The ultimate guide to optimizing annotation workflowsThis blog post collects tips and advice for how to build efficient human-in-the-loop data development workflows, break down business problems into actionable annotation steps and make the most of automation and model assistance.
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillationInfoQ Dev SummitLLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, Ines shows some practical solutions for using the latest models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillationPyData LondonLLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, Ines shows some practical solutions for using the latest models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
On the Creation of Classifiers to Support Assessment of E-PortfoliosGantikow, Isking, Libbrecht, Müller, Rebholz (2023)In this workflow, Prodigy selects and presents text examples that were classified with a very low degree of certainty. The annotator reviews the proposed classifications and corrects them, if necessary.
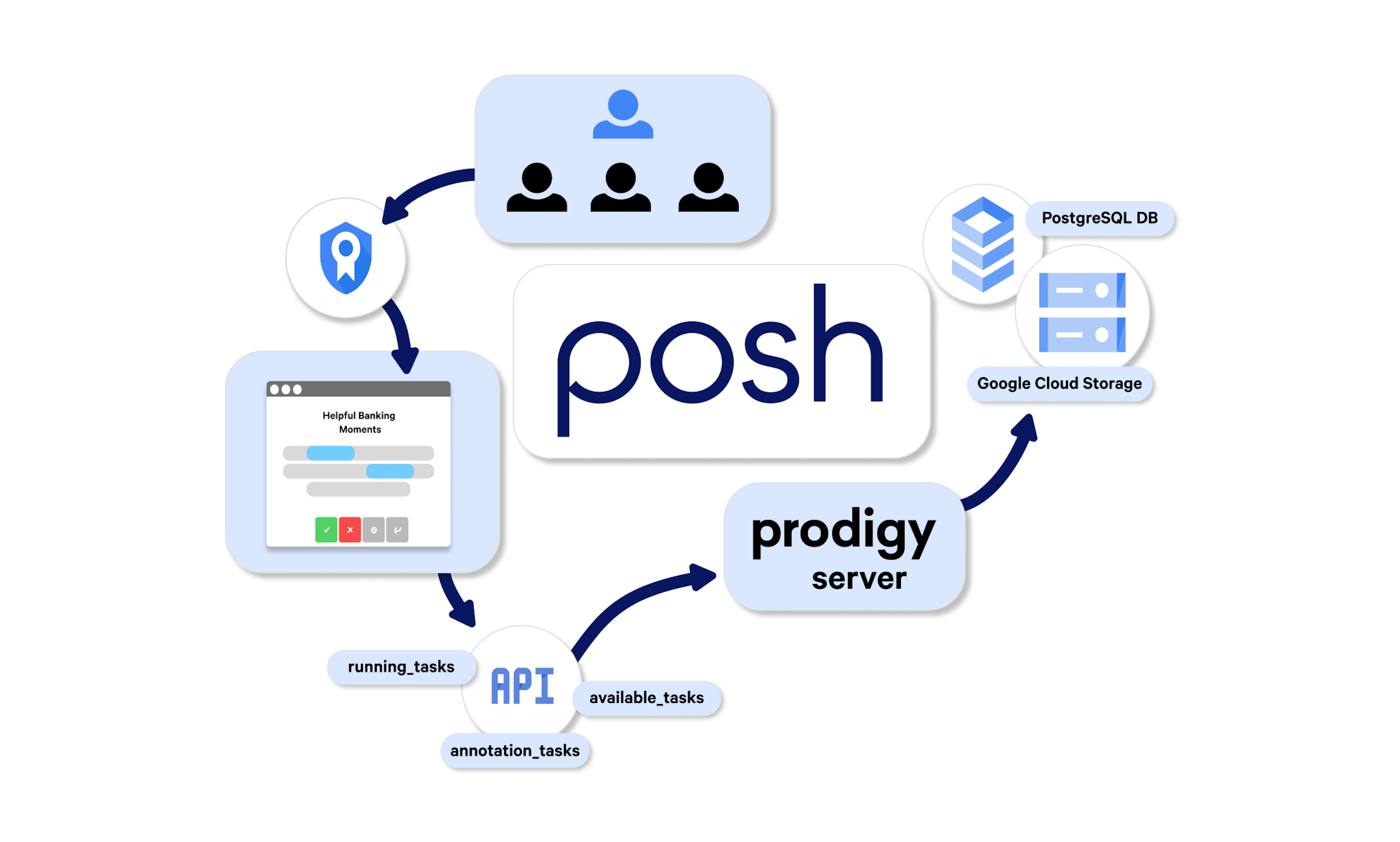
Deploying a Prodigy cloud service for Posh’s financial chatbotsA Prodigy case study of Posh AI's production-ready annotation platform and custom chatbot annotation tasks for banking customers.
Diary of a spaCy project: Predicting GitHub TagsMany people assume that working on an NLP project involves a lot of machine learning. Our experience is that it's much less about flowing tensors, and more about making a tailored solution. This blogposts demonstrates how a typical spaCy project could be initiated, implemented and executed towards a custom solution.
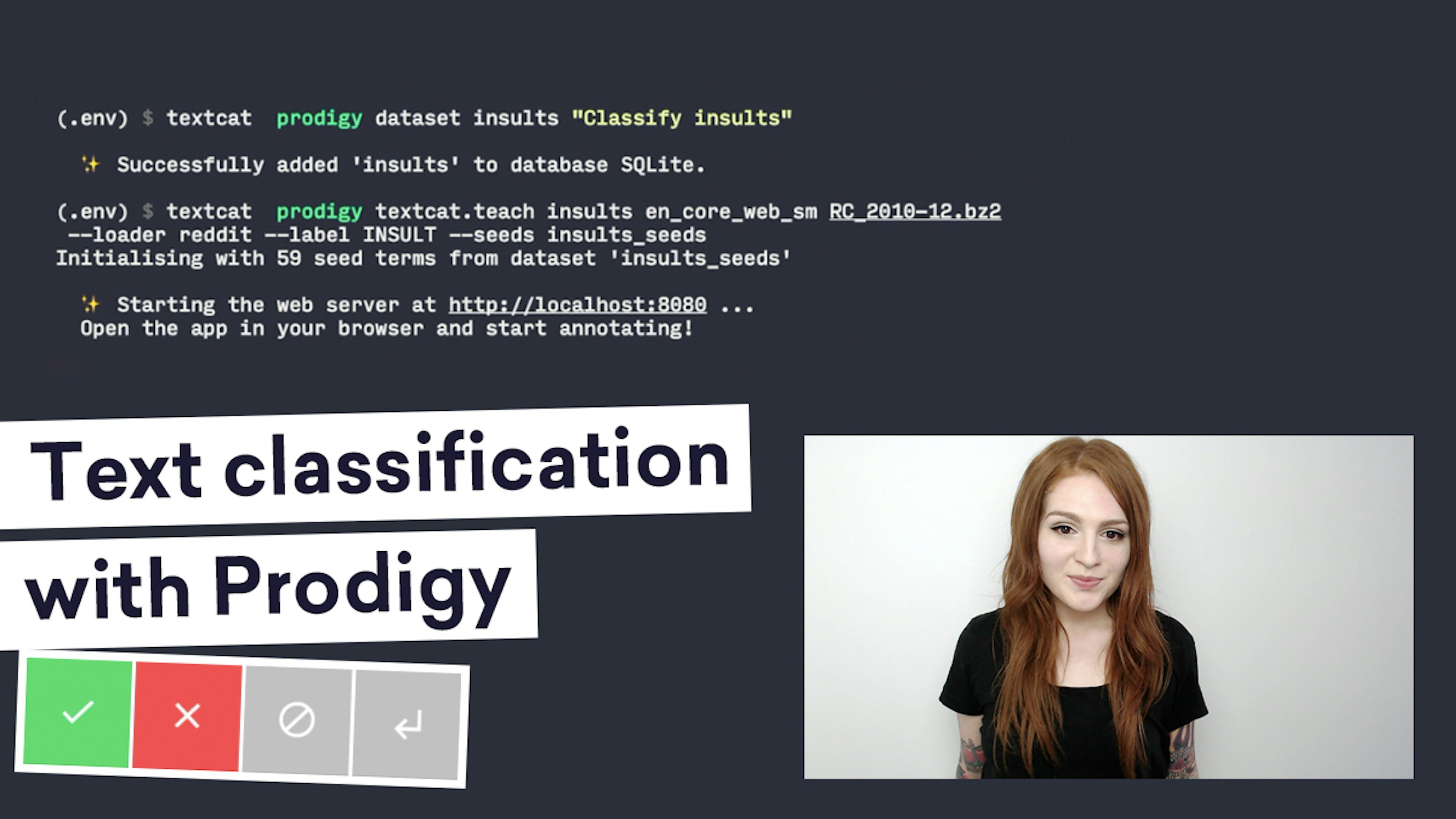
Training an insults classifier with Prodigy in ~1 hourIn this video, we’ll show you how to use Prodigy to train a classifier to detect disparaging or insulting comments. Prodigy makes text classification particularly powerful, because you can try out new ideas very quickly.
How Love Without Sound helps the music industry recover millions in revenue for artists with NLP, spaCy and ProdigyA case study on Love Without Sound’s innovative AI-powered tools for the music industry and law firms specializing in royalty negotiations.
How GitLab uses spaCy to analyze support tickets and empower their communityA case study on GitLab’s large-scale NLP pipelines for extracting actionable insights from support tickets and usage questions.
Towards Structured Data: LLMs from Prototype to ProductionU.S. Census Bureau: Center for Optimization and Data Science SeminarThis talk presents pragmatic and practical approaches for how to use LLMs beyond just chat bots, how to ship more successful NLP projects from prototype to production and how to use the latest state-of-the-art models in real-world applications.
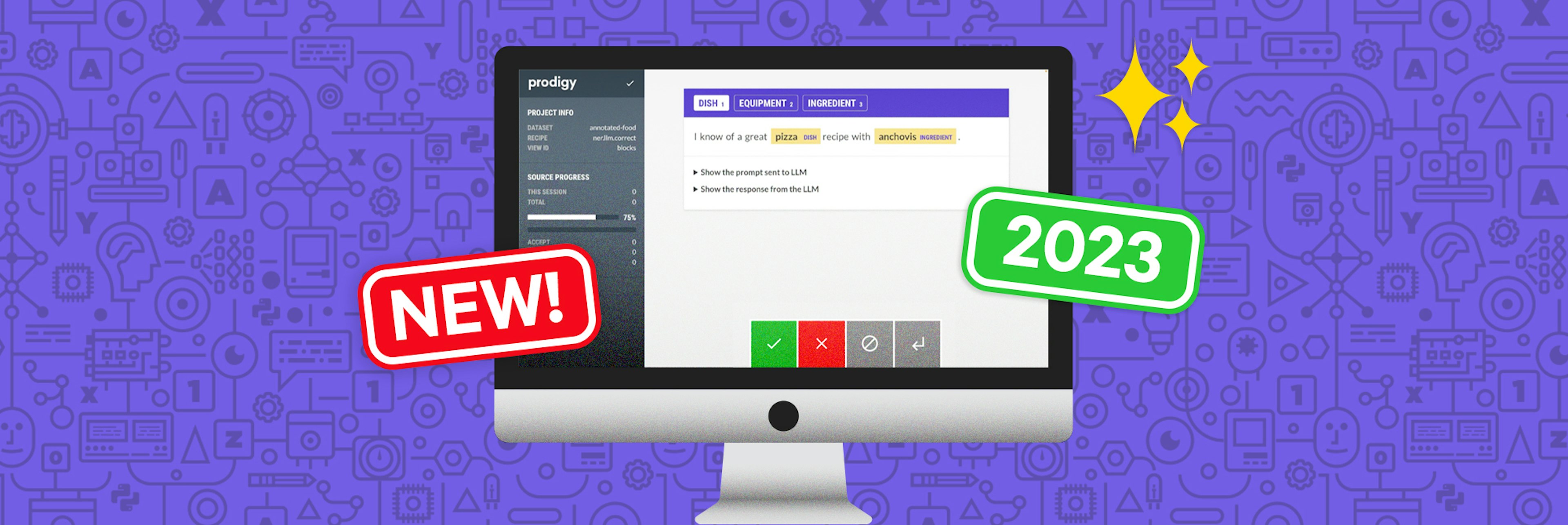
Prodigy in 2023: LLMs, task routers, QA and pluginsWe have made a ton of new updates in Prodigy this year with v1.12, v1.13, and v1.14 releases. So we decided to write a post about them.
Large Language Models: From Prototype to ProductionEuroPython KeynoteLarge Language Models (LLMs) have shown some impressive capabilities and their impact is the topic of the moment. In this talk, Ines presents visions for NLP in the age of LLMs and a pragmatic, practical approach for how to use Large Language Models to ship more successful NLP projects from prototype to production today.
Speech acts in the Dutch COVID-19 Press ConferencesSchueler, Marx (2022), Language Resources and EvaluationWe used the annotation tool Prodigy. Prodigy provides a simple interface in which the annotator sees a sentence and selects the applicable speech acts. The use of Prodigy considerably sped up the annotation process, allowing the annotators to annotate around 200 sentences per hour.
Healthsea: an end-to-end spaCy pipeline for exploring health supplement effectsCreate better access to health with machine learning and natural language processing. Read about our journey of developing Healthsea, an end-to-end spaCy pipeline for analyzing user reviews to supplement products and extracting potential effects on health.
Supervised similarity: Learning symmetric relations from duplicate question dataSupervised models for text-pair classification let you create software that assigns a label to two texts, based on some relationship between them. When the relationship is symmetric, it can be useful to incorporate this constraint into the model. This post shows how a siamese convolutional neural network performs on two duplicate question data sets with experimental results.
Mastering spaCyDéborah Mesquita, Duygu Altinok (Packt Publishing, 2025)Build structured NLP solutions with custom components and models powered by LLMs. By end of the book you will be empowered to build robust NLP pipelines and integrate them with web applications to build end-to-end solutions.
A practical guide to human-in-the-loop distillationThis blog post presents practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
spaCy meets LLMs: Using Generative AI for Structured DataData+ML Community MeetupThis talk dives deeper into spaCy’s LLM integration, which provides a robust framework for extracting structured information from text, distilling large models into smaller components, and closing the gap between prototype and production.
Impoliteness and morality as instruments of destructive informal social control in online harassment targeting Swedish journalistsBjörkenfeldt, Gustafsson (2023)In the annotation tool Prodigy used for this process, the tweets directed towards journalists were displayed alongside the initial tweet that initiated the conversation thread and the subsequent reply from the journalist.
Bulk Labelling and ProdigyIn this video, we’ll show a bulk labelling technique that can help you prepare data for Prodigy.
Mastering spaCyDuygu Altinok (Packt Publishing, 2021)An end-to-end practical guide to implementing NLP applications using the Python ecosystem. By the end of this book, you'll be able to confidently use spaCy, including its linguistic features, word vectors, and classifiers, to create your own NLP apps.
Deep text-pair classification with Quora's 2017 question datasetQuora recently released the first dataset from their platform: a set of 400,000 question pairs, with annotations indicating whether the questions request the same information. This data set is large, real, and relevant — a rare combination. In this post, I'll explain how to solve text-pair tasks with deep learning, using both new and established tips and technologies.
Serverless custom NLP with LLMs, Modal and ProdigyIn this blog post, we’ll show you how you can go from an idea and little data to a fully custom information extraction model using Prodigy and Modal, no infrastructure or GPU setup required.
How to uncover and avoid structural biases in evaluating your Machine Learning/NLP projectsPyData LondonThis talk highlights common pitfalls that occur when evaluating ML and NLP approaches. It provides comprehensive advice on how to set up a solid evaluation procedure in general, and dives into a few specific use-cases to demonstrate artificial bias that unknowingly can creep in.
The AI Revolution Will Not Be Monopolized: Behind the scenesOpen Source ML MixerA more in-depth look at the concepts and ideas, academic literature, related experiments and preliminary results for distilled task-specific models.
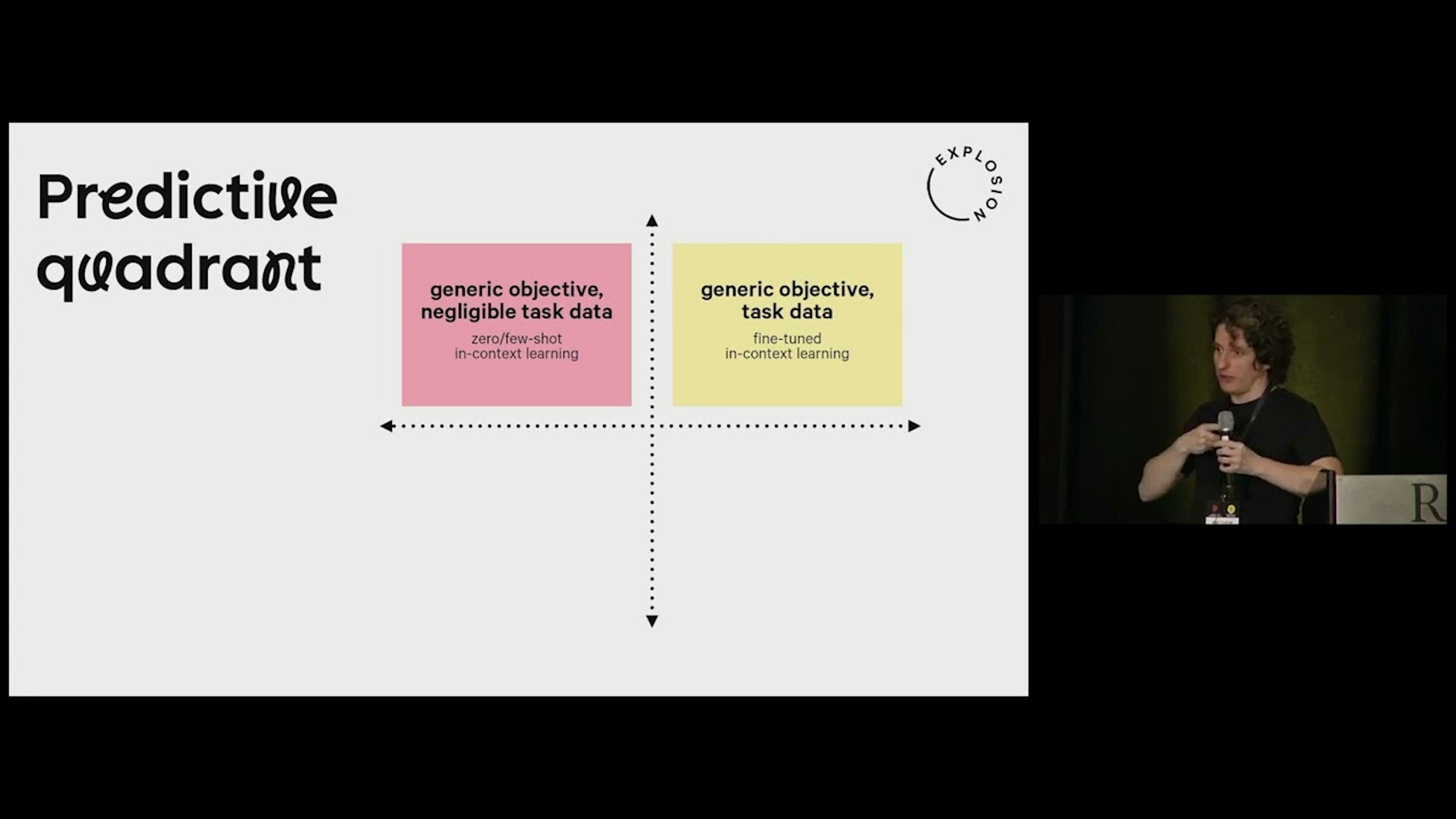
How many Labelled Examples do you need for a BERT-sized Model to Beat GPT-4 on Predictive Tasks?Generative AI SummitHow does in-context learning compare to supervised approaches on predictive tasks? How many labelled examples do you need on different problems before a BERT-sized model can beat GPT-4 in accuracy? The answer might surprise you: models with fewer than 1b parameters are actually very good at classic predictive NLP, while in-context learning struggles on many problem shapes.
You are what you read: Building a personal internet front-page with spaCy and ProdigyPyCon DE & PyData Berlin
Finding Bad Labels for Text Classification with Jupyter and Prodigy In this video, we’ll show you how to use set up Prodigy to find bad labels in text classification tasks. While many of the techniques are applied to text classification, they can also be used for classification tasks in general.
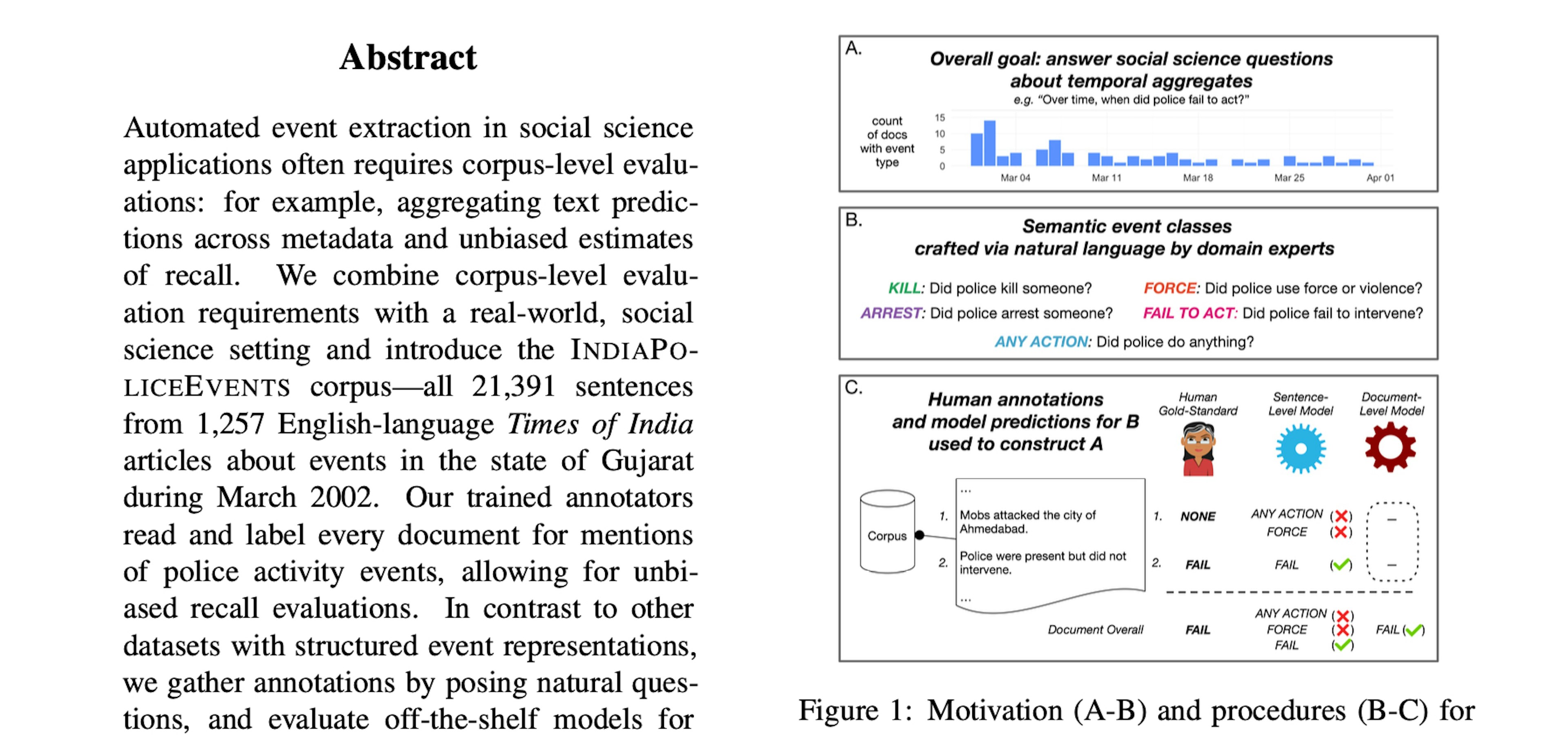
Corpus-Level Evaluation for Event QA: The IndiaPoliceEvents Corpus Covering the 2002 Gujarat ViolenceHalterman, Keith, Sarwar, O’Connor (2021), ACL 2021Figure A2 shows a stylized version of the custom interface we built using the Prodigy annotation tool. Annotators are presented with an entire document, with sentences sequentially highlighted.