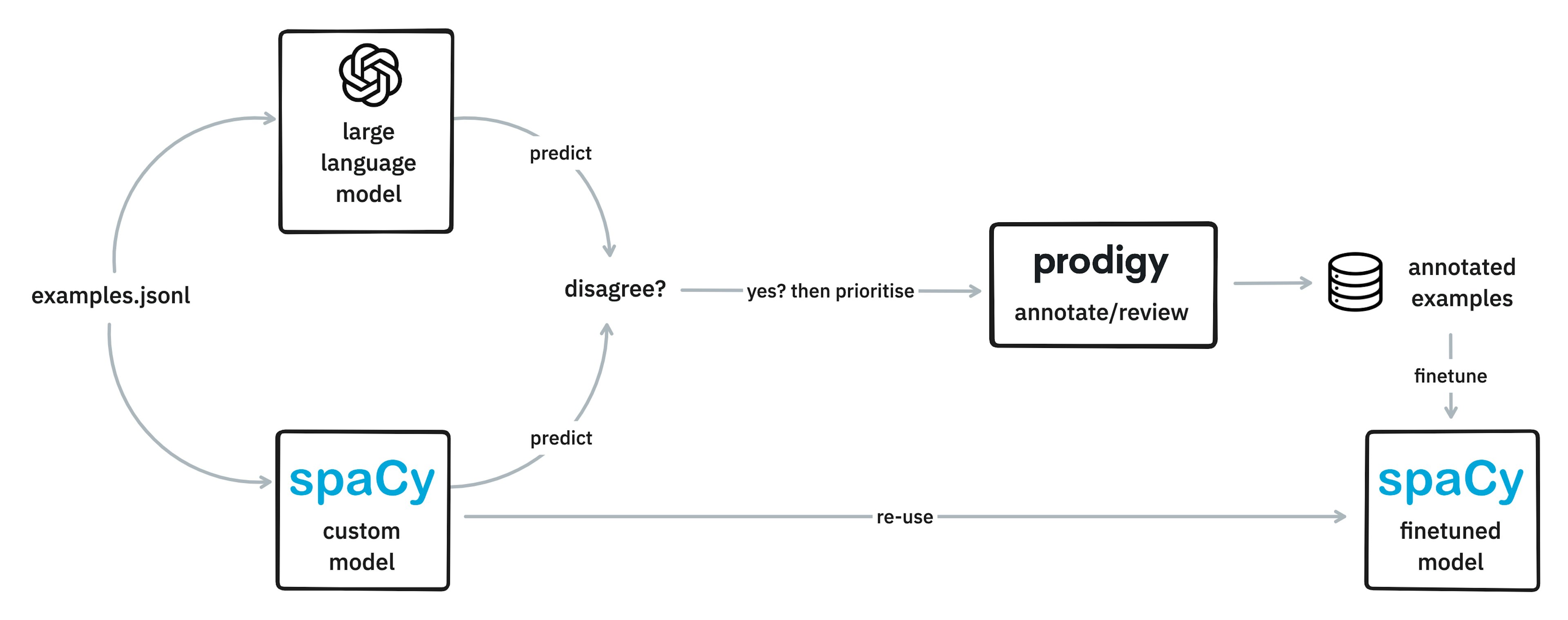
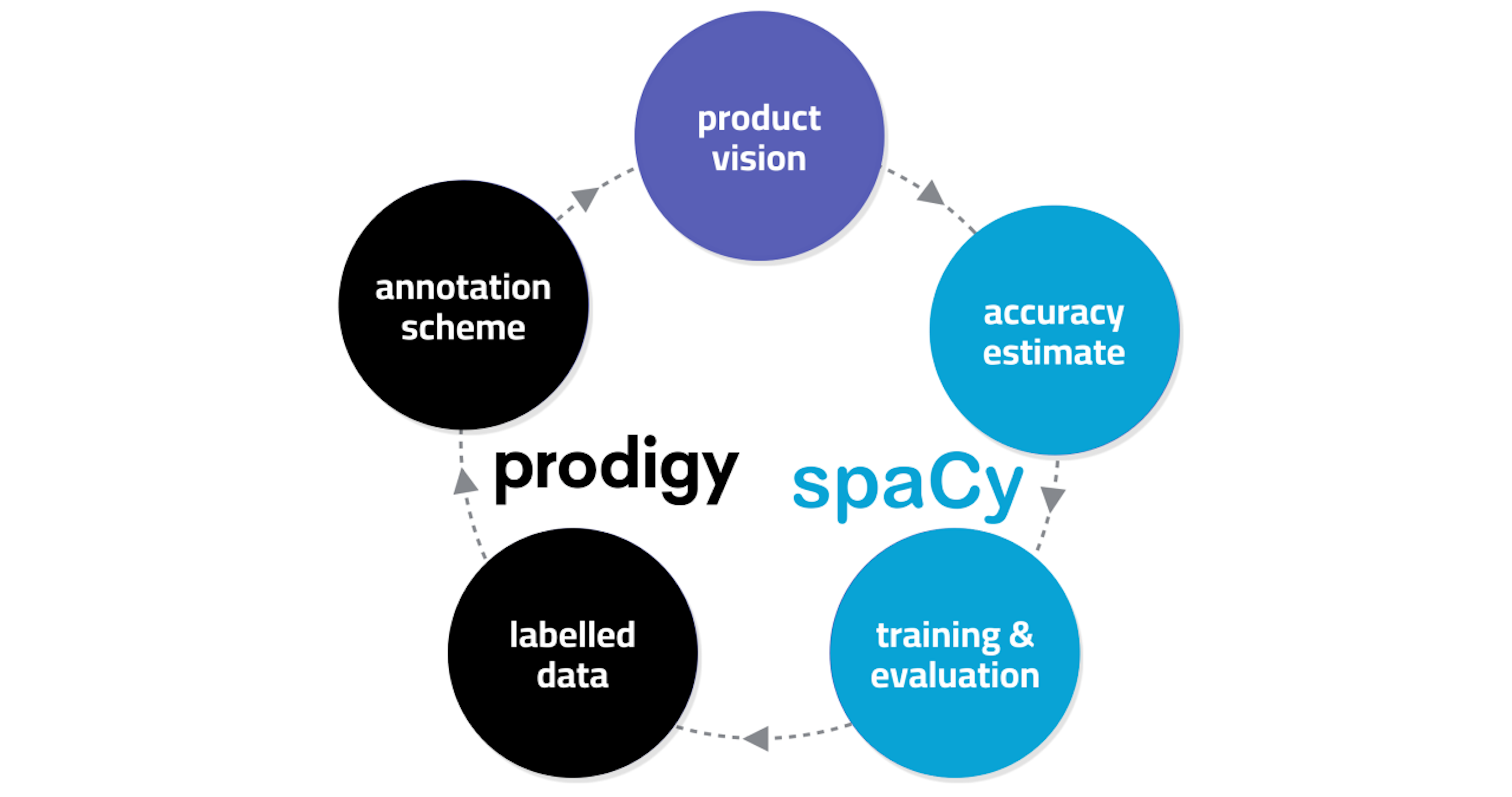
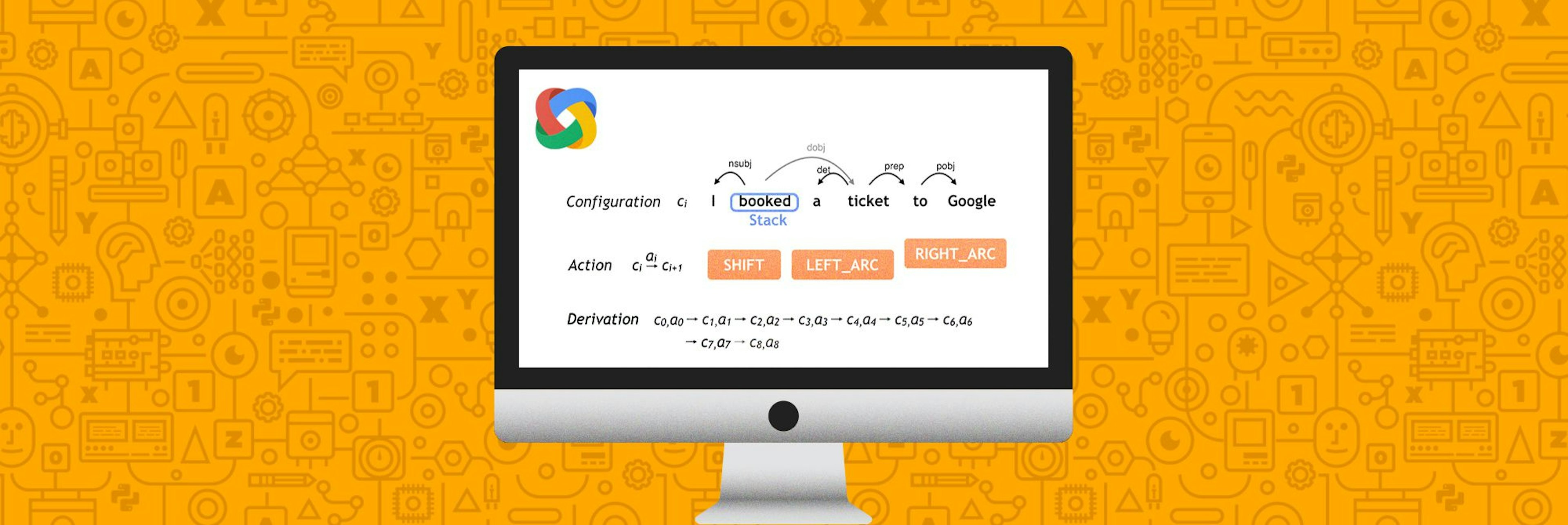
For the last two years, I’ve done almost all of my work in Cython. And I don’t mean, I write Python, and then “Cythonize” it, with various type-declarations et cetera. I just, write Cython. I use "raw" C structs and arrays, and occasionally C++ vectors, with a thin wrapper around malloc/free that I wrote myself. The code is almost always exactly as fast as C/C++, because that's really all it is, but with Python right there, if I want it.