- 9 minute read
- Blog
- Part-of-Speech Tagging
- Dependency Parsing

Yesterday, Google open sourced their Tensorflow-based dependency parsing library, SyntaxNet. The library gives access to a line of neural network parsing models published by Google researchers over the last two years. I’ve been following this work closely since it was published, and have been looking forward to the software being published. This post tries to provide some context around the release — what’s new here, and how important is it?
SyntaxNet provides an important module in a natural language processing (NLP) pipeline such as spaCy. If you zoom out of NLP a little, the technology trend you see is all about extending the range of work computers can take on. Until recently, you couldn’t write software to control a car, and you couldn’t write software to tweak the tone of your emails, analyse customer feedback or monitor global news for significant business risks. Admittedly, none of those capabilities are a self-driving car. But just wait. Language is at the heart of human endeavour. Our total mastery of moving stuff around has long been inevitable, but the potential upside of NLP technologies is so good that it’s hard to predict.
Within this larger value chain, SyntaxNet is a fairly low-level technology. It’s like an improved drill bit. By itself, it doesn’t give you any oil — and oil, by itself, doesn’t give you any energy or plastics, and energy and plastics by themselves don’t give you any work or any products. But if the bottle-neck in that whole value chain was in the efficiency of oil extraction, and your drill bit improves that substantially, the low-level technology can prove pretty important.
I think that syntactic parsing is a bottle-neck technology in NLP, and that the last 4 or 5 years of improvements to this technology will have outsize impacts. Now, you could argue that I think that because this is the problem I’ve been working on for all my adult life, and the technology that I left academia to take commercial. All I can say is that this reverses causation: it’s my belief in the problem’s importance that’s caused my investment in it, not the other way around.
Okay, so I think the problem is important. But how big a step forward is SyntaxNet? If you’ve been using the neural network model in Stanford CoreNLP, you’re using an algorithm that’s almost identical in design, but not in detail. The parsing model used by spaCy is also similar. Conceptually, the contribution of the SyntaxNet work is pretty subtle. It’s mostly about careful experimentation, tuning, and refinement. However, if Google didn’t do this work, it’s possible that nobody else would have. The neural network models that make SyntaxNet tick have also opened up a rich landscape of sexier ideas, and researchers are busily exploring them. There’s a bias towards ideas that make researchers look (and feel!) clever. Probably, we would have ended up with parsing models that were just as accurate, but with incorrect assumptions about which aspects of the system design were important to accuracy, leading to slower progress in the future.
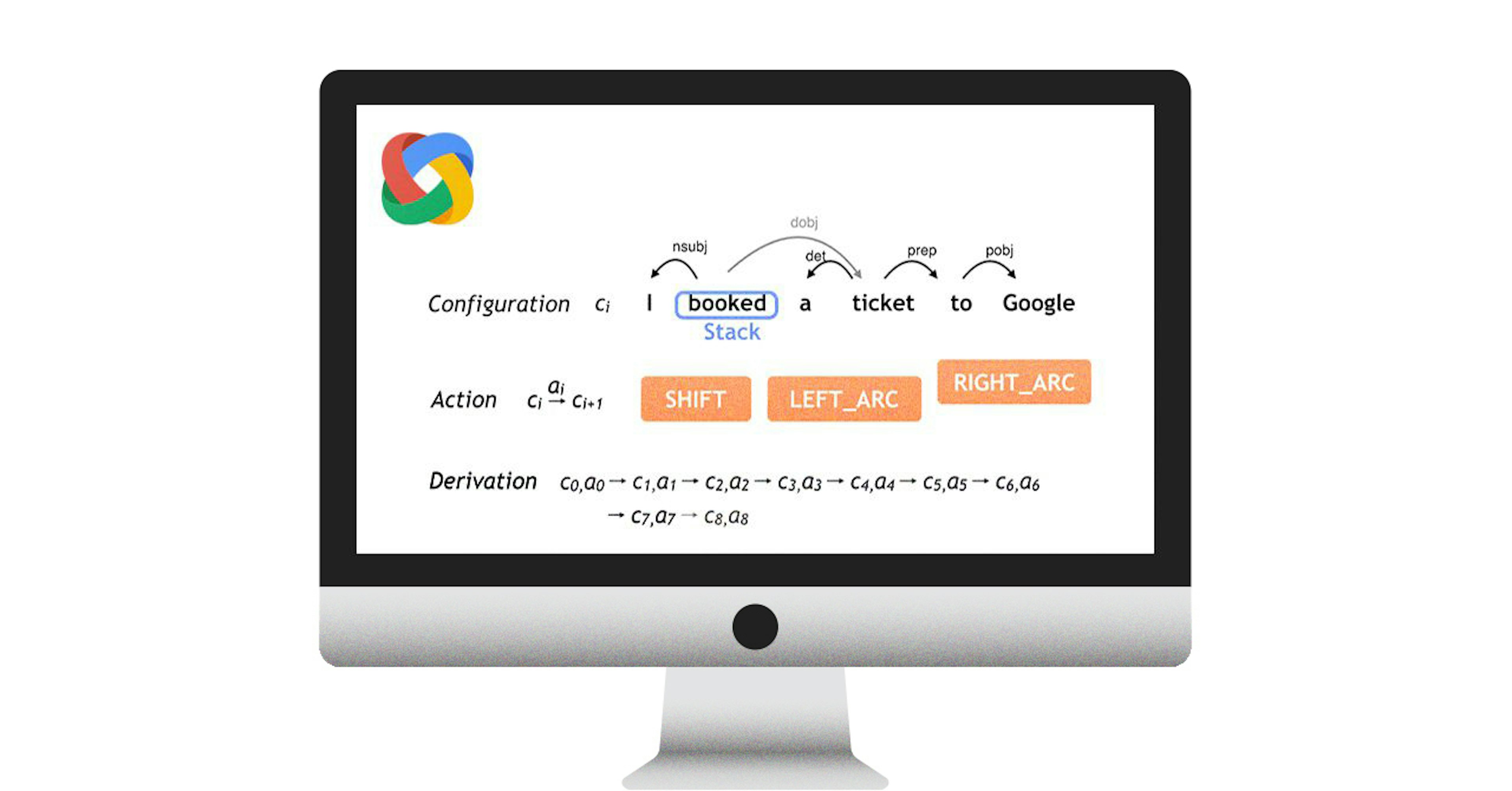
What SyntaxNet does
A syntactic parser describes a sentence’s grammatical structure, to help another application reason about it. Natural languages introduce many unexpected ambiguities, which our world-knowledge immediately filters out. A favourite example:
They ate the pizza with anchovies

A correct parse would link “with” to “pizza”, while an incorrect parse would link “with” to “eat”:

You can explore the technology visually with our displaCy demo, or see a terse example of a rule-based approach to computing with the parse tree. The tree of word-word relationships can also be used to recognise simple phrases, which makes it easy to extend “bag-of-words” technologies such as word2vec. For instance, we parsed every comment posted to Reddit in 2015, and used word2vec on the phrases, entities and words. This produces a nice conceptual map that’s more useful than a model strictly limited to whitespace-delimited words.
SyntaxNet is a library for training and running syntactic dependency parsing models. One model that it provides offers a particularly good speed/accuracy trade-off. In keeping with the fashion of the moment, they’ve called this model Parsey McParseface. Hopefully, they can maintain this sort of meme-based naming system. I think it’ll be a good way to keep the timeline clear. Memes get old fast, and so does NLP technology.
How big is the advance?
Despite the “most accurate in the world” billing, Parsey McParseface is really only inches ahead of equivalent recent research, that uses a more complicated neural network architecture, but with more limited parameter tuning. So, similar technologies are out there in academia. On the other hand, if what you care about is actually doing things, those technologies haven’t been available yet.
On the time-honoured benchmark for this task, Parsey McParseface achieves over 94% accuracy, at around 600 words per second. On the same task, spaCy achieves 92.4%, at around 15,000 words per second. The extra accuracy might not sound like much, but for applications, it’s likely to be pretty significant.
For any predictive system, often the important consideration is the difference to a baseline predictor, rather than the absolute accuracy. A model that predicts that the weather will be the same as yesterday will often be accurate, but it’s not adding any value. The thing about dependency parsing is that about 80% of the dependencies are very easy and unambiguous, which means that a system that only predicts those dependencies correctly is injecting very little extra information, that wasn’t trivially available by just looking at each word and its neighbours.
In summary, I think Parsey McParseface is a very nice milestone on a larger trend. The thing that’s really significant is how quickly the speed and accuracy of natural language processing technologies is advancing. I think there are lots of ideas that didn’t work yesterday, that are suddenly becoming very viable.
What’s next?
One of the things I’m most excited about is that there’s a very clear way forward, given the design of the Parsey McParseface model. It’s one of those things where you can say, “Okay, if this works, that’s great news”. This type of parser, pioneered by Joakim Nivre in 2004, reads the sentence one word at a time, and maintains only a handful of competing representations. You can slot in any state representation, any set of actions, and any probability model into this architecture. For instance, if you’re parsing the output of a speech recognition system, you could have the parser refine the speech recogniser’s guess at the words, based on the syntactic context. If you’re populating a knowledge base, you can extend the state representation to include your target semantics, and learn it jointly with the syntax.
Joint models and semi-supervised learning have always been the “motherhood and apple pie” of natural language understanding research. There was never any doubt that these things were good — but without a concrete proposal, they’re just platitudes. It was always clear that chopping the task of understanding a sentence up into lots of subproblems, and having a pipeline of distinct models, was an unsatisfying solution. It was also obvious that a natural language understanding system should be able to make use of the vast quantities of unannotated text available. I think a transition-based neural network model gives a convincing answer to both questions. You can learn any structure you like this way, and the more text you see, the more you learn, without adding any new parameters to the model.
Obviously, we want to build a bridge between Parsey McParseface and spaCy, so that you can use the more accurate model with the sweeter spaCy API. However, for any individual use-case, there’s always a lot of tuning to do to make these technologies really perform. In particular, every application sees a different type of text. Accuracy goes up substantially if the statistical model is tuned to the domain. For instance, in well edited text such as a financial report, you want the model to consider capitalisation as a decisive indicator — but if you’re parsing tweets, capitalisation is almost meaningless.
Our plan is to solve this problem by providing a range of pre-trained models, adapted to different languages and genres. We also have some ideas we’re really excited about, to help each user train their own custom model, as painlessly as possible. We think that in NLP, the algorithms are racing ahead, while the data is lagging behind. We want to fix that. If you can’t wait for the result, I hope you’ll get in touch.



