Using natural language processing to identify emergency department patients with incidental lung nodules requiring follow-upMoore, Socrates, Hesami, Denkewicz, Cavallo, Venkatesh, Taylor (2025)CT reports were annotated by MD raters using Prodigy software to develop a stepwise NLP “pipeline” that first excluded prior or known malignancy, determined the presence of a lung nodule, and then categorized any recommended follow-up. NLP was developed using a RoBERTa large language model on the spaCy platform.
spacy-llm: From quick prototyping with LLMs to more reliable and efficient NLP solutionsAstraZeneca NLP Community of PracticeLLMs are paving the way for fast prototyping of NLP applications. Here, Sofie showcases how to build a structured NLP pipeline to mine clinical trials, using spaCy and spacy-llm. Moving beyond a fast prototype, she offers pragmatic solutions to make the pipeline more reliable and cost efficient.
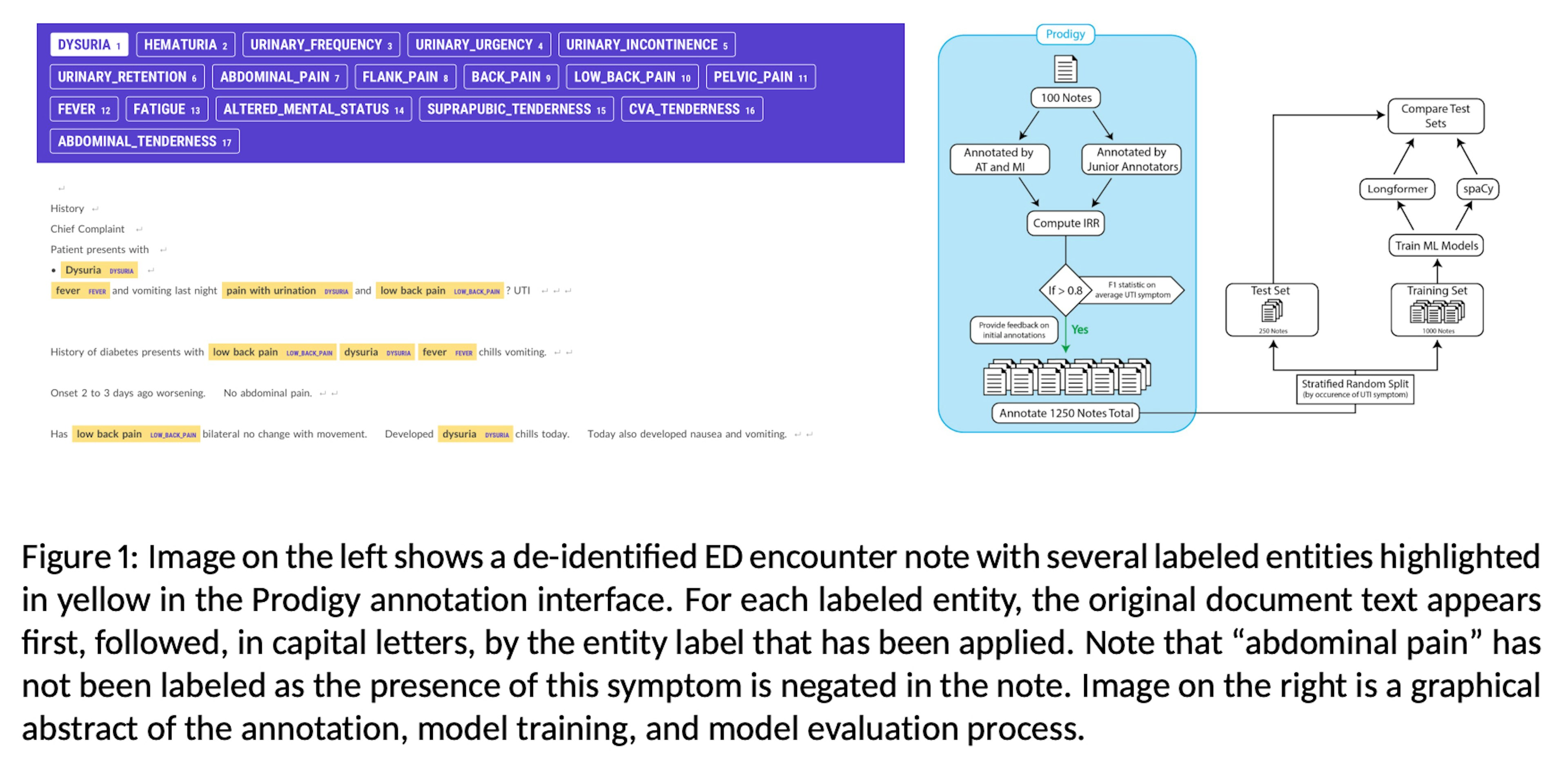
Identifying Signs and Symptoms of Urinary Tract Infection from Emergency Department Clinical Notes Using Large Language ModelsIscoe, Socrates, Gilson, Chi, Li, Huang, Kearns, Perkins, Khandjian, Taylor (2023)For annotation we employed Prodigy, a scriptable annotation tool designed to maximize efficiency, enabling data scientists to perform the annotation tasks themselves and facilitating rapid iterative development in natural language processing (NLP) projects.
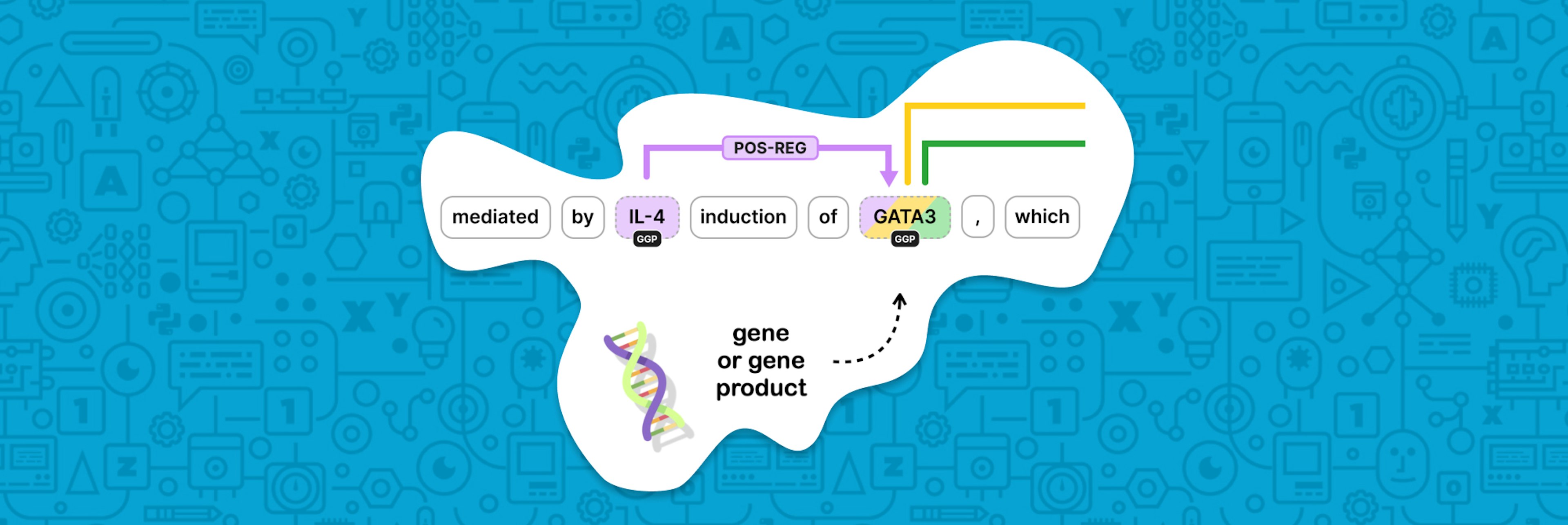
Implementing a custom trainable component for relation extractionRelation extraction refers to the process of predicting and labeling semantic relationships between named entities. In this blog post, we'll go over the process of building a custom relation extraction component using spaCy and Thinc. We'll also add a Hugging Face transformer to improve performance at the end of the post. You'll see how you can utilize Thinc's flexible and customizable system to build an NLP pipeline for biomedical relation extraction.
Automated Identification of Clinical Procedures in Free-Text Electronic Clinical Records with a Low-Code Named Entity Recognition WorkflowMacri, Teoh, Bacchi, Sun, Selva, Casson, Chan (2022), Methods of Information in MedicineThe use of a low-code annotation software tool [Prodigy] allows the rapid creation of a custom annotation dataset to train a NER model to identify clinical procedures stored in free-text electronic clinical notes.
Toward Automatic Summarization of Hospital Discharge NotesLandes (2024)For NLP tasks, vectorizers include spaCy token features such as part of speech (POS) tags, named entity recognition (NER) tags, dependency head relations and depth.
Herding LLMs Towards Structured NLPGlobal AI ConferenceThis talk shows how we integrate LLMs into spaCy, leveraging its modular and customizable framework. This allows for cheaper, faster and more robust NLP - driven by cutting-edge LLMs, without compromising on having structured, validated data.
scispacy v0.5.3A Python package containing spaCy models for processing biomedical, scientific or clinical text, developed by AI2.
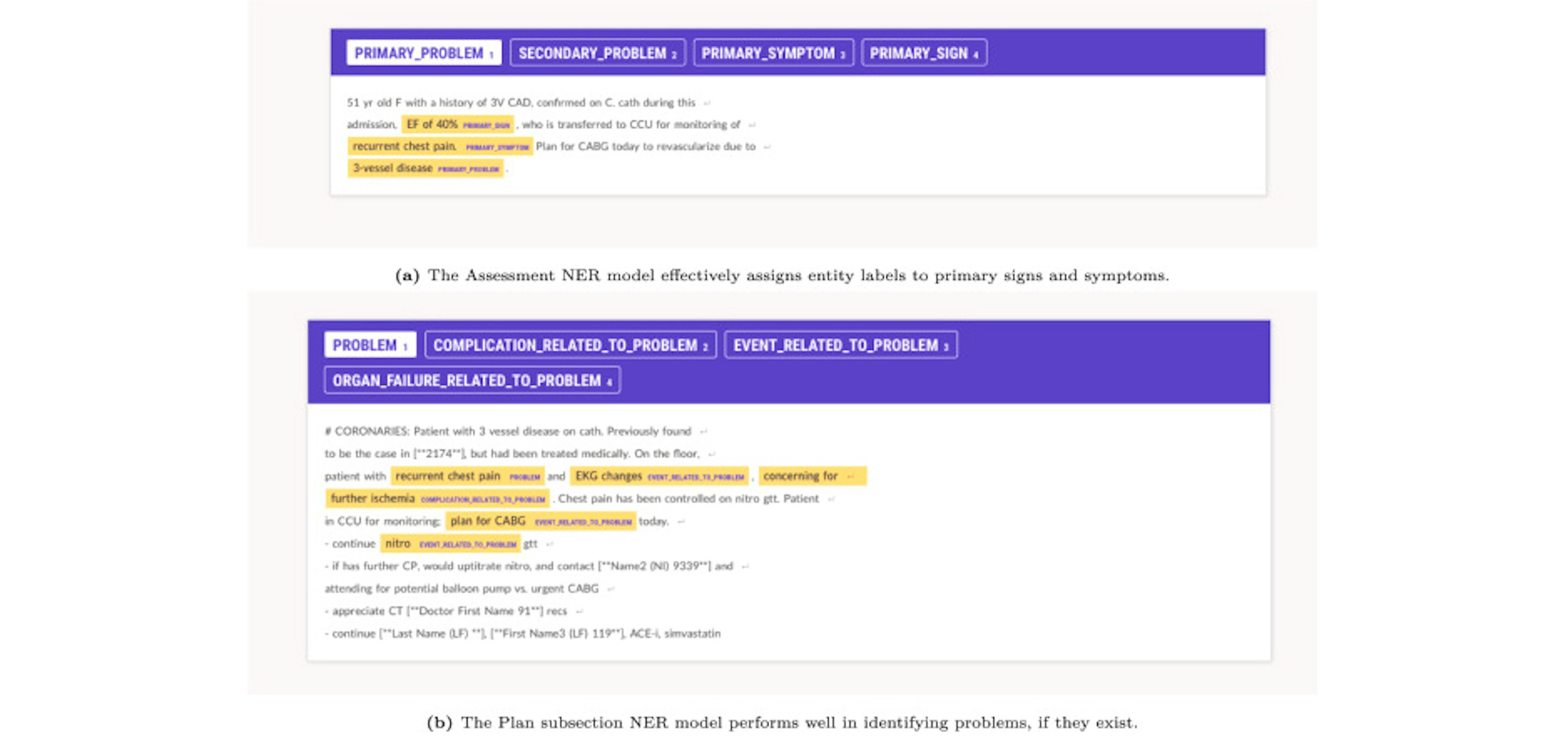
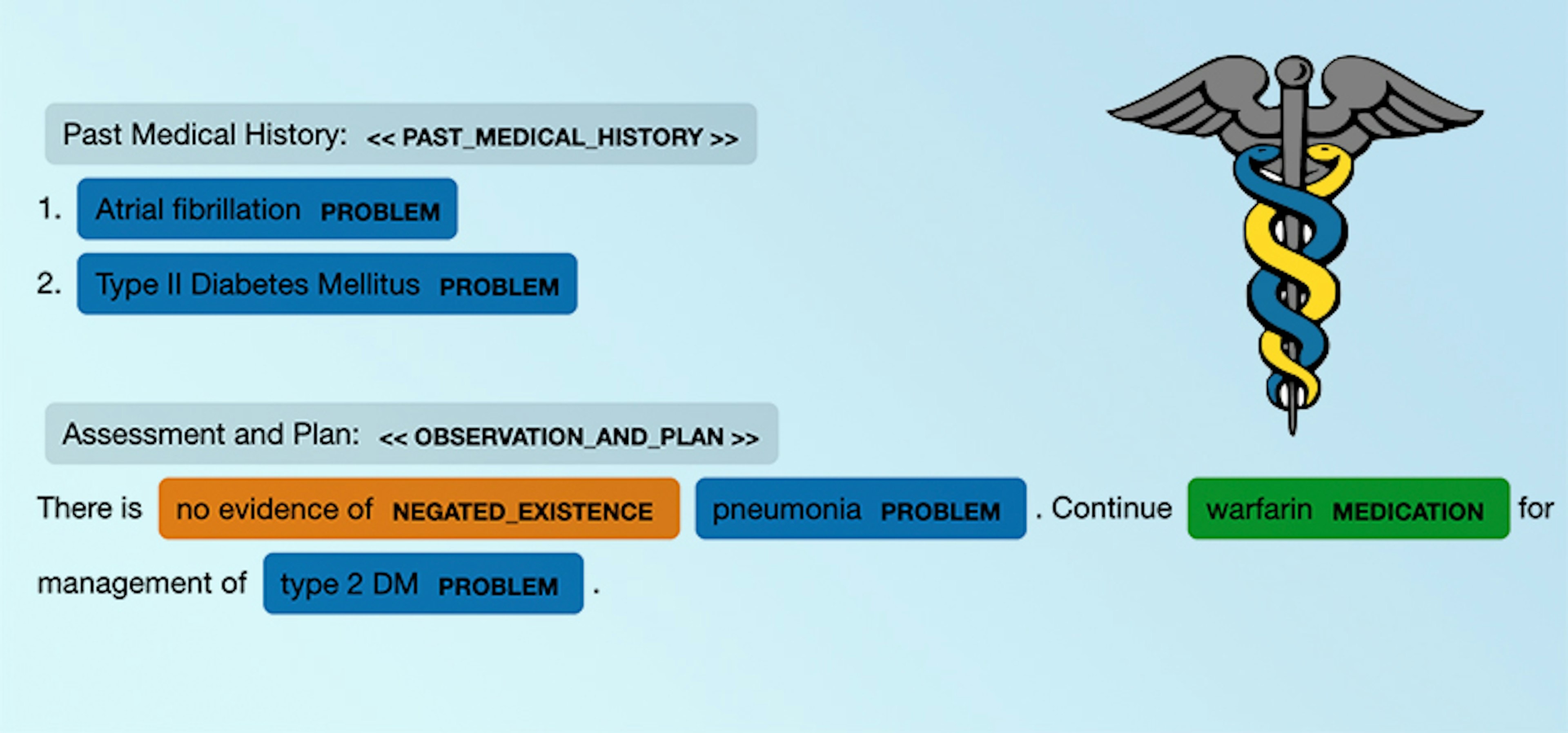
Predicting relations between SOAP note sections: The value of incorporating a clinical information modelSocrates, Gilson, Lopez, Chi, Taylor, Chartash (2023), Journal of Biomedical InformaticsTo support human annotation, we first annotate 100 Assessment and Plan subsections manually using Prodigy, and then use spacy-transformers to fine-tune a general domain RoBERTa-base model pretrained on OntoNotes 5 for both the Assessment and Plan section NER tagging.
Healthsea: an end-to-end spaCy pipeline for exploring health supplement effectsCreate better access to health with machine learning and natural language processing. Read about our journey of developing Healthsea, an end-to-end spaCy pipeline for analyzing user reviews to supplement products and extracting potential effects on health.
The application of natural language processing for the extraction of mechanistic information in toxicologyConradi, Luechtefeld, de Haan, Pieters, Freedman, Vanhaecke, Vinken, Teunis (2024)All steps were conducted using the open-source Python package spaCy. Specifically, the NER model was trained using scispaCy en-core-sci-lg (Neumann et al., 2019) as a starting point, which allowed for a vocabulary (word vectors) and grammar trained on scientific literature.
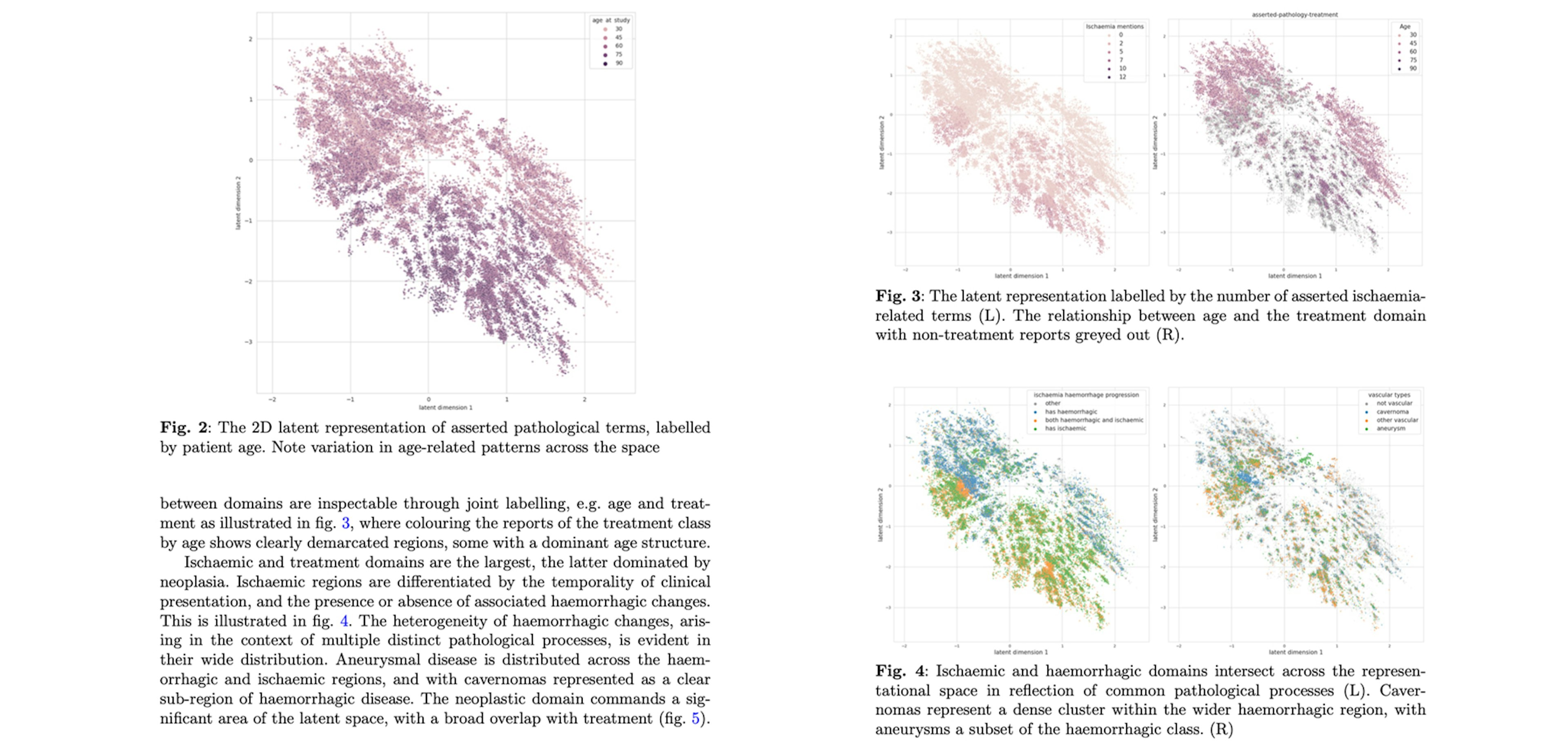
Neuradicon: operational representation learning of neuroimaging reportsWatkins, Gray, Julius, Mah, Pinaya, Wright, Jha, Engleitner, Cardoso, Ourselin, Rees, Jaeger, Nachev (2023)Labelled data for each task was produced using the Prodigy labelling tool. Each report was labelled in a paired-annotation manner. [...] We used the grammatical dependency parse produced by the spaCy parser as input and implemented the patterns using the spaCy dependency matcher.
Into the Single Cell Multiverse: an End-to-End Dataset for Procedural Knowledge Extraction in Biomedical TextsDannenfelser, Zhong, Zhang, Yao (2023), NeurIPSTissue, cell type, tool, and method were annotated using the Prodigy software tool developed by Explosion AI for easy tracking of token-level tags.
spaCy v3: Custom trainable relation extraction componentspaCy v3.0 features new transformer-based pipelines that get spaCy’s accuracy right up to the current state-of-the-art, and a new training config and workflow system to help you take projects from prototype to production. In this video, Sofie shows you how to apply all these new features when implementing a custom trainable component from scratch.
KAZU v1.5A biomedical NLP framework designed to handle production workloads, built by AstraZeneca and Korea University and using spaCy under the hood.
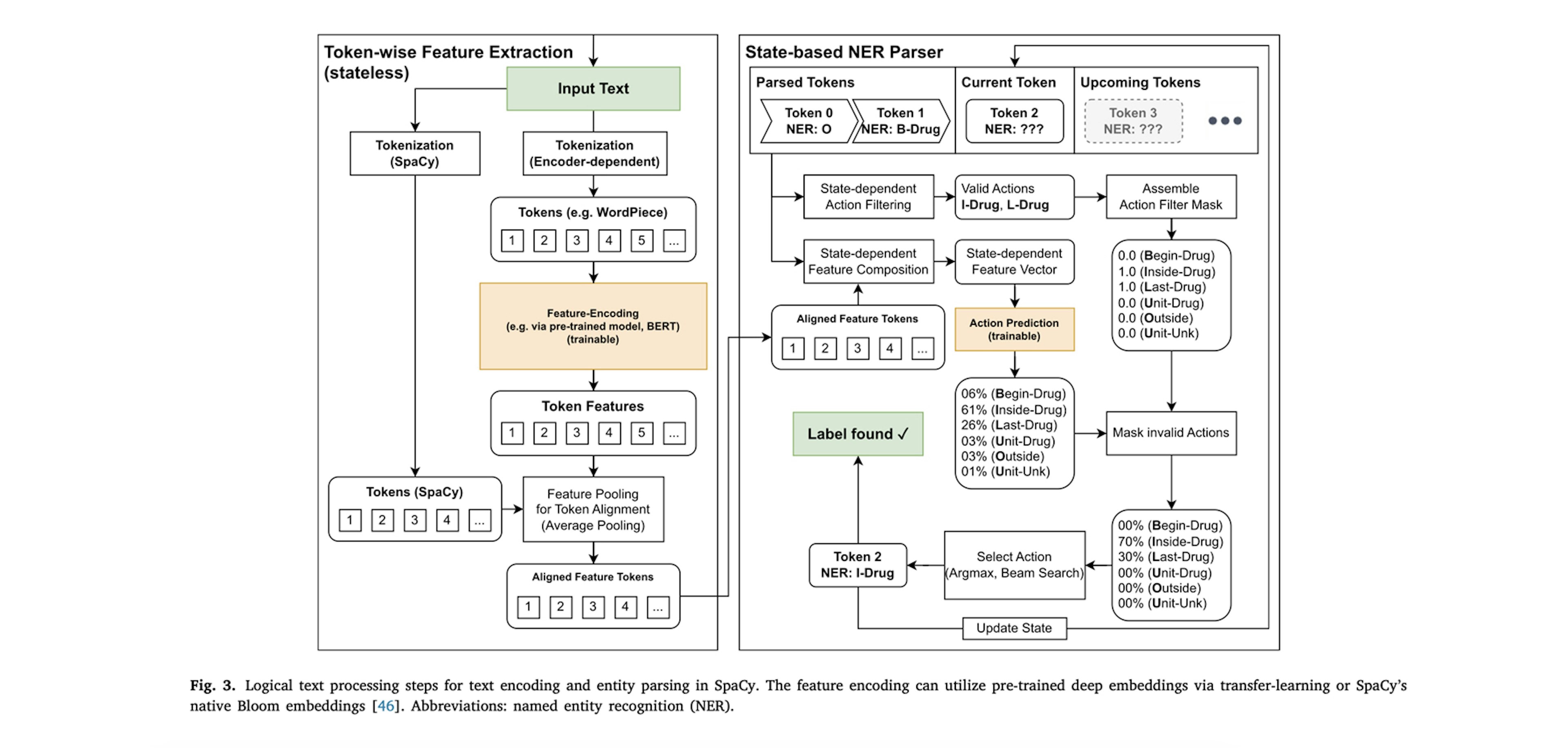
GERNERMED++: Semantic annotation in German medical NLP through transfer-learning, translation and word alignmentFrei, Frei-Stuber, Kramer (2023), Journal of Biomedical InformaticsThe training of our entity recognition model employs the entity recognition parser from the spaCy library which follows a transducer-based parsing approach with a BILOU scheme instead of a state-agnostic token tagging approach.
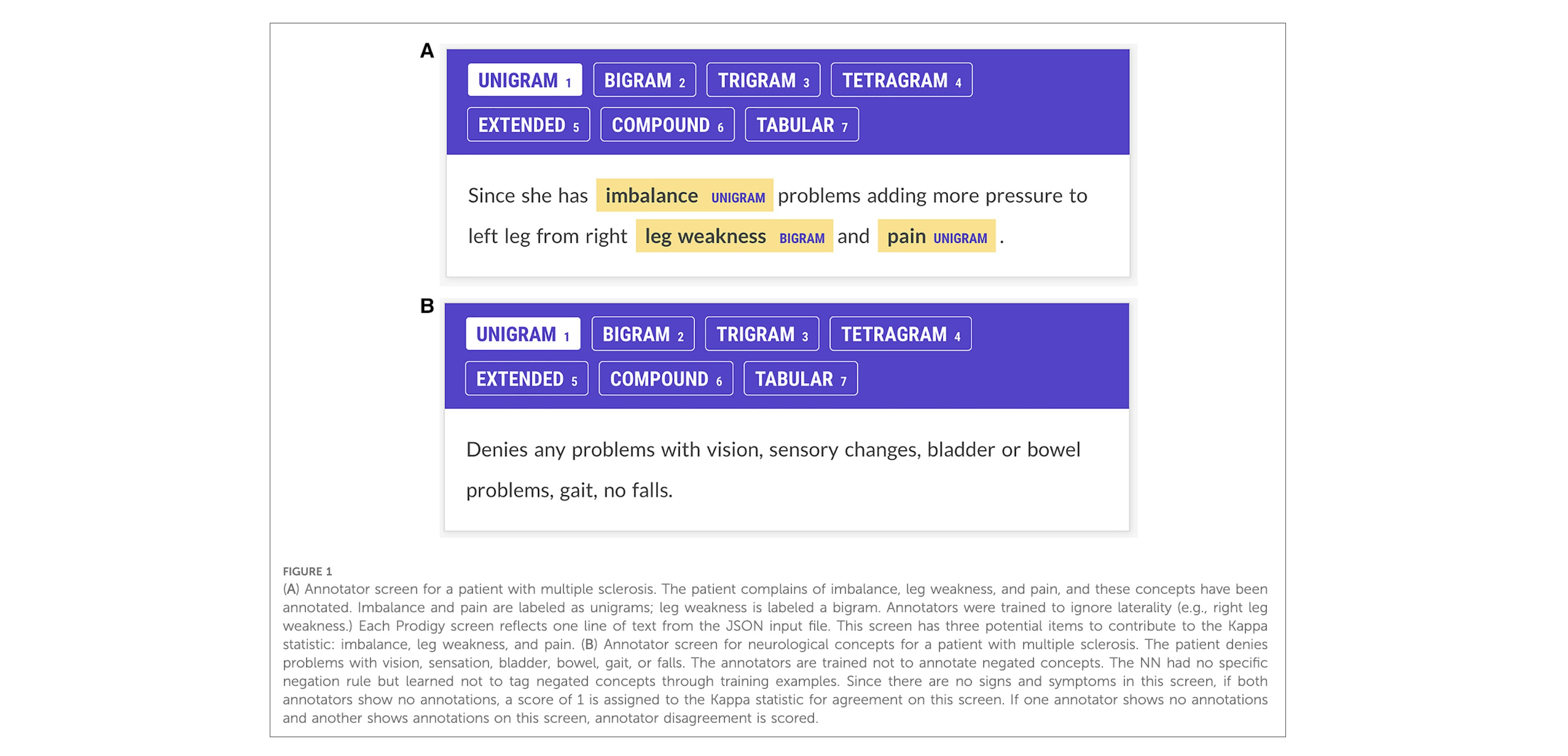
Inter-rater agreement for the annotation of neurologic signs and symptoms in electronic health recordsOommen, Howlett-Prieto, Carrithers, Hier (2023)Prodigy was used to annotate neurologic concepts in the EHR physician notes.
Speech acts in the Dutch COVID-19 Press ConferencesSchueler, Marx (2022), Language Resources and EvaluationWe used the annotation tool Prodigy. Prodigy provides a simple interface in which the annotator sees a sentence and selects the applicable speech acts. The use of Prodigy considerably sped up the annotation process, allowing the annotators to annotate around 200 sentences per hour.
Identifying Predictors of Suicide in Severe Mental Illness: A Feasibility Study of a Clinical Prediction RuleSenior, Burghart, Yu, Kormilitzin, Liu, Vaci, Nevado-Holgado, Pandit, Zlodre, Fazel (2020)The named entity recognition model was developed in two phases: 1) training with“gold-standard” annotations collected with GATE and 2) model fine-tuning with Prodigy—an active learning-based annotation tool.