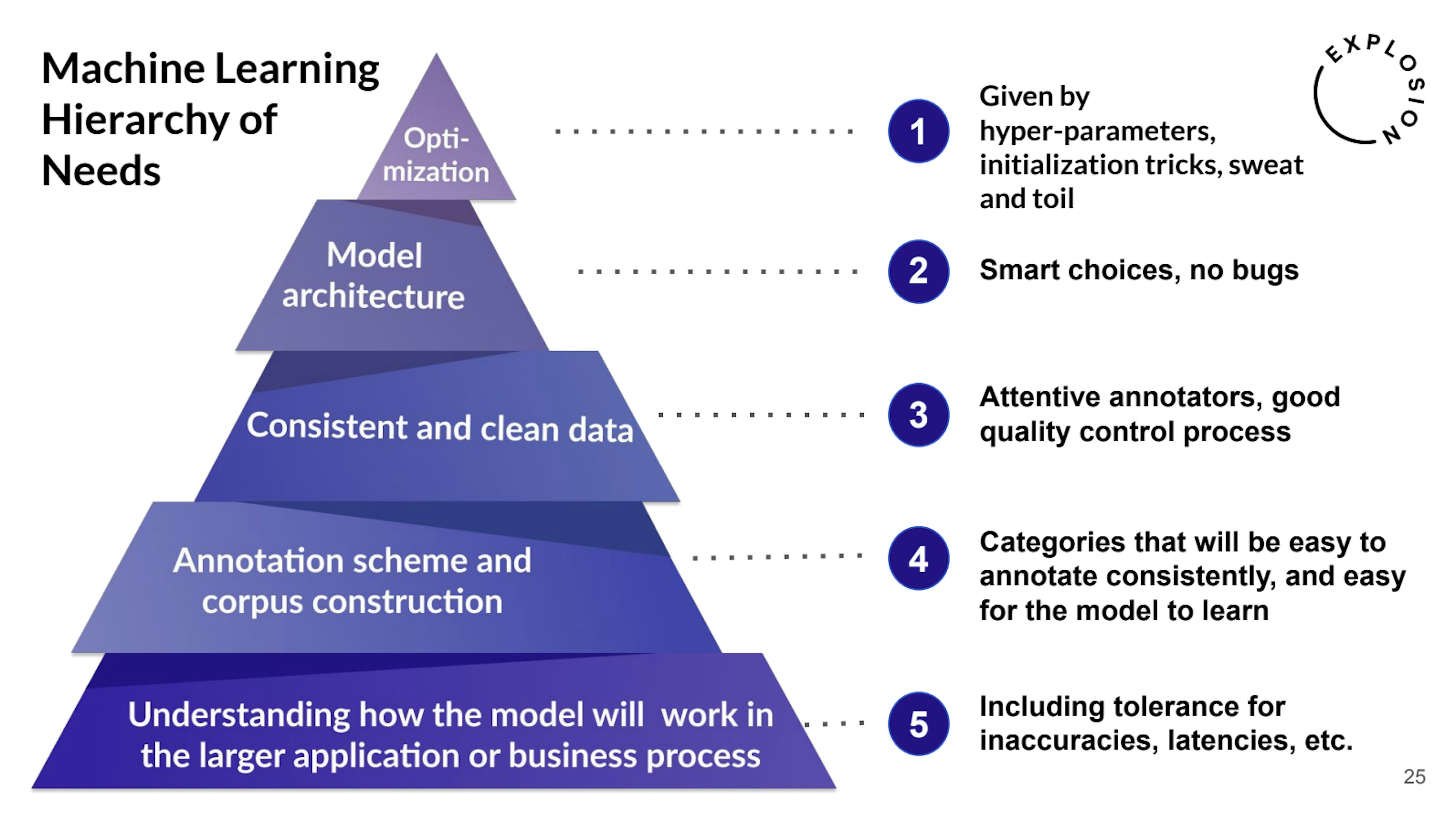
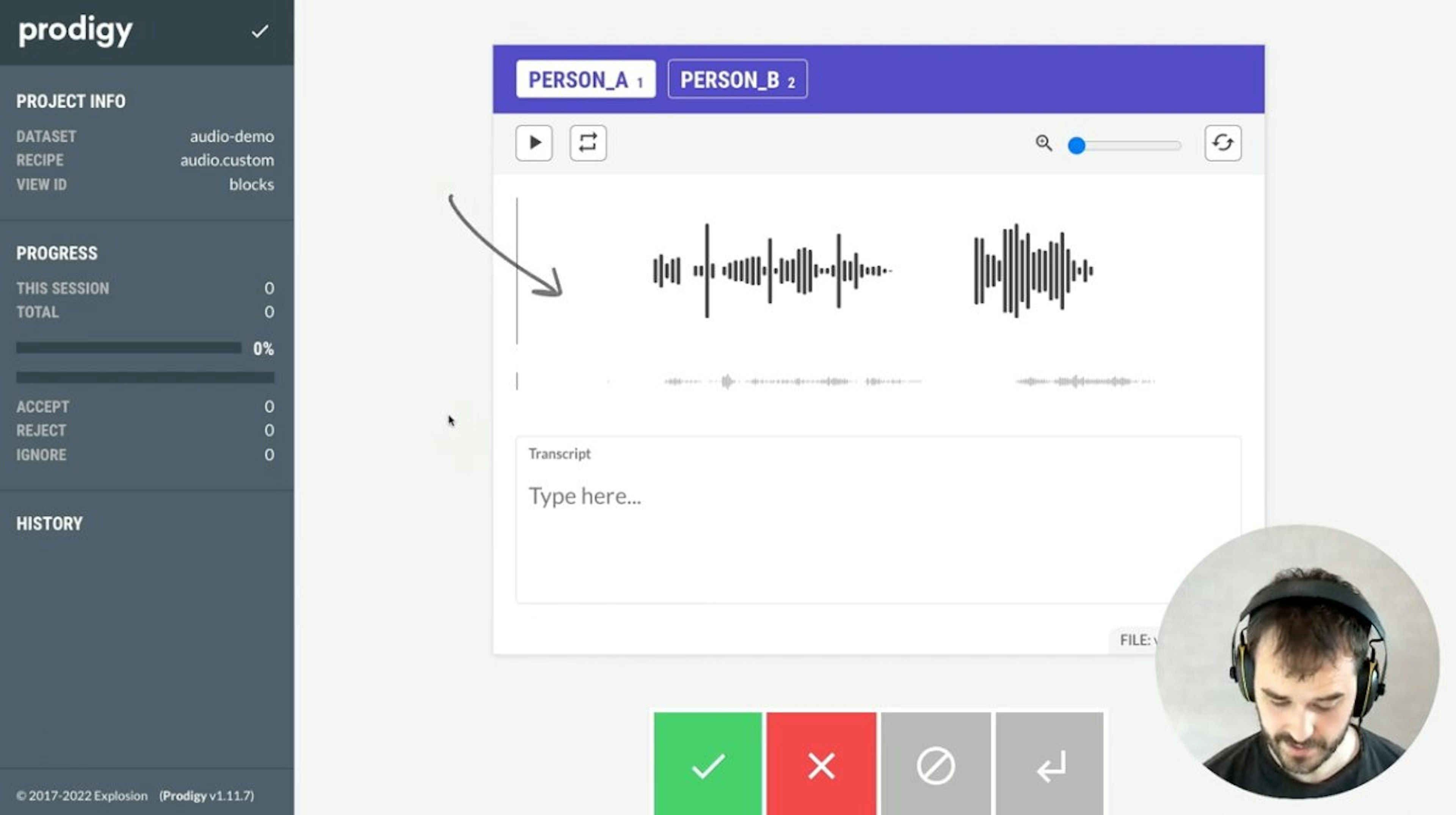



Toggle for character vs. token highlighting, CSS and JS from local and remote paths