
We’ve talked to Jordan Davis, founder of Love Without Sound, about how he built innovative AI-powered tools for the music industry and law firms specializing in royalty negotiations, and helped publishers recover hundreds of millions of dollars in lost revenue for artists.
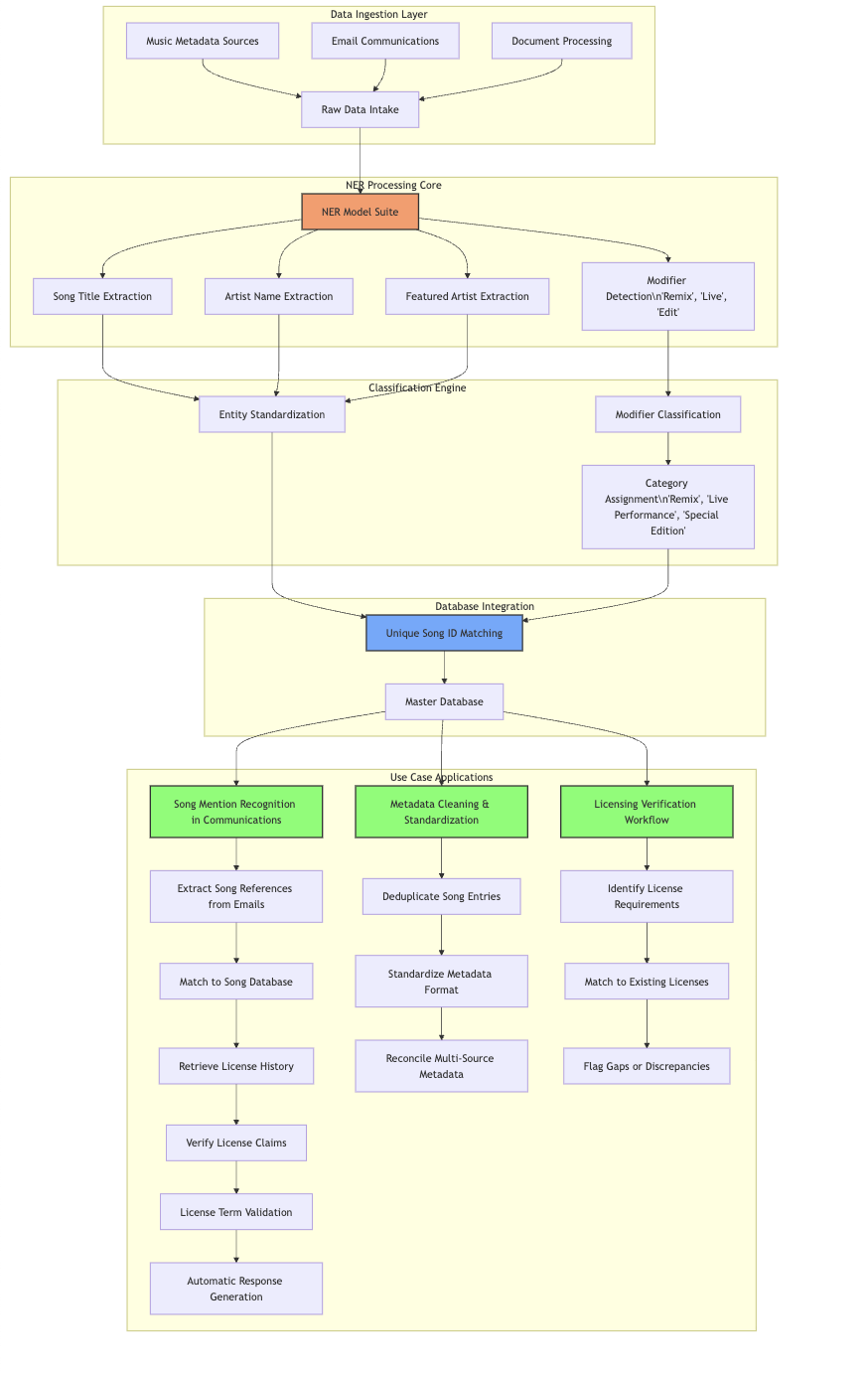
Love Without Sound’s modular suite of Natural Language Processing (NLP) tools includes a model for standardizing metadata of billions of tracks, classifiers for real-time processing of legal correspondence in emails and attachments, and a case citation detection pipeline that recommends counter-arguments and predicts negotiation outcomes. With the help of modern developer tooling, Jordan was able to build new AI features entirely in-house. The models are highly accurate, run fast and are deployed in a fully data-private environment.
NLP-powered tools for the music industry
Large corporations often use music for commercials and other promotional content, including that of up-and-coming artists. In fact, many bands got their start by being featured in TV commercials. However, with fragmented social media platforms and channels for different countries and markets, music is often published in contexts that it wasn’t originally licensed for. This results in millions of lost royalties. Artists are often powerless to monitor this and claim compensation they’re owed, so Love Without Sound helps their labels find and recover royalties for music used without the appropriate license.
This process can also involve extensive legal correspondence and negotiations, with thousands of emails being sent per day. Jordan’s tools help law firms streamline this process and work out licensing deals and settlements to compensate the artists. (For example, in 2020, exercise bike company Peloton paid $300m to settle a lawsuit for using songs by Beyoncé, Maroon 5 and many other artists in their workout videos without permission. And in Germany, then-chancellor Angela Merkel’s party had to stop using The Rolling Stones’ “Angie” as their unauthorized campaign anthem.)

Standardizing structured music metadata
At the core of the solution lies high-quality structured music metadata. Without it, it’s impossible to accurately match up artists and their work. If you collected digital music in the early days of the internet, you might remember messy metadata and ID3 tags. While this is something that shouldn’t be a problem anymore these days, it’s in fact more prevalent than ever. Spotify is receiving approximately 40,000 new tracks per day and 15% of them contain incorrect metadata.
There’s no standard for how featured artists, live versions or remixes are noted in the track information. And while auto-formatting in programs like Excel can be a blessing, it can also mistakenly convert titles like Jay Z’s “4:44” or Beyoncé’s “7/11” to decimals or datetime objects.

This is more than just an annoyance for the listener. Incorrect metadata can lead to songs and even whole albums being attributed incorrectly on streaming platforms like Spotify, which in turn results in royalties being paid out to the wrong artists and labels, or not at all. Estimates suggest $2.5 billion in royalties remained unallocated in the U.S. alone between 2016 and 2018 due to metadata issues. This systemic issue disproportionately affects independent artists.
Indeed, Jordan got the idea for his products after receiving substantial royalty checks for a country singer of the same name, whose songs were mistakenly attributed to him. It turned out the artist’s team had already been searching for these royalties, unable to figure out how they got lost.
I was already aware of the industry’s metadata problem, but this situation was eye-opening. Artists are literally losing money because of basic identification errors. That’s when I realized there’s no effective solution and that I wanted to create one.
— Jordan Davis
To solve this problem, Jordan developed a spaCy pipeline with named entity recognition and text classification components that normalize and standardize song and artist information across a 2 billion-row database. The models extract components like song titles, featured artists, and modifiers like live versions or remixes. They then classify these modifiers and create hierarchical IDs to group related versions of songs.

To create the data, Jordan started by annotating a small sample using Prodigy’s ner.manual recipe and trained a preliminary model. As new data comes in, he uses ner.correct with the model in the loop to review the predictions in the UI and make corrections if necessary. He then retrains the pipeline with Prodigy’s train command.
If there are new client requests or additions to the music catalog, I can simply spin up Prodigy, create a new dataset with more examples and edge cases, and update the model. This keeps the results current and gives me a consistent and continuous process.
— Jordan Davis
Bringing structure to legal documents and negotiations
While negotiations generally take place over the phone, the crucial parts are often found in emails, sandwiched between multiple disclaimer blocks. As a first step towards extracting the contents in a structured format, Jordan developed a classifier to detect the start and end of a message. After extracting message bodies, the correspondence classifier distinguishes substantive business communications from non-essential emails like newsletters and meeting invitations. It then extracts structured data from the relevant emails.

Another area that benefits from automated NLP features is case citation detection. There’s a finite amount of cases that may be cited during negotiations, and arguments that are made in reference to a case. Utilizing a database of cases and arguments, the system is able to recommend appropriate counter-arguments and predict the direction a case is heading in, given the arguments used and a large volume of previous negotiations. This allows law firms to expedite their legal operation at scale and has reduced research time by nearly 50%.

By engaging with the data and iterating on the components and definitions using Prodigy, Jordan was able to break down the complex business problem (“make law firms more productive”) into individual steps that can be solved with machine learning.
What I love about Prodigy is that it makes it really easy to iterate and try out ideas. You often don’t know whether something works until you try it. For example, the email content detection seemed like a silly idea at first, but then I tried it and it worked great. In other cases, I start out with a label scheme and as soon as I engage with the data, I find that I haven’t defined what I’m looking for clearly enough. Prodigy lets me iterate on my schemas and definitions, and build much better models this way.
— Jordan Davis
The end-to-end solution uses a spaCy pipeline consisting of transformer- and CNN-based components for named entity recognition, span categorization and text classification:
- Legal Citation Extraction: Identify case citations and map them to the specific arguments they support.
- Music Reference Extraction: Link references to songs to unique identifiers in the database.
- Request Tracking: Extract explicitly stated or implied action items and requests, classify their urgency and create a real-time dashboard of pending requests.
In addition to the email contents, the attachments are classified as well and critical data points are extracted. For settlement agreements, the system identifies payment deadlines, amounts, and granted rights. For tolling agreements, it highlights key dates and extension provisions. Letters, copyright registrations, licenses, and any other common documents are also processed and forwarded to the relevant part of the system. For PDF contracts and agreements, Jordan uses a signature detection component that finds signature blocks and classifies them as signed or unsigned.
End-to-end music reference extraction
When songs are mentioned in the correspondence, the system links these references to unique identifiers in its music metadata database. This enables quick verification of licensing claims and provides essential context to guide Love Without Sound’s clients in making informed decisions.
When I discovered spaCy, it immediately answered all my questions! Our spaCy extraction pipeline has transformed license management and copyright registration analysis, and made supporting record labels and artists much faster and more successful.
— Jordan Davis
Future plans and work in progress
With the large volumes of metadata, finding the right information quickly can become a challenge. Jordan is currently building a custom Retrieval-Augmented Generation (RAG) pipeline for querying case history and artist information with both SQL and natural language. The main job of the Large Language Model (LLM) is to translate the natural language question into the right SQL queries, a clearly defined task that allows utilizing a smaller model that ideally runs privately on-premise.
Jordan is also working on a musical audio embedding model that structures audio data based on sonic properties rather than metadata. It can then map related tracks, including remixes, samples and songs with production similarities, to proximate vector positions. Using this approach, the system will be able to identify further metadata inconsistencies, verify rights management claims and enable content-based recommendations.
Results and evaluation
Legal documents and financial information of artists and businesses are highly confidential, so all models and applications need to run locally in a data-private environment. The pipelines also need to operate fast to be able to process emails and attachments in real time, and handle music catalogs with millions of tracks and their metadata. Jordan opted to train separate models for each feature, which can be combined freely by the application. This keeps the solution extremely modular. It also means that each component can be developed, improved and evaluated separately. For more details and evaluation results, see the in-depth materials.
| Component | Type | Labels | Accuracy1 | Speed2 |
|---|---|---|---|---|
| Metadata Extraction (Songs) | ner | 3 | 0.94 | 6,217 |
| Metadata Extraction (Artists) | ner | 2 | 0.93 | 1,696 |
| Metadata Extraction (Modifiers)3 | textcat | 5 | 0.99 | 447,493 |
| Correspondence Classification4 | textcat | 1 | 0.98 | 587,907 |
| Email Body Extraction | ner | 2 | 0.90 | 13,923 |
| Attachment Classification | textcat | 9 | 0.98 | 2,831 |
| Legal Agreement Section Classification | textcat | 38 | 0.92 | 11,765 |
| Legal Agreement Span Extraction5 | spancat | 3 | 0.94 | 306 |
| Legal Agreement Entity Extraction | ner | 5 | 0.92 | 3,337 |
| Legal Citation Extraction | ner | 1 | 0.98 | 14,809 |
To train the models and process data at scale, Jordan uses Modal, a serverless cloud platform that provides high-performance computing for AI models and large batch jobs. It gives developers cost-effective access to both CPU and GPU resources on demand, without having to worry about infrastructure setup. Just like spaCy and Prodigy, Modal is fully scriptable in Python and its developer API smoothly integrates into existing workflows.
Jordan’s workflows and results are great examples of how modern developer tooling can make even the smallest teams with limited resources super productive. Love Without Sound identified a specialized, high-value use case in an industry, and was able to create new AI products, models and datasets in house. With LLMs not only providing development support, but also the ability to automate data development and create systems, we’ll likely see many more success stories like this in the future.
🎵 Bonus: Jordan’s NLP development playlist
Resources
- In-depth materials: More details, figures and sources used in this case study
- Prodigy: A modern annotation tool for NLP and machine learning
- Prodigy for legal data: Bring structure to your legal and regulatory documents or domain-specific contracts
- Named Entity Recognition with spaCy: Documentation and examples
- Span Categorization with spaCy: A new approach for extracting arbitrary and potentially overlapping spans of text
- Named Entity Recognition with Prodigy: Documentation and workflows
- Modal: High-performance serverless cloud for developers
- Serverless custom NLP with LLMs, Modal and Prodigy: Build a fully custom information extraction model, no infrastructure or GPU setup required
- From PDFs to AI-ready structured data: A new modular workflow for processing PDFs with spaCy
- Applied NLP Thinking: How to translate business problems into machine learning solutions
- What the history of the web can teach us about the future of AI: How developer tooling makes it possible to develop AI features in house
- Metadata is the biggest little problem plaguing the music industry: Article by The Verge on the music metadata problem
- Case Studies: Our other real-world case studies from industry



