Atomic NLPAn applied NLP methodology inspired by Atomic Design: building reliable language understanding systems out of small, composable components instead of one big model and a prompt.
Building AI with AIPyCon Ireland KeynoteAI-powered coding assistants have transformed the way we build software, and AI itself. In this talk, Ines shows why we should use LLMs to build systems instead of as systems, and why code is more important than ever, not less.
How Love Without Sound helps the music industry recover millions in revenue for artists with NLP, spaCy and ProdigyA case study on Love Without Sound’s innovative AI-powered tools for the music industry and law firms specializing in royalty negotiations.
Distill Your LLMs and Surpass Their PerformanceInfoQ MagazineIn her presentation at InfoQ Dev Summit, Ines Montani provided the audience with practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components.
Applied NLP in the Age of Generative AIPyData Amsterdam KeynoteIn this talk, Ines shares the most important lessons we’ve learned from solving real-world information extraction problems in industry, and shows you a new approach and mindset for designing robust and modular NLP pipelines in the age of Generative AI.
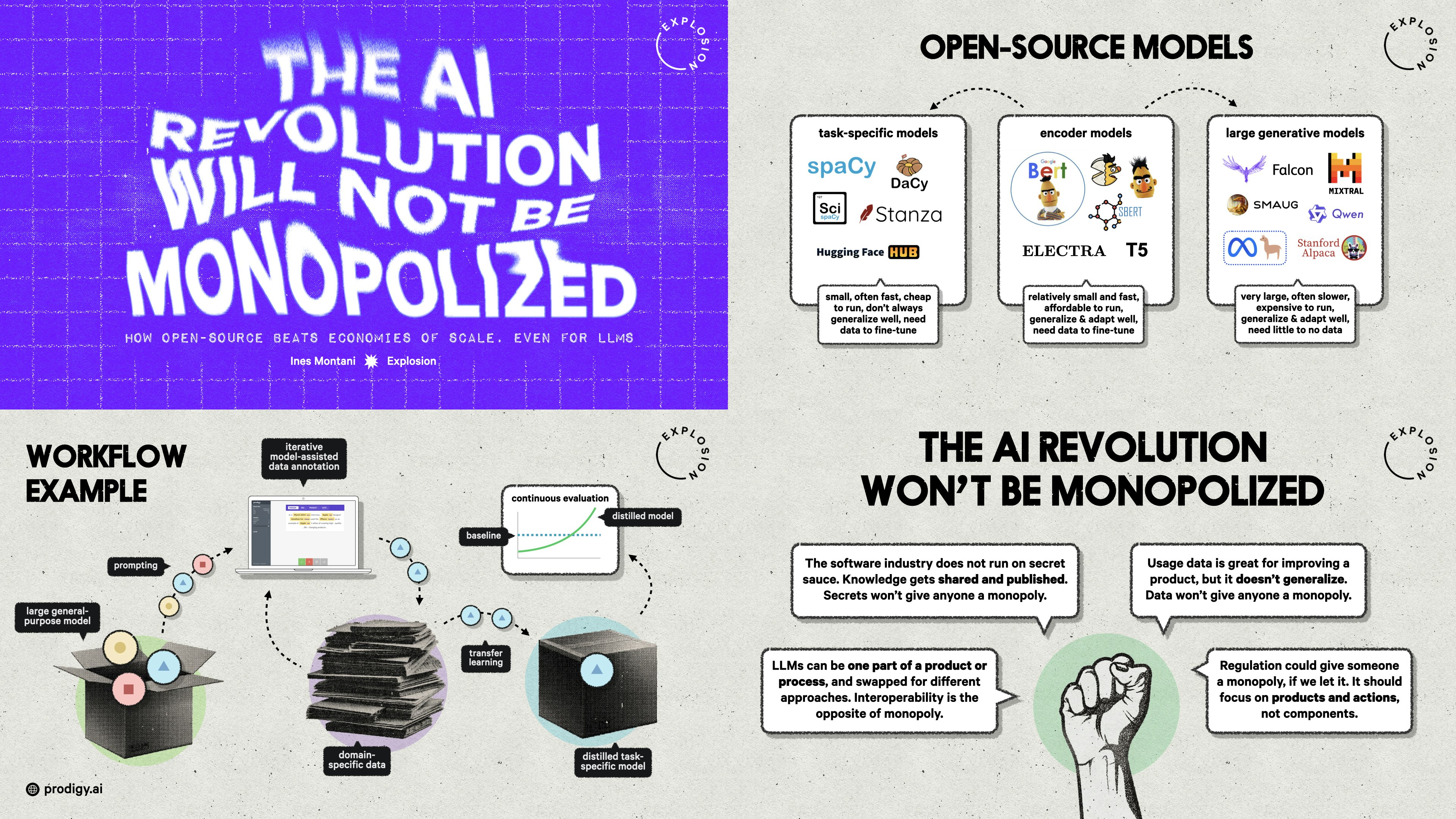
The AI Revolution Will Not Be MonopolizedInfoQOpen-source initiatives are pivotal in democratizing AI technology, offering transparent, extensible tools that empower users. Daniel Dominguez summarizes the key takeaways from Ines’ recent talk for InfoQ.
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillationPyData LondonLLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, Ines shows some practical solutions for using the latest models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsPyCon DE & PyData BerlinWith the latest advancements in NLP and LLMs, and big companies like OpenAI dominating the space, many people wonder: Are we heading further into a black box era with larger and larger models, obscured behind APIs controlled by big tech monopolies?
Against LLM maximalismLLMs are not a direct solution to most of the NLP use-cases companies have been working on. They are extremely useful, but if you want to deliver reliable software you can improve over time, you can't just write a prompt and call it a day. Once you're past prototyping and want to deliver the best system you can, supervised learning will often give you better efficiency, accuracy and reliability.
spaCy behind the scenes: library patterns & design concepts explainedDeveloper productivity has been central to our design of spaCy, both in smaller decisions and some of the bigger architectural questions. We believe in embracing the complexities of machine learning, not hiding it away under leaky abstractions, while also maintaining the developer experience. Read on to learn some of the design patterns within the library, how we've implemented them, and most importantly, why.
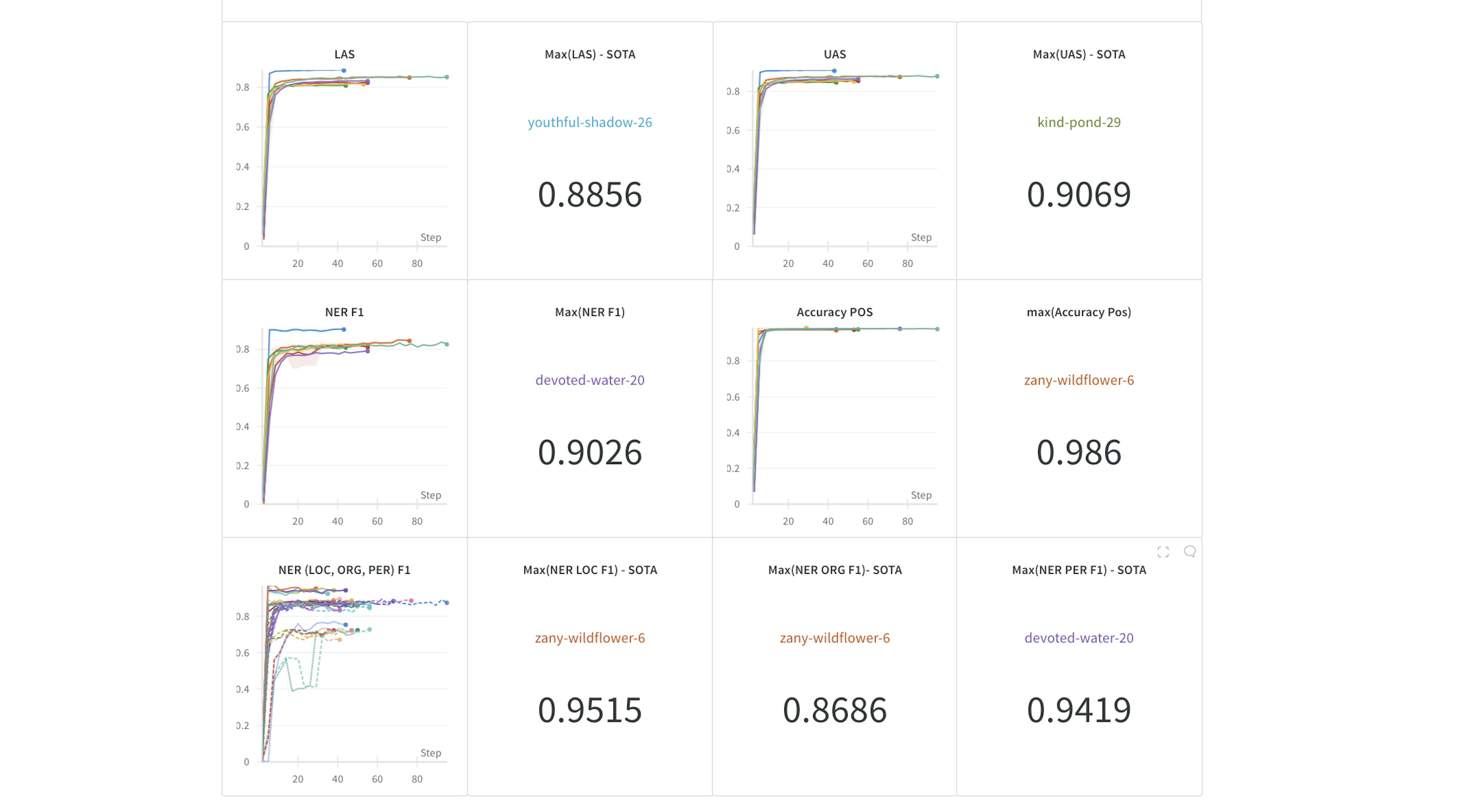
Reproducible spaCy NLP Experiments with Weights & BiasesWeights & Biases BlogThis tutorial will show how to add Weights & Biases to any spaCy NLP project to track your experiments, save model checkpoints, and version your datasets.
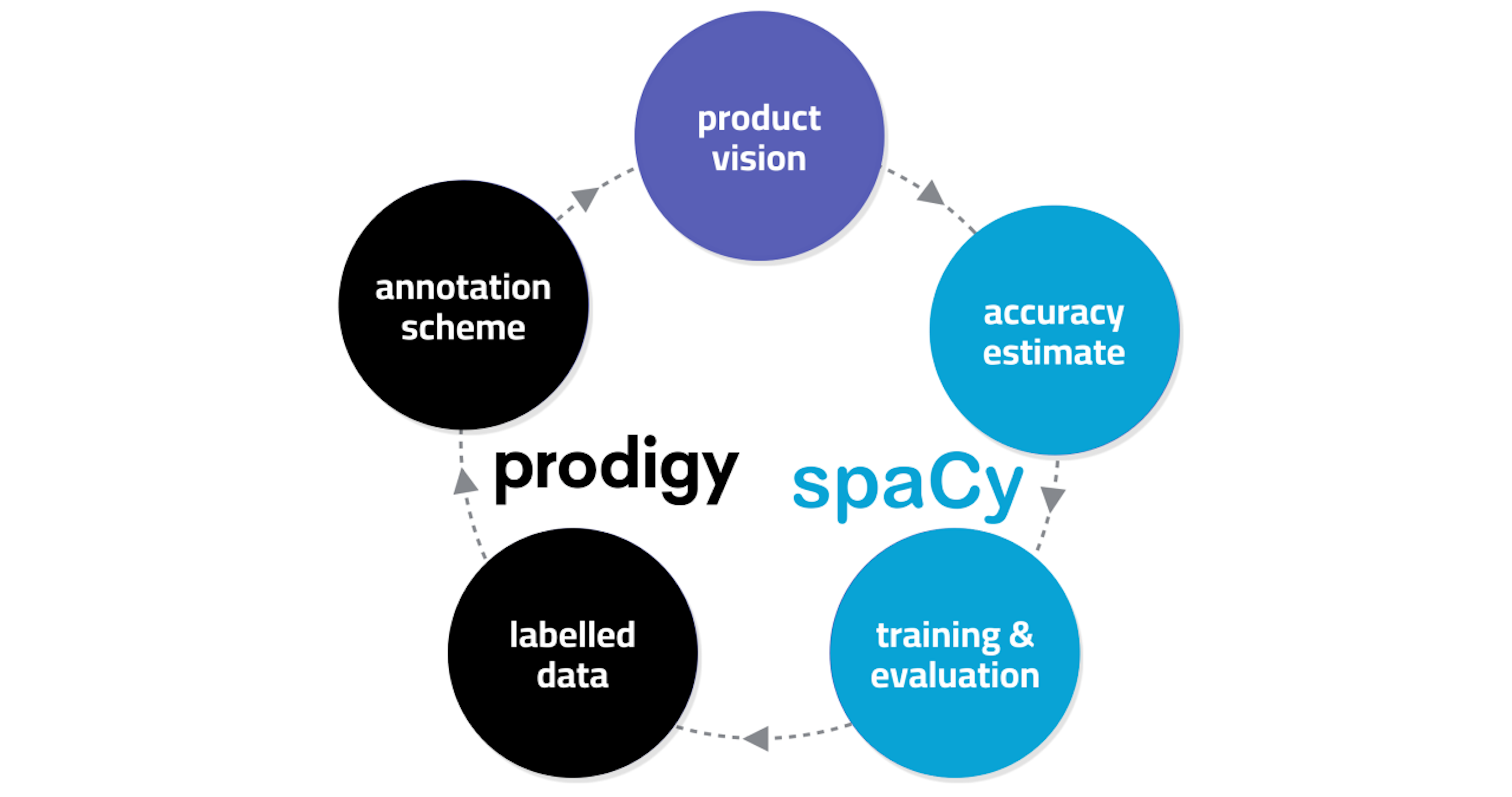
Building new NLP solutions with spaCy and ProdigyPyData Berlin“Commercial machine learning projects are currently like start-ups: many projects fail, but some are extremely successful, justifying the total investment. While some people will tell you to embrace failure, I say failure sucks — so what can we do to fight it? In this talk, I will discuss how to address some of the most likely causes of failure for new NLP projects.”
Vibe NLP for Applied NLPPyCon DE & PyDataWhat if we could take learnings from AI-powered coding agents and apply them to solving real-world NLP problems? In this talk, I’ll show how we’ve built a powerful virtual NLP assistant to help developers create practical and modular solutions that are small, fast and fully data-private.
Conquering PDFs: document understanding beyond plain textPyData LondonIn this talk, Ines presents a new and modular approach for building robust document understanding systems, using state-of-the-art models and the awesome Python ecosystem.
What the history of the web can teach us about the future of AIHow will AI development look in the future? There is a lot we can learn from another groundbreaking technology: the web. This blog post takes a look at what the history of the web can teach us, and what this means for developers, models, open source and regulation.
How GitLab uses spaCy to analyze support tickets and empower their communityA case study on GitLab’s large-scale NLP pipelines for extracting actionable insights from support tickets and usage questions.
A practical guide to human-in-the-loop distillationThis blog post presents practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
Towards Structured Data: LLMs from Prototype to ProductionU.S. Census Bureau: Center for Optimization and Data Science SeminarThis talk presents pragmatic and practical approaches for how to use LLMs beyond just chat bots, how to ship more successful NLP projects from prototype to production and how to use the latest state-of-the-art models in real-world applications.
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsQCon London
Diary of a spaCy project: Predicting GitHub TagsMany people assume that working on an NLP project involves a lot of machine learning. Our experience is that it's much less about flowing tensors, and more about making a tailored solution. This blogposts demonstrates how a typical spaCy project could be initiated, implemented and executed towards a custom solution.
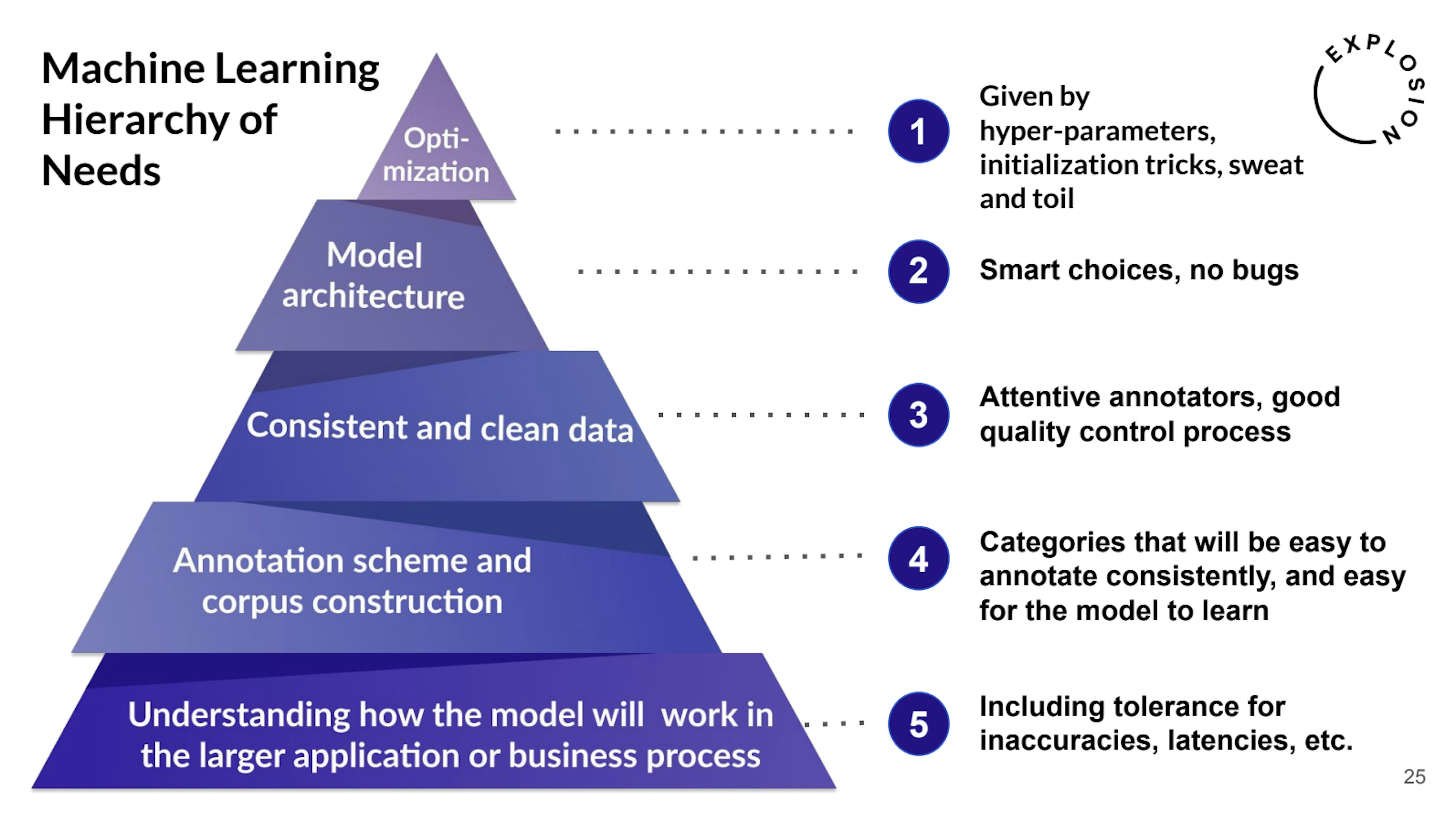
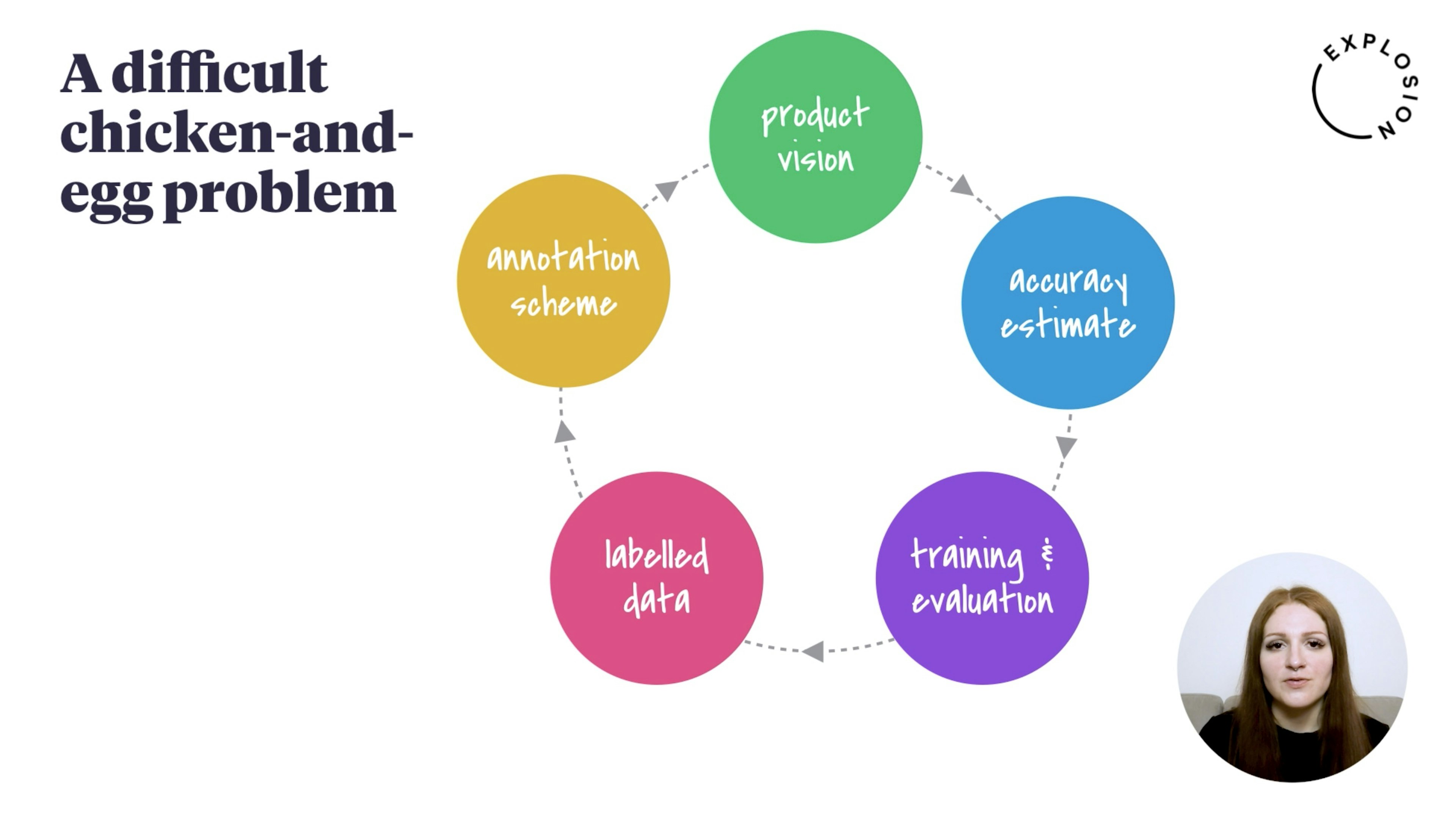
Applied NLP Thinking: How to Translate Problems into SolutionsWe’ve been running Explosion for about five years now, which has given us a lot of insights into what Natural Language Processing looks like in industry contexts. In this blog post, I’m going to discuss some of the biggest challenges for applied NLP and translating business problems into machine learning solutions.
The ultimate guide to optimizing annotation workflowsThis blog post collects tips and advice for how to build efficient human-in-the-loop data development workflows, break down business problems into actionable annotation steps and make the most of automation and model assistance.
Conquering PDFs: document understanding beyond plain textPyCon DE & PyDataIn this talk, Ines presents a new and modular approach for building robust document understanding systems, using state-of-the-art models and the awesome Python ecosystem.
What the history of the web can teach us about the future of AIPyCon+Web KeynoteIn this talk, Ines takes a look at what the history of the web can teach us about the future of AI, and what this means for developers, models, open source and regulation.
Applied NLP with LLMs: Beyond Black-Box MonolithsPyBerlinIn this talk, Ines shows some practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components.
Practical Tips for Bootstrapping Information Extraction PipelinesDataHack SummitThis talk presents approaches for bootstrapping NLP pipelines and retrieval via information extraction, including tips for training, modelling and data annotation.
How S&P Global is making markets more transparent with NLP, spaCy and ProdigyA case study on S&P Global’s efficient information extraction pipelines for real-time commodities trading insights in a high-security environment.
spaCy meets LLMs: Using Generative AI for Structured DataData+ML Community MeetupThis talk dives deeper into spaCy’s LLM integration, which provides a robust framework for extracting structured information from text, distilling large models into smaller components, and closing the gap between prototype and production.
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsPyCon Lithuania KeynoteWith the latest advancements in NLP and LLMs, and big companies like OpenAI dominating the space, many people wonder: Are we heading further into a black box era with larger and larger models, obscured behind APIs controlled by big tech monopolies?
Setting your ML project up for success“What can you do to maximize probability of success for your Machine Learning solution? Throughout my 15 years as data scientist in academia, big pharma and through consulting, one common theme has emerged: the most reliable predictor of success for any NLP or ML-based solution is whether or not you involve the data science team early on.”
Introducing spaCy Tailored PipelinesExplosion is pleased to announce a new development services offering, spaCy Tailored Pipelines. We’ll build you a custom natural language processing pipeline, delivered in a standardized format using spaCy’s projects system.
Engineering a human-aligned LLM evaluation workflow with Prodigy and DSPyThis post demonstrates a human-in-the-loop workflow for developing and evaluating LLMs, using Prodigy and DSPy to create task-specific, human-aligned metrics that guide model optimization beyond generic evaluation measures.
How to advocate for modular NLP in the age of Generative AIWith all the hype around Generative AI, many are led to believe it’s the solution to everything. So how can you, as a developer, communicate the nuances and advocate for new and modular solutions that are better, easier and cheaper?
From PDFs to AI-ready structured data: a deep diveThis blog post presents a new modular workflow for converting PDFs and similar documents to structured data and shows you how to build end-to-end document understanding and information extraction pipelines for industry use cases.
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillationInfoQ Dev SummitLLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, Ines shows some practical solutions for using the latest models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
The Window-Knocking Machine TestHow will technology shape our world going forward? And what tools and products should we build? When imagining what the future could look like, it helps to look back in time and compare past visions to our reality today.
How to uncover and avoid structural biases in evaluating your Machine Learning/NLP projectsPyData LondonThis talk highlights common pitfalls that occur when evaluating ML and NLP approaches. It provides comprehensive advice on how to set up a solid evaluation procedure in general, and dives into a few specific use-cases to demonstrate artificial bias that unknowingly can creep in.
Economies of Scale Can’t Monopolise the AI RevolutionInfoQ MagazineDuring her presentation at QCon London, Ines Montani stated that economies of scale are not enough to create monopolies in the AI space and that open-source techniques and models will allow everybody to keep up with the “Gen AI revolution”.
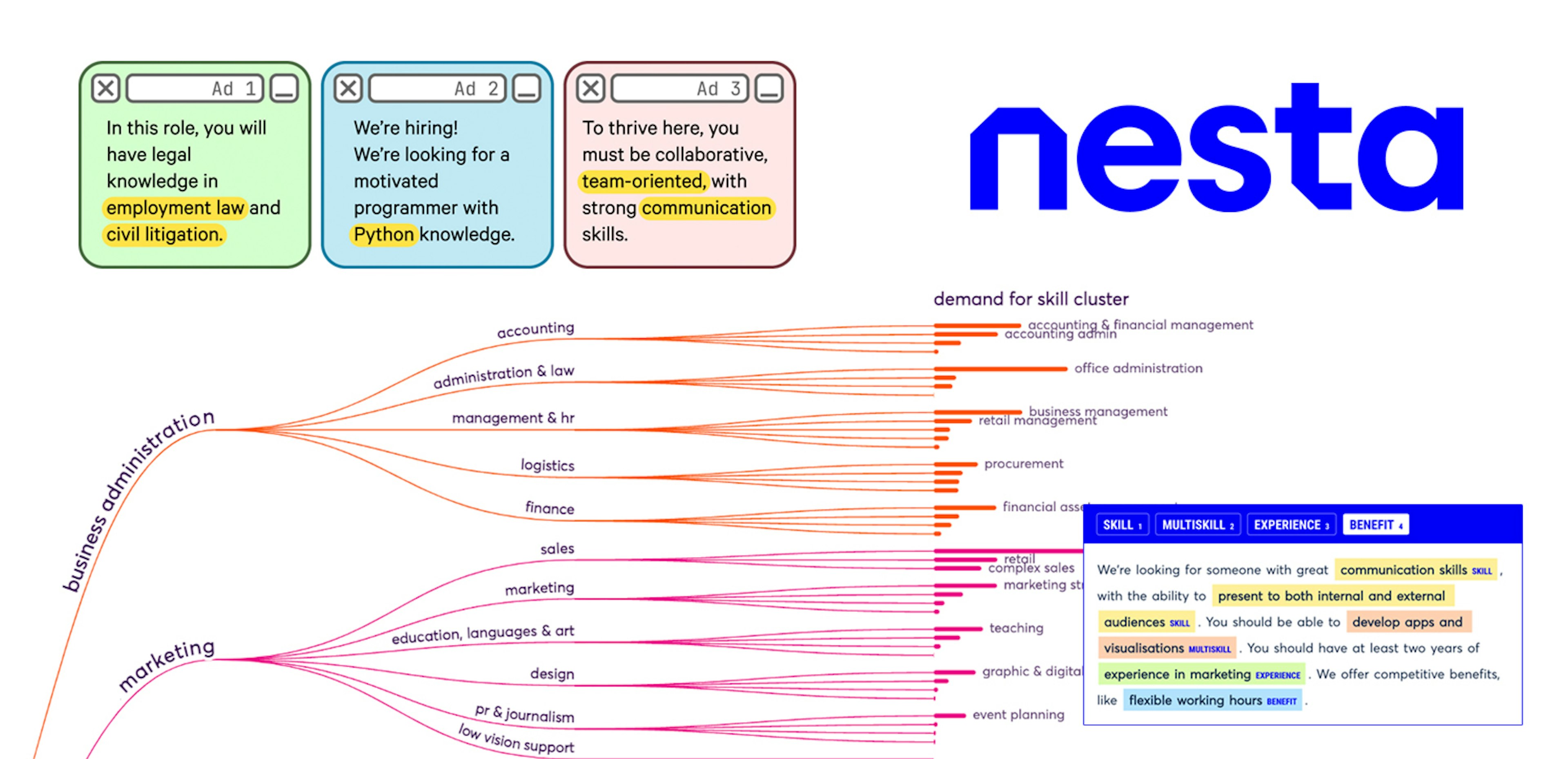
How Nesta uses NLP to process 7m job ads and shed light on the UK’s labor marketA case study on Nesta’s workflow for extracting 7 million job ads to better understand UK skill demand, using a custom mapping step to match skills to any government taxonomy.
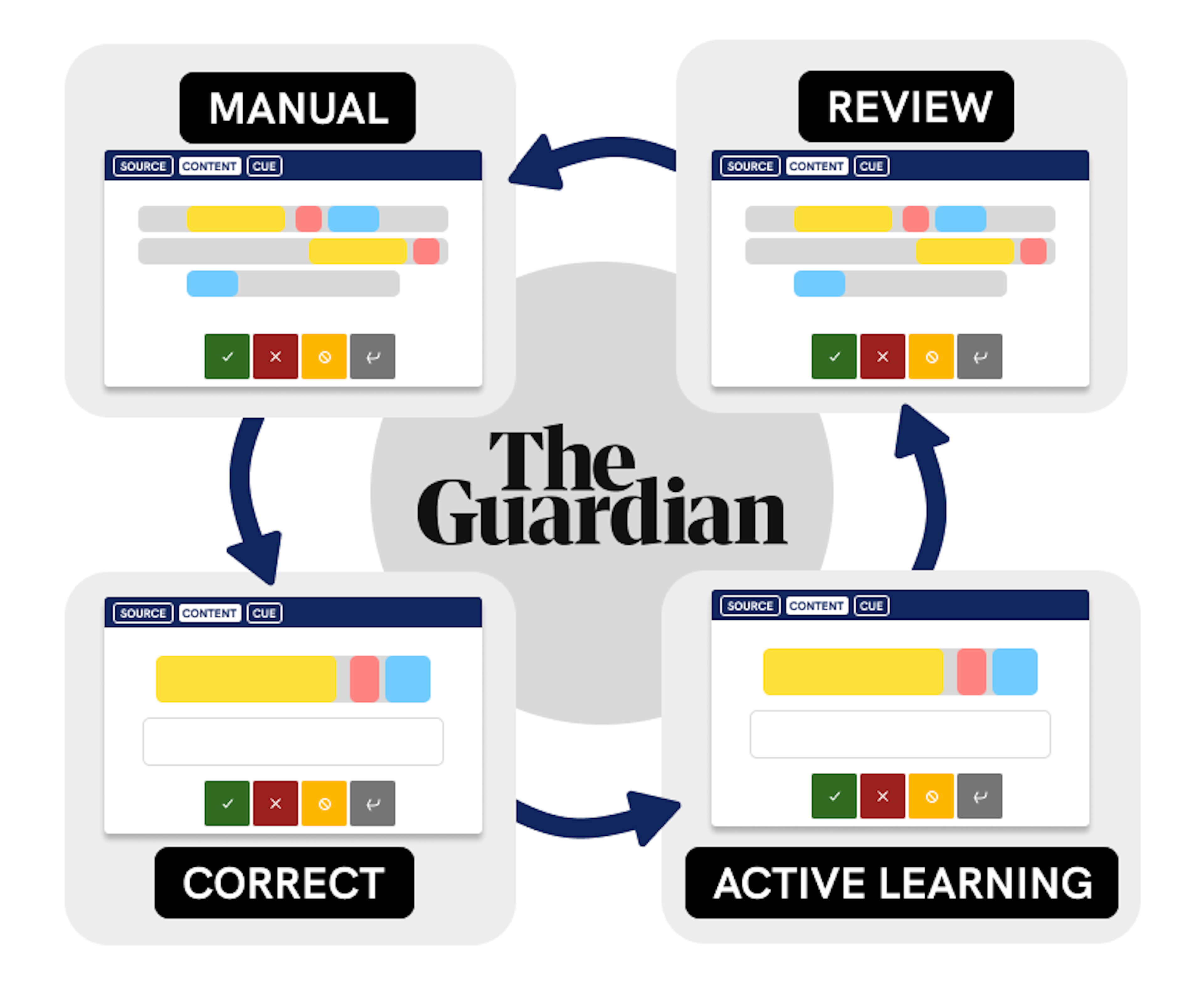
How the Guardian approaches quote extraction with NLPA case study of the Guardian's spaCy-Prodigy workflow to modularize quote extraction for content creation. This study includes iterative annotation guidelines and custom interface functionality.
spaCy v3's project and config systems are pretty greatThe road to production has become increasingly harder. Machine Learning Engineers who turn prototypes into production-ready software face difficulties with the lack of tooling and best-practices. spaCy v3, with its configuration and project system, introduced a way to solve this problem. Here's my take on how it works, and how it can ramp-up your team!
FAQ #1: Tips & tricks for NLP, annotation & training with Prodigy and spaCyIn this video, Ines talks about a few frequently asked questions and shares some general tips and tricks for how to structure your NLP annotation projects, how to design your label schemes and how to solve common problems.