
- 12 minute read
- Blog

What’s holding back Artificial Intelligence? While researchers rightly focus on better algorithms, there are a lot more things to be done. In this post I’ll discuss three ways in which front-end development can improve AI technology: by improving the collection of annotated data, communicating the capabilities of the technology to key stakeholders, and exploring the system’s behaviours and errors.
Update (January 2018)
Many of the ideas and concepts described in this post went into Prodigy, our new annotation tool powered by active learning. Prodigy lets you collect training and evaluation data with a model in the loop, using the model’s predictions to determine what to ask next. Its web application helps the human annotator focus on one binary decision at a time. For more details, see the website or try the live demo.
Data Collection and Training
Contrary to popular belief, the bottleneck in AI is data, not algorithms. Data collection strongly relies on humans doing efficient work on computers. Humans interact with computers through interfaces, and the design, user experience and technology of those interfaces determines the quality of those interactions. Thus, front-end development is actually a key part of developing AI technologies.
Let’s say you have a bunch of user-generated data and you want to write a function that recognises technology companies. A good way to start off would be to give the computer a few examples: Apple, Google, Microsoft, IBM, Amazon… So far, so good. It’s easy to search for exactly those words across your data. But even the first examples already come with their own problems. You clearly want Apple, the company, not “apple”, the fruit. You also want Google, the company, not “google”, the verb. These ambiguities may make your simple function inaccurate and not particularly useful. If you can provide labelled examples of the words in context, you’ll be able to produce a more sophisticated function that can handle these ambiguities using a statistical model. For a good model, you want to be collecting a lot of examples — around 10,000 at least, and ideally much much more.
You can collect these examples by asking a human to go through your texts and mark the technology companies using an annotation or data collection tool. There are several different tools, like Brat, and platforms, like Amazon Mechanical Turk and CrowdFlower, that can help you get this work done. But this is only the starting point. With the growing demand for AI training data, we need to re-think the old-fashioned approach and make it more efficient and ultimately, more cost-effective.
In many cases, the creation of annotated data can seem like the ultimate unskilled labour. There’s no shortage of humans who speak better English than any computer. This suggests a tempting theory: annotation time should be dirt cheap, right? If so, then investment in annotation tools should be a waste. Just buy more labour. I think if you try this, you’ll see that people don’t behave so simply. The workers you’re hoping to hire so cheaply are homo sapiens, not homo economicus. If your tools are bad, the task will be boring and frustrating, and as a result, the workers’ input quality will be low. Believing that you can make your annotation tools bad because labour should be cheap is like believing that your offer is so valuable that your users shouldn’t care if your website is confusing and hard to use. Yes, maybe they shouldn’t, but empirically, they do — so you fix your website. Similarly, I think the finding will be that it’s well worth fixing the user experience on data collection tools.
How can we improve user experience? It helps to take a look at what humans actually enjoy doing for free and even pay money to do: games. The mobile game industry, in particular, has perfected the art of making incredibly simple, almost mundane tasks enjoyable. Subsequently, the principle of ”gamification” has been adopted widely across other apps and services. The goal here is pretty clear: get the user familiar with the task as quickly as possible, then get them hooked. A good game needs the right balance of reward and gratification – rewarding enough to not frustrate the players, but not too rewarding either to keep them engaged. This psychological mechanism discovered by B. F. Skinner in the 1960s has proven to be dangerously effective in slot machine design and, later on, the so-called ”freemium” game industry.
One of my favourite examples is the popular mobile game ”94%”. The concept is similar to ”Family Feud”: you have to find the top given answers to prompts like “Something you eat with your hands”. Other levels simply show you a photo and ask you to guess the most common associations. The game is so much fun that users have given it a solid rating of 4.5 stars on the iTunes store and seem to have spent a lot of money on extra coins to use on hints and jokers.
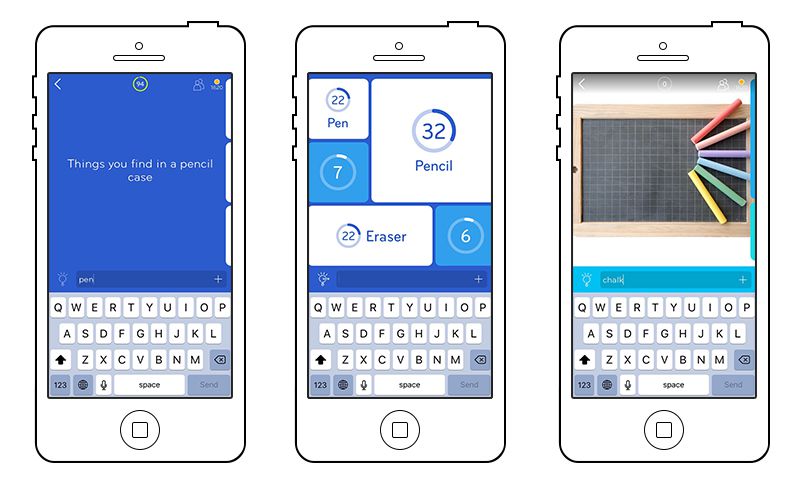
Now, if our goal is not to design a profitable mobile game, but to actually pay people for annotating our data while making their experience with our interface more pleasant and efficient, there’s actually a lot we can – and should – take away from this.
The “task” completed by the user in “94%” is a prime example of the type of data you’ll want to collect to train your AI model on. It’s inherently human and so intuitive to us that we barely even think about it – and that makes it so hard for a computer to learn, and so valuable to us. If mobile games are able to make people pay to do these things, imagine all the possibilities once we apply modern knowledge of gamification, UX psychology, UI design, accessibility standards and cross-platform front-end technologies to the current state of data collection tools.
Demonstration and Education
A big part of AI development and research is showing people how the technology works and what it’s able to do. The more we understand what’s possible, the better we are at building software using those new technologies. Artificial Intelligence is often presented as a magical black box, and the mystery behind it is what makes it so intriguing. But in reality, our aim should be to make it more transparent and accessible for everyone. It’s not enough to just show the results. People need to be able to see what’s going on behind the scenes from the computer’s perspective, and be able to interact with the technology directly. That’s where front-end development comes in once again.
Innovation on the back-end also needs innovation on the front-end. There’s no framework for “visualising AI”, and it won’t suffice to host an API and ask a front-end developer to “visualise it”. A good demo needs to build a bridge between showing the technological advancements and giving people an idea of how they’re actually useful in production.
Let’s say you want to demonstrate how well your newly trained technology company tagging model works. You could let users type in a sentence like “Mark Zuckerberg is the CEO of Facebook.” Hopefully, your back-end service will reliably tag “Facebook”, which you could then highlight on the screen. But does this really show what your model is capable of? Probably not. For what the user sees, you could have simply used a dictionary of all Fortune 500 tech companies and called it a day. There’s an interesting dilemma here. If you rely on your users to enter examples, they’re probably not going to think of interesting ones. You’ll either get really simple cases that no system could get wrong, or pathological cases that no system could get right. But if you suggest the examples, the demo is likely to look too stage-managed.
One way to address this dilemma is to help the user look behind the scenes of the system. For instance, if you want to show how the computer actually recognises those companies, a much better way would be to focus your demo on exactly that: What evidence does the model base its guess on? When your model recognises “Facebook”, it doesn’t actually say that Facebook is a technology company. It only says that it’s very, very confident that it is, based on what it’s seen so far. Each of the model’s guesses comes with a confidence – a high number means it thinks the guess is most likely correct, a low number means that it might as well be completely wrong. Now your demo could, for instance, visualise the confidence with percentages or even an interactive graph, and let the user input their own sentences for comparison. How confident is the model that “Pikachu” is a technology company?
While demos typically tease future functionality, they can also be useful tools in their own right. Take displaCy, the interactive visualiser I developed for spaCy. The tool shows you the grammatical structure of any sentence you type in, as predicted by spaCy’s parser (with an accuracy of around 91%). The annotation mode even lets you do manual annotations using the same mechanism as the computer, and ask spaCy for its prediction at any point in the process. displaCy was crucial for demonstrating spaCy’s syntactic parser because the capabilities of the system are abstract and partly arbitrary. Visualisation makes the system easier to use, and easier to improve.

Debugging and Iteration
Whether it’s an app, a consumer service or part of an internal process, the end goal is to use AI technology to power a product. One of the biggest challenges is understanding and addressing the system’s error profile. Your system is almost certainly going to make mistakes. When it does, you want to fail gracefully. It’s hard to do that if you’re running blind, without a good overview of your system’s behaviours. The best way to get that overview is to hook your model up with a front-end as soon as possible.
Statistical errors are like other kinds of performance problems. If you’re developing a mobile app, you obviously prefer your server to reply quickly. However, even if some processes take 30 seconds to complete, you might still be able to build an app that feels snappy. If you can predict a performance problem, you can often find a design that mitigates it.
Seeing the back-end in action on a much smaller scale lets the developer explore the model and inspect the system’s behaviours way before any potential user would start interacting with it. Even at the best of times, humans are famously bad at forming intuitions about what cases are common. Machine learning systems often make unintuitive errors that would be very difficult to guess. The best way to catch these errors is to inspect the system’s output.
For instance, you might decide that your technology company tagger is failing at
cases even you find difficult — the only way you’re figuring out whether some of
these examples are tech companies is to look them up in
CrunchBase. This suggests a simple solution: you
add an is_in_crunchbase feature, and suddenly your model is doing great. In
other cases, the error analysis shows that your model needs more examples of a
particular type. You can use this to bias your data annotation, e.g. by
annotating more tweets, and fewer blog posts.
A more principled solution is to use active learning: you let the model ask the questions, based on what it thinks it doesn’t know. Implementing this obviously requires some additional engineering on the back-end, but the result can be far more efficient than unbiased annotation.
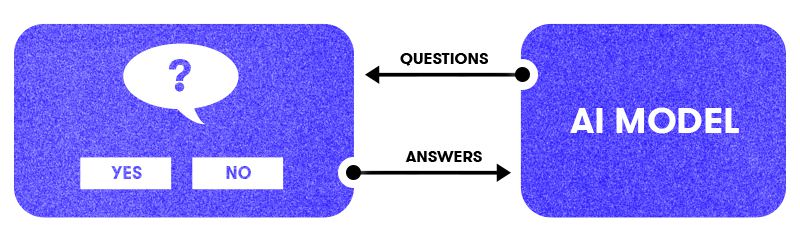
Ultimately, what we’re trying to do is have a human teach things to the computer. In those cases, deciding whether the model is right or wrong is trivial. Netflix is a technology company, “Snorlax” isn’t. If the model “thinks” otherwise, it’s clearly wrong. However, the computer will often know and “remember” a lot of things that the human doesn’t. Active learning lets you exploit this and focus on the interesting cases where a human’s input is actually going to have an impact.
Conclusion
Artificial Intelligence is a fairly abstract area of study. The abstraction seems to reduce, but actually increases the need for front-end development. Abstract technologies are difficult to intuit, making visualisation an indispensible part of the debugging process. They’re also inherently hard to communicate — and when words fail, demos rule. But most importantly, machine learners need human teachers. The task of training a system is fundamentally repetitive, but the lesson from gamification is that a repetitive task can be rewarding rather than aversive, depending on the interaction design.
Just as front-end development is essential for any web-based product’s success today, I believe it will add immeasurable value to the development process of up and coming AI technologies, powering better user-facing products.
Update (January 2018)
Many of the ideas and concepts described in this post went into Prodigy, our new annotation tool powered by active learning. Prodigy lets you collect training and evaluation data with a model in the loop, using the model’s predictions to determine what to ask next. Its web application helps the human annotator focus on one binary decision at a time. For more details, see the website or try the live demo.



