As the field of natural language processing advances and new ideas develop, we’re seeing more and more ways to use compute efficiently, producing AI systems that are cheaper to run and easier to control.
Large Language Models (LLMs) have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. This blog post presents some practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
Software in industry
Amidst all the hype, it’s important to keep in mind that AI development is still just software development, and a lot of the same principles apply. Workflows are changing quickly and many new paradigms are emerging – but in the end, there are basic things about technologies that help teams build on them reliably. We’ve learned over time as an industry that we want our solutions to be:
- modular, so that we can combine a smaller set of primitives we understand in different ways
- transparent, so that we can debug or prevent issues
- explainable, so that we can build the right mental model of how things are working
If the AI system is a black box that’s tasked with solving the whole problem at once, we get very little insights into how our application performs in different scenarios and how we can improve it. It becomes a purely empirical question: just try and see.
There’s also a second dimension that applies to the whole development workflow and lifecycle. We often need that to be:
- data-private, so that internal data doesn’t leave our servers and we can meet legal and regulatory requirements
- reliable, so that we have stable request times with few failures
- affordable, so that it fits within our budget
This can make it impractical to rely on third-party APIs. Unfortunately it’s not necessarily true that running open-source models is cheaper than using APIs, as providers like OpenAI do have solid economies of scale. However, moving the dependency on large generative models from runtime to development changes this calculation. If we’re able to produce a smaller, task-specific model, we can achieve a much more cost-effective solution that also provides full data privacy and lower operational complexity, leading to significantly higher reliability.
Strategies for applied NLP
To illustrate the idea, here’s a pretty classic applied NLP problem you might be tasked with. Let’s say you’re working for an electronics manufacturer or retailer and you’ve been collecting user-generated reviews of your products that you want to analyze further. Your plan could look like this:
- Find mentions of products in the reviews.
- Link mentions to your catalog with more meta information.
- Extract customer sentiment for different attributes like
Battery,Camera,PerformanceandDesign, also called “aspect-oriented sentiment analysis”. - Add the results to your database in a structured format so you can query it and compute sentiment analytics at scale.

Looking at the data, some sentiment expressions are very straightforward and barely need sophisticated solutions. Others are a lot more subtle: we know what a power-bank is and that needing it all the time means that the phone’s battery life is likely bad. Making this prediction requires a lot of knowledge about the language and the world.
Large generative models are very good at this. However, the knowledge we’re interested in to solve this particular problem is really only a very small subset of what the model can do and what’s encoded in its weights. So what if we could extract only those parts and create a smaller task-specific component for our particular aspect-oriented sentiment task?
The focus on in-context learning as a new technology doesn’t mean that transfer learning has somehow been replaced or become obsolete. It’s simply a different tool used for a different purpose. The recent literature shows that transfer learning using embeddings like BERT-base is still very competitive compared to few-shot in-context learning approaches (Zhou et al., 2024).
This does make sense: it would be weird if there was no scalable way to improve a model with labelled data. It’s also worth keeping in mind that evaluations in research are typically performed on benchmark datasets, i.e. datasets we inherently don’t control. In applied work, however, we have full control of the data. So if accuracies are already promising using benchmark data, we’ll likely be able to achieve even better results by creating our own task-specific data.
Using LLMs for predictive tasks
Fundamentally, aspect-oriented sentiment analysis is a predictive task, not a generative one. There’s a structured output we’re trying to create, to be consumed by some other program – we’re not generating unstructured text or images to be consumed by a human.
In-context learning introduces a new workflow for using pretrained models to perform predictive tasks: instead of training a task network on top of an encoder model, you typically use a prompt template and a corresponding parser that transforms the raw text output into the task-specific structured data.
For distillation, we can then use the outputs as training data for a task-specific model. Ideally, we’ll want to include a human-in-the-loop step, so we can correct any errors the LLM is making. If we’re not correcting errors, we can’t really hope to do better than the LLM – garbage in, garbage out, as they say.
Closing the gap between prototype and production
It’s never been easier to build impressive demos and prototypes. But at the same time, many teams are experiencing what I also call the “prototype plateau”: when it comes time to productionize a solution, the prototype doesn’t translate into a usable system.
One of the root causes often lies in diverging workflows. If the prototype assumes fundamentally different inputs and outputs compared to the production system, like sample text to text vs. user-generated text to structured data, there’s no guarantee that it will actually work the same way in practice. Ideally, you want a prototyping workflow that standardizes inputs and outputs and uses the same data structures that your application will need to work on and produce at runtime.
Taking a step back and working on a robust and stable evaluation may not be the most exciting part of the prototyping process, but it’s crucial. Without a good evaluation, you’ll have no way of knowing whether your system is improving and whether changes you make actually lead to better results. Your evaluation should consist of concrete examples from your runtime data that you know the correct answer to – it’s not enough to just try it out with arbitrary examples you can think of, or ask another LLM to do the evaluation for you. This is like evaluating on your training data: it doesn’t give you meaningful insights and only reproduces what a model predicts, which is what you want to evaluate in the first place.
When evaluating your system, the accuracy score isn’t the only thing you should track: what’s even more important is the utility of your system: whether it solves the problem it’s supposed to, and whether it fits into the larger context of your application.
In applied NLP, it’s important to pay attention to the difference between utility and accuracy. “Accuracy” here stands for any objective score you can calculate on a test set […]. This is a figure you can track, and if all goes well, that figure should go up. In contrast, the “utility” of the model is its impact in the application or project. This is a lot harder to measure, and always depends on the application context.
— Applied NLP Thinking: How to Translate Problems into Solutions
As much as we’d like the world to fit neatly into categories, it usually doesn’t, which is especially true when working with natural language. And just like with code, the first idea you come up with is usually not the best one. Once you start engaging with your data, you’ll inevitably come across edge cases you hadn’t considered, and will need to adapt. This means that you need a workflow that allows you to work iteratively and take into account the structure and ambiguity of natural language.
Structured data from prototype to production
I believe that closing the gap between prototype and production ultimately comes down to the right developer tooling. We thought about this a lot when designing spacy-llm, an extension library for spaCy that provides components to use open-source and proprietary LLMs for a variety of structured prediction tasks like named entity recognition, text classification or relation extraction, with battle-tested prompts under the hood that can be customized if needed.

Previously, trying out an idea and creating a model that predicts something and that you can improve upon required significant data annotation work with pretty uncertain outcomes. With spacy-llm you can now build a working prototype in mere minutes and access the predictions via the structured Doc object, representing the input text and document-, span- and token-level predictions. This also provides a standardized interface for inputs and outputs during prototyping and production, whether you decide to ship the LLM-powered approach, or replace the components with distilled versions for the production system.

Human-in-the-loop distillation
Bootstrapping the pipeline with LLM components gets us to a working system very quickly and produces annotated data for a specific task like text classification or named entity recognition. If we can improve the labels somewhat — either by doing some data aggregation to discard obvious problems, or by correcting them manually, or both — we can train on data that’s more correct than the LLM output, which gives us a chance of getting a model that’s not only smaller and faster, but more accurate, too.
The goal is to create gold-standard data by streaming in and correcting the LLM’s predictions, extracting only the information we’re interested in, until the accuracy of the task-specific model reaches or exceeds the zero- or few-shot LLM baseline. Using transfer learning and initializing the model with pretrained embeddings means that we’ll actually need relatively few task-specific examples.
When putting a human in the loop, we do need to consider its natural limitations: humans are great at context and ambiguity but much worse than machines at remembering things and performing a series of repetitive steps consistently. We can also get overwhelmed and lose focus if presented with too much information, which leads to mistakes due to inattention.
This means that the best way to ask a human for feedback and corrections can differ a lot from how we would structure a task for a machine learning model. Ideally, we want to construct the interface to reduce cognitive load and only focus on the minimum required information from the human to correct the annotations pre-selected by the LLM.
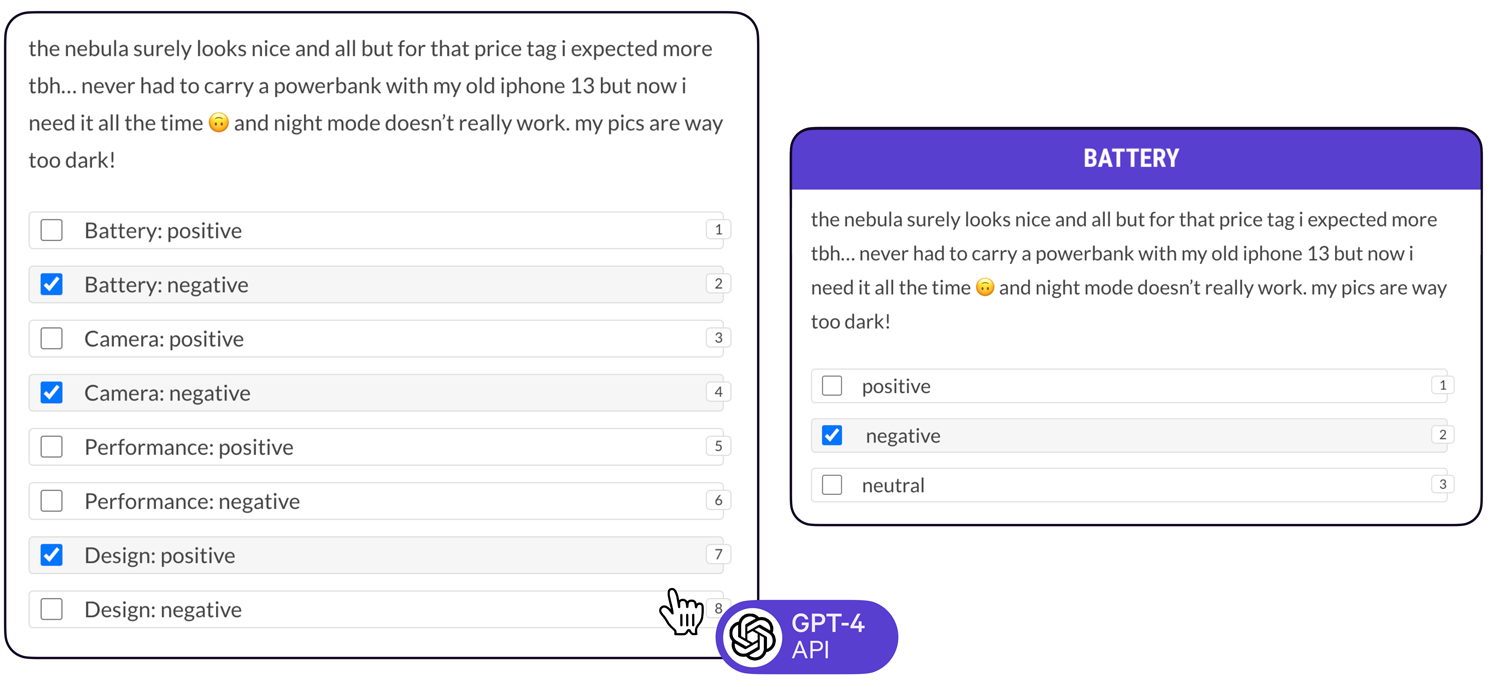
The above example illustrates two possible interfaces defined with Prodigy. The multiple-choice interface (left) includes both positive and negative sentiment for various attributes, while also allowing null values if no option is selected, since not all reviews cover all available aspects.
An alternative approach (right) is to make multiple passes over the data and annotate sentiment for one aspect at a time. While this seems like it creates more work for the human, experiments have shown that this approach can actually be significantly faster than annotating all categories at the same time, as it helps the annotator focus and lets them move through the examples much quicker. (Also see the S&P Global case study for a 10× increase in data development speed by annotating labels individually.)
Case studies and results
Since releasing the LLM-powered distillation workflows for spaCy and Prodigy we’ve been trying them out on various use cases and have started documenting industry projects across different domains that have been able to achieve very promising results.
Did you try out human-in-the-loop distillation for your project and have an interesting use case to share? Or do you need help with implementing a similar workflow in your organization? Get in touch with us!
PyData NYC: analyzing Reddit posts on cooking
For this workshop hosted by Ryan and me at PyData NYC last year, we set ourselves an ambitious goal: Can we beat an LLM with a task-specific component? As the task, we chose extracting DISH, INGREDIENT and EQUIPMENT from r/cooking Reddit posts. By using the LLM to pre-annotate spans and correcting the predictions together with the participants, we were able to beat the few-shot baseline of 74% with a task-specific component, producing a small model artifact and a 20× inference time speedup.
| Generative LLM | Distilled Component | |
|---|---|---|
| Accuracy (F-score) | 0.74 | 0.74 |
| Speed (words/second) | < 100 | ~ 2,000 |
| Model Size | ~ 5 TB | 400 MB |
| Parameters | 1.8t | 130m |
| Training Examples | 0 | 800 |
| Evaluation Examples | 200 | 200 |
| Data Development Time 1 | ~ 2h | ~ 8h |
Due to time constraints of the workshop, we stopped after matching the baseline accuracy, but more annotation would have likely led to even better results. Working on the data also uncovered many edge cases and inspired interesting discussions about the label scheme (e.g. “Is Cheetos an ingredient?”). For a real-world application, these questions are important to resolve: if you’re not clear on how to apply your intended classification, it’ll be much harder to develop an AI system that produces consistent results.
S&P Global: real-time commodities trading insights
S&P Global are one of the leading providers of data and insights for global energy and commodities, covering raw materials like metals, agricultural products and chemicals. To provide better market transparency and generate structured data in real time, their team built and shipped efficient spaCy pipelines as small as 6 MB that run entirely in-house in a high-security environment and meet their strict inference SLAs. Using LLMs during development and Prodigy for semi-automated annotation, they were also able to achieve a 10× speed-up of their data collection and annotation workflows.
| Global Carbon Credits | Americas Crude Oil | Asia Steel Rebar | |
|---|---|---|---|
| Accuracy (F-score) | 0.95 | 0.96 | 0.99 |
| Speed (words/second) | 15,730 | 13,908 | 16,015 |
| Model Size | 6 MB | 6 MB | 6 MB |
| Training Examples | 1,598 | 1,695 | 1,368 |
| Evaluation Examples | 211 | 200 | 345 |
| Data Development Time | ~ 15h | ~ 15h | ~ 15h |
Think of it as a refactoring process
While you can view distillation as a purely technical challenge, I think it makes more sense to think of it as a refactoring process. Just like with writing and refactoring software, you’re trying to break down larger problems into modular and composable building blocks. The goal is to select the best possible techniques out of those available and balance trade-offs between operational complexity, ease of use and quality of results.
Refactoring is also an opportunity to reassess dependencies: Does it make sense to drag in this large library that you’re only using a single simple function of? Similarly, can you replace larger, slower and more expensive models with smaller and faster versions? And are there dependencies that you can move from runtime to development?
Making problems easier
It’s easy to forget that in applied work, you’re allowed to make the problem easier! This isn’t university or academia, where you’re handed a dataset of fixed inputs and outputs. And as with other types of engineering, it isn’t a contest to come up with the most clever solutions to the most difficult problems. We’re trying to get things done. If we can replace a difficult problem with a much easier one, that’s a win.
Reducing your system’s operational complexity also means that less can go wrong. And if things do, it becomes a lot easier to diagnose and fix them. At their core, many NLP systems consist of relatively flat classifications. You can shove them all into a single prompt, or you can decompose them into smaller pieces that you can work on independently. A lot of classification tasks are actually very straightforward to solve nowadays – but they become vastly more complicated if one model needs to do them all at once.
Instead of throwing away everything we’ve learned about software design and asking the LLM to do the whole thing all at once, we can break up our problem into pieces, and treat the LLM as just another module in the system. When our requirements change or get extended, we don’t have to go back and change the whole thing.
Just because the result is easier, it doesn’t necessarily mean that getting there is trivial. There just isn’t much discussion of this process, since research typically (and rightly) focuses on generalizable solutions to the hardest problems. You do need to understand all the techniques you have available, and make an informed choice. Just like with programming, this skill develops through experience and you get better at it the more problems you solve.

Factoring out business logic
When we refactor code, we’re often trying to regroup the logic into functions that have a clear responsibility, and clearly defined behavior. We shouldn’t have to understand the whole program to know how some function should be behaving – it should make sense by itself. When you’re creating an NLP pipeline, you’re also dividing up computation into a number of functions. In simple terms, this can be broken down into a formula like this:
result = business_logic(classification(text))Going back to our example of phone reviews, how can we divide up the work? It’s the same type of question that comes up in any other refactoring discussion, only that the stakes are much higher. You can really change how your model performs and how it generalizes to future data by the choices you make here.
We can train a model to predict mentions of phone models, but we shouldn’t train it to tag mentions with “latest model”. Maybe some phone was the latest when the review was written, but isn’t now. There’s no way to know that from the text itself, which is what the model is working from. You could try to include all these extra database features as well to make the prediction, but… why? If you know what phone the review is talking about, and you have a database that tells you when that model was released, you can compute the information deterministically.
| Classification | Business Logic | ||
|---|---|---|---|
| product name | SpacePhone | catalog reference | P3204-W2130 |
| product model name | Nebula | latest model | true |
| phone | true | touchscreen phone | true |
The model really has no chance to predict labels like “latest model” or “touchscreen” reliably. At best it can try to learn what’s latest at a given time, or memorize that “nebula” is always “touchscreen” (some very expensive conditional logic). This is really bad for your application: the model is learning something that doesn’t generalize, and your evaluation data might not show you the problem.
Here’s a tip to help you refactor: Try to look through the texts from the model’s point of view. Imagine this is a task you’re being told to do, and the input is all you’ve got to work with. What do you need to know to get to the answer? If the model just needs to know what words generally mean and how sentences are structured, and then apply a fairly simple labelling policy, that’s good. If the model needs to combine that language knowledge with a lot of external knowledge, that’s bad. If the answer will depend on facts that change over time, that’s really bad.
Conclusion
In many real-world applications, AI models are going to be just one function in a larger system. So as with any function, you can move the work around. You can have a function that does a whole task end-to-end, or you can break off some bits and coordinate the functions together.
This refactoring process is very important, because it changes what the model learns and how it can generalize. With the right tooling, you can refactor faster and make sure you don’t just commit to your first idea. Taking control of more of the stack is also helpful, because you’re inheriting fewer constraints from how the upstream component happens to work.
It’s also just really important to be working through the data iteratively, because your assumptions about how it will look and how it needs to be classified might not be correct. Annotation is a great way to do that – it’s not just a cost, it’s a benefit in itself as well. Very often the process of annotating is almost more valuable than the annotations themselves.
With an efficient workflow and the right automation, it often only needs a few hours of work to create enough data to achieve high accuracies and outperform a general-purpose LLM on the same task. And as general-purpose LLMs improve, this workflow just becomes more powerful. The resulting task-specific models are less operationally complex, small, fast and can usually be run entirely in-house, without requiring expensive hardware.
Finally, with the tools and techniques we have available, there’s absolutely no need to compromise on software development best practices or data privacy. People promoting “one model to rule them all” approaches might be telling that story, but the rest of us aren’t obliged to believe them.
Resources
- How S&P Global is making markets more transparent with NLP, spaCy and Prodigy: Case study on real-time commodities trading insights using human-in-the-loop distillation
- Half hour of labeling power: Can we beat GPT?: Slides and video from PyData NYC workshop on human-in-the-loop distillation
- Large Language Models in spaCy: Use LLM-powered components for a variety of NLP tasks in your pipeline
- Large Language Models in Prodigy: Use LLMs to automate annotation and data creation for distilled task-specific models
- Against LLM maximalism: LLMs beyond “one model to rule them all”
- Applied NLP Thinking: How to translate business problems into machine learning solutions
- Tailored Solutions: We can help you implement similar workflows and strategies for your projects



