Build-to-own AI: Agentic Development for HumansPyData PyCon Yerevan KeynoteInstead of using LLM APIs, we can take back control and build our own systems, bootstrapped by agents. In this talk, Ines shows you these new agentic workflows, what they mean for developer tools and why code and open-source are more important than ever.
Vibe NLP for Applied NLPPyCon DE & PyDataWhat if we could take learnings from AI-powered coding agents and apply them to solving real-world NLP problems? In this talk, I’ll show how we’ve built a powerful virtual NLP assistant to help developers create practical and modular solutions that are small, fast and fully data-private.
Style tips for less experienced developers coding with AIGetting good performance out of LLM coding is less about prompts or agents, and more about the code you steer the model towards. Matt shares some lessons software engineers have learned over the years about building bigger things.
Conquering PDFs: document understanding beyond plain textPyData LondonIn this talk, Ines presents a new and modular approach for building robust document understanding systems, using state-of-the-art models and the awesome Python ecosystem.
Conquering PDFs: document understanding beyond plain textPyCon DE & PyDataIn this talk, Ines presents a new and modular approach for building robust document understanding systems, using state-of-the-art models and the awesome Python ecosystem.
Prozessvisualisierung mit generativer KI im PraxistestiX Magazin / HeiseGerman article by Nils Durner on visualizing technical processes with Generative AI, featuring spaCy and Presidio for PII anonymization.
Distill Your LLMs and Surpass Their PerformanceInfoQ MagazineIn her presentation at InfoQ Dev Summit, Ines Montani provided the audience with practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components.
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillationInfoQ Dev SummitLLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, Ines shows some practical solutions for using the latest models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
Practical Tips for Bootstrapping Information Extraction PipelinesDataHack SummitThis talk presents approaches for bootstrapping NLP pipelines and retrieval via information extraction, including tips for training, modelling and data annotation.
How S&P Global is making markets more transparent with NLP, spaCy and ProdigyA case study on S&P Global’s efficient information extraction pipelines for real-time commodities trading insights in a high-security environment.
Towards Structured Data: LLMs from Prototype to ProductionU.S. Census Bureau: Center for Optimization and Data Science SeminarThis talk presents pragmatic and practical approaches for how to use LLMs beyond just chat bots, how to ship more successful NLP projects from prototype to production and how to use the latest state-of-the-art models in real-world applications.
ZenML v0.58.0New out-of-the-box Prodigy integration in ZenML for LLMs and beyond, to make data development and annotation a core part of your MLOps lifecycle.
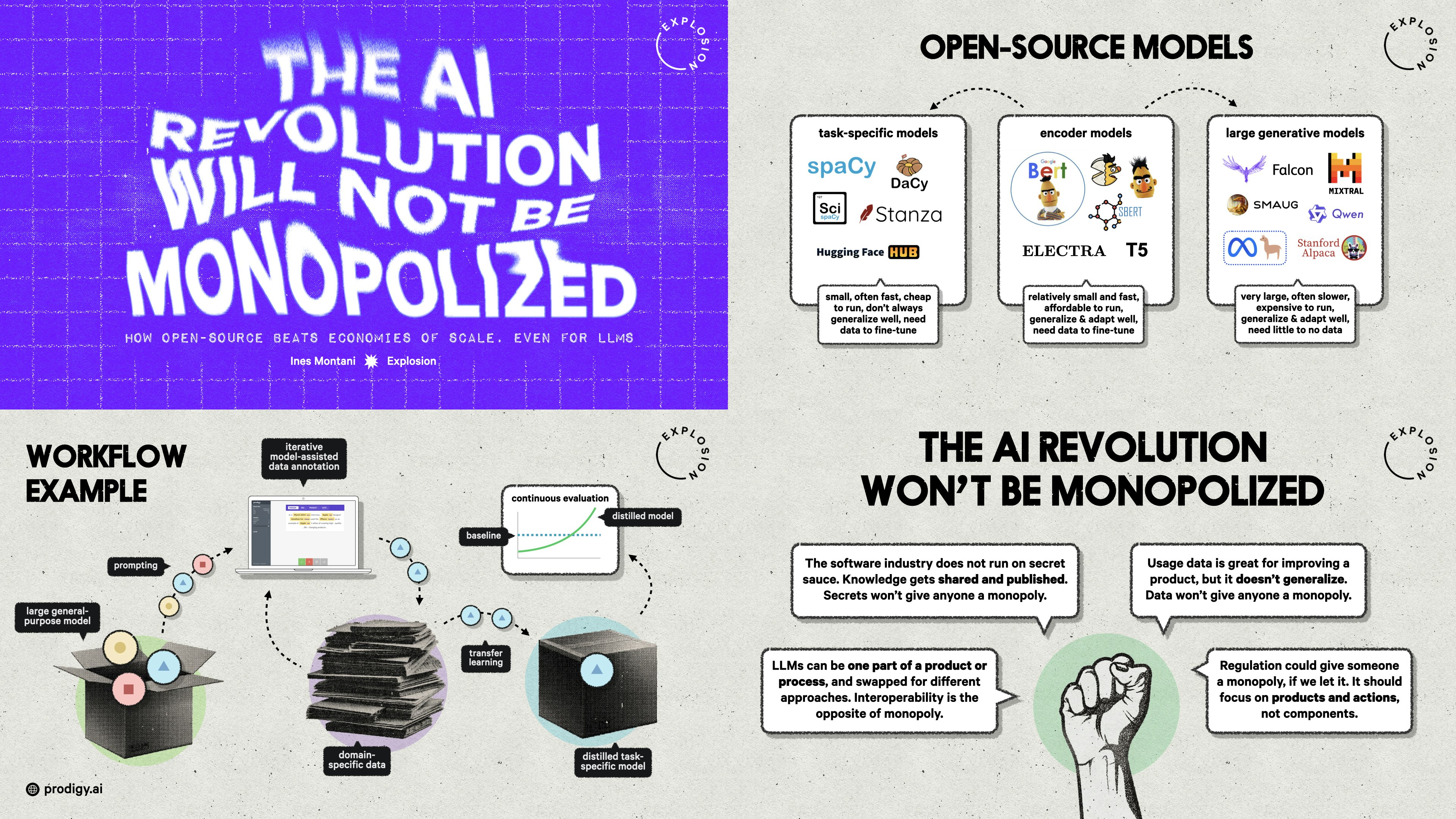
The AI Revolution Will Not Be Monopolized: Behind the scenesOpen Source ML MixerA more in-depth look at the concepts and ideas, academic literature, related experiments and preliminary results for distilled task-specific models.
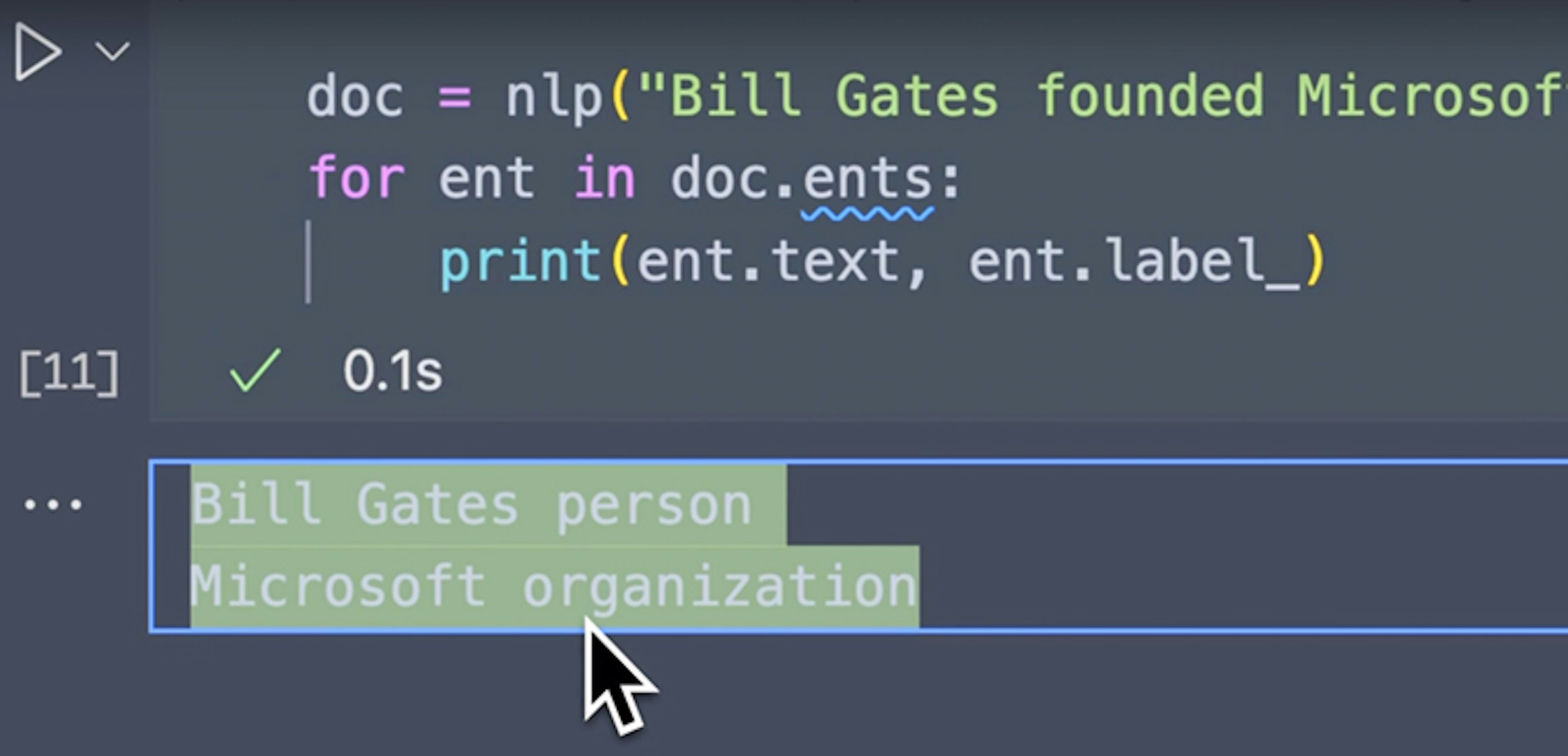
Zero-Shot NER with GliNER and spaCy Python Tutorials for Digital HumanitiesTutorial by WJB Mattingly on how to integrate the generalist GLiNER model for Named Entity Recognition with spaCy's versatile NLP environment.
Herding LLMs Towards Structured NLPGlobal AI ConferenceThis talk shows how we integrate LLMs into spaCy, leveraging its modular and customizable framework. This allows for cheaper, faster and more robust NLP - driven by cutting-edge LLMs, without compromising on having structured, validated data.
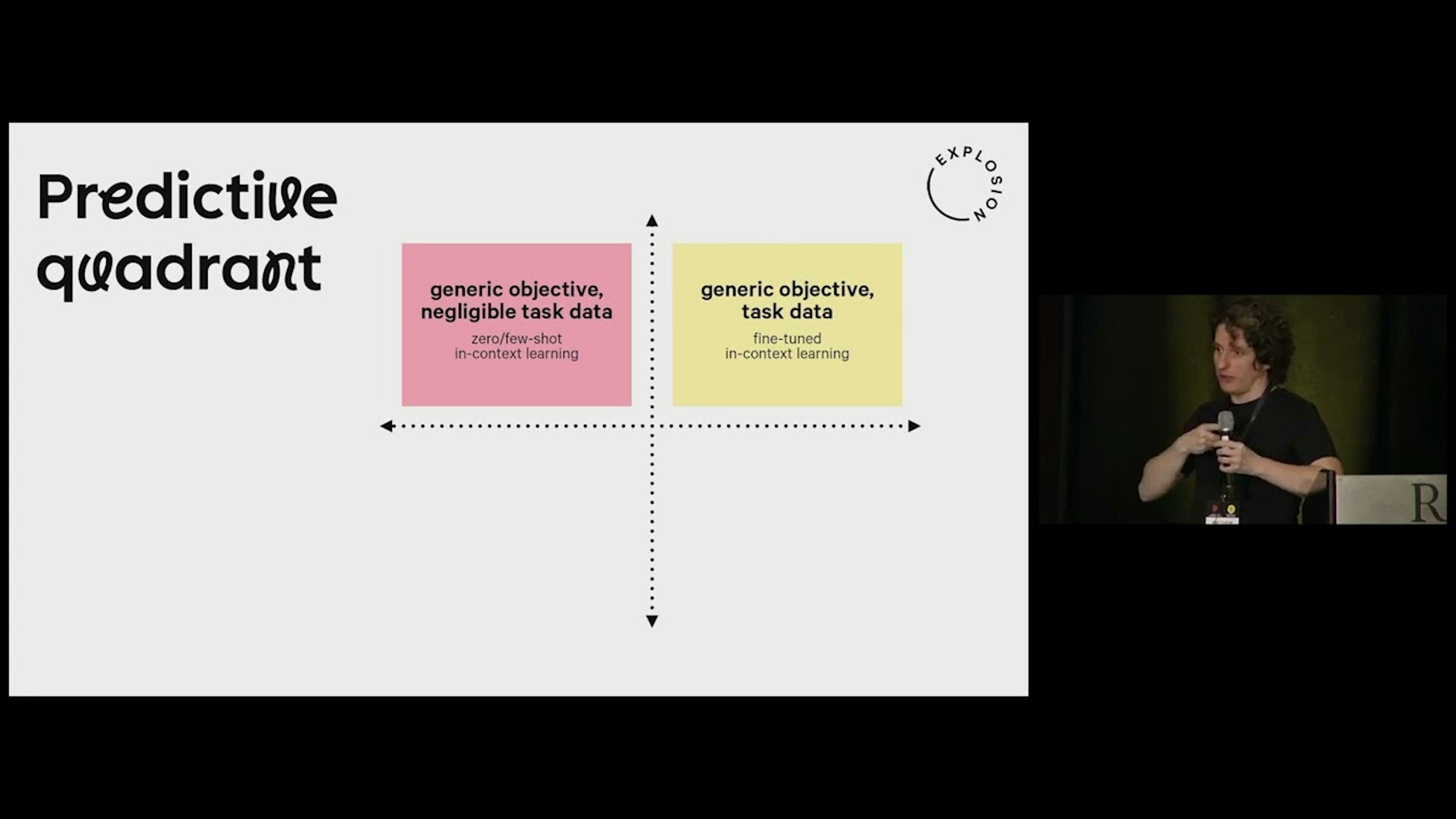
How many Labelled Examples do you need for a BERT-sized Model to Beat GPT-4 on Predictive Tasks?Generative AI SummitHow does in-context learning compare to supervised approaches on predictive tasks? How many labelled examples do you need on different problems before a BERT-sized model can beat GPT-4 in accuracy? The answer might surprise you: models with fewer than 1b parameters are actually very good at classic predictive NLP, while in-context learning struggles on many problem shapes.
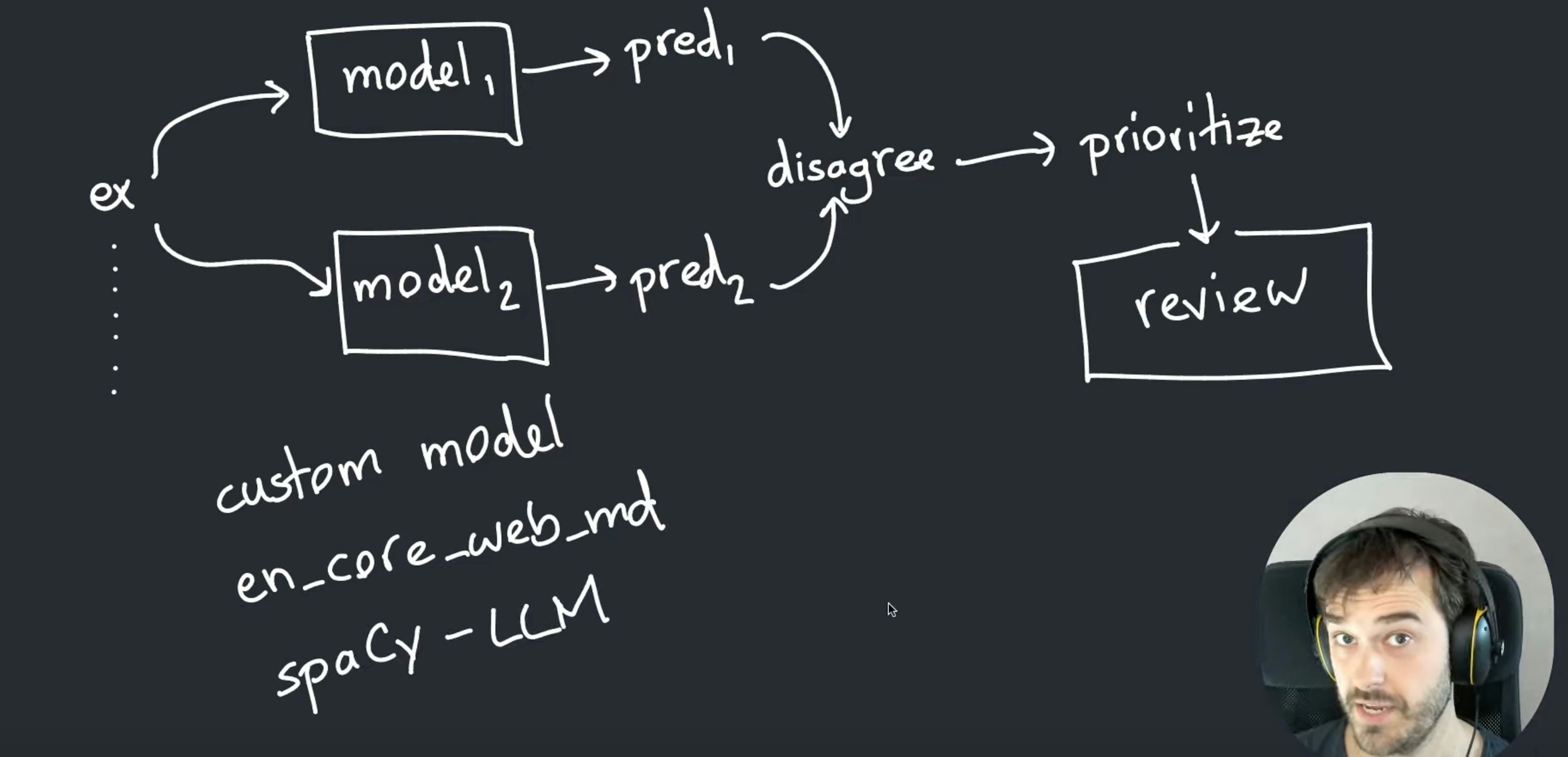
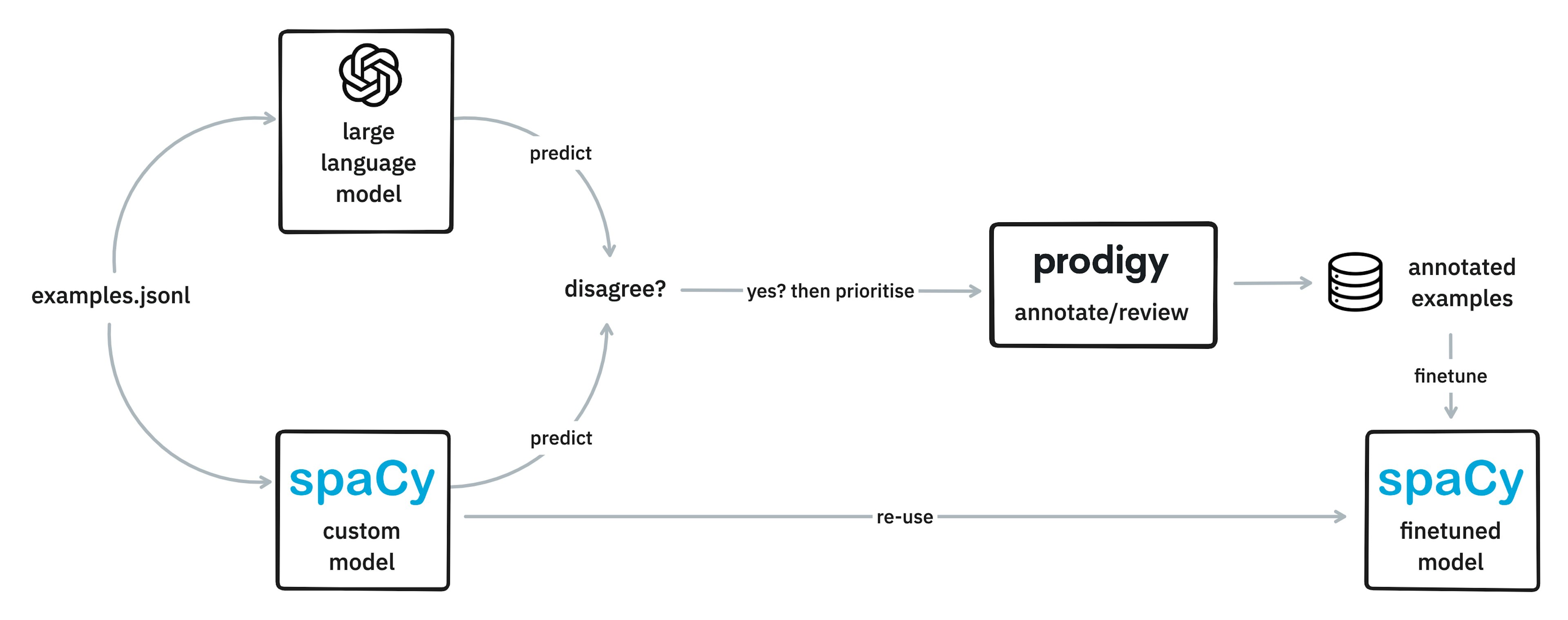
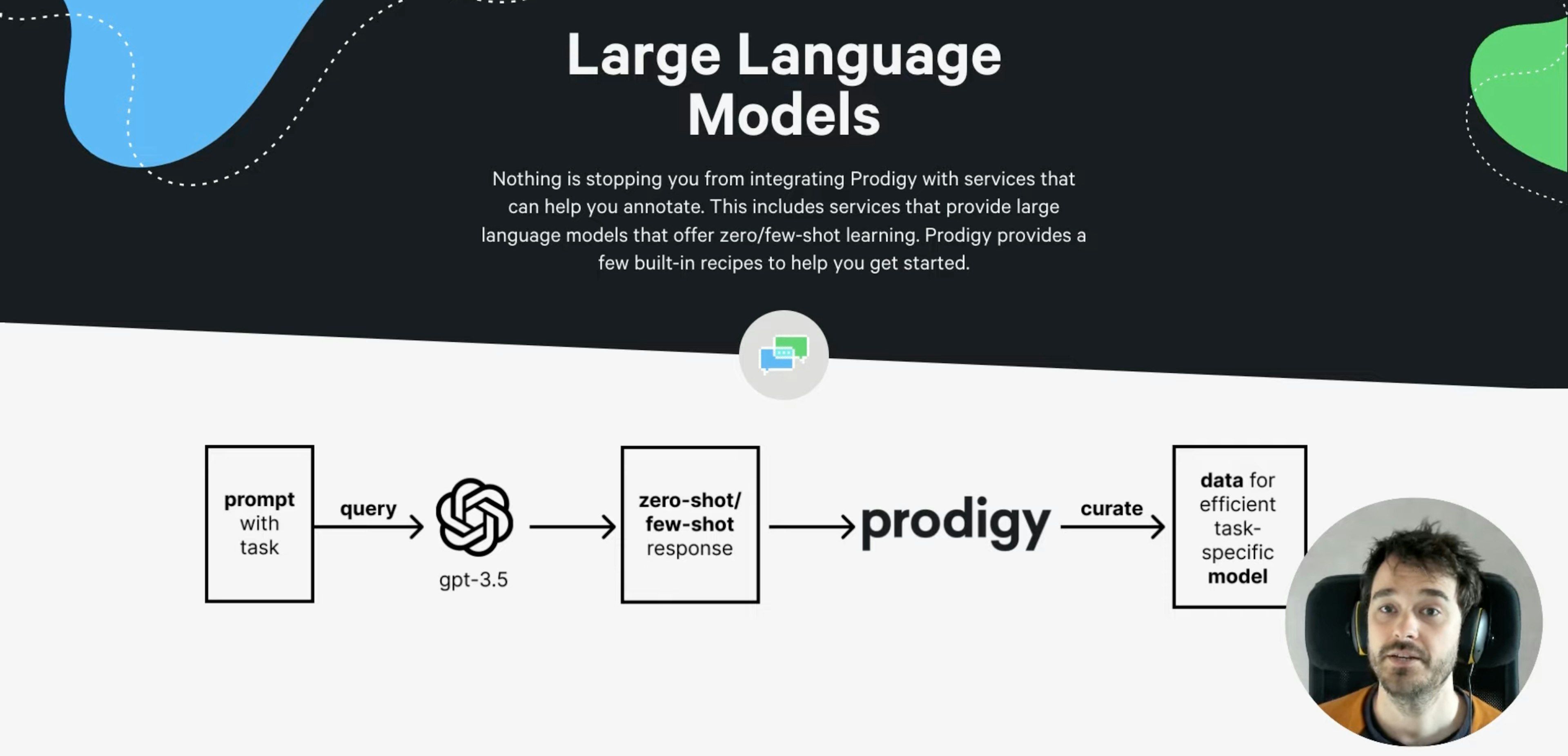
Models as annotators in ProdigyHow to use models and LLMs as annotators to find disagreements and prioritize examples to annotate first.
✨ prodigy v1.12.0Jul 5, 2023LLM-assisted workflows for annotation and prompt engineering, task routing for multi-annotator setups
Atomic NLPAn applied NLP methodology inspired by Atomic Design: building reliable language understanding systems out of small, composable components instead of one big model and a prompt.
A Century of Immigration Rhetoric in the UK ParliamentGennaro, Vissens, Thornewill von Essen, Ravalde, Egan, Dave, Dable, Facini (2026)With all annotated snippets, we trained two transformer-based classifiers, each using a spaCy pipeline consisting of a RoBERTa base transformer model and spaCy’s textcat (text categorisation) component.
Engineering a human-aligned LLM evaluation workflow with Prodigy and DSPyThis post demonstrates a human-in-the-loop workflow for developing and evaluating LLMs, using Prodigy and DSPy to create task-specific, human-aligned metrics that guide model optimization beyond generic evaluation measures.
Applied NLP in the Age of Generative AI: Future-Proof Strategies for Banking and FinanceECONDAT KeynoteA modern approach and mindset for building future-proof NLP pipelines in-house, focusing on use cases from banking, finance and economics.
How to advocate for modular NLP in the age of Generative AIWith all the hype around Generative AI, many are led to believe it’s the solution to everything. So how can you, as a developer, communicate the nuances and advocate for new and modular solutions that are better, easier and cheaper?
What the history of the web can teach us about the future of AIHow will AI development look in the future? There is a lot we can learn from another groundbreaking technology: the web. This blog post takes a look at what the history of the web can teach us, and what this means for developers, models, open source and regulation.
Serverless custom NLP with LLMs, Modal and ProdigyIn this blog post, we’ll show you how you can go from an idea and little data to a fully custom information extraction model using Prodigy and Modal, no infrastructure or GPU setup required.
Applied NLP in the Age of Generative AIPyData Amsterdam KeynoteIn this talk, Ines shares the most important lessons we’ve learned from solving real-world information extraction problems in industry, and shows you a new approach and mindset for designing robust and modular NLP pipelines in the age of Generative AI.
Exploring the AI nexus with the mind behind spaCyLeading With Data PodcastIn this episode, Matt takes you on a deep dive into the future of data and the challenges facing current Large Language Models (LLMs).
spaCy meets LLMs: Using Generative AI for Structured DataData+ML Community MeetupThis talk dives deeper into spaCy’s LLM integration, which provides a robust framework for extracting structured information from text, distilling large models into smaller components, and closing the gap between prototype and production.
Getting Started with NLP and spaCyTalkPython CourseThere is a lot of text data out there and maybe you're interested in getting structured data out of it. There are a lot of options out there and this course will introduce you to the field by focussing on spaCy while also exploring other tools.
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsQCon London
Constructing a knowledge base with spaCy and spacy-llmMantisNLP BlogThis blog post shows how to use spaCy and LLMs to extract entities and relationships from text and quickly tackle the complex problem of constructing a knowledge base graph from a corpus.
Prodigy in 2023: LLMs, task routers, QA and pluginsWe have made a ton of new updates in Prodigy this year with v1.12, v1.13, and v1.14 releases. So we decided to write a post about them.
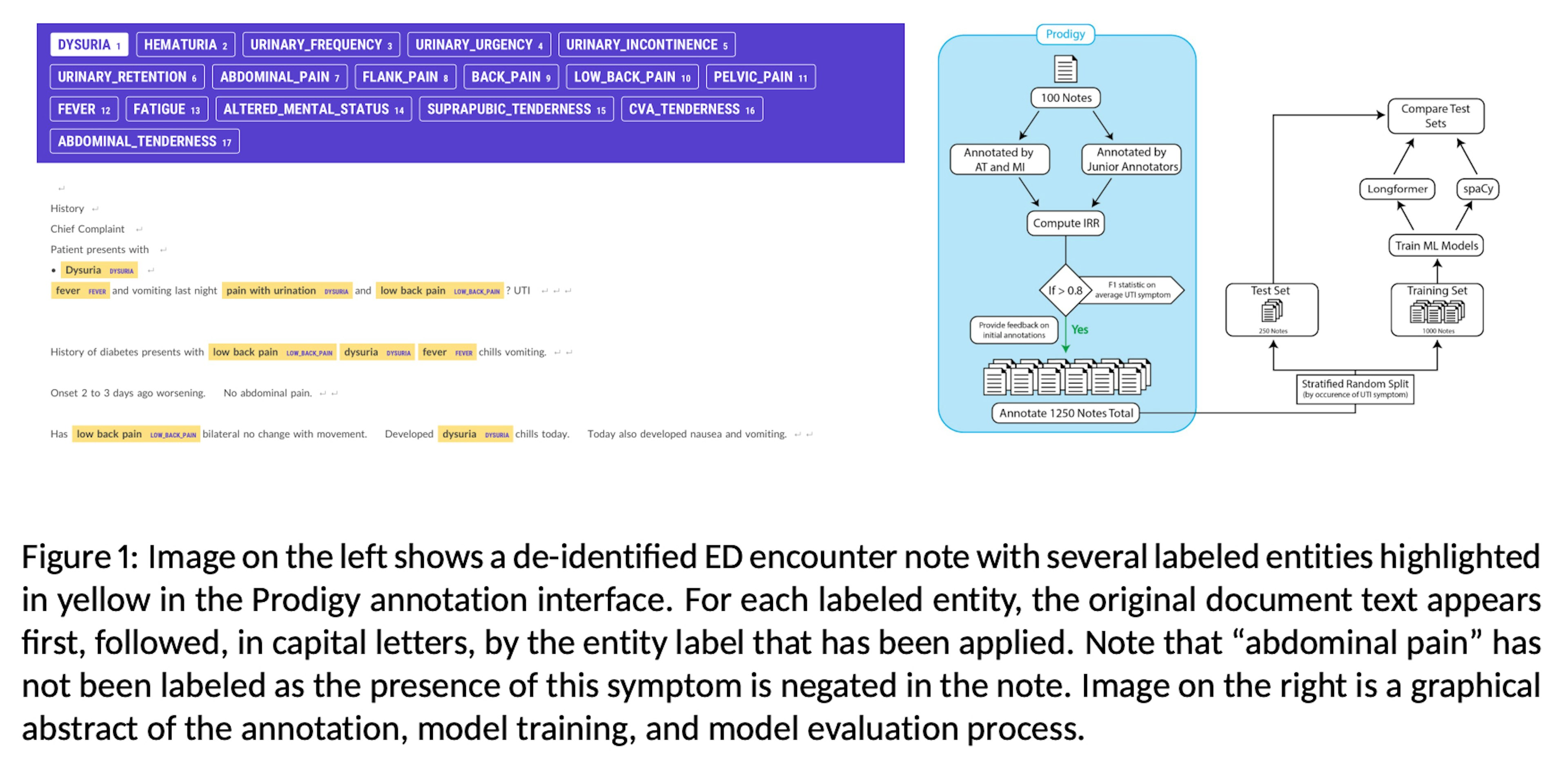
Identifying Signs and Symptoms of Urinary Tract Infection from Emergency Department Clinical Notes Using Large Language ModelsIscoe, Socrates, Gilson, Chi, Li, Huang, Kearns, Perkins, Khandjian, Taylor (2023)For annotation we employed Prodigy, a scriptable annotation tool designed to maximize efficiency, enabling data scientists to perform the annotation tasks themselves and facilitating rapid iterative development in natural language processing (NLP) projects.
How to Host Your Own API of Open Language Models For FreePowered by Explosion’s curated-transformers, FastAPI and ngrok.
🦙 spacy-llm v0.3.0Jun 14, 2023Cohere, Anthropic, OpenLLaMa, StableLM, logging, streamlit demo, lemmatization task
Taking back control of your AI developmentFeminist AI (PyData London)Short unconference presentation by Ines on the current focus of our work: empowering developers to build AI in-house again.
How rightwing rhetoric has risen sharply in the UK parliamentThe GuardianIn-depth analysis by the Guardian in collaboration with University College London, powered by Prodigy for semi-automated data annotation and spaCy for classification model training and prediction.
Building AI with AIPyCon Ireland KeynoteAI-powered coding assistants have transformed the way we build software, and AI itself. In this talk, Ines shows why we should use LLMs to build systems instead of as systems, and why code is more important than ever, not less.
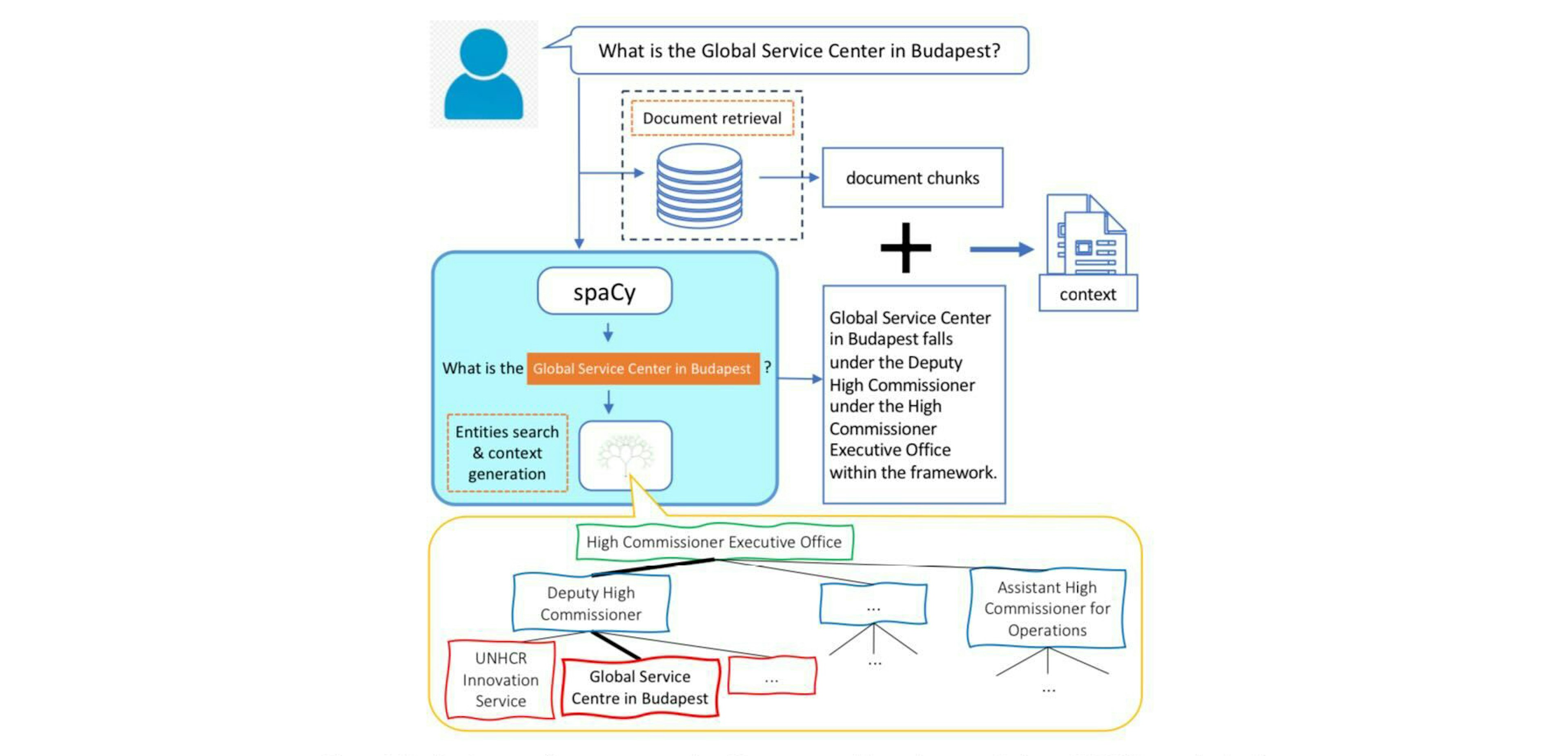
E^2GraphRAG: Streamlining Graph-based RAG for High Efficiency and EffectivenessZhao, Zhu, Guo, He, Li (2025)Instead of using LLMs for entity extraction, we employ the traditional NLP tool spaCy to extract entities, and use their co-occurrence in a chunk as relations.
How Love Without Sound helps the music industry recover millions in revenue for artists with NLP, spaCy and ProdigyA case study on Love Without Sound’s innovative AI-powered tools for the music industry and law firms specializing in royalty negotiations.
What the history of the web can teach us about the future of AIPyCon+Web KeynoteIn this talk, Ines takes a look at what the history of the web can teach us about the future of AI, and what this means for developers, models, open source and regulation.
Combining the Best of Two Worlds: From TF-IDF to Llama LLMOpen Source Summit EuropeTalk by William Arias, Staff Developer Advocate at GitLab, on combining traditional NLP techniques and LLMs to solve hallucination issues and create robust spaCy applications.
The AI Revolution Will Not Be MonopolizedInfoQOpen-source initiatives are pivotal in democratizing AI technology, offering transparent, extensible tools that empower users. Daniel Dominguez summarizes the key takeaways from Ines’ recent talk for InfoQ.
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillationPyData LondonLLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, Ines shows some practical solutions for using the latest models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
The AI Revolution Won’t Be MonopolizedTalkPython PodcastThere hasn’t been a boom like the AI boom since the .com days. And it may look like a space destined to be controlled by a couple of tech giants. But Ines Montani thinks open source will play an important role in the future of AI.
Economies of Scale Can’t Monopolise the AI RevolutionInfoQ MagazineDuring her presentation at QCon London, Ines Montani stated that economies of scale are not enough to create monopolies in the AI space and that open-source techniques and models will allow everybody to keep up with the “Gen AI revolution”.
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsPyCon Lithuania KeynoteWith the latest advancements in NLP and LLMs, and big companies like OpenAI dominating the space, many people wonder: Are we heading further into a black box era with larger and larger models, obscured behind APIs controlled by big tech monopolies?
T-RAG: Lessons from the LLM TrenchesFatehkia, Lucas, Chawla (2024)An important application area is question answering over private enterprise documents where the main considerations are data security, which necessitates applications that can be deployed on-prem, [and] limited computational resources. [...] In addition to retrieving contextual documents, we use the spaCy library with custom rules to detect named entities from the organization.
State-of-the-Art Transformer Pipelines in spaCyaiGrunnIn this talk, we will show you how you can use transformer models (from pretrained models such as XLM-RoBERTa to large language models like Llama2) to create state-of-the-art annotation pipelines for text annotation tasks such as named entity recognition.
MP Interests Tracker: Utilising GenAI to uncover insights in the UK Register of Financial InterestJournalismAI BlogProject from teams at The Times and BBC using spacy-llm to make complex financial interests data more accessible.
Large Language Models: From Prototype to ProductionEuroPython KeynoteLarge Language Models (LLMs) have shown some impressive capabilities and their impact is the topic of the moment. In this talk, Ines presents visions for NLP in the age of LLMs and a pragmatic, practical approach for how to use Large Language Models to ship more successful NLP projects from prototype to production today.
Large Disagreement Modelling“In this blogpost I’d like to talk about large language models. There’s a bunch of hype, sure, but there’s also an opportunity to revisit one of my favourite machine learning techniques: disagreement.”
Show Us Your (Agent) SkillsPyMC Labs × Vanishing GradientsWhat are people at the top of the game building with AI agents and how are they doing it? In this episode, 6 developers are sharing their workflows.
The ultimate guide to optimizing annotation workflowsThis blog post collects tips and advice for how to build efficient human-in-the-loop data development workflows, break down business problems into actionable annotation steps and make the most of automation and model assistance.
Sovereign AI systems instead of black box solutionsit-dailyGerman article featuring Ines’ take on AI in industry, the role of open source, and using Generative AI to create systems.
Feminist AI LAN PartyPyCon DE & PyDataThree days of workshops, hacking, creating, publishing and connecting locally, featuring a data development workshop with Prodigy and a session on hacking LLMs.
Mastering spaCyDéborah Mesquita, Duygu Altinok (Packt Publishing, 2025)Build structured NLP solutions with custom components and models powered by LLMs. By end of the book you will be empowered to build robust NLP pipelines and integrate them with web applications to build end-to-end solutions.
From PDFs to AI-ready structured data: a deep diveThis blog post presents a new modular workflow for converting PDFs and similar documents to structured data and shows you how to build end-to-end document understanding and information extraction pipelines for industry use cases.
Applied NLP with LLMs: Beyond Black-Box MonolithsPyBerlinIn this talk, Ines shows some practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components.
The NLP and AI Revolution with the spaCy CreatorsVanishing GradientsIn this interview with Hugo Bowne-Anderson, we delve into the forefront of NLP and the future of AI development, covering topics like human-in-the-loop distillation, open-source AI and Explosion’s journey.
A practical guide to human-in-the-loop distillationThis blog post presents practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
Simply Simplify LanguageInteractive app by the Canton of Zurich, Switzerland, using LLMs and spaCy to analyze and simplify institutional communication and make bureaucratic German more inclusive.
KI – Die künstlerische Intelligenz?Immergut Festival (German)Panelists are discussing the latest developments in Generative AI, hype vs. reality and what those new technologies mean for people, businesses, art, creativity and the music industry.
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsPyCon DE & PyData BerlinWith the latest advancements in NLP and LLMs, and big companies like OpenAI dominating the space, many people wonder: Are we heading further into a black box era with larger and larger models, obscured behind APIs controlled by big tech monopolies?
Designing for tomorrow’s programming workflowsPyCon LithuaniaModern editors and AI-powered tools like GitHub Copilot and ChatGPT are changing how people program and are transforming our workflows and developer productivity. But what does this mean for how we should be writing and designing our APIs and libraries?
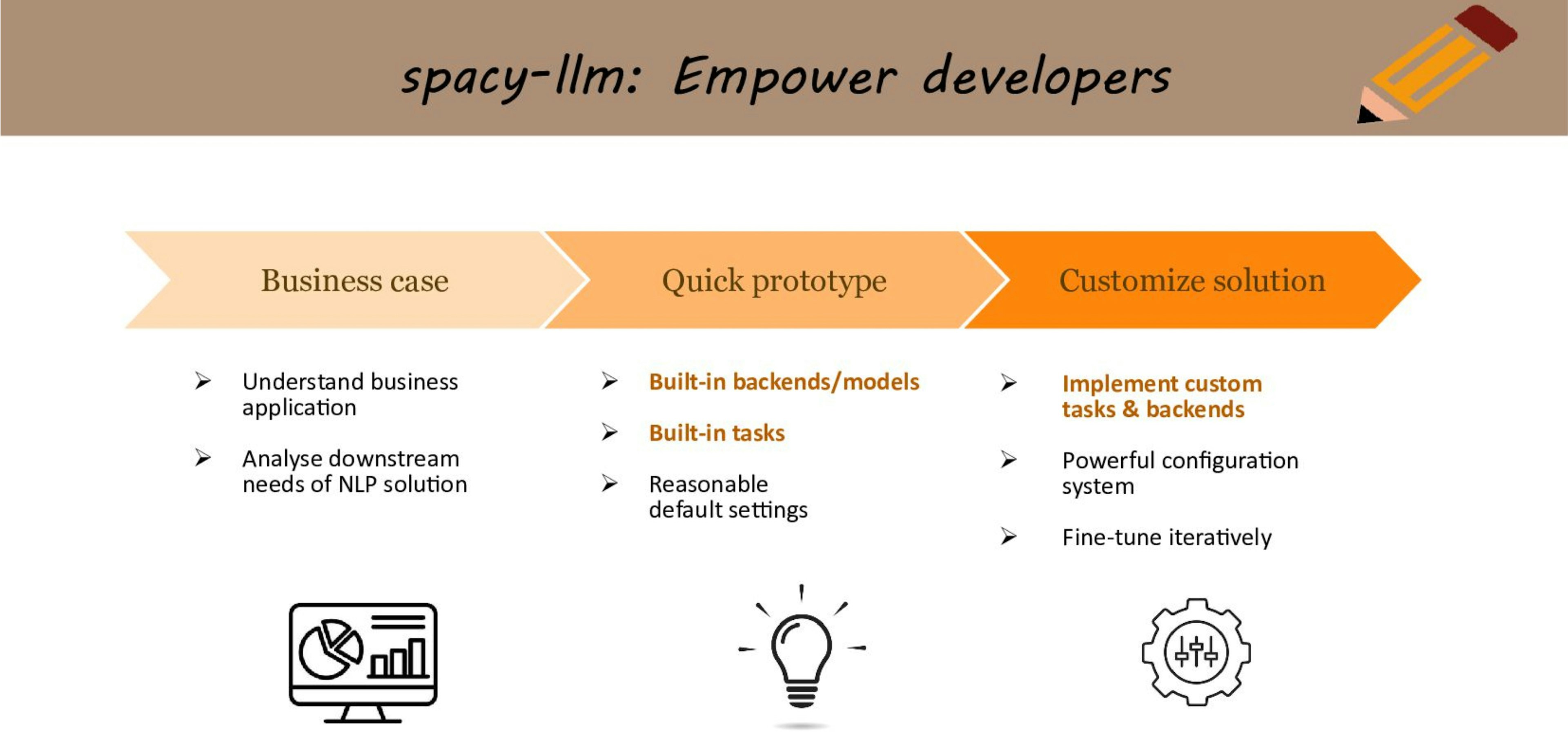
spacy-llm: From quick prototyping with LLMs to more reliable and efficient NLP solutionsAstraZeneca NLP Community of PracticeLLMs are paving the way for fast prototyping of NLP applications. Here, Sofie showcases how to build a structured NLP pipeline to mine clinical trials, using spaCy and spacy-llm. Moving beyond a fast prototype, she offers pragmatic solutions to make the pipeline more reliable and cost efficient.
Half hour of labeling power: Can we beat GPT?PyData NYCLarge Language Models (LLMs) offer a lot of value for modern NLP and can typically achieve surprisingly good accuracy on predictive NLP tasks. But can we do even better than that? In this workshop we show how to use LLMs at development time to create high-quality datasets and train specific, smaller, private and more accurate models for your business problems.
Panel: Large Language ModelsBig PyData BBQwith Ines, Alejandro Saucedo (Zalando, Institute for Ethical AI & ML), Alina Lehnhard (Cerence), Michael Gerz (Heidelberg University), Alexander CS Hendorf (Königsweg)
🦙 spacy-llm v0.5.0Sep 8, 2023Improved user API and novel Chain-of-Thought prompting for more accurate NER
Against LLM maximalismLLMs are not a direct solution to most of the NLP use-cases companies have been working on. They are extremely useful, but if you want to deliver reliable software you can improve over time, you can't just write a prompt and call it a day. Once you're past prototyping and want to deliver the best system you can, supervised learning will often give you better efficiency, accuracy and reliability.