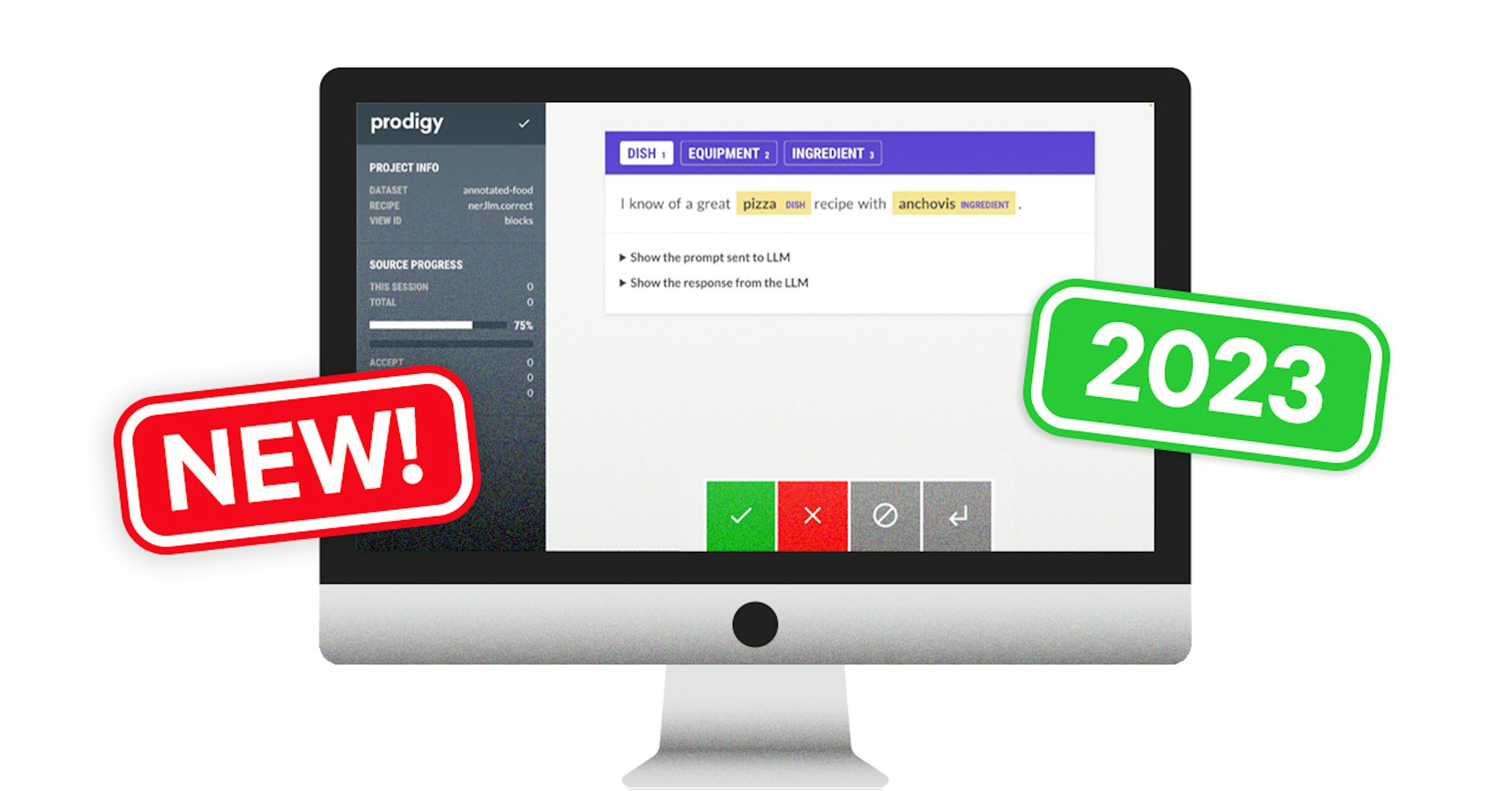
This year our releases of Prodigy v1.12, v1.13 and v1.14 are our biggest in almost two years. Throughout 2023, we have introduced support for Large Language Models (LLMs) through spacy-llm, added customizable task routing, expanded our QA features with inter-annotator agreement metrics, infused more interactivity into the UI, and shared several open-source Prodigy plug-ins with the community.

Boosting annotator efficiency with Large Language Models
In July and August, we released LLM-assisted recipes for data annotation and prompt engineering:
- NER:
ner.llm.correct,ner.llm.fetch - Spancat:
spans.llm.correct,spans.llm.fetch - Textcat:
textcat.llm.correct,textcat.llm.fetch - Prompt engineering and terms:
ab.llm.tournamentterms.llm.fetch

These recipes allow you to craft a prompt for a number of NLP tasks and use LLMs to “preannotate” the data for you. This can speed up the annotation process significantly as the annotator is now focusing on curating the model’s annotation rather than starting from scratch. It’s a shift from mundane manual annotation to a more nuanced and strategic role, enhancing efficiency and precision in the overall annotation workflow.
The text-in, text-out interface of our recipes means you can try to engineer a prompt that the large language model can use to perform a specific task that you’re interested in. While this approach is not perfect and part of on-going research, it does offer a general method to construct prompts for many typical NLP tasks such as NER or text classification.
If you would like to define an LLM-assisted annotation for other NLP tasks,
that’s also possible because our LLM workflows are powered by
spacy-llm which means a complete
flexibility in terms of prompt, task and the LLM backend specification. All
these settings can be conveniently defined via the spaCy config system, which makes
it easy to keep your environment reproducible and well organized.
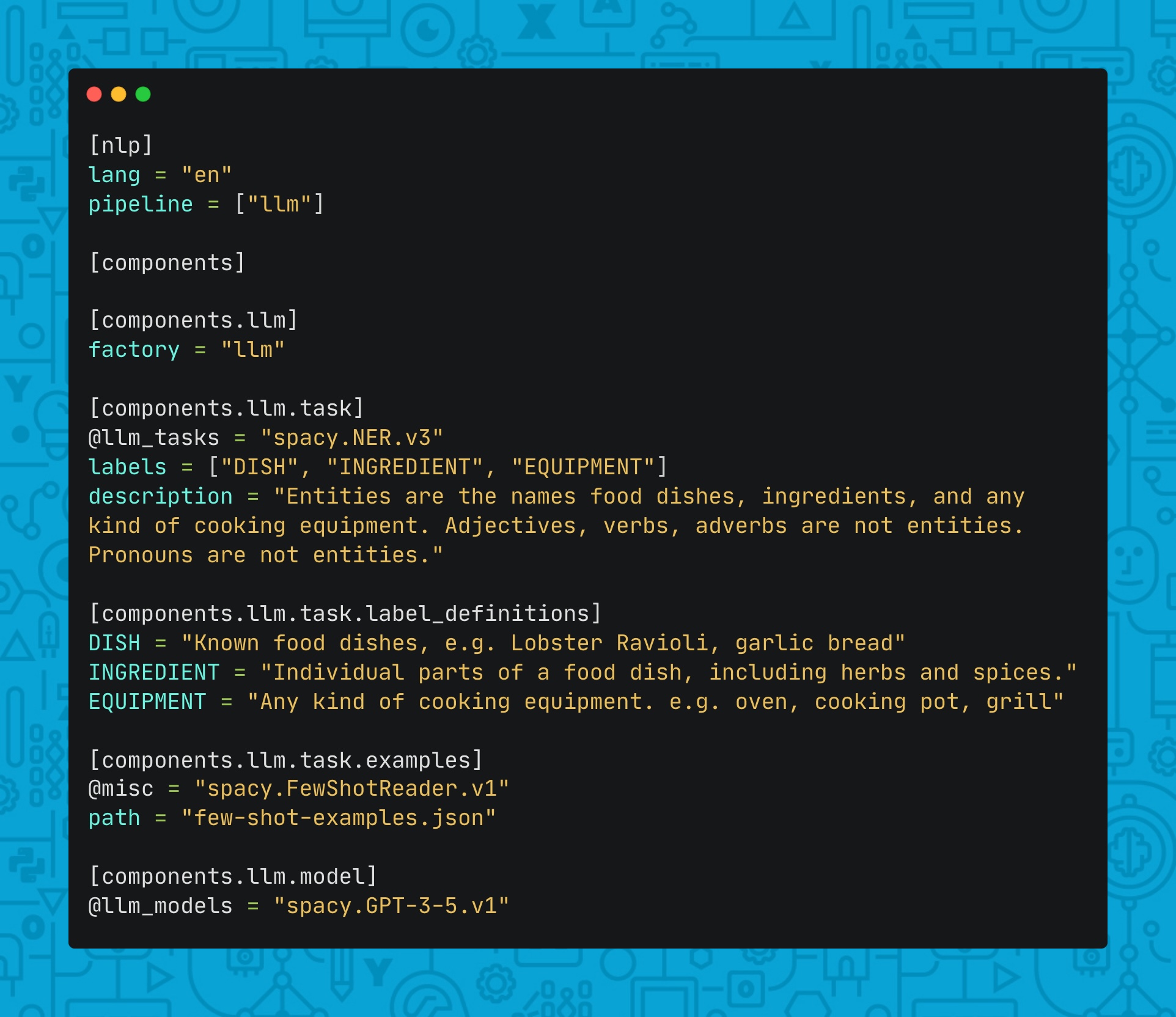
There are several other advantages of leveraging spacy-llm for LLM workflows
in Prodigy which are worth pointing out:
- choose from a variety of LLM providers (OpenAI, Anthropic, Cohere) or even
a locally running model (Dolly, Falcon, OpenLLaMa), eliminating the need to
send your data to a third-party. A full list of supported models can be found
on
spacy-llmdocs, and you can even hook up your own. - built-in cache support to reduce API costs
- improve your prompts by adding examples and label definitions for your task
Most importantly, the tasks and prompts are under active development from the
spaCy team so all the upgrades to spacy-llm can be expected to be directly
transferable to your Prodigy workflows (and we make sure there’s plenty of
documentation on our end to make the use of it easier). For example, as of v1.14.0
you can define your prompt using the
chain-of-thought
technique. And there is more to come! Entity linking task is anticipated as the
next likely addition. A full list of supported tasks is provided on the
spacy-llm docs or even try
your own!
Prompt engineering forms an important part of any LLM based workflow. To
facilitate making an informed decision while choosing the most optimal prompt,
we developed the
ab.llm.tournament recipe.
This recipe employs an algorithm inspired by the Glicko rating system to set up
duels between different prompt/LLM combinations. By letting the user mark the
winner of each duel through the selection of their preferred version of the
generated text, the recipe promotes a systematic method for identifying the most
effective prompt/LLM combination. If you’re interested in the details of the
algorithm be sure to check the author’s Andy Kitchen’s
GitHub.
Expanding functionality with Prodigy Plugins
Another big update is the introduction of Prodigy plugins. Prodigy Plugins are open-source add-ons that can be installed separately from the main Prodigy library. They are meant to provide recipes using third-party libraries, which opens up lots of possibilities for new custom recipes without worrying about Prodigy dependencies. We created new docs for Prodigy plugins and plan to keep adding new ones too!
| 🤗 Prodigy HF | Recipes that interact with the Huggingface stack. | Github repo |
| 📄 Prodigy PDF | Recipes that help with the annotation of PDF files. | Github repo |
| 🤫 Prodigy Whisper | Recipes that leverage OpenAI’s Whisper model for audio transcription. | Github repo |
| 🏘 Prodigy ANN | Recipes that allow you to use approximate nearest neighbor techniques to help you annotate. | Github repo |
| 🌕 Prodigy Lunr | Recipes that allow you to use old-school string matching techniques to help you annotate. | Github repo |
| 🦆 sense2vec | Recipes that allow to fetch terms using phrase embeddings trained on Reddit. | Github repo |
Manage multi-annotator workflows with Task Routers
Another new feature is Task Routing, which was released in v1.12.0. Task Routers allow you to distribute the annotation workload among multiple annotators. You can make sure examples receive a specific number of annotations or even set up custom routing so that those examples get seen by certain annotators.
Before Prodigy v1.12, with
named multi-user sessions,
you could configure how examples should be sent out across multiple sessions by
using Prodigy’s feed_overlap setting. This setting permits either a complete
overlap i.e. each annotator annotates each task, or no overlap at all i.e. each
task is annotatated only once.
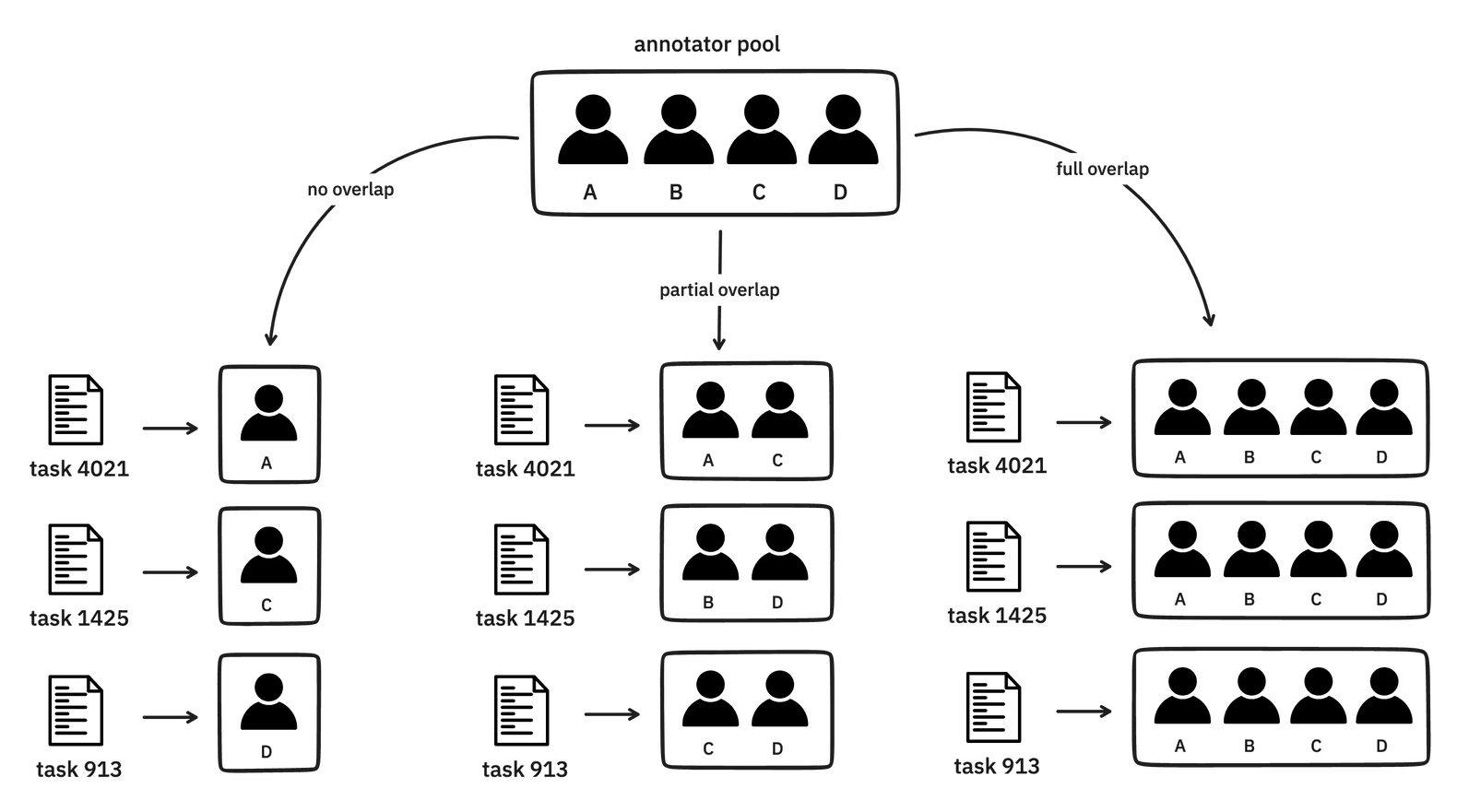
As of Prodigy v1.12+, apart from the complete overlap setting (or lack thereof)
you can also opt for a partial overlap. You have two options here: adjust
the annotations_per_task setting in the Prodigy
configuration file to specify the
average number of annotations per example, or create a
custom task routing function.
This function would output a list of session names to direct the example to, and
it should be passed to a new recipe component
task router. Apart from
the task router, in Prodigy v1.12.0 we have also exposed the
session factory
component that allows you to fully customize the process of session
initialization e.g. you could prepopulate each new session with a custom
history.
task router and session factory components enable the implementation of
highly customized annotation protocols. For example, tasks could be distributed
based on the model score or the annotator’s expertise. Check out
our guide on task routing for more details
and ideas.
Monitoring QA with inter-annotator agreement metrics
In early October, we released inter-annotator metrics in v1.14.3 including two new commands for computing inter-annotator agreement for document level and token level annotations:
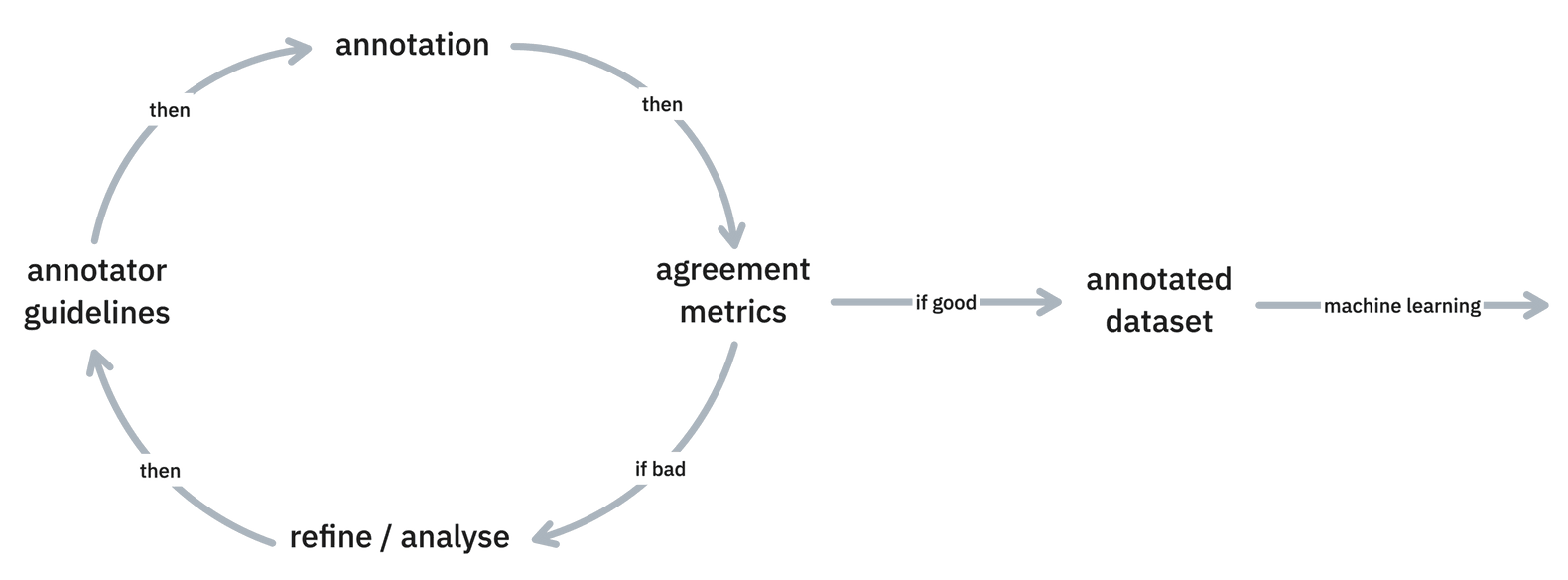
Ensuring annotator agreement is crucial in ML training as disagreements signal issues like ambiguity or insufficient annotator coaching. IAA metrics help fine-tune guidelines early in the project, fostering a shared understanding for accurate dataset annotation.
Prodigy provides three built-in IAA metrics for document-level annotations:
- Percent (Simple) Agreement
- Krippendorf’s Alpha
- Gwet’s AC2
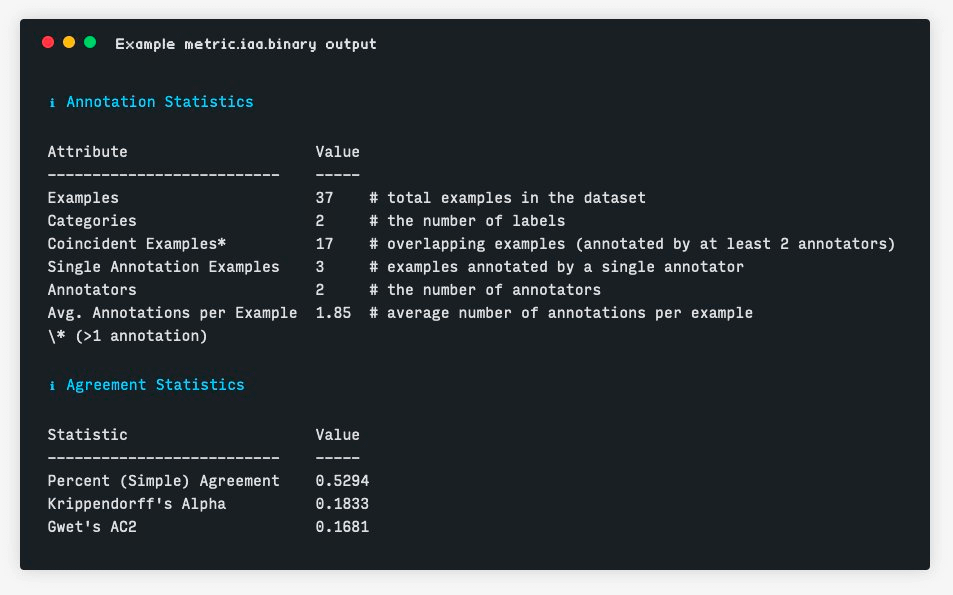
Krippendorf’s Alpha and Gwet’s AC2 (as opposed to Cohen’s Kappa) have some nice properties that make them well suited multi-annotator datasets such as that they do not require full overlap, they can handle more than two annotators, and they can scale to large category sets.
For token-level annotation we propose the pairwise F1 score, that also comes with a confusion matrix to help identify problematic pairs of categories.
For more details, check out our new Metrics section in the docs.
Customize progress tracking
Also in Prodigy v1.12, we refactored the internal representation of the stream of tasks and the underlying input source in a way that the stream object is aware of the source object, its type, and how much of it has been consumed.
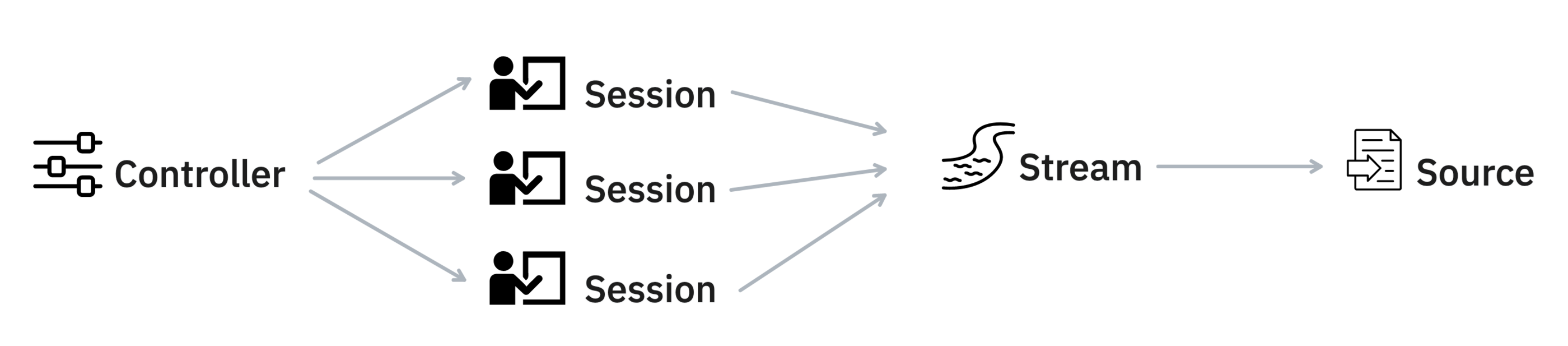
This allows us to provide more tractable progress tracking in projects where the target number of annotations is not known upfront. This was tricky when the stream was an opaque generator disconnected from the data source. In fact, we now distinguish between different types of progress in the front-end i.e. the progress (for custom functions), source progress (based on the progress through the input source) and the target progress (based on the set target). Since all these new progress bars have slightly different semantics be sure to check our docs on progress for extra context.
Prioritize tasks based on models’ disagreements
As of v1.13.1 Prodigy added new “model as annotator” recipes including:
These recipes can add annotations to a dataset from a model as if they were done by an annotator. These recipes support any spaCy pipeline, which includes pipelines that use large language models as a backend.
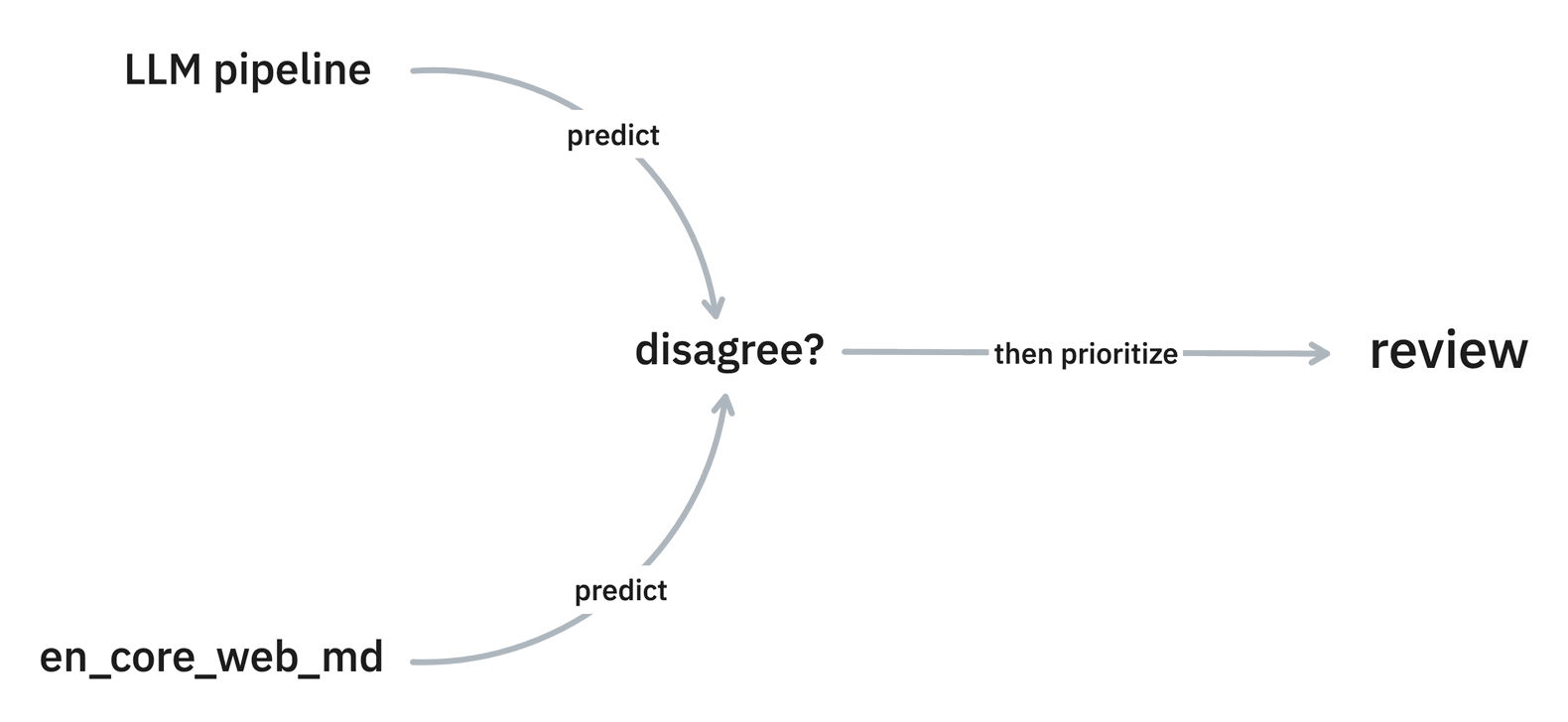
These “model as annotator”-recipes work great together with the review recipe because they allow you to focus on examples where models disagree and it’s these examples that might be interesting candidates to annotate first.
More interactive UI
We’ve wanted to add more interactivity to Prodigy UI for while. With Prodigy v1.14.1 we shipped custom event hooks, which allow the user to define their own event handlers for custom interfaces. Custom events are registered functions that can be returned from a recipe and called via the Prodigy frontend. We believe it’s a great feature for e.g. swapping the model in model-in-the-loop annotation workflows. Check out the Custom Event docs for more details or this reproducible LLM example.
 without restarting the Prodigy server")
We’ve also got great results in one of our consulting projects when hooking up Prodigy recipes with a knowledge base to look up entities on the fly, while annotating.
In future, we are planning to support even more customization by allowing the users to define their custom web components. In the meantime, we have improved the DX of interface customization by supporting the mounting of javascript and css from local directories and remote URLs. This means that you can even add a full-fledged framework like HTMX to your custom recipe and create a fully dynamic interface with custom events.
Other updates
We’ve also made lots of smaller fixes including new docs, bug fixes, and added additional recipes or support:
Recipes
- Added validation for empty annotations for exclusive textcat models in
textcat.manualandtextcat.correct. - Added
--accept_emptyflag totextcat.manualandtextcat.correctto turn off the new validation. - A new
filter-by-patternsrecipe - Experimental support for training coref models
Interfaces
- Added
llm-iointerface to show the prompt/response from an LLM. - Added a toggle for switching between character and token highlighting in
ner_manualandspans_manualUIs.

API
- Added
filter_seen_beforehelper functions to make it easier to remove specific duplicates from your stream in custom recipes. - Added
make_ner_suggestions, similarly fortextcatandspancattoo. These functions make it easier to turn spaCy output into annotation examples. - Added
allow_work_stealingsetting inprodigy.jsonthat allows you to turn off work stealing. - Added
PRODIGY_LOG_LOCALSenvironment variable to supply local variables for when debugging Prodigy error messages
Support
- Add support for
spacy3.6-3.7,Pydanticv2.0, andspacy-llm0.6. - Python 3.11 support (dropping Python 3.7 support)
- Support for Parquet input files
Resources
- Prodigy Changelog: Detailed overview
- Prodigy Teams: Get a sneak peak and sign up for our waitlist!
- spaCy-llm: Projects, plugins and extensions
- Prodigy Large Language Models docs: Details on LLM recipes
- Prodigy Task Router docs: Details on Task Routing
- Prodigy Review docs:
reviewrecipe andmodel-annotaterecipes - Prodigy Deployment docs: Design patterns for deploying Prodigy



