Build-to-own AI: Agentic Development for HumansPyData PyCon Yerevan KeynoteInstead of using LLM APIs, we can take back control and build our own systems, bootstrapped by agents. In this talk, Ines shows you these new agentic workflows, what they mean for developer tools and why code and open-source are more important than ever.
The ultimate guide to optimizing annotation workflowsThis blog post collects tips and advice for how to build efficient human-in-the-loop data development workflows, break down business problems into actionable annotation steps and make the most of automation and model assistance.
How to advocate for modular NLP in the age of Generative AIWith all the hype around Generative AI, many are led to believe it’s the solution to everything. So how can you, as a developer, communicate the nuances and advocate for new and modular solutions that are better, easier and cheaper?
✨ prodigy v1.18.0Feb 24, 2025Text editing during NER and span annotation, custom translations and more JavaScript features
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillationInfoQ Dev SummitLLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, Ines shows some practical solutions for using the latest models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
How to uncover and avoid structural biases in evaluating your Machine Learning/NLP projectsPyData LondonThis talk highlights common pitfalls that occur when evaluating ML and NLP approaches. It provides comprehensive advice on how to set up a solid evaluation procedure in general, and dives into a few specific use-cases to demonstrate artificial bias that unknowingly can creep in.
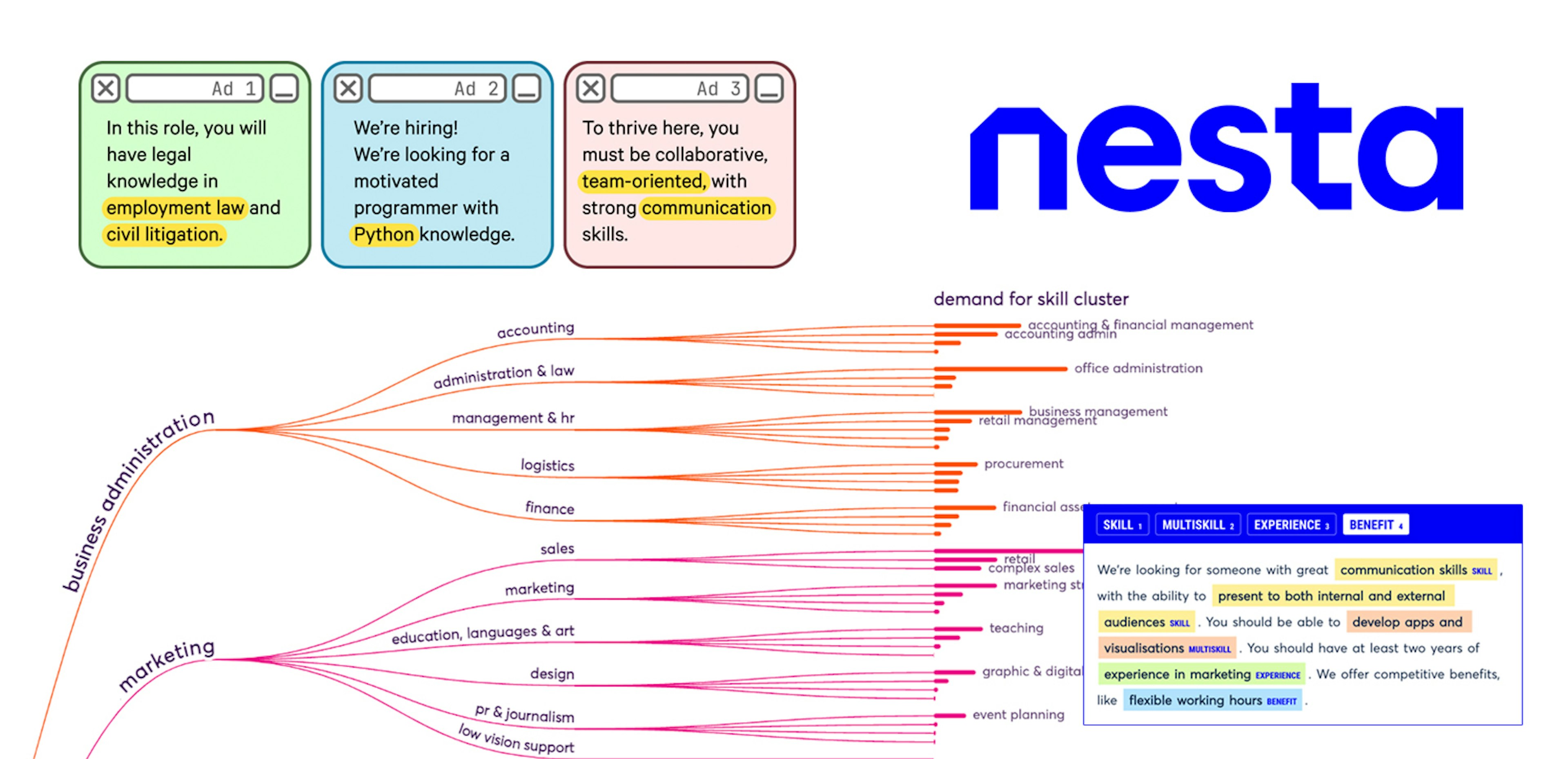
How Nesta uses NLP to process 7m job ads and shed light on the UK’s labor marketA case study on Nesta’s workflow for extracting 7 million job ads to better understand UK skill demand, using a custom mapping step to match skills to any government taxonomy.
Prodigy-ANN for Image Retrieval via CLIPDealing with a huge bucket of images that you want to annotate? The new image retrieval features in Prodigy-ANN (approximate nearest neighbors) might help!
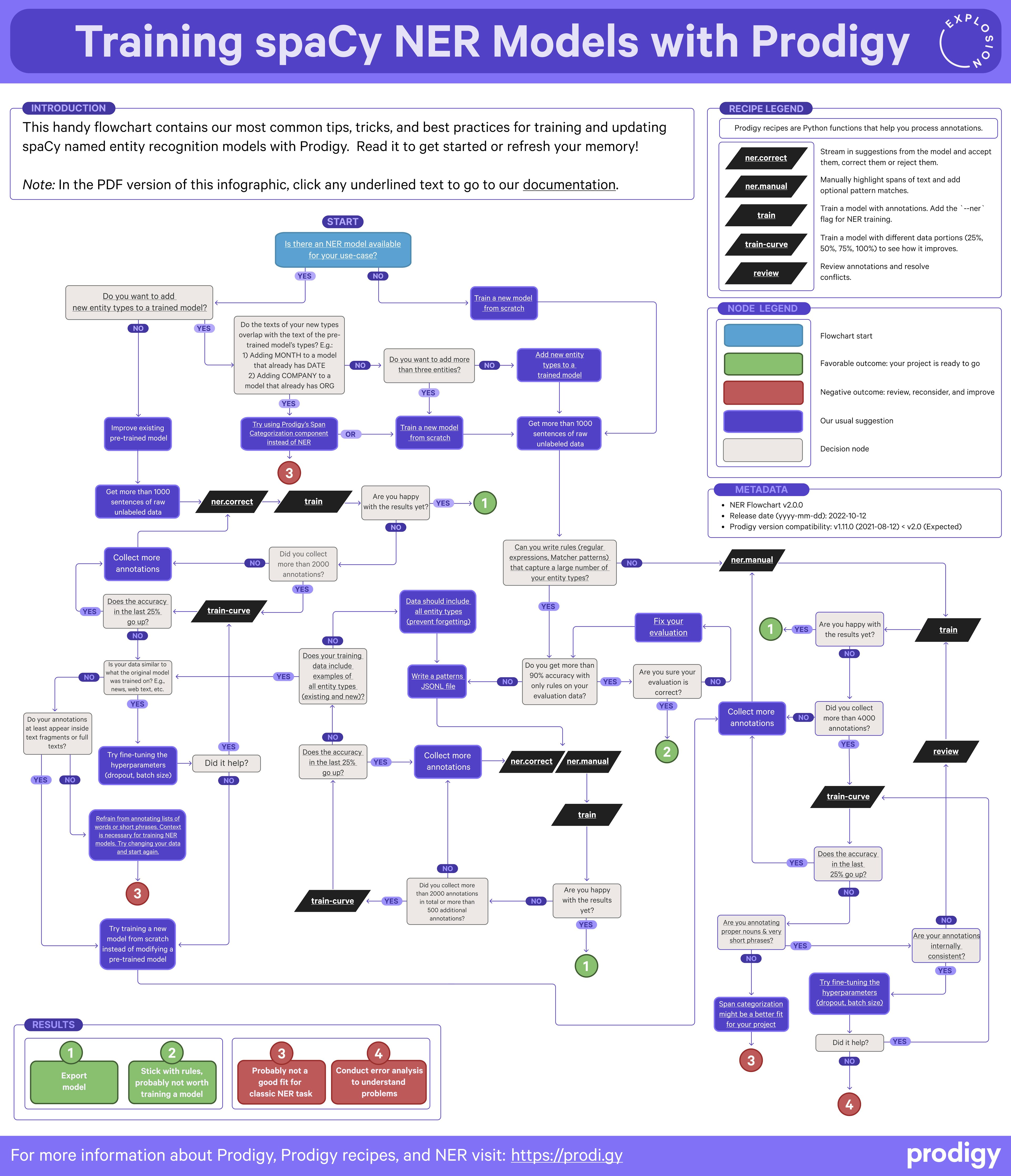
Training spaCy NER Models with ProdigyThis handy flowchart contains our most common tips, tricks, and best practices for training and updating spaCy named entity recognition models with Prodigy.
Finding Video Games with Sense2VecIn this video, we’ll show how you can improve the annotation experience by leveraging sense2vec to pre-fill named entities.
Finding Bad Image Data using UMAP and ProdigyIn this video, we’ll show you how to use Prodigy to find bad examples in the Google QuickDraw dataset. We will be leveraging a technique that involves UMAP to find strange images semi-automatically.
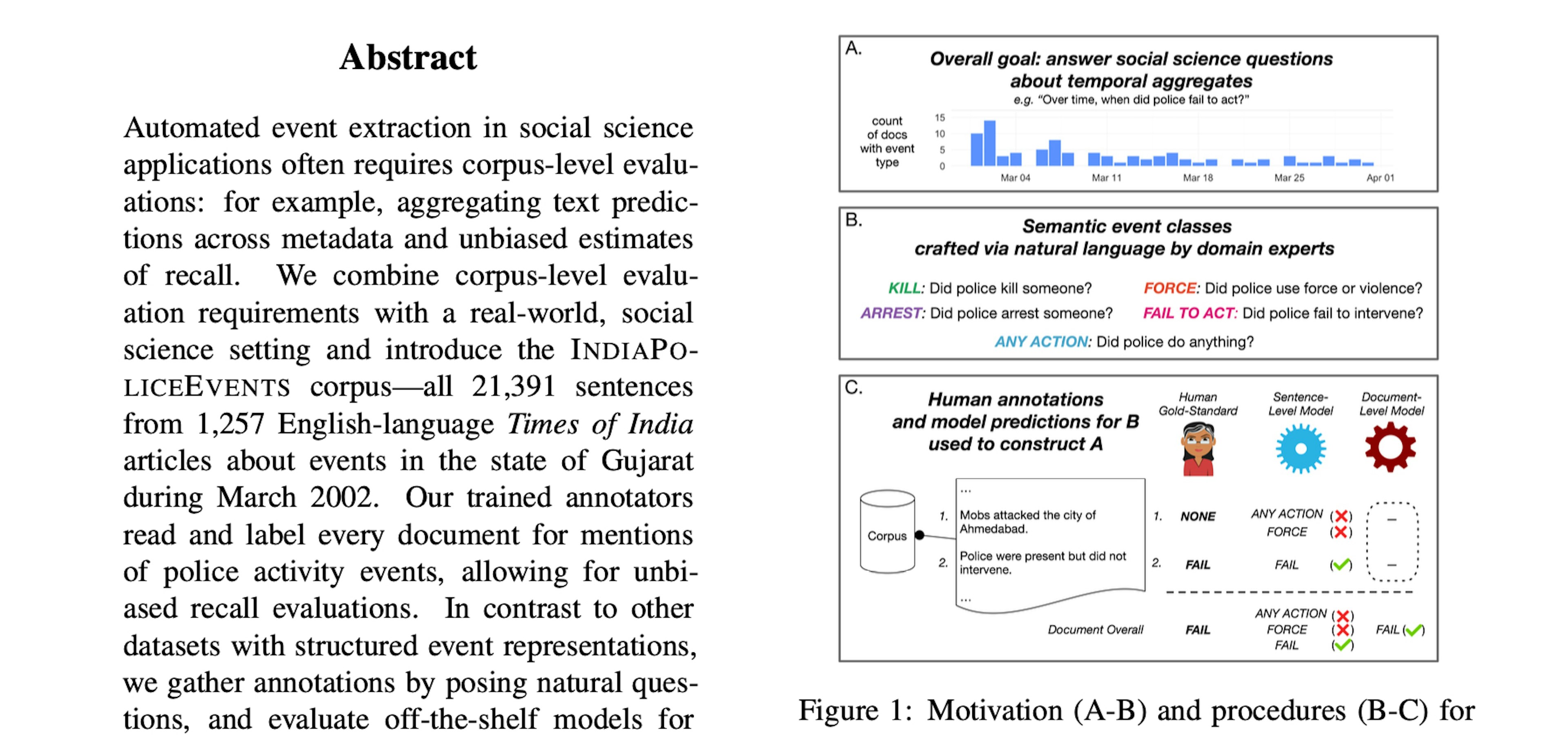
Corpus-Level Evaluation for Event QA: The IndiaPoliceEvents Corpus Covering the 2002 Gujarat ViolenceHalterman, Keith, Sarwar, O’Connor (2021), ACL 2021Figure A2 shows a stylized version of the custom interface we built using the Prodigy annotation tool. Annotators are presented with an entire document, with sentences sequentially highlighted.
FAQ #1: Tips & tricks for NLP, annotation & training with Prodigy and spaCyIn this video, Ines talks about a few frequently asked questions and shares some general tips and tricks for how to structure your NLP annotation projects, how to design your label schemes and how to solve common problems.
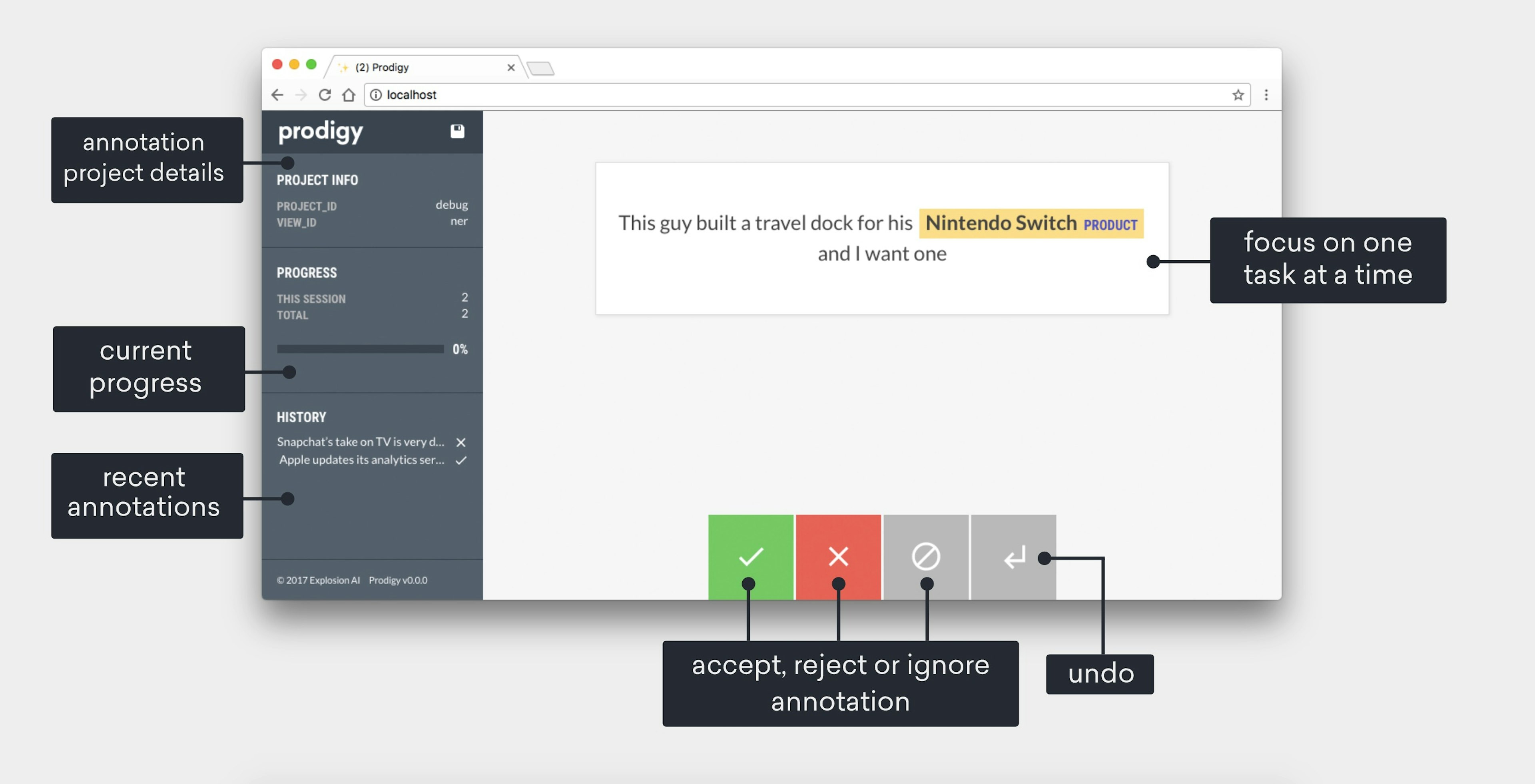
Building Prodigy: Our new tool for efficient machine teachingines.ioThe philosophy behind Prodigy’s features and its cloud-free design.
Vibe NLP for Applied NLPPyCon DE & PyDataWhat if we could take learnings from AI-powered coding agents and apply them to solving real-world NLP problems? In this talk, I’ll show how we’ve built a powerful virtual NLP assistant to help developers create practical and modular solutions that are small, fast and fully data-private.
Building AI with AIPyCon Ireland KeynoteAI-powered coding assistants have transformed the way we build software, and AI itself. In this talk, Ines shows why we should use LLMs to build systems instead of as systems, and why code is more important than ever, not less.
How Love Without Sound helps the music industry recover millions in revenue for artists with NLP, spaCy and ProdigyA case study on Love Without Sound’s innovative AI-powered tools for the music industry and law firms specializing in royalty negotiations.
Prodigy Dashboard PluginThe new dashboard plugin adds a web application for managing annotations, data analytics and annotation progress, and is now available for early beta testing.
✨ prodigy v1.16.0Oct 22, 2024Modal plugin for on-demand deployment, cross-platform wheels and UI fixes
Practical Tips for Bootstrapping Information Extraction PipelinesDataHack SummitThis talk presents approaches for bootstrapping NLP pipelines and retrieval via information extraction, including tips for training, modelling and data annotation.
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillationPyData LondonLLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, Ines shows some practical solutions for using the latest models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
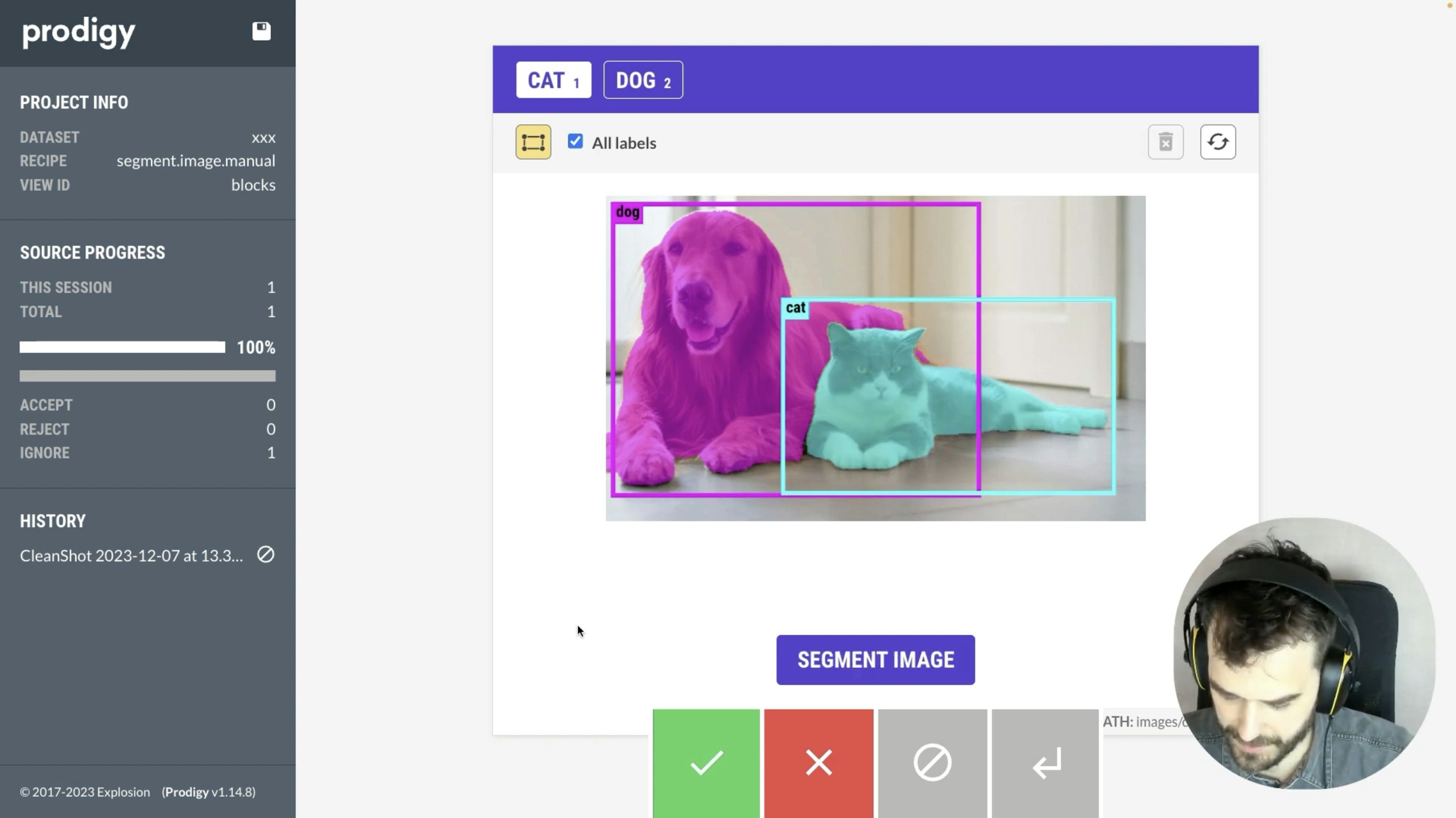
Prodigy-Segment for Pixel SegmentationUse Meta’s “Segment Anything” model in Prodigy to help you select the right pixels in images.
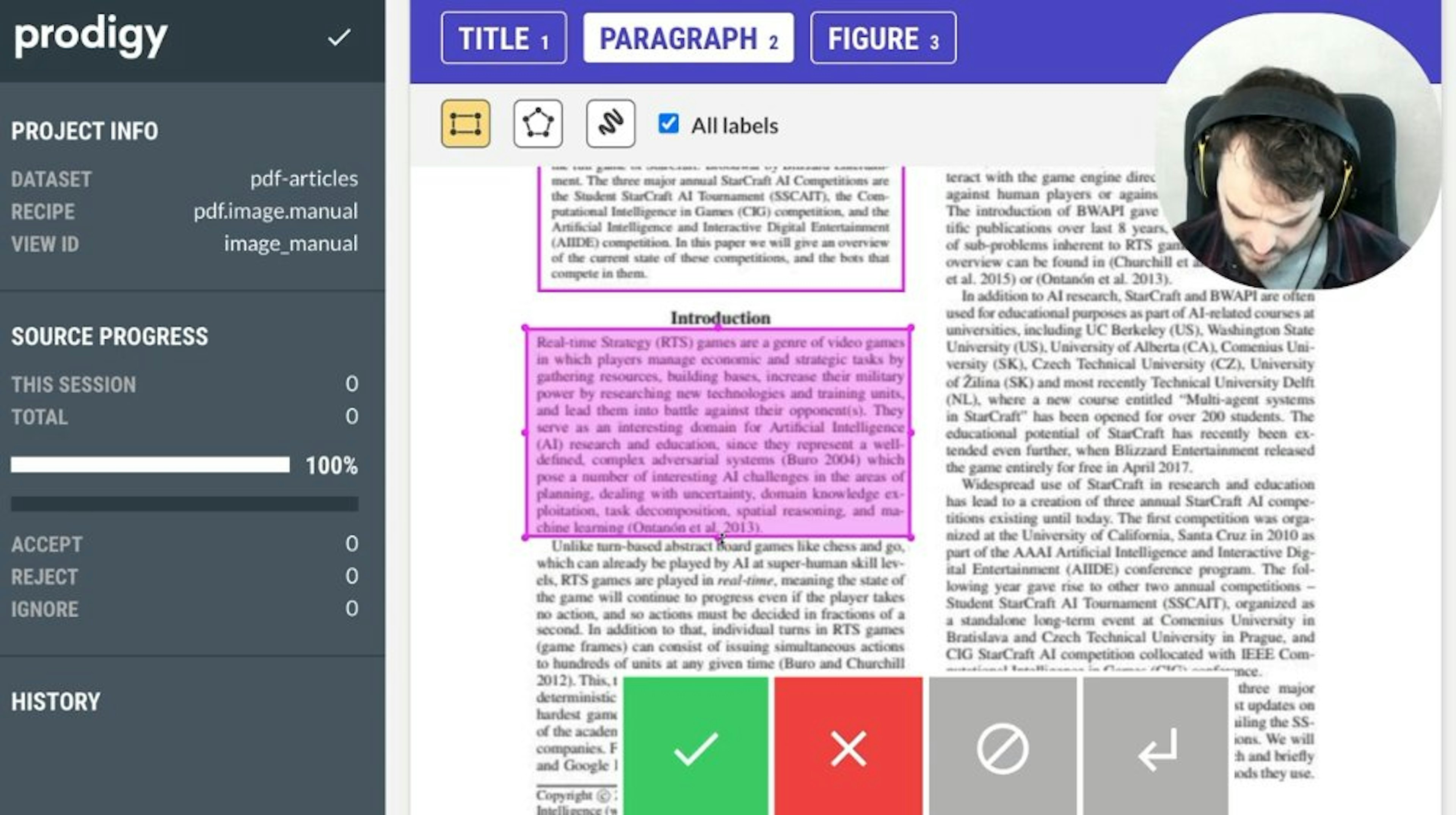
Prodigy-PDF for PDF annotation and OCRWant to annotate PDF files? Our new Prodigy plugin can help with that! To explain how to use PDF segmentation and OCR, Vincent made a small demo video.
✨ prodigy v1.14.3Oct 6, 2023Inter-annotator agreement for document-level and token-level annotations, new plugins
✨ prodigy v1.12.0Jul 5, 2023LLM-assisted workflows for annotation and prompt engineering, task routing for multi-annotator setups
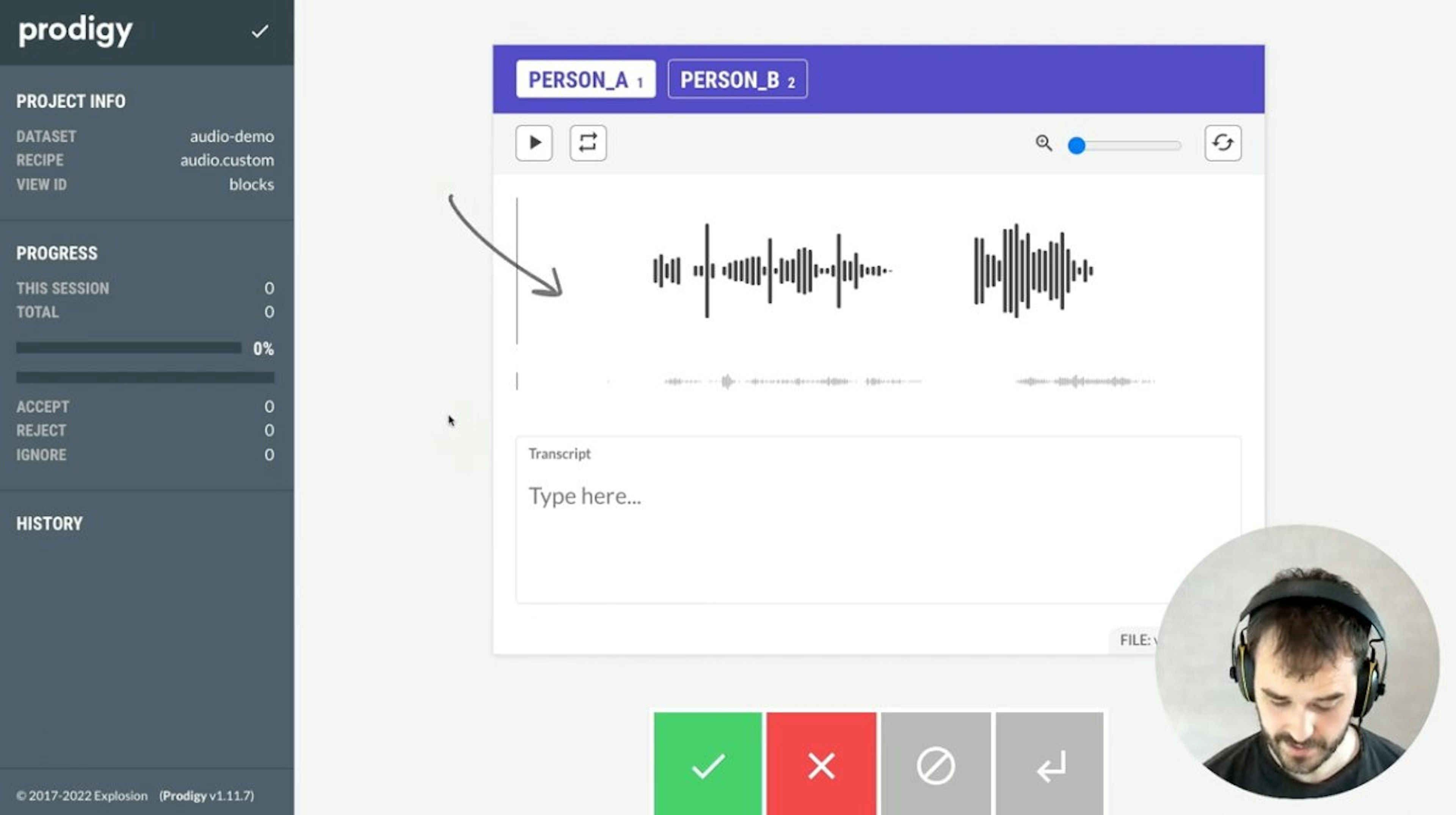
Custom Interfaces with blocksYou can create custom annotation layouts in Prodigy using the annotation widgets that Prodigy provides by using the blocks feature. This video explains how to use this feature by building a custom interface that can manually annotate and transcribe audio.
Bulk Labelling and ProdigyIn this video, we’ll show a bulk labelling technique that can help you prepare data for Prodigy.
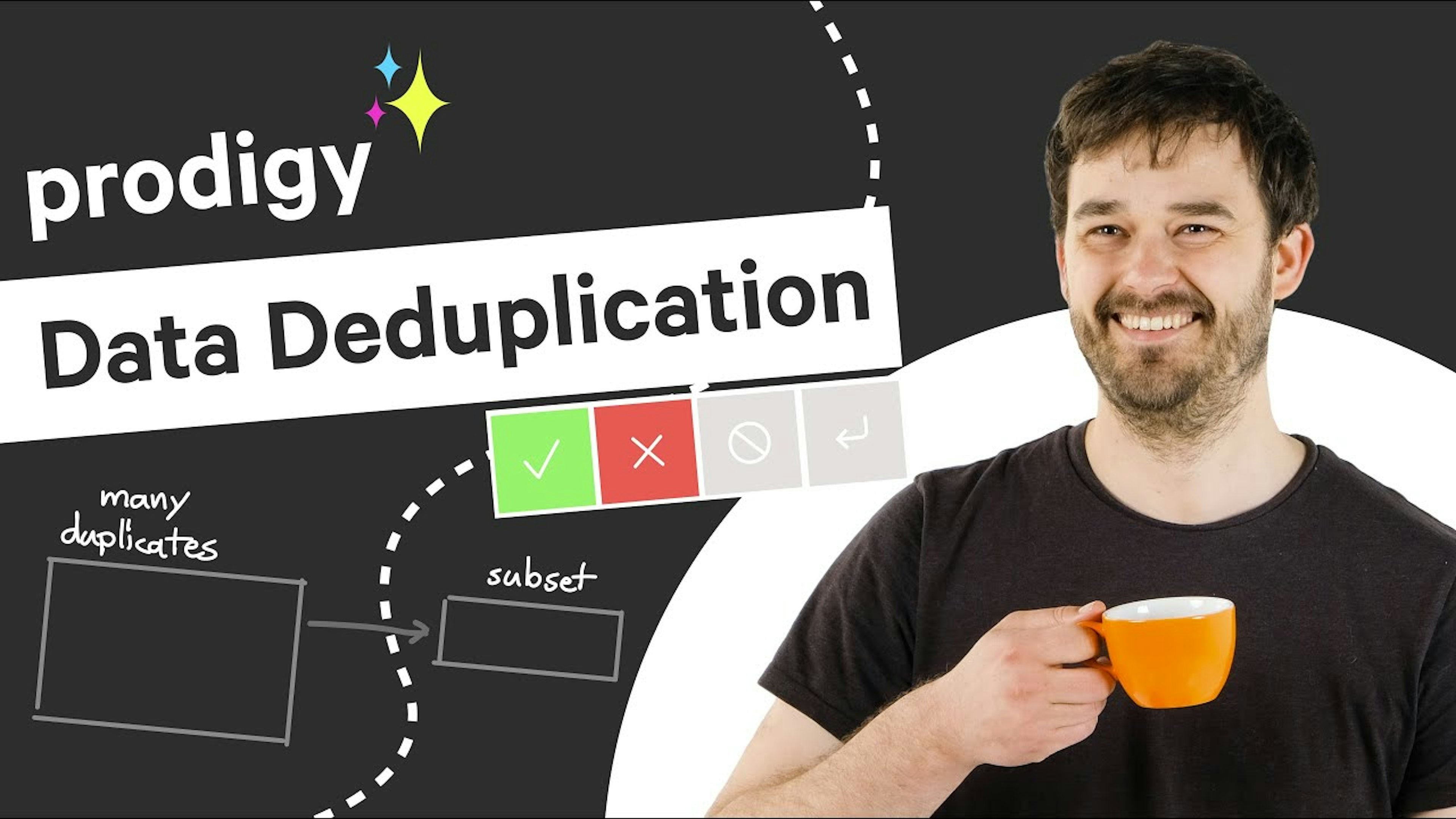
Finding Duplicates in Tabular Data with Jupyter and ProdigyIn this video, we’ll show you how to use Prodigy to train a named entity recognition model from scratch, by taking advantage of semi-automatic annotation and modern transfer learning techniques.
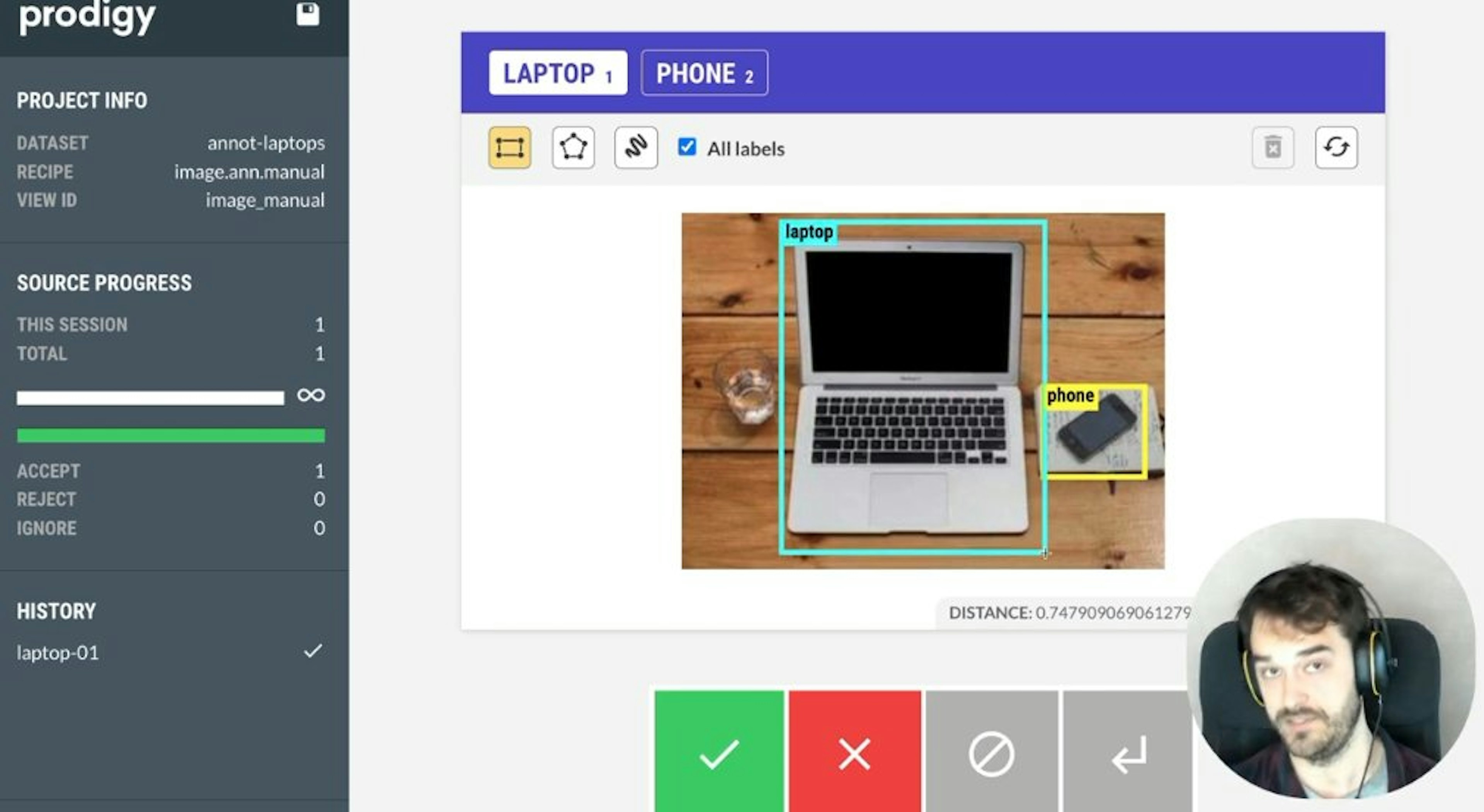
Prodigy v1.10: Dependencies, relations, audio, video & moreVersion 1.10 of Prodigy includes tons of new features, including manual dependency and relation annotation, audio and video annotation, a new and improved image UI, new recipe callbacks, more settings for manual NER, plus various new config options and settings.
✨ prodigy v1.8.0May 20, 2019Support for spaCy v2.1, basic auth, multi-user sessions, review workflow & more
Rapid NLP annotationData Science SummitThis talk presents a fast, flexible and even somewhat fun approach to named entity annotation. Using our approach, a model can be trained for a new entity type in only a few hours, starting from only a feed of unannotated text and a handful of seed terms.
Prodigy: A new tool for radically efficient machine teachingMachine learning systems are built from both code and data. It's easy to reuse the code but hard to reuse the data, so building AI mostly means doing annotation. This is good, because the examples are how you program the behaviour – the learner itself is really just a compiler. What's not good is the current technology for creating the examples. That's why we're pleased to introduce Prodigy, a downloadable tool for radically efficient machine teaching.
A Century of Immigration Rhetoric in the UK ParliamentGennaro, Vissens, Thornewill von Essen, Ravalde, Egan, Dave, Dable, Facini (2026)With all annotated snippets, we trained two transformer-based classifiers, each using a spaCy pipeline consisting of a RoBERTa base transformer model and spaCy’s textcat (text categorisation) component.
Conquering PDFs: document understanding beyond plain textPyData LondonIn this talk, Ines presents a new and modular approach for building robust document understanding systems, using state-of-the-art models and the awesome Python ecosystem.
From PDFs to AI-ready structured data: a deep diveThis blog post presents a new modular workflow for converting PDFs and similar documents to structured data and shows you how to build end-to-end document understanding and information extraction pipelines for industry use cases.
A practical guide to human-in-the-loop distillationThis blog post presents practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
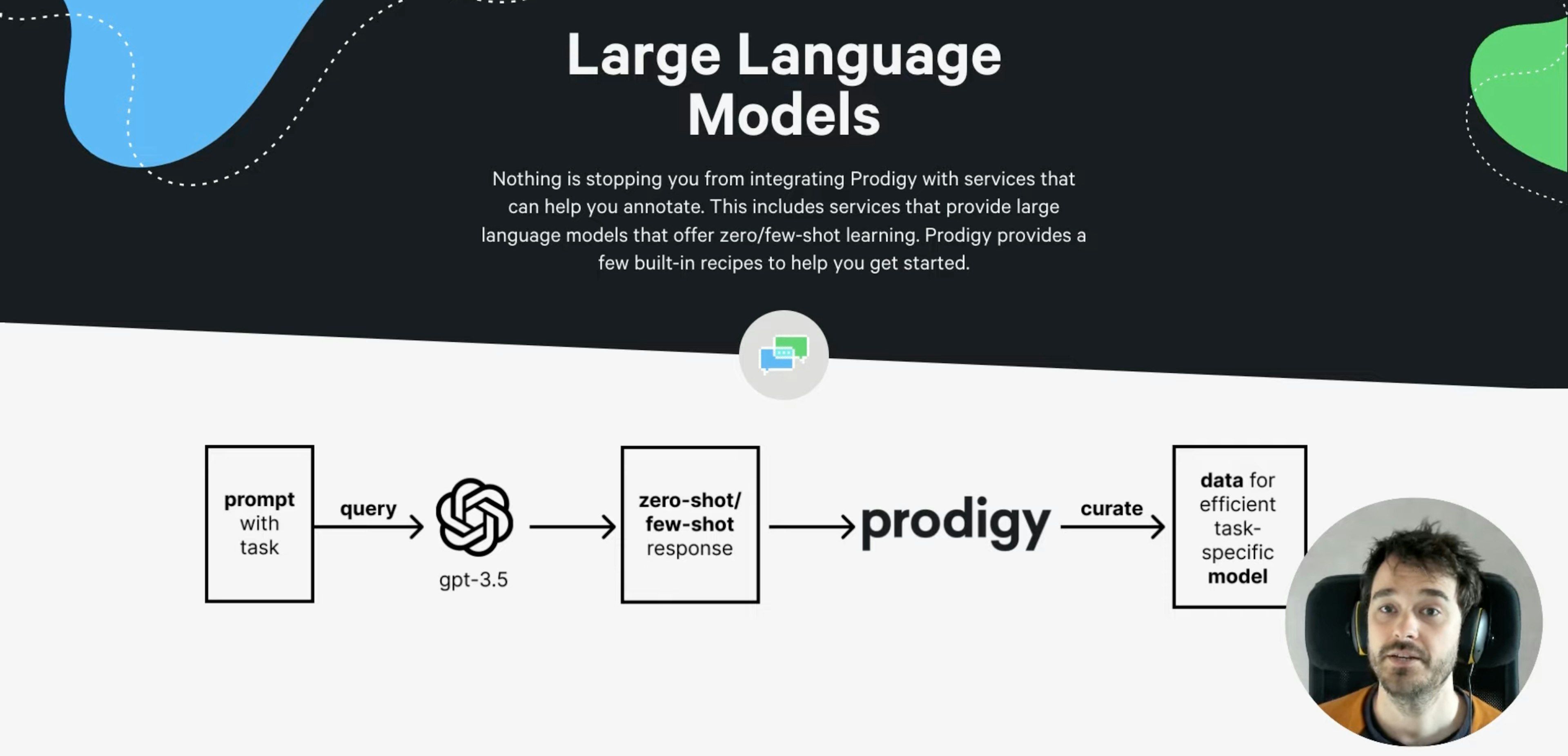
Towards Structured Data: LLMs from Prototype to ProductionU.S. Census Bureau: Center for Optimization and Data Science SeminarThis talk presents pragmatic and practical approaches for how to use LLMs beyond just chat bots, how to ship more successful NLP projects from prototype to production and how to use the latest state-of-the-art models in real-world applications.
Prodigy in 2023: LLMs, task routers, QA and pluginsWe have made a ton of new updates in Prodigy this year with v1.12, v1.13, and v1.14 releases. So we decided to write a post about them.
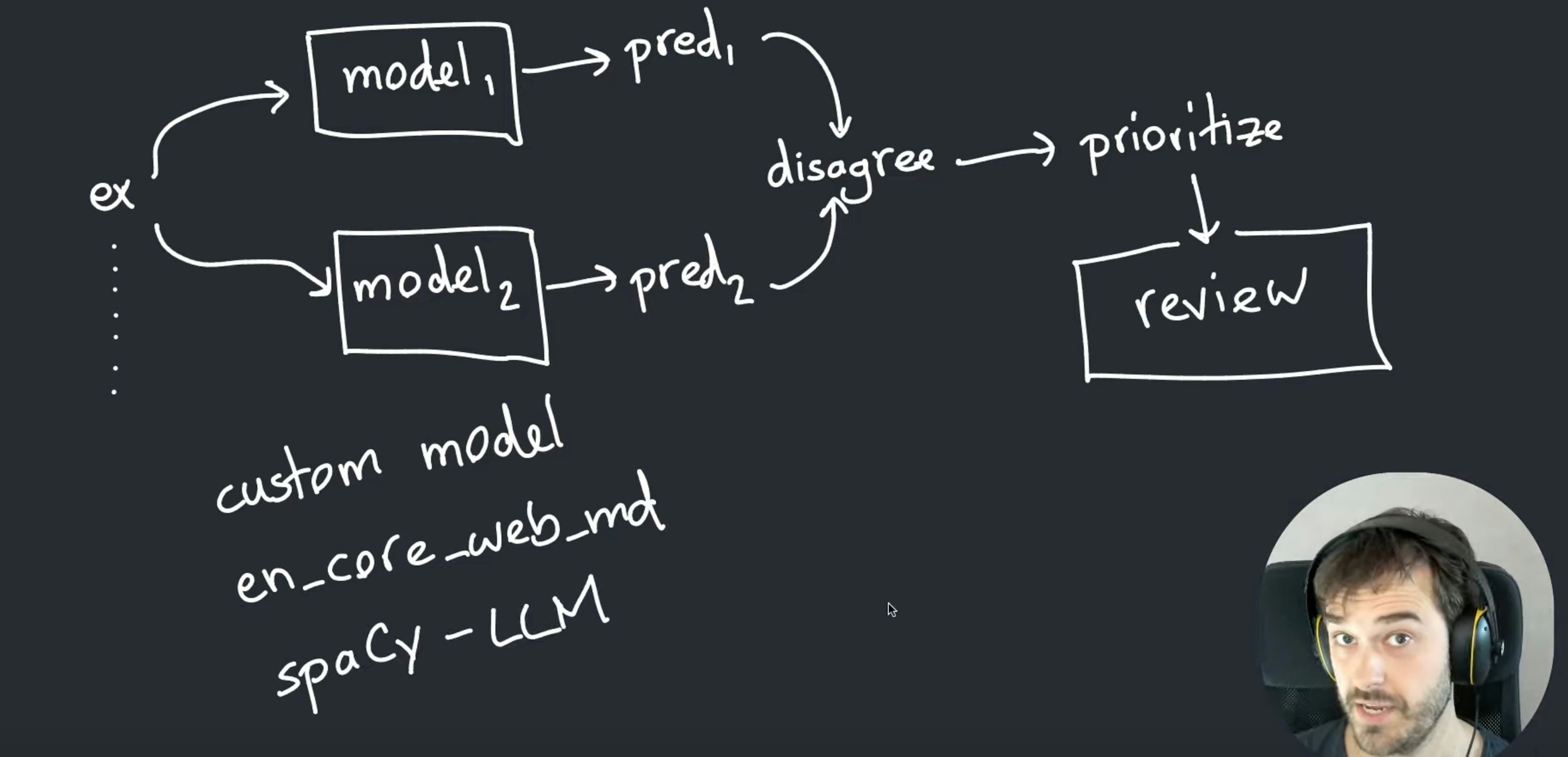
Models as annotators in ProdigyHow to use models and LLMs as annotators to find disagreements and prioritize examples to annotate first.
How Good is the Model in Model-in-the-loop Event Coreference Resolution Annotation?Ahmed, Nath, Regan, Pollins, Krishnaswamy, Martin (2023)Figure 6 illustrates the interface design of the annotation methodology on the popular model-in-the-loop annotation tool - Prodigy. We use this tool for the simplicity it offers in plugging in the various ranking methods we explained.
Finetuning and Bulk Labelling Images with Prodigy In this video, we’ll show how you might be able to improve the annotation experience by using bulk labelling for image classification.
Finding Bad Labels for Text Classification with Jupyter and Prodigy In this video, we’ll show you how to use set up Prodigy to find bad labels in text classification tasks. While many of the techniques are applied to text classification, they can also be used for classification tasks in general.
✨ prodigy v1.11.0Aug 12, 2020spaCy v3 support, annotation for overlapping and nested spans, better installation & more
Image Captioning with Prodigy & PyTorchIn this video, we’ll show you how you can use Prodigy to script fully custom annotation workflows in Python, how to plug in your own machine learning models and how to mix and match different interfaces for your specific use case.
Training a new entity type with Prodigy – annotation powered by active learningIn this video, we’ll show you how to use Prodigy to train a phrase recognition system for a new concept. Specifically, we’ll train a model to detect references to drugs, using text from Reddit.
Supervised learning is great — it's data collection that's brokenShort of Artificial General Intelligence, we'll always need some way of specifying what we're trying to compute. Labelled examples are a great way to do that, but the process is often tedious. However, the dissatisfaction with supervised learning is misplaced. Instead of waiting for the unsupervised messiah to arrive, we need to fix the way we're collecting and reusing human knowledge.
How rightwing rhetoric has risen sharply in the UK parliamentThe GuardianIn-depth analysis by the Guardian in collaboration with University College London, powered by Prodigy for semi-automated data annotation and spaCy for classification model training and prediction.
Conquering PDFs: document understanding beyond plain textPyCon DE & PyDataIn this talk, Ines presents a new and modular approach for building robust document understanding systems, using state-of-the-art models and the awesome Python ecosystem.
✨ prodigy v1.17.0Nov 18, 2024Pages UI for multi-page tasks like longer documents, PDFs or collections of images
Serverless custom NLP with LLMs, Modal and ProdigyIn this blog post, we’ll show you how you can go from an idea and little data to a fully custom information extraction model using Prodigy and Modal, no infrastructure or GPU setup required.
How S&P Global is making markets more transparent with NLP, spaCy and ProdigyA case study on S&P Global’s efficient information extraction pipelines for real-time commodities trading insights in a high-security environment.
ZenML v0.58.0New out-of-the-box Prodigy integration in ZenML for LLMs and beyond, to make data development and annotation a core part of your MLOps lifecycle.
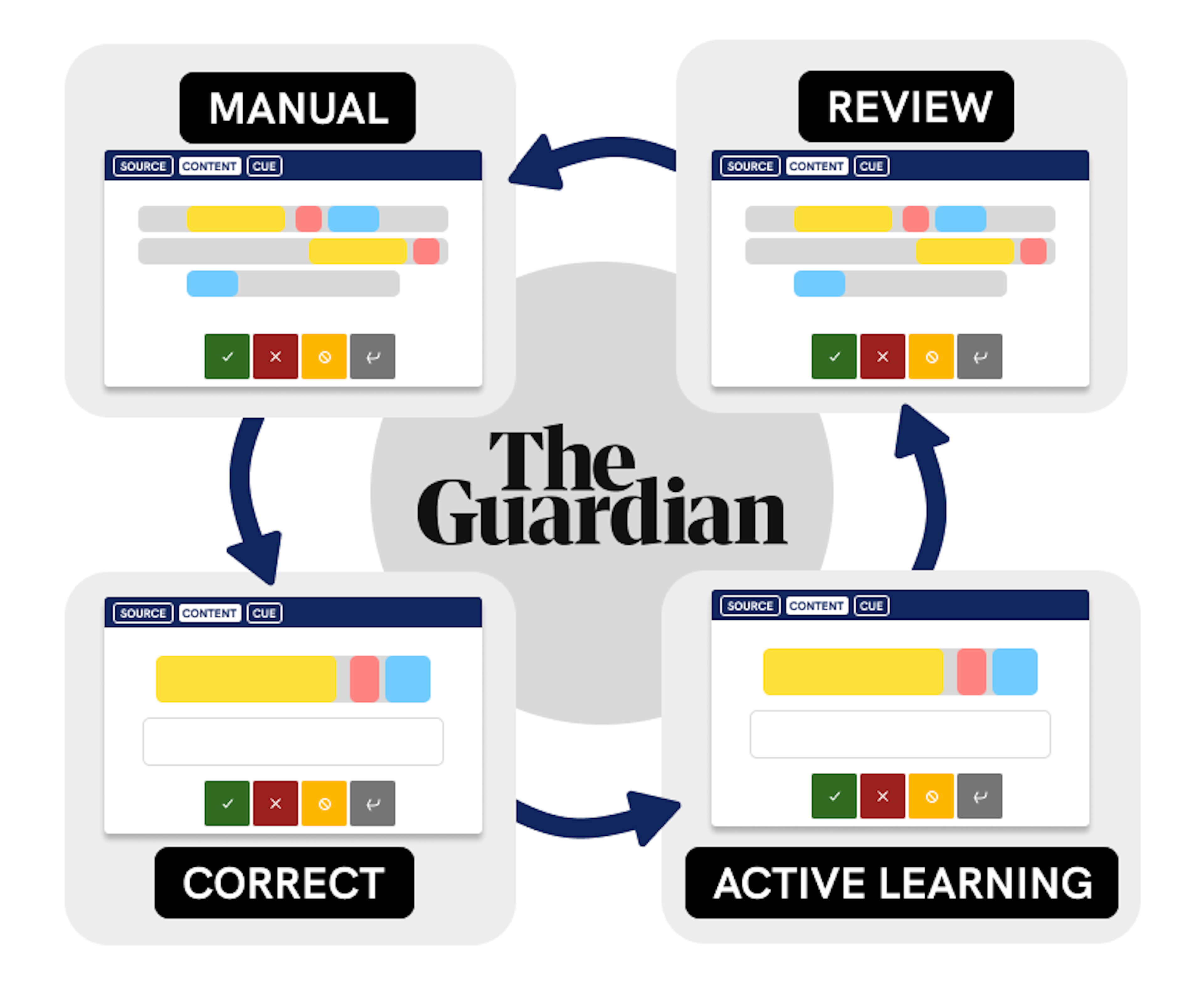
Who said what: using machine learning to correctly attribute quotesThe Guardian Engineering BlogHow the Guardian uses spaCy and Prodigy to train a custom coreference resolution model.
✨ prodigy v1.14.5Oct 24, 2023Toggle for character vs. token highlighting, CSS and JS from local and remote paths
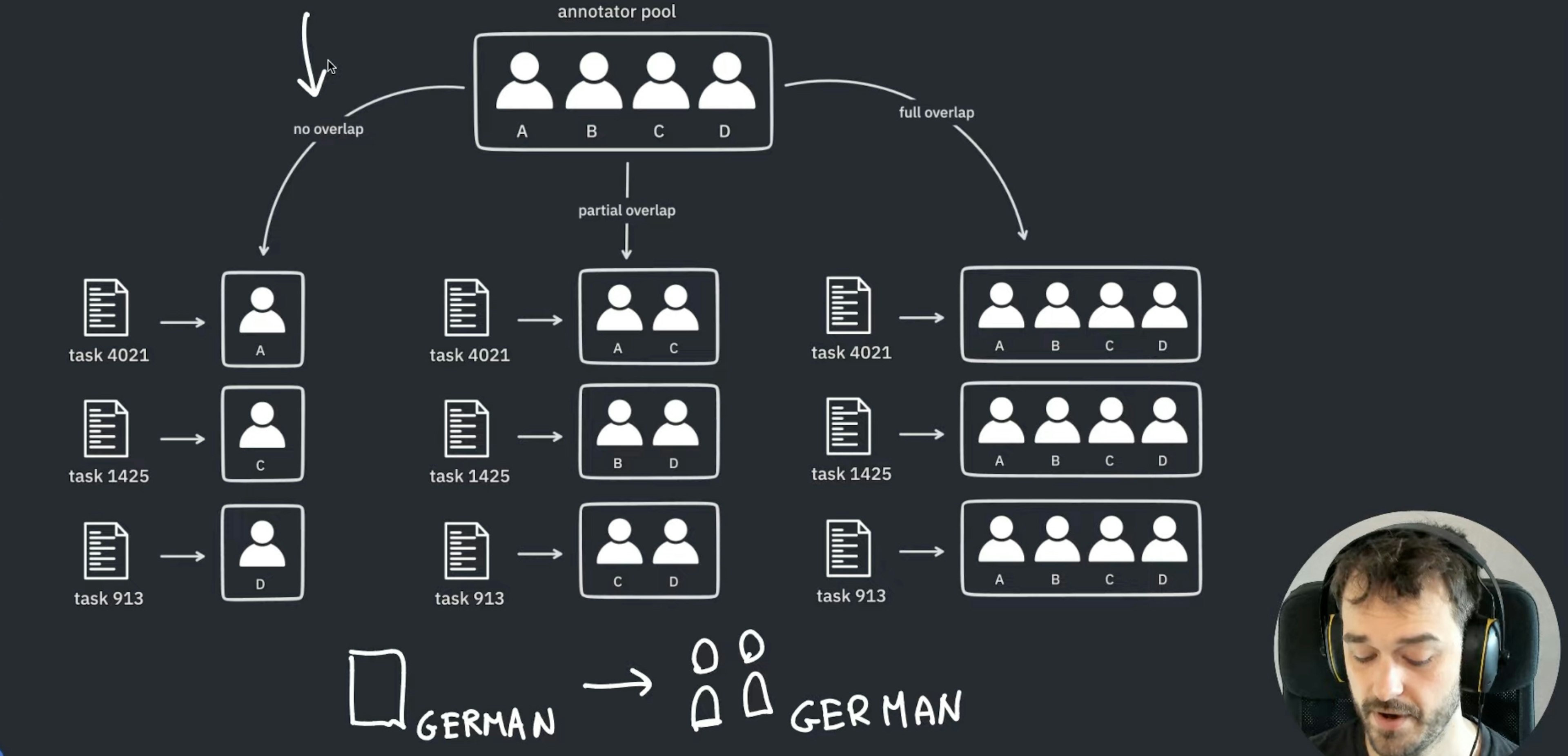
Task Routers in ProdigyHow to use the new task routers to customize how examples are assigned in multi-annotator workflows.
Rulers, NER, and data iterationAbout the power of Rules + ML and the importance of iteration on your pipeline and your data.
How the Guardian approaches quote extraction with NLPA case study of the Guardian's spaCy-Prodigy workflow to modularize quote extraction for content creation. This study includes iterative annotation guidelines and custom interface functionality.
Diary of a spaCy project: Predicting GitHub TagsMany people assume that working on an NLP project involves a lot of machine learning. Our experience is that it's much less about flowing tensors, and more about making a tailored solution. This blogposts demonstrates how a typical spaCy project could be initiated, implemented and executed towards a custom solution.
Talking sense: using machine learning to understand quotesThe Guardian BlogHow the Guardian uses spaCy and Prodigy to train a machine learning model that helps extract quotes from news articles and match them to the correct source.
✨ prodigy v1.10.0Jun 16, 2020Dependency and relation annotation, audio, video, character-based NER & more
Training a Named Entity Recognition Model with Prodigy and Transfer LearningIn this video, we’ll show you how to use Prodigy to train a named entity recognition model from scratch, by taking advantage of semi-automatic annotation and modern transfer learning techniques.
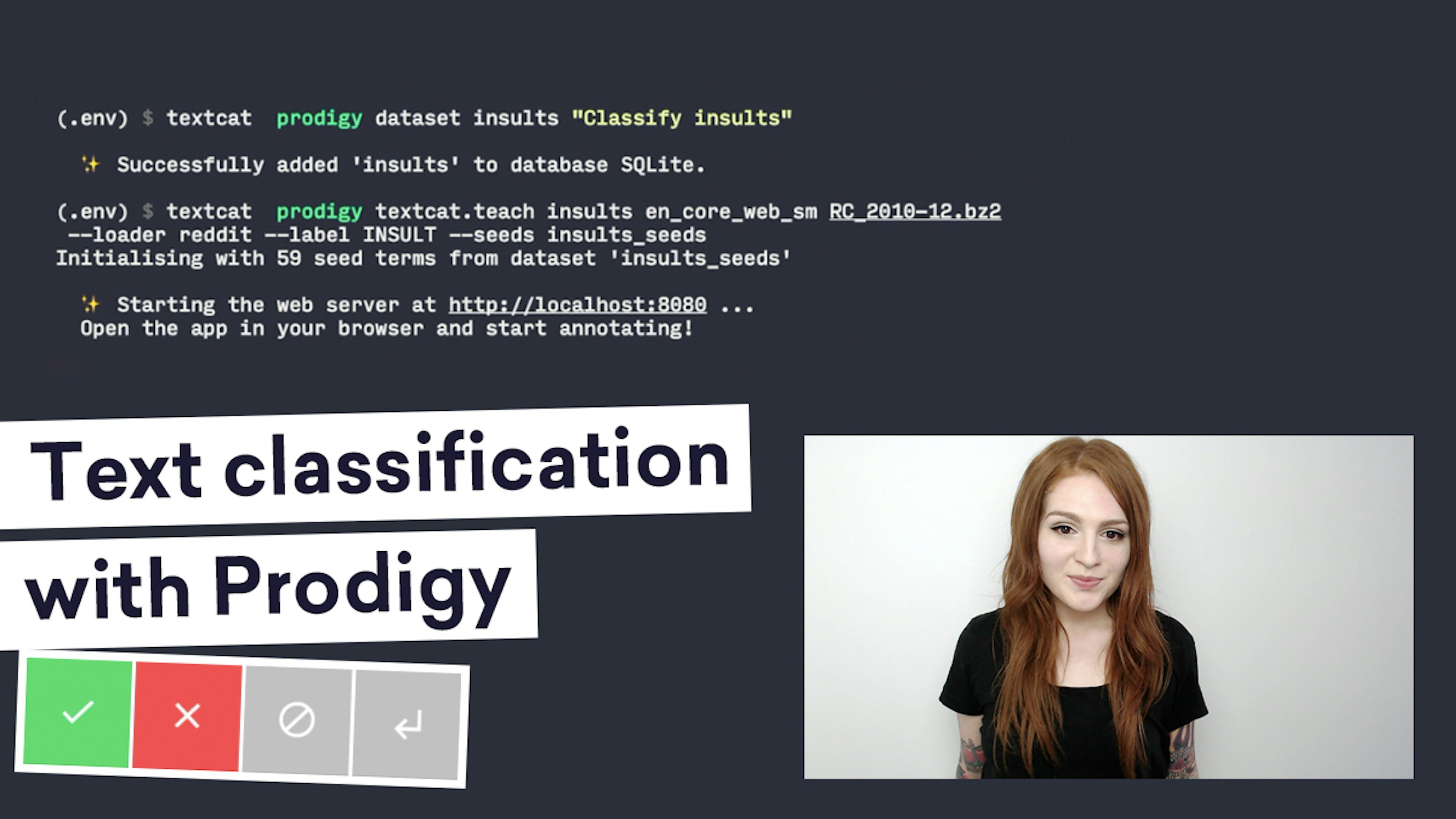
Training an insults classifier with Prodigy in ~1 hourIn this video, we’ll show you how to use Prodigy to train a classifier to detect disparaging or insulting comments. Prodigy makes text classification particularly powerful, because you can try out new ideas very quickly.