How Love Without Sound helps the music industry recover millions in revenue for artists with NLP, spaCy and ProdigyA case study on Love Without Sound’s innovative AI-powered tools for the music industry and law firms specializing in royalty negotiations.
Introducing spaCy v3.6spaCy v3.6 introduces the span finder component and trained pipelines for Slovenian.
Spancat: a new approach for span labelingThe SpanCategorizer is a spaCy component that answers the NLP community's need to have structured annotation for a wide variety of labeled spans, including long phrases, non-named entities, or overlapping annotations. In this blog post, we're excited to talk more about spancat and showcase new features to help with your span labeling needs!
Mastering spaCyDéborah Mesquita, Duygu Altinok (Packt Publishing, 2025)Build structured NLP solutions with custom components and models powered by LLMs. By end of the book you will be empowered to build robust NLP pipelines and integrate them with web applications to build end-to-end solutions.
SpanCat with spaCy and Prodigy on real dataYouTube series by WJB Mattingly showing an end-to-end project, from cultivating and annotating data to training, testing and visualizing a model.
Introducing spaCy v3.3spaCy v3.3 improves the speed of core pipeline components, adds a new trainable lemmatizer, and introduces trained pipelines for Finnish, Korean and Swedish.
From PDFs to AI-ready structured data: a deep diveThis blog post presents a new modular workflow for converting PDFs and similar documents to structured data and shows you how to build end-to-end document understanding and information extraction pipelines for industry use cases.
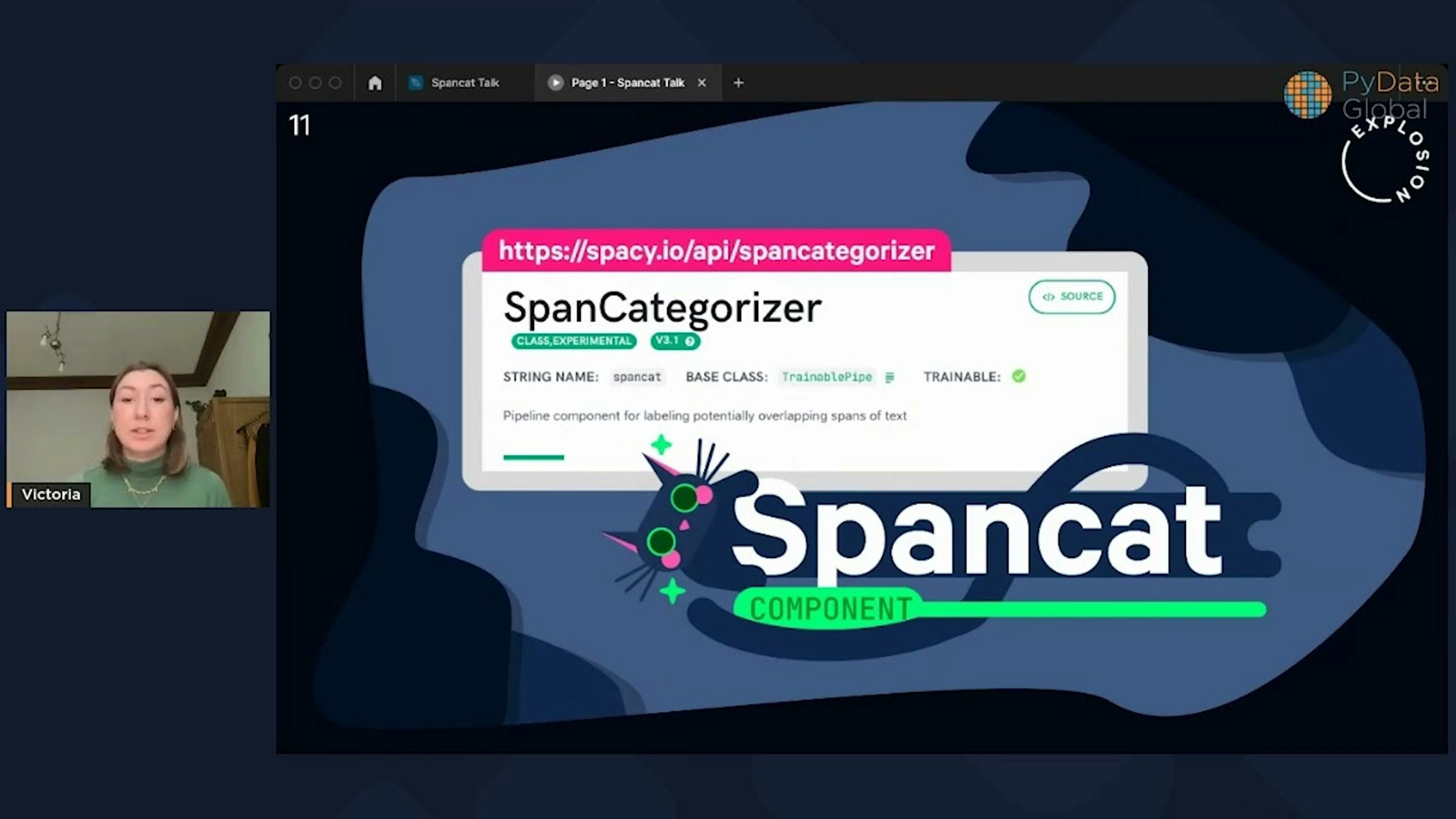
Is it possible to have entities within entities within entities?PyData Global 2022Named entity recognition models might not be able to handle a wide variety of spans, but Spancat certainly can! Dive into named entity recognition, its limitations, and how we’ve solved them with a solution-focused talk and practical applications.
Mastering spaCyDuygu Altinok (Packt Publishing, 2021)An end-to-end practical guide to implementing NLP applications using the Python ecosystem. By the end of this book, you'll be able to confidently use spaCy, including its linguistic features, word vectors, and classifiers, to create your own NLP apps.
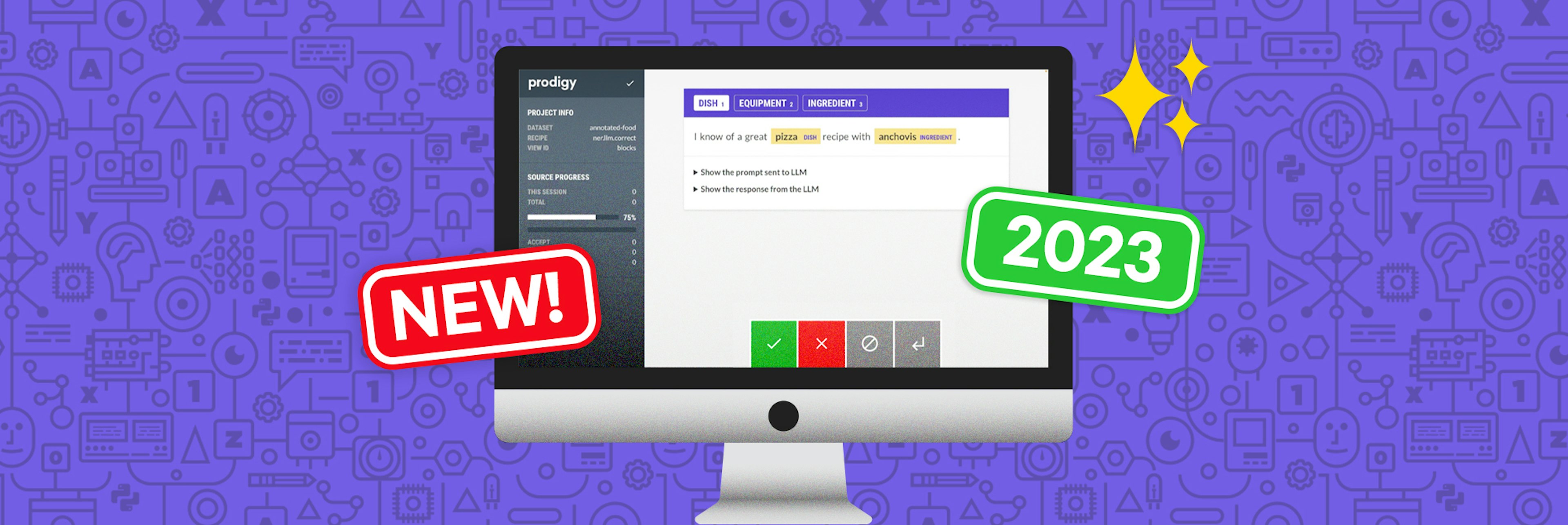
Prodigy in 2023: LLMs, task routers, QA and pluginsWe have made a ton of new updates in Prodigy this year with v1.12, v1.13, and v1.14 releases. So we decided to write a post about them.
Introducing Span Categorization in Prodigy and spaCyIn this video, we’ll show you how to use Prodigy for spaCy’s Span Categorizer. We’ll be annotating food recipes and looking into ways to help with consistent annotations and speed up the process with patterns and temporary models.
✨ prodigy v1.11.0Aug 12, 2020spaCy v3 support, annotation for overlapping and nested spans, better installation & more
Introducing spaCy v3.1It’s been great to see the adoption of spaCy v3, which introduced transformer-based pipelines, a new training system and more. Version 3.1 adds more on top of it, including the ability to use predicted annotations during training, a component for predicting arbitrary and overlapping spans and new pipelines for Catalan and Danish.