
We founded Explosion in October 2016, so this was our first full calendar year in operation. We set ourselves ambitious goals this year, and we’re very happy with how we achieved them. Here’s what we got done.
Company and Fundraising
Over the last year, more and more companies have been questioning the logic of the standard venture-backed startup playbook. While we wouldn’t say bootstrapping is for everyone, it’s been a joy to build the company that we want to build, the way we want to build it:
- Worked with some amazing companies and shipped custom, cutting-edge machine learning solutions for a range of exciting problems.
- Funded 120% of company and personal expenses through consulting projects.
- Received $0 of external funding and retained 100% ownership.
- Declined 36 opportunities to “touch base” with investors and other professional networkers, who were confused by our radical we-spend-our-time-working approach.
spaCy
In 2017 spaCy grew into one of the most popular open-source libraries for Artificial Intelligence. It was also a huge year for development, with the release of version 2.0. Highlights included:
- Developed new deep learning models for text classification, parsing, tagging, and NER with near state-of-the-art accuracy.
- Improved APIs for training, updating and pipeline customization, as well as model packaging.
- Introduced new system for extending
Doc,SpanandTokenobjects with custom attributes. - Celebrated 5,000 stars on GitHub and sent out hundreds of stickers to users in 28 countries. Can’t wait to do another round for the 10k!
Of course, we didn’t just work on the fun stuff. We also fixed every open bug before releasing v2.0, improved our build and test infrastructure, and made huge improvements to the docs. Some statistics:
- Published 18 spaCy releases and another 19 alphas.
- Merged 3,238 commits from 129 authors.
- Relaunched the spaCy website with almost 25k words of documentation and a dozen new usage tutorials, including an extensive spaCy 101 guide for beginners.
- Published 13 pre-trained statistical models for tagging, parsing and NER in 8 languages, and extended tokenization support to 26 languages in total.
Prodigy
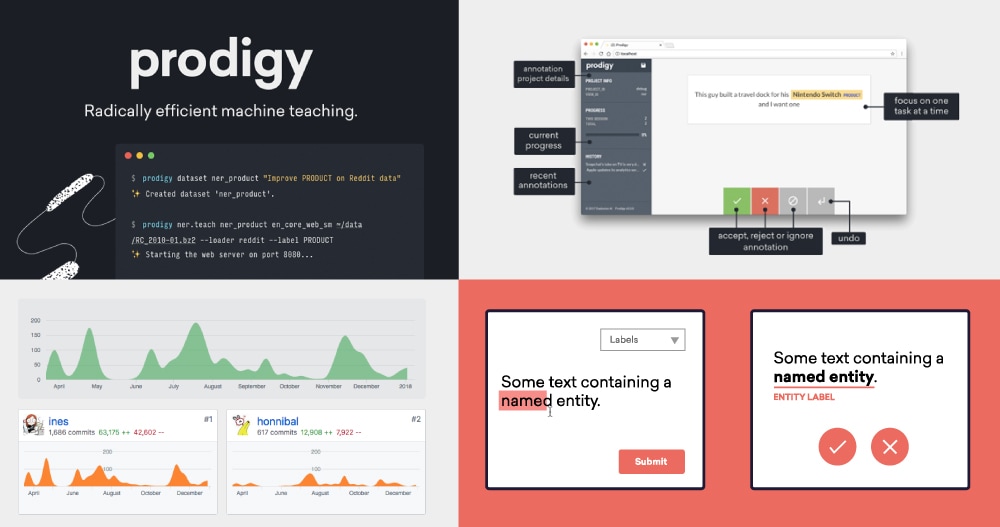
In December we released Prodigy, our new annotation tool powered by active learning. Prodigy is our first commercial product, and the first product of its type on the market. You can see the thought process behind Prodigy in three blog posts that we wrote along the way. In August 2016, Ines wrote a post on how AI developers could benefit from better tooling and more careful attention to interaction design. In April 2017, we published a follow up that described the solution we were working on, and in August we introduced Prodigy, and started accepting beta users.
- Released Prodigy v1.0, v1.1 and v1.2 in addition to five beta versions.
- Implemented 9 annotation interfaces and over 20 built-in recipes.
- Created an active and growing user community. Discourse is actually a fantastic product for this – it makes GitHub issues feel almost sad in comparison.
- Published two tutorial videos demonstrating the tool and published three blog posts explaining what Prodigy is, and why we built it.
Other Open-Source Software
Alongside spaCy, we’ve also published a number of smaller or less complete open-source projects.
| Thinc | 🔮 spaCy’s Machine Learning library for NLP in Python. After 17 releases in 2017, we’re looking forward to making Thinc available for a wider range of use cases outside of spaCy. |
| LightNet | 🌓 Bringing pjreddie’s DarkNet out of the shadows #yolo Originally developed for testing active learning-powered image annotation with Prodigy. There’s still a lot to do, so we hope you can get involved. The DarkNet code base is a great way to learn about implementing neural networks from scratch. |
| cython-blis | 💥 Fast matrix-multiplication as a self-contained Python library After continuing to struggle with BLAS libraries for NumPy, we built this Cython wrapper for BLIS as an experiment. Currently missing Windows support – contributions welcome! |
| spacymoji | 💙👉💫 Emoji handling and meta data for spaCy A plugin to add emoji meta data to spaCy objects, developed to showcase the new custom pipeline components and attribute extensions. We hope to see many more spaCy plugins like this in the future. |
Selected Writing, Talks and Videos
Our mission is to help developers get the latest research into production. Demystifying “AI” by making it easier to use and understand is a big part of that. Here’s some of what we published in 2017:
-
PyCon Israel Keynote: Why Python’s the best language for AI (and how to make it even better)
-
Video: spaCy’s NER model: incremental parsing with Bloom embeddings & residual CNNs
-
Video: Training an insults classifier with Prodigy in ~1 hour
-
Video: Training a new entity type with Prodigy – annotation powered by active learning
-
Pseudo-rehearsal: A simple solution to catastrophic forgetting for NLP
-
Prodigy: A new tool for radically efficient machine teaching
-
Supervised learning is great — it’s data collection that’s broken
-
Supervised similarity: Learning symmetric relations from duplicate question data
-
Deep text-pair classification with Quora’s 2017 question dataset
-
Building Prodigy: Our new tool for efficient machine teaching
Thanks for your support! We think 2018 can be even better – to stay in the loop, follow us on Twitter.



