Build-to-own AI: Agentic Development for HumansPyData PyCon Yerevan KeynoteInstead of using LLM APIs, we can take back control and build our own systems, bootstrapped by agents. In this talk, Ines shows you these new agentic workflows, what they mean for developer tools and why code and open-source are more important than ever.
Vibe NLP for Applied NLPPyCon DE & PyDataWhat if we could take learnings from AI-powered coding agents and apply them to solving real-world NLP problems? In this talk, I’ll show how we’ve built a powerful virtual NLP assistant to help developers create practical and modular solutions that are small, fast and fully data-private.
Sovereign AI systems instead of black box solutionsit-dailyGerman article featuring Ines’ take on AI in industry, the role of open source, and using Generative AI to create systems.
AI in Reality Fireside Chat: Enterprise AI & Open-Source InnovationPyCon DE & PyDataPanel discussion with Alexander CS Hendorf, Dr. Alexander Beck, Walid Mehanna and Ines.
KI zwischen Freiheit und Kontrolle: The AI Revolution Will Not Be Monopolizeddata:unplugged (German)How should we envision the use of AI in practice? And are we heading further into a black box era with larger and larger models, obscured behind APIs controlled by big tech monopolies?
What the history of the web can teach us about the future of AIHow will AI development look in the future? There is a lot we can learn from another groundbreaking technology: the web. This blog post takes a look at what the history of the web can teach us, and what this means for developers, models, open source and regulation.
From PDFs to AI-ready structured data: a deep diveThis blog post presents a new modular workflow for converting PDFs and similar documents to structured data and shows you how to build end-to-end document understanding and information extraction pipelines for industry use cases.
Applied NLP with LLMs: Beyond Black-Box MonolithsPyBerlinIn this talk, Ines shows some practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components.
10 Years of Open Source: Navigating the Next AI RevolutionEuroSciPy KeynoteIn this talk, Ines shares the most important lessons we’ve learned in 10 years of working on open-source software, our core philosophies that helped us adapt to an ever-changing AI landscape and why open source and interoperability still wins over black-box, proprietary APIs.
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillationPyData LondonLLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, Ines shows some practical solutions for using the latest models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
KI – Die künstlerische Intelligenz?Immergut Festival (German)Panelists are discussing the latest developments in Generative AI, hype vs. reality and what those new technologies mean for people, businesses, art, creativity and the music industry.
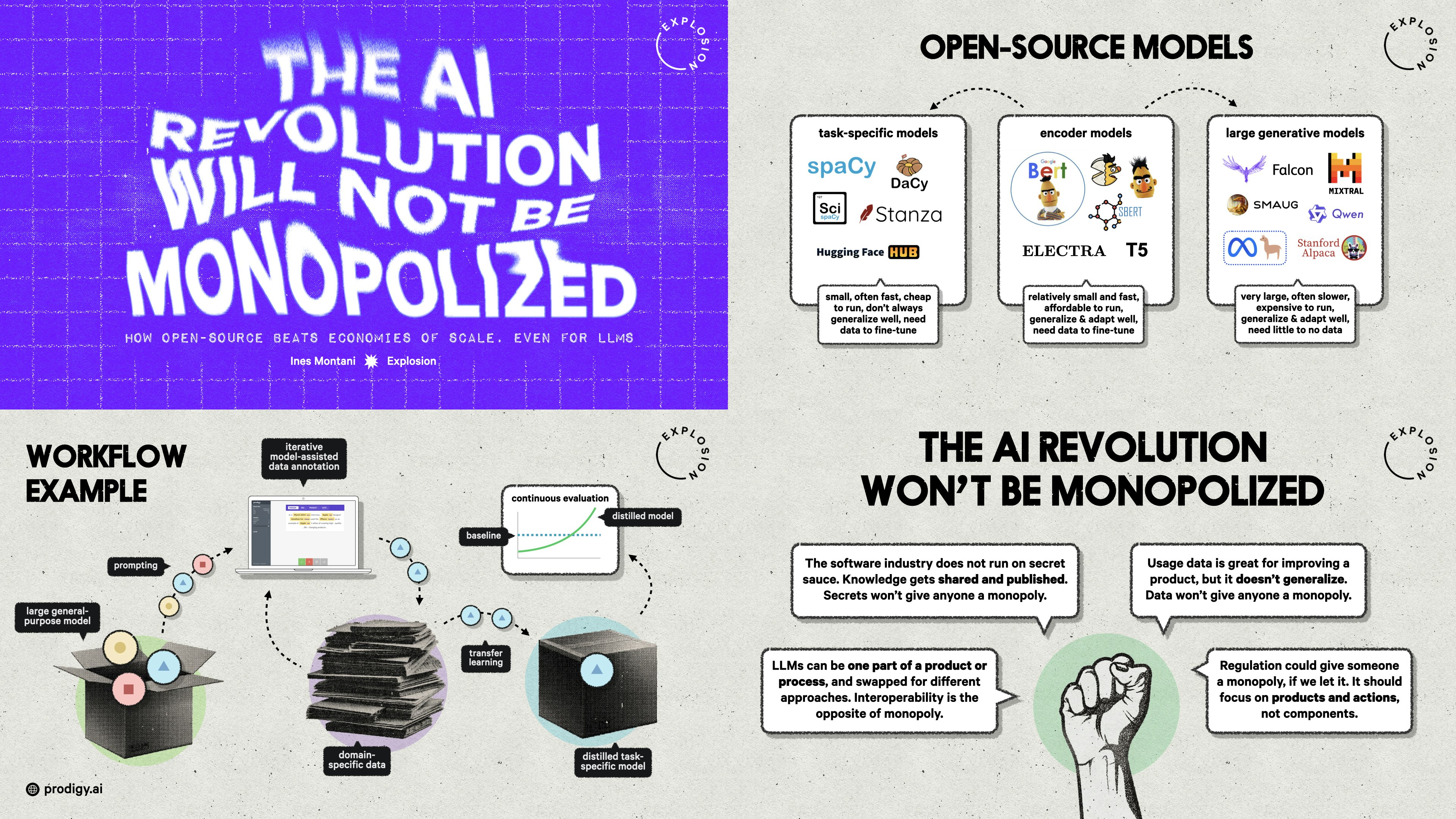
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsQCon London
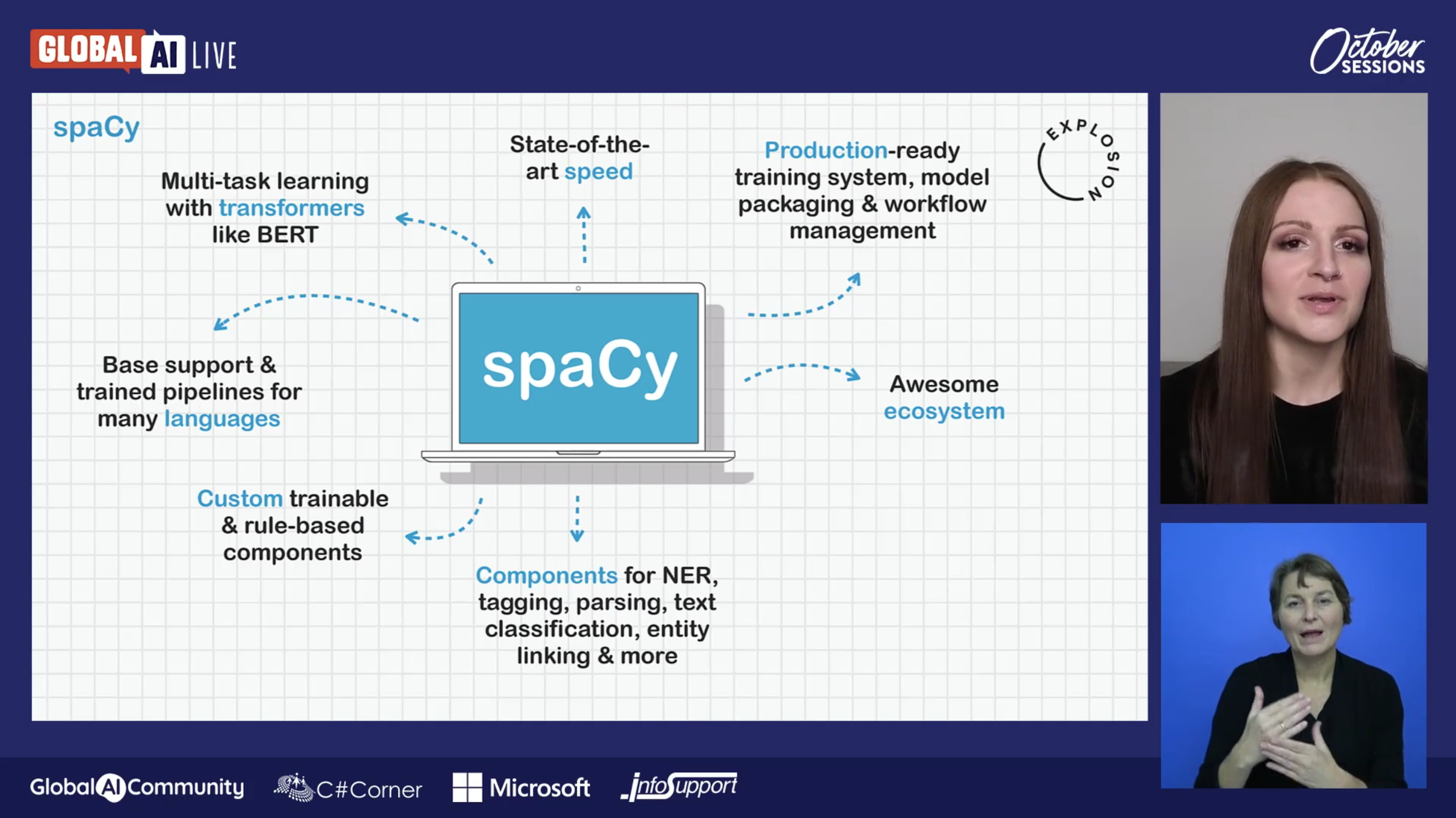
Introducing spaCy v3.6spaCy v3.6 introduces the span finder component and trained pipelines for Slovenian.
We’ve sold 5% of ExplosionSince founding Explosion in 2016, we’ve run the company as a profitable business and we decided to only consider external investment if we could find a deal that wouldn’t compromise the direction or stability of the company. We’re pleased to announce that we’ve found an investment that ticks all the boxes.
spaCy v3: Design concepts explained (behind the scenes)In this video, Ines shows you some of the new design concepts and explain what’s going on under the hood, how we’ve implemented them and most importantly, why.
Explosion in 2020: Our Year in ReviewWhile 2020 hasn’t been easy for anyone, at Explosion we’ve considered ourselves relatively fortunate in this most interesting year. We’ve always worked remotely, so we’ve been able to take both pride and comfort in continuing to ship good software. Here’s a look back at what we’ve been up to.
Image Captioning with Prodigy & PyTorchIn this video, we’ll show you how you can use Prodigy to script fully custom annotation workflows in Python, how to plug in your own machine learning models and how to mix and match different interfaces for your specific use case.
Explosion in 2019: Our Year in ReviewAs 2019 draws to a close and we step into the 2020s, we thought we’d take a look back at the year and all we’ve accomplished. And we realized we had so much that we could give you a month-by-month rundown of everything that happened.
Interview with Ines MontaniSayak PaulInes talks about how she got into programming, how to stay up to date with the latest developments in our field and the ideas behind the PyCon India keynote “Let Them Write Code”.
Introducing spaCy v2.2Version 2.2 of the spaCy Natural Language Processing library is leaner, cleaner and even more user-friendly. In addition to new model packages and features for training, evaluation and serialization, we've made lots of bug fixes, improved debugging and error handling, and greatly reduced the size of the library on disk.
Advanced NLP with spaCy: A free online courseIn this free and interactive online course, you’ll learn how to use spaCy to build advanced natural language understanding systems, using both rule-based and machine learning approaches.
The process: Transforming spaCy’s docsIncrement MagazineMaking your documentation work for users with vastly different needs is a challenge. Here’s how spaCy, an open-source library for natural language processing, did it.
Introducing custom pipelines and extensions for spaCy v2.0As the release candidate for spaCy v2.0 gets closer, we've been excited to implement some of the last outstanding features. One of the best improvements is a new system for adding pipeline components and registering extensions to the Doc, Span and Token objects. In this post, we'll introduce you to the new functionality, and finish with an example extension package, spacymoji.
Reflections on running spaCy: commercial open-source NLPines.ioAs more and more people and companies are getting involved with open-source software, balancing the expectations of an open community and a traditional provider vs. consumer relationship is becoming increasingly difficult. Are maintainers becoming too authoritarian? Are users becoming too demanding? Are large companies selling out open-source?
Introducing Explosion AIThe problem with developing a machine learning model is that you don't know how well it'll work until you try — and trying is very expensive. Obviously, this risk is unappealing, but the existing solution in the market, one-size-fits-all cloud services, are even worse. We're launching Explosion AI to give you a better option.
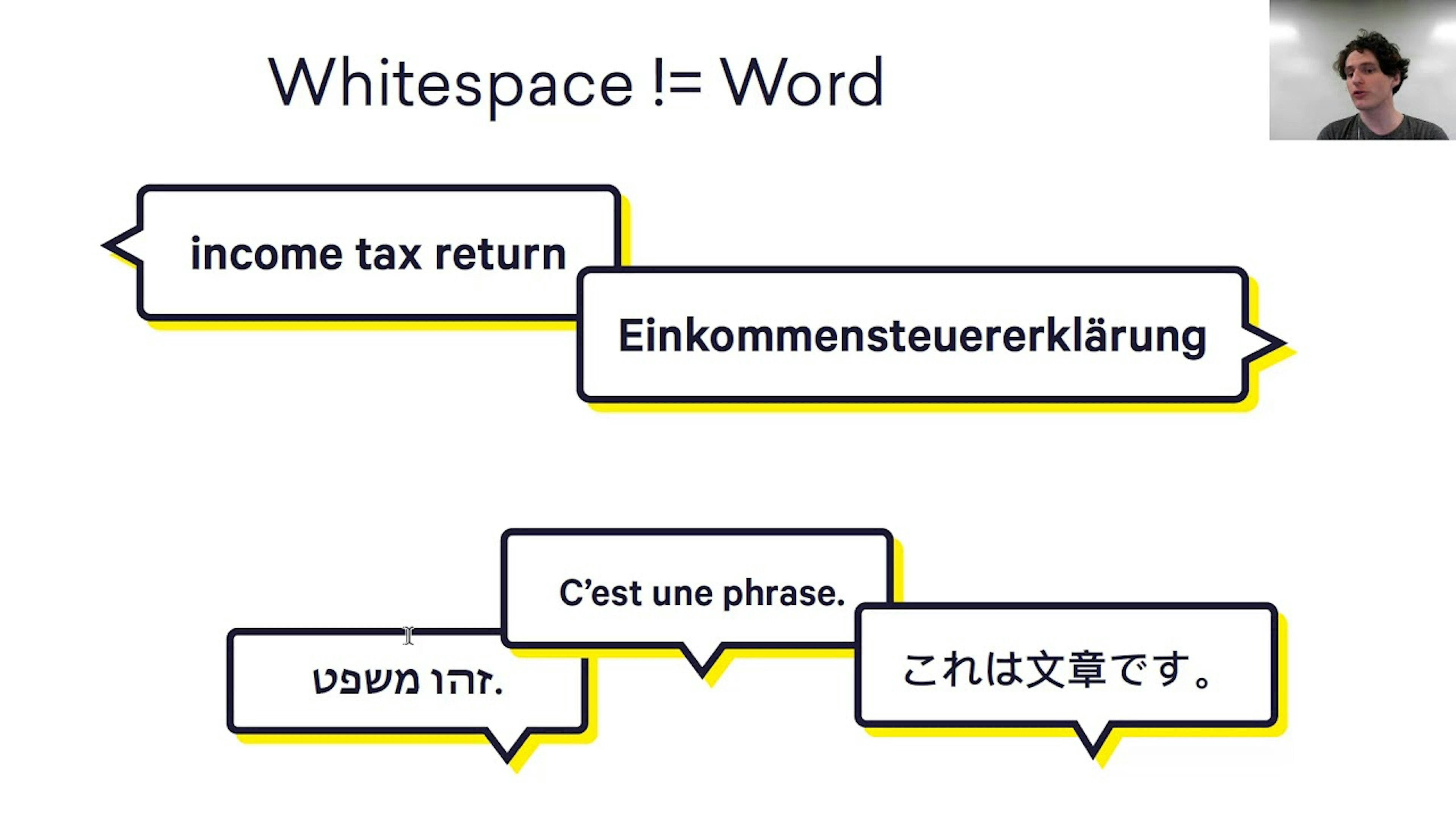
Atomic NLPAn applied NLP methodology inspired by Atomic Design: building reliable language understanding systems out of small, composable components instead of one big model and a prompt.
The ultimate guide to optimizing annotation workflowsThis blog post collects tips and advice for how to build efficient human-in-the-loop data development workflows, break down business problems into actionable annotation steps and make the most of automation and model assistance.
Conquering PDFs: document understanding beyond plain textPyData LondonIn this talk, Ines presents a new and modular approach for building robust document understanding systems, using state-of-the-art models and the awesome Python ecosystem.
Feminist AI LAN PartyPyCon DE & PyDataThree days of workshops, hacking, creating, publishing and connecting locally, featuring a data development workshop with Prodigy and a session on hacking LLMs.
How to advocate for modular NLP in the age of Generative AIWith all the hype around Generative AI, many are led to believe it’s the solution to everything. So how can you, as a developer, communicate the nuances and advocate for new and modular solutions that are better, easier and cheaper?
What the history of the web can teach us about the future of AIPyCon+Web KeynoteIn this talk, Ines takes a look at what the history of the web can teach us about the future of AI, and what this means for developers, models, open source and regulation.
Serverless custom NLP with LLMs, Modal and ProdigyIn this blog post, we’ll show you how you can go from an idea and little data to a fully custom information extraction model using Prodigy and Modal, no infrastructure or GPU setup required.
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillationInfoQ Dev SummitLLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, Ines shows some practical solutions for using the latest models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
The NLP and AI Revolution with the spaCy CreatorsVanishing GradientsIn this interview with Hugo Bowne-Anderson, we delve into the forefront of NLP and the future of AI development, covering topics like human-in-the-loop distillation, open-source AI and Explosion’s journey.
Happy 10th Birthday, spaCy!10 years ago today Matt pushed the first commit to spaCy. Since then, the library has evolved as the field moved forward, but also stayed true to its core mission: industrial-strength NLP.
Towards Structured Data: LLMs from Prototype to ProductionU.S. Census Bureau: Center for Optimization and Data Science SeminarThis talk presents pragmatic and practical approaches for how to use LLMs beyond just chat bots, how to ship more successful NLP projects from prototype to production and how to use the latest state-of-the-art models in real-world applications.
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsPyCon DE & PyData BerlinWith the latest advancements in NLP and LLMs, and big companies like OpenAI dominating the space, many people wonder: Are we heading further into a black box era with larger and larger models, obscured behind APIs controlled by big tech monopolies?
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsPyCon Lithuania KeynoteWith the latest advancements in NLP and LLMs, and big companies like OpenAI dominating the space, many people wonder: Are we heading further into a black box era with larger and larger models, obscured behind APIs controlled by big tech monopolies?
Solutions for Advanced NLP for Diverse LanguagesNew Languages for NLP KeynoteThis talk discusses spaCy’s philosophy for modern NLP, its extensible design and new recent features to enable the development of advanced natural language processing pipelines for typologically diverse languages.
Explosion in 2021: Our Year in ReviewThe year 2021 is coming to an end, and like the previous year, it was shaped by unique challenges that impacted our work together. For Explosion, it was a very productive year. We found an investor that fits our strategy, the work on Prodigy Teams is in full swing, and the team has grown a lot. So here's our look back at our highlights of the year 2021.
Welcome spaCy to the Hugging Face HubHugging Face BlogHugging Face makes it really easy to share your spaCy pipelines with the community! With a single command, you can upload any pipeline package, with a pretty model card and all required metadata auto-generated for you.
What does “real-world NLP” look like and how can students get ready for it?Teaching NLP at NAACL Keynote
Training a Named Entity Recognition Model with Prodigy and Transfer LearningIn this video, we’ll show you how to use Prodigy to train a named entity recognition model from scratch, by taking advantage of semi-automatic annotation and modern transfer learning techniques.
Künstliche Intelligenz Beyond the HypeZündfunk Netzkongress (German)“Artificial intelligence” is everywhere in the headlines. Many futuristic-sounding things suddenly seem possible. It’s not easy to judge what all these technological advances mean. What is hype and what really works? And how should we imagine the future?
spaCy meets Transformers: Fine-tune BERT, XLNet and GPT-2Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. You can now use these models in spaCy, via a new interface library we've developed that connects spaCy to Hugging Face's awesome implementations.
Introducing spaCy v2.1Version 2.1 of the spaCy Natural Language Processing library includes a huge number of features, improvements and bug fixes. In this post, we highlight some of the things we're especially pleased with, and explain some of the most challenging parts of preparing this big release.
Frag deinen Kühlschrank: Wie künstliche Intelligenz die Welt verändertARD alpha Documentary (German)In this documentation we explore what it feels like to work with intelligent machines. At large research centers and small start-ups we meet people who decide how and what AI learns today. Ines Montani teaches machines to understand the meaning of texts. Even for the young programmer, artificial intelligence is not magic, but a technology that everyone should understand.
How to Ignore Most Startup Advice and Build a Decent Software BusinessEuroPython Keynote“In this talk, I’m not going to give you one "weird trick" or tell you to ~* just follow your dreams *~. But I’ll share some of the things we’ve learned from building a successful software company around commercial developer tools and our open-source library spaCy.”
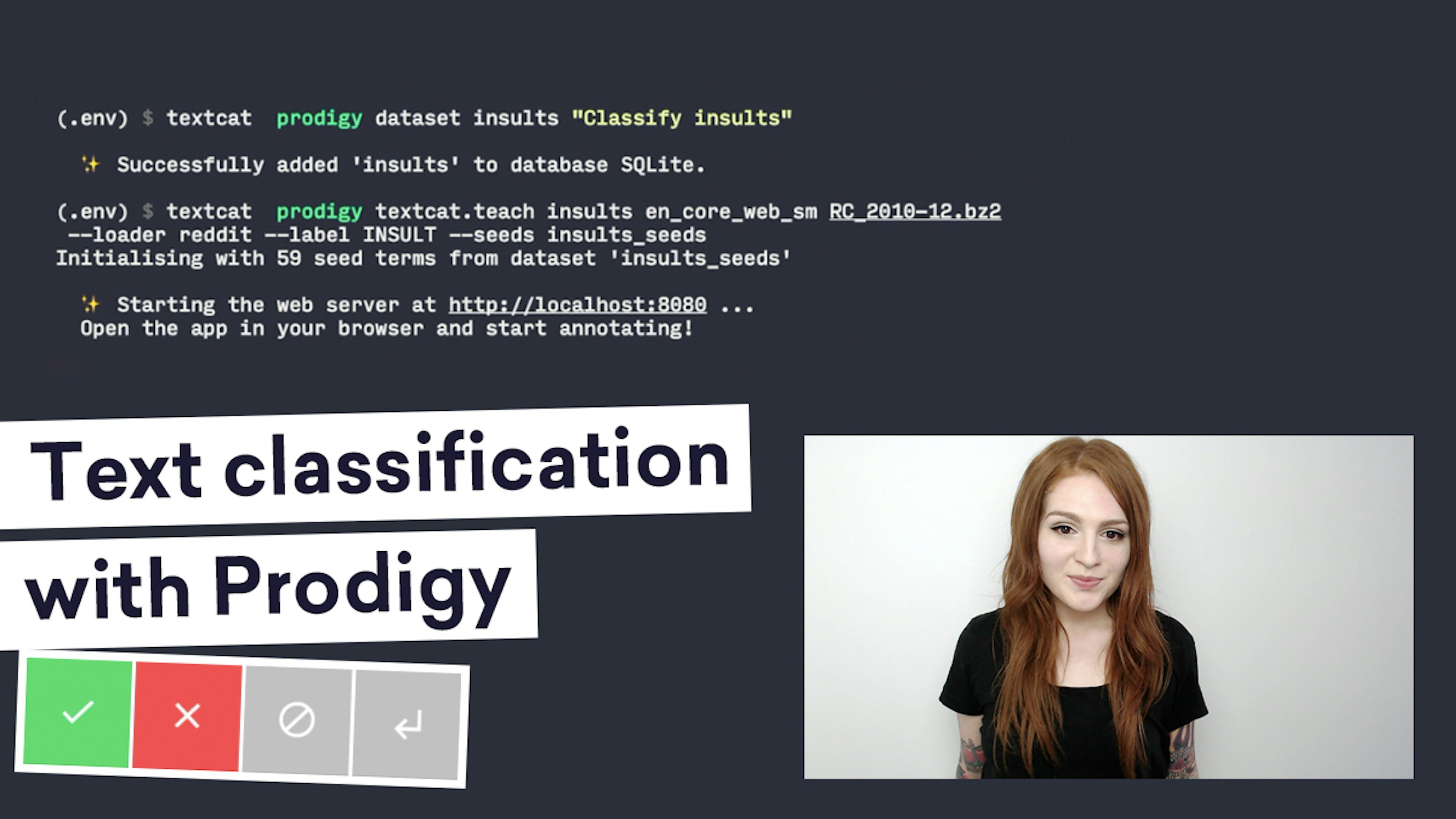
Training an insults classifier with Prodigy in ~1 hourIn this video, we’ll show you how to use Prodigy to train a classifier to detect disparaging or insulting comments. Prodigy makes text classification particularly powerful, because you can try out new ideas very quickly.
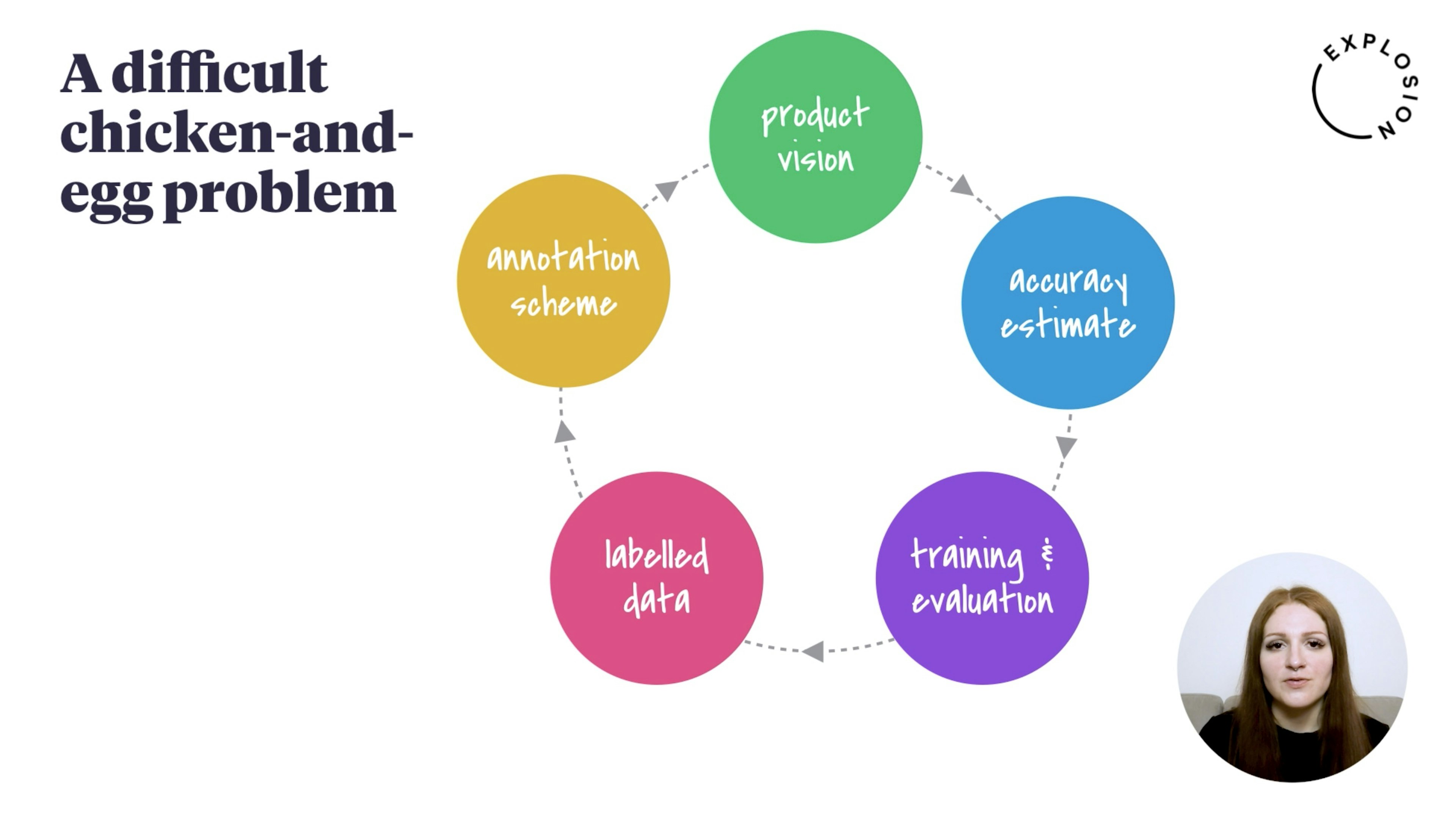
Supervised learning is great — it's data collection that's brokenShort of Artificial General Intelligence, we'll always need some way of specifying what we're trying to compute. Labelled examples are a great way to do that, but the process is often tedious. However, the dissatisfaction with supervised learning is misplaced. Instead of waiting for the unsupervised messiah to arrive, we need to fix the way we're collecting and reusing human knowledge.
How front-end development can improve Artificial IntelligenceWhat's holding back Artificial Intelligence? While researchers rightly focus on better algorithms, there are a lot more things to be done. In this post I'll discuss three ways in which front-end development can improve AI technology: by improving the collection of annotated data, communicating the capabilities of the technology to key stakeholders, and exploring the system's behaviours and errors.
A quick chat with Ines & MattPy4AIImpromptu video interview on what inspired our talk and the conference vibes in sunny Pavia.
Building AI with AIPyCon Ireland KeynoteAI-powered coding assistants have transformed the way we build software, and AI itself. In this talk, Ines shows why we should use LLMs to build systems instead of as systems, and why code is more important than ever, not less.
Applied NLP in the Age of Generative AI: Future-Proof Strategies for Banking and FinanceECONDAT KeynoteA modern approach and mindset for building future-proof NLP pipelines in-house, focusing on use cases from banking, finance and economics.
Conquering PDFs: document understanding beyond plain textPyCon DE & PyDataIn this talk, Ines presents a new and modular approach for building robust document understanding systems, using state-of-the-art models and the awesome Python ecosystem.
How Love Without Sound helps the music industry recover millions in revenue for artists with NLP, spaCy and ProdigyA case study on Love Without Sound’s innovative AI-powered tools for the music industry and law firms specializing in royalty negotiations.
Cracking the Code: How to Start a Career in AIWelcome to the JungleShort video interview with Ines about the 4 skills job hunters can cultivate for a career in artificial intelligence.
Accelerate your Career with Open-Source AIdotAIPanel discussion about making a career out of open-source software, featuring Gael Varoquaux (scikit-learn), Steeve Morin (ZML) and Ines.
Applied NLP in the Age of Generative AIPyData Amsterdam KeynoteIn this talk, Ines shares the most important lessons we’ve learned from solving real-world information extraction problems in industry, and shows you a new approach and mindset for designing robust and modular NLP pipelines in the age of Generative AI.
The Window-Knocking Machine TestHow will technology shape our world going forward? And what tools and products should we build? When imagining what the future could look like, it helps to look back in time and compare past visions to our reality today.
A practical guide to human-in-the-loop distillationThis blog post presents practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
spaCy meets LLMs: Using Generative AI for Structured DataData+ML Community MeetupThis talk dives deeper into spaCy’s LLM integration, which provides a robust framework for extracting structured information from text, distilling large models into smaller components, and closing the gap between prototype and production.
The AI Revolution Will Not Be Monopolized: Behind the scenesOpen Source ML MixerA more in-depth look at the concepts and ideas, academic literature, related experiments and preliminary results for distilled task-specific models.
Launching the Explosion Merch StoreSpread the love and support us and our open-source work with some of our unique, custom-designed swag. All orders come with free shipping and stickers!
Panel: Large Language ModelsBig PyData BBQwith Ines, Alejandro Saucedo (Zalando, Institute for Ethical AI & ML), Alina Lehnhard (Cerence), Michael Gerz (Heidelberg University), Alexander CS Hendorf (Königsweg)
Introducing spaCy v3.5spaCy v3.5 introduces new CLI commands, fuzzy matching, improvements for entity linking and more.
spaCy behind the scenes: library patterns & design concepts explainedDeveloper productivity has been central to our design of spaCy, both in smaller decisions and some of the bigger architectural questions. We believe in embracing the complexities of machine learning, not hiding it away under leaky abstractions, while also maintaining the developer experience. Read on to learn some of the design patterns within the library, how we've implemented them, and most importantly, why.
Introducing spaCy v3.3spaCy v3.3 improves the speed of core pipeline components, adds a new trainable lemmatizer, and introduces trained pipelines for Finnish, Korean and Swedish.
Introducing spaCy v3.2spaCy v3.2 features usability improvements for custom training and scoring, improved performance and support for floret, our new fastText word vectors algorithm.
Introducing spaCy v3.1It’s been great to see the adoption of spaCy v3, which introduced transformer-based pipelines, a new training system and more. Version 3.1 adds more on top of it, including the ability to use predicted annotations during training, a component for predicting arbitrary and overlapping spans and new pipelines for Catalan and Danish.
Introducing spaCy v3.0spaCy v3.0 is a huge release! It features new transformer-based pipelines that get spaCy's accuracy right up to the current state-of-the-art, and a new workflow system to help you take projects from prototype to production. It's much easier to configure and train your pipeline, and there are lots of new and improved integrations with the rest of the NLP ecosystem.
PyCon Colombia Speaker InterviewKaro and Ines talked about getting into tech and machine learning, and what’s next for spaCy and our other tools.
Building Prodigy: Our new tool for efficient machine teachingines.ioThe philosophy behind Prodigy’s features and its cloud-free design.
An open-source named entity visualizer for the modern webNamed Entity Recognition is a crucial technology for NLP. Whatever you're doing with text, you usually want to handle names, numbers, dates and other entities differently from regular words. To help you make use of NER, we've released displaCy-ent.js. This post explains how the library works, and how to use it.
Taking back control of your AI developmentFeminist AI (PyData London)Short unconference presentation by Ines on the current focus of our work: empowering developers to build AI in-house again.
How AI is reshaping IT skillsconnect professionalGerman article featuring Ines’ take on the impact of AI on future-proof skills for IT professionals.
Developer Trends in 2025TalkPython PodcastDiscussion with Michael Kennedy, Calvin Hendryx-Parker, Gina Häußge, Richard Campbell and Ines.
KI ohne Ketten: Warum Open Source gegen Big Tech gewinnen kannUNMUTE IT Podcast (German)Interview with Ines on open source, LLMs, ethics and sustainable AI development.
Künstliche Intelligenz: Technologie der Zukunft – und warum Open Source die Karten neu mischtHeise KI-Woche 2025 (German)German talk on the future of Artificial Intelligence and the impact of open-source software and models.
PyLadies entrepreneurs and career developmentPyLadiesConPanel discussion about career challenges and starting your own business with Cheuk Ting Ho, Tereza Iofciu, Anwesha Das, Una Galyeva and Ines.
How GitLab uses spaCy to analyze support tickets and empower their communityA case study on GitLab’s large-scale NLP pipelines for extracting actionable insights from support tickets and usage questions.
Back to our roots: Company update and future plansWe’re back to running Explosion as a smaller, independent-minded and self-sufficient company. spaCy and Prodigy will stay stable and sustainable, maintained by their original authors. We’ll keep updating our stack wth the latest technologies, without changing its core identity or purpose.
How S&P Global is making markets more transparent with NLP, spaCy and ProdigyA case study on S&P Global’s efficient information extraction pipelines for real-time commodities trading insights in a high-security environment.
The AI Revolution Won’t Be MonopolizedTalkPython PodcastThere hasn’t been a boom like the AI boom since the .com days. And it may look like a space destined to be controlled by a couple of tech giants. But Ines Montani thinks open source will play an important role in the future of AI.
Ines Montani on Natural Language ProcessingSoftware Engineering RadioInes speaks with host Jeremy Jung about solving problems using natural language processing. They cover generative vs. predictive tasks, creating a pipeline and breaking down problems, labeling examples for training, fine-tuning models, using LLMs to label data and build prototypes, and the spaCy NLP library.
Half hour of labeling power: Can we beat GPT?PyData NYCLarge Language Models (LLMs) offer a lot of value for modern NLP and can typically achieve surprisingly good accuracy on predictive NLP tasks. But can we do even better than that? In this workshop we show how to use LLMs at development time to create high-quality datasets and train specific, smaller, private and more accurate models for your business problems.
Large Language Models: From Prototype to ProductionEuroPython KeynoteLarge Language Models (LLMs) have shown some impressive capabilities and their impact is the topic of the moment. In this talk, Ines presents visions for NLP in the age of LLMs and a pragmatic, practical approach for how to use Large Language Models to ship more successful NLP projects from prototype to production today.
Explosion in 2022: Our Year in ReviewIt's been another exciting year at Explosion! We've developed a new end-to-end neural coref component for spaCy, improved the speed of our CNN pipelines up to 60%, and published new pre-trained pipelines for Finnish, Korean, Swedish and Croatian. We've also released several updates to Prodigy and introduced new recipes to kickstart annotation with zero- or few-shot learning.
Introducing spaCy v3.4spaCy v3.4 brings typing and speed improvements along with new vectors for English CNN pipelines and new trained pipelines for Croatian.
Introducing spaCy Tailored PipelinesExplosion is pleased to announce a new development services offering, spaCy Tailored Pipelines. We’ll build you a custom natural language processing pipeline, delivered in a standardized format using spaCy’s projects system.
Applied NLP Thinking: How to Translate Problems into SolutionsWe’ve been running Explosion for about five years now, which has given us a lot of insights into what Natural Language Processing looks like in industry contexts. In this blog post, I’m going to discuss some of the biggest challenges for applied NLP and translating business problems into machine learning solutions.
Prodigy v1.10: Dependencies, relations, audio, video & moreVersion 1.10 of Prodigy includes tons of new features, including manual dependency and relation annotation, audio and video annotation, a new and improved image UI, new recipe callbacks, more settings for manual NER, plus various new config options and settings.
The Future of NLP in PythonPyCon Colombia KeynoteThe data community came to Python for the language, and stayed for each other – once it got critical mass, it’s the ecosystem that counts. We’ve been proud to be part of that. So what does the future hold for NLP in Python?
sense2vec reloaded: contextually-keyed word vectorsIn 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. That work is now due for an update. In this post, we present a new version and a demo NER project that we trained to usable accuracy in just a few hours.
Explosion awarded META Seal of RecognitionWe’re proud to accept the META Seal of Recognition at META-FORUM in Brussels, along with Mozilla. The META-FORUM is an international conference series backed by the European Union on powerful and innovative Language Technologies for a multilingual information society.
FAQ #1: Tips & tricks for NLP, annotation & training with Prodigy and spaCyIn this video, Ines talks about a few frequently asked questions and shares some general tips and tricks for how to structure your NLP annotation projects, how to design your label schemes and how to solve common problems.
The AI Revolution will not be MonopolizedHack TalksWho’s going to "win at AI"? There are now several large companies eager to claim that title. Others say that China will take over, leaving Europe and the US far behind. But short of true Artificial General Intelligence, there’s no reason to believe that machine learning or data science will have a single winner. Instead, AI will follow the same trajectory as other technologies for building software: lots of developers, a rich ecosystem, many failed projects and a few shining success stories.
Explosion in 2017: Our Year in ReviewWe founded Explosion in October 2016, so this was our first full calendar year in operation. We set ourselves ambitious goals this year, and we're very happy with how we achieved them. Here's what we got done.
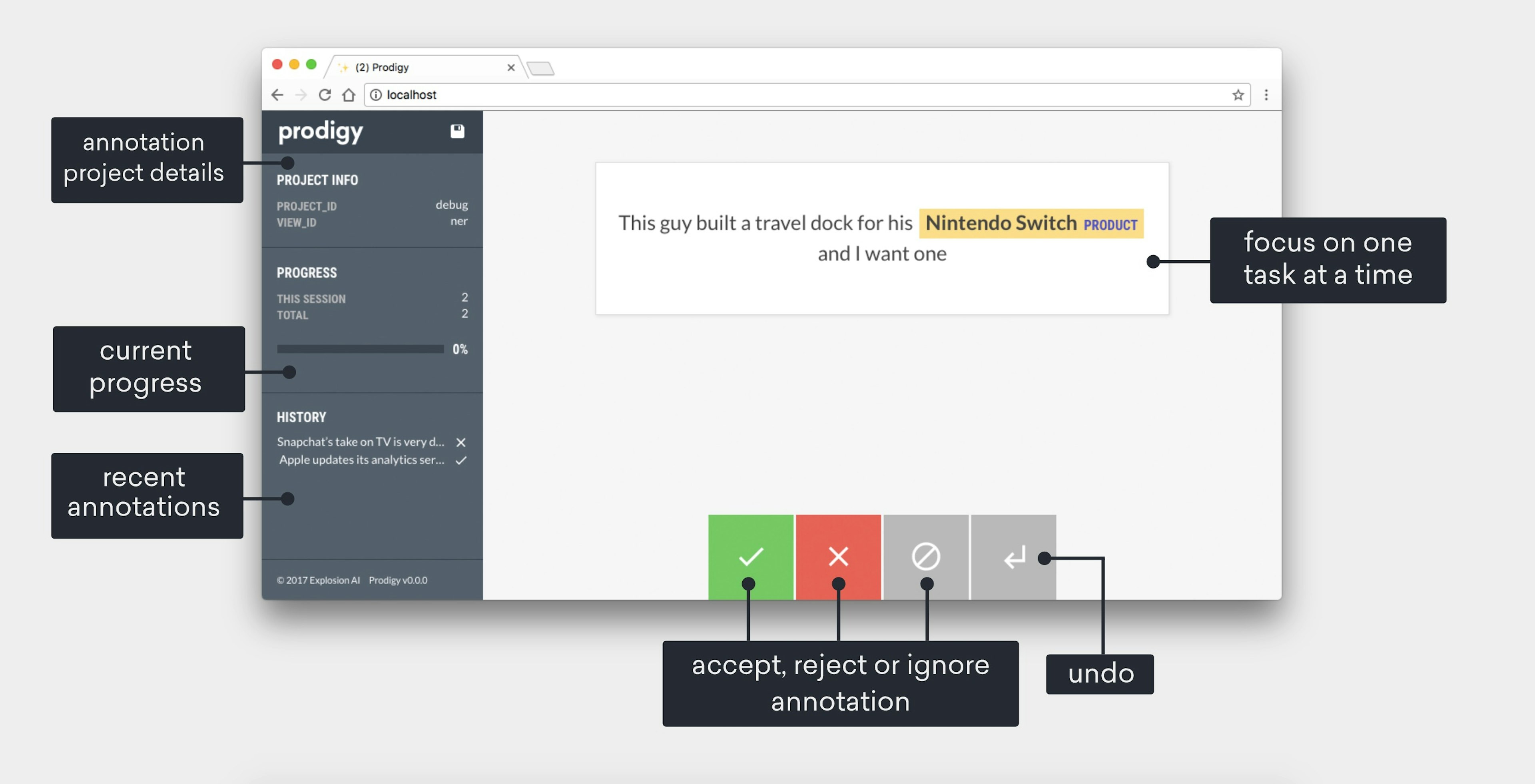
Prodigy: A new tool for radically efficient machine teachingMachine learning systems are built from both code and data. It's easy to reuse the code but hard to reuse the data, so building AI mostly means doing annotation. This is good, because the examples are how you program the behaviour – the learner itself is really just a compiler. What's not good is the current technology for creating the examples. That's why we're pleased to introduce Prodigy, a downloadable tool for radically efficient machine teaching.
displaCy.js: An open-source NLP visualizer for the modern webWith new offerings from Google, Microsoft and others, there are now a range of excellent cloud APIs for syntactic dependencies. A key part of these services is the interactive demo, where you enter a sentence and see the resulting annotation. We're pleased to announce the release of displaCy.js, a modern and service-independent visualization library. We hope this makes it easy to compare different services, and explore your own in-house models.