Mastering spaCyDéborah Mesquita, Duygu Altinok (Packt Publishing, 2025)Build structured NLP solutions with custom components and models powered by LLMs. By end of the book you will be empowered to build robust NLP pipelines and integrate them with web applications to build end-to-end solutions.
calamanCy: A Tagalog Natural Language Processing ToolkitMiranda (2023), EMNLP 2023We introduce calamanCy, an open-source toolkit for constructing NLP pipelines for Tagalog. It is built on top of spaCy, enabling easy experimentation and integration with other frameworks.
Introduction to Japanese Natural Language ProcessingMasato Hagiwara, Paul O’Leary McCann (2021)A thorough guide for programmers working with Japanese text, covering fundamental issues like tokenization and recent research topics like generating natural language texts.
✨ prodigy v1.10.0Jun 16, 2020Dependency and relation annotation, audio, video, character-based NER & more
SyntaxNet in context: Understanding Google's new TensorFlow NLP modelYesterday, Google open sourced their Tensorflow-based dependency parsing library, SyntaxNet. The library gives access to a line of neural network parsing models published by Google researchers over the last two years. I've been following this work closely since it was published, and have been looking forward to the software being published. This post tries to provide some context around the release — what's new here, and how important is it?
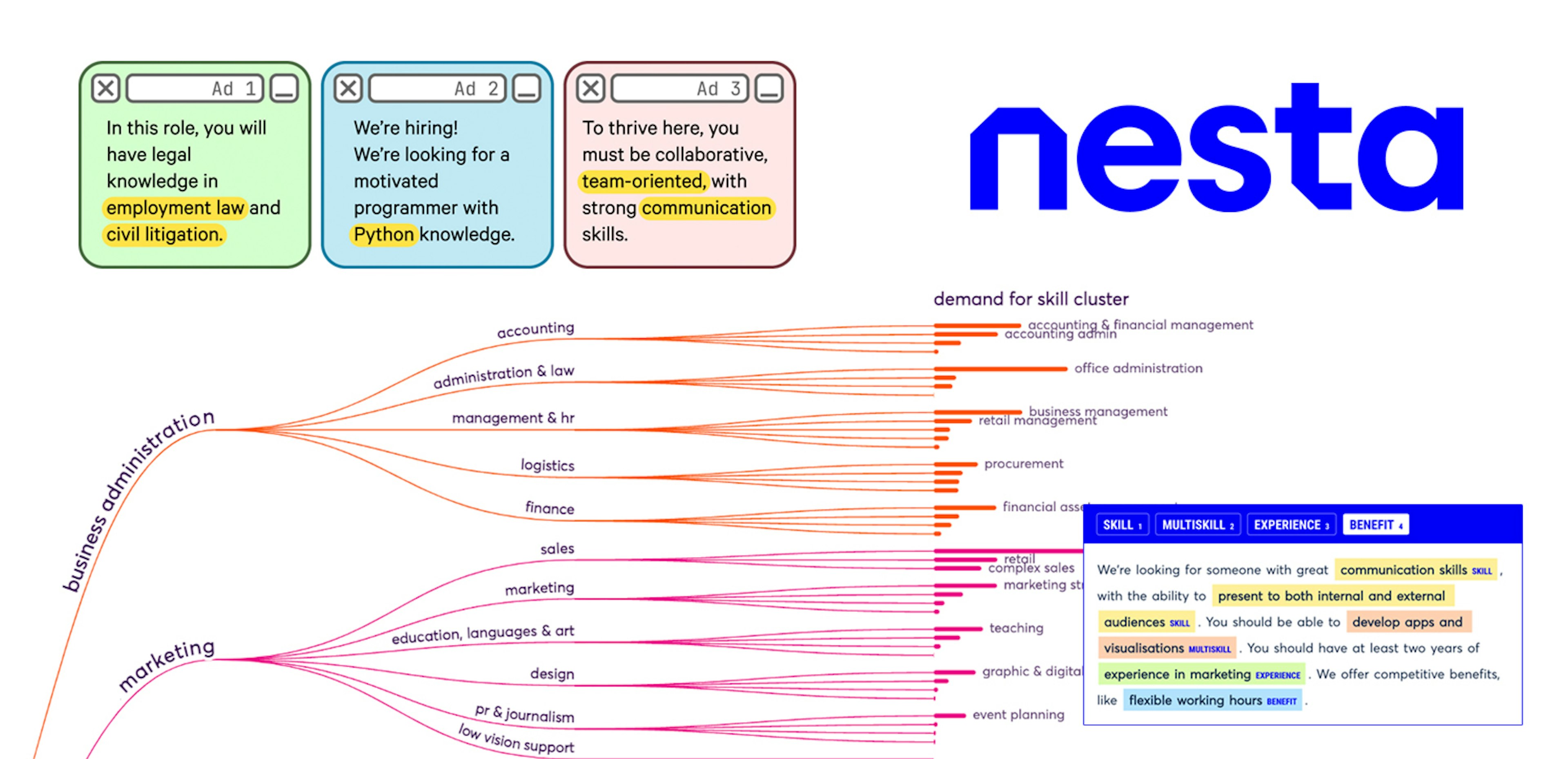
How Nesta uses NLP to process 7m job ads and shed light on the UK’s labor marketA case study on Nesta’s workflow for extracting 7 million job ads to better understand UK skill demand, using a custom mapping step to match skills to any government taxonomy.
Mastering spaCyDuygu Altinok (Packt Publishing, 2021)An end-to-end practical guide to implementing NLP applications using the Python ecosystem. By the end of this book, you'll be able to confidently use spaCy, including its linguistic features, word vectors, and classifiers, to create your own NLP apps.
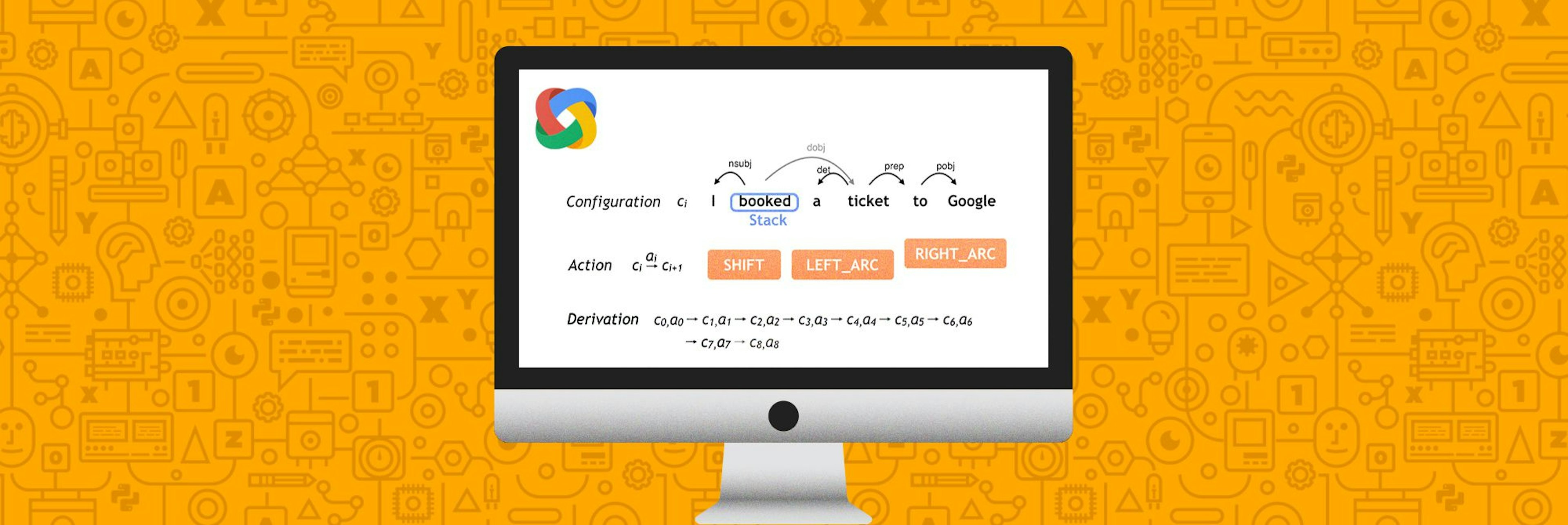
Parsing English in 500 Lines of PythonThis post explains how transition-based dependency parsers work, and argues that this algorithm represents a break-through in natural language understanding. A concise sample implementation is provided, in 500 lines of Python, with no external dependencies. This post was written in 2013. In 2015 this type of parser is now increasingly dominant.
Muted: Multilingual Targeted Offensive Speech Identification and VisualizationTillmann, Trivedi, Rosenthal, Borse, Zhang, Sil, Bhattacharjee (2023)Muted can leverage any transformer-based HAP-classification model [...] to identify toxic spans, without further fine-tuning. In addition, we use the spaCy library to identify the specific targets and arguments for the words predicted by the attention heatmaps.
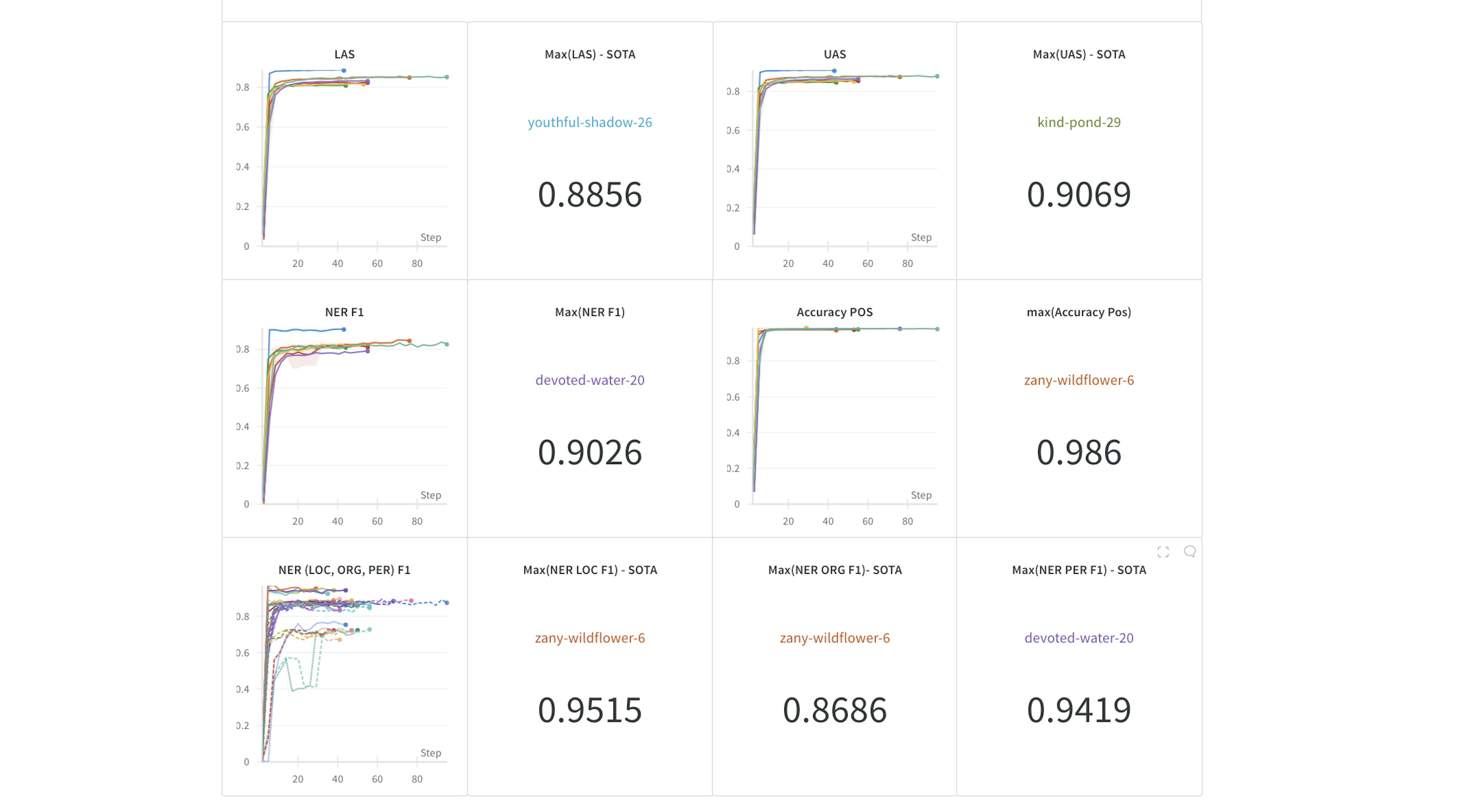
Universal Dependencies v2.5 Benchmarks for spaCyWe present Universal Dependencies v2.5 benchmarks for spaCy v3.2 that show the competitive performance of spaCy in a direct comparison with Stanza and Trankit using the end-to-end evaluation from the CoNLL 2018 Shared Task.
Prodigy v1.10: Dependencies, relations, audio, video & moreVersion 1.10 of Prodigy includes tons of new features, including manual dependency and relation annotation, audio and video annotation, a new and improved image UI, new recipe callbacks, more settings for manual NER, plus various new config options and settings.
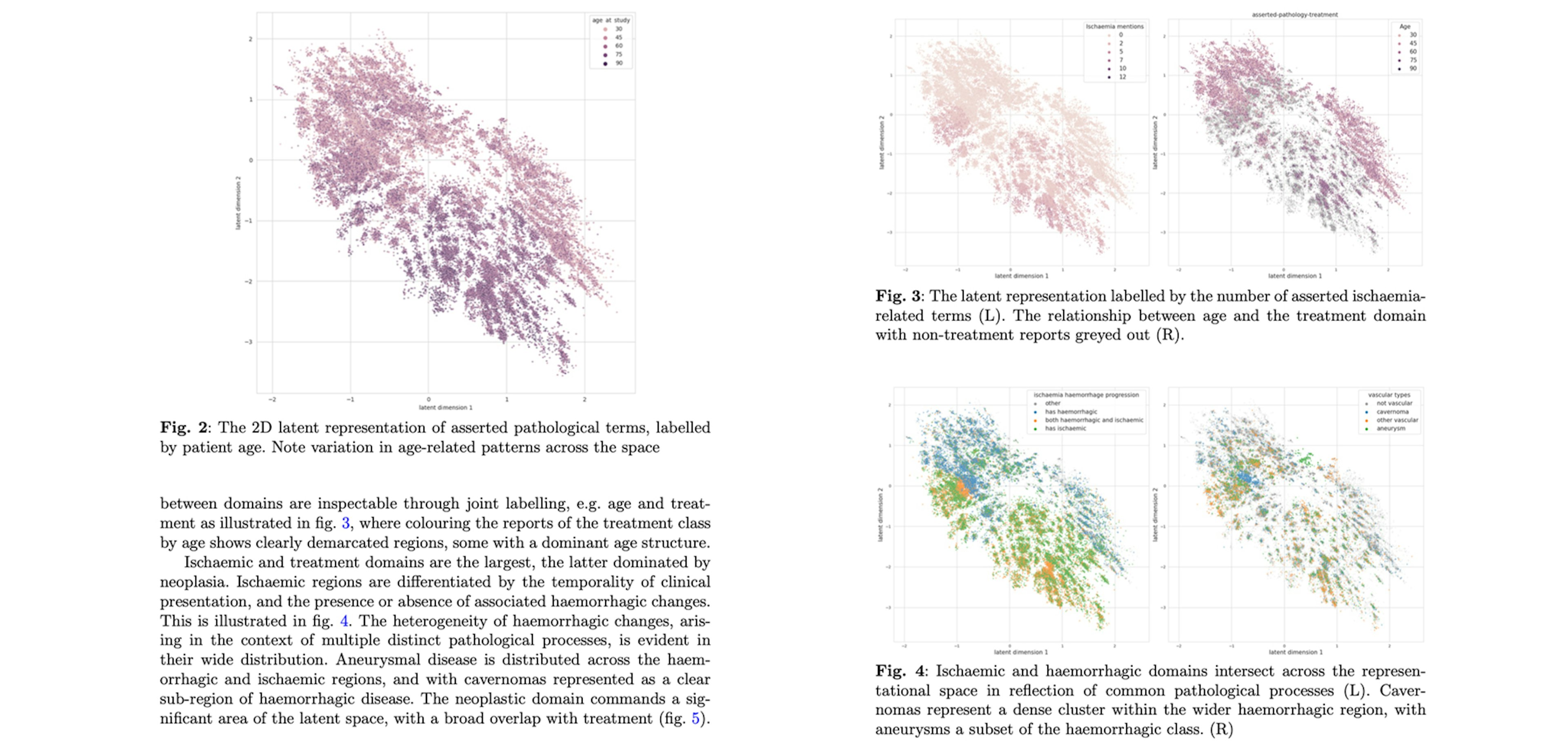
Neuradicon: operational representation learning of neuroimaging reportsWatkins, Gray, Julius, Mah, Pinaya, Wright, Jha, Engleitner, Cardoso, Ourselin, Rees, Jaeger, Nachev (2023)Labelled data for each task was produced using the Prodigy labelling tool. Each report was labelled in a paired-annotation manner. [...] We used the grammatical dependency parse produced by the spaCy parser as input and implemented the patterns using the spaCy dependency matcher.
Reproducible spaCy NLP Experiments with Weights & BiasesWeights & Biases BlogThis tutorial will show how to add Weights & Biases to any spaCy NLP project to track your experiments, save model checkpoints, and version your datasets.
displaCy.js: An open-source NLP visualizer for the modern webWith new offerings from Google, Microsoft and others, there are now a range of excellent cloud APIs for syntactic dependencies. A key part of these services is the interactive demo, where you enter a sentence and see the resulting annotation. We're pleased to announce the release of displaCy.js, a modern and service-independent visualization library. We hope this makes it easy to compare different services, and explore your own in-house models.