
We’ve talked to Christopher Ewen, Senior Product Manager at S&P Global Commodity Insights, about how their small team built and shipped impressively efficient information extraction pipelines for real-time commodities trading insights in a high-security environment, and how they were able to achieve a 10× speed-up of their data collection and annotation workflows to build a new dataset.
S&P Global are one of the leading providers of data and insights for global energy and commodities, covering raw materials like metals, agricultural products and chemicals as well as the energy transition. Publishing benchmark prices in these markets lets producers and consumers lock in prices and hedge against uncertainty. Transparency is key to allowing these markets to operate efficiently and provides clarity and guidance in navigating the volatile commodity landscape, enabling fair trade, effective risk management, and informed decision-making.
Processing structured “heards” in real time
“Heards” are trading activities market reporters receive daily via phone, email and instant messenger – essentially, information that was heard about commodities trades across many different markets like agriculture, coal, electric power, natural gas or oil, happening and published in real time. Relevant information collected that meets the methodological standards is published through real-time information services as “heards” in order to test information with the market. The information includes up to 32 different attributes, like price, participants or location, that are published as both structured and unstructured data. Customers include banks, financial institutions and trading houses at more than 15,000 public and private organizations in over 150 countries, who access the data via S&P’s Platts Connect platform, the underlying API or third-party vendors.

A key goal of Chris’ team is to make the commodities markets as transparent as possible and publish information and benchmark prices “immediately as heard”. Extracting the information from these heards automatically provides even more transparency while maintaining the real-time nature of the information.
In addition to the live feed, having structured historical data is also incredibly valuable, both internally and for customers. S&P Global process around 8,000 new heards per day, with an archive of over 13 million data points since 2017. While it would previously take an analyst hours to find answers in the unstructured data and wrangling Excel spreadsheets, the structured feed now lets them find this information in seconds.
Heards are collected as very concise notes using an extremely specific structure with extremely specific terminology. This presents several challenges, but also opportunities for a custom NLP pipeline: some attributes can be extracted reliably via rules, whereas others require a statistical language model.

To build automated production pipelines for processing heards in real time, Chris and his team at S&P Global use custom spaCy pipelines, fine-tuned for each market, and Prodigy for efficient annotation, data collection, quality control and evaluation.
Maximum performance for maximum transparency
For their production stack, high inference speed and latency is crucial: the incoming data entries need to be processed and validated in real time and meet the 15ms SLA per heard to provide maximum market transparency to customers. Using spaCy’s component implementations, their fine-tuned language models run at around 15,000 words per second at accuracies of up to 99% and model artifacts of 6 MB, making it easy to develop and deploy the pipelines in-house.
Having a small model makes it much easier to achieve our strict inference SLAs. The system is much less operationally complex because the model is so efficient. Less complexity means less that can go wrong.
— Christopher Ewen, Senior Product Manager
Keeping the data and models entirely private and in-house is also critical: heards contain information that can significantly affect and move markets and any pre-publication information is highly segregated, even within the office. Customers trust the commodities team to publish the data as soon as it comes in and before it’s seen by anybody else.
Naturally, the structured data needs to be highly accurate, which requires domain experts in the loop at all times. The team realized quickly that teaching people to annotate training and evaluation data would take too long and not pay off, so initially, Product Manager Chris was the only expert available to create data. Despite this challenge, the team was able to take advantage of Prodigy’s efficient design and interfaces to create a workflow requiring only 30 minutes of work per attribute per market, or 15 hours per market in total, and successfully ship their first pipelines to production. The reduced time needed by the market specialists allows them to focus on their job of communicating with market participants, assessing prices and publishing news.
Given the very specific structure and terminology used in heards, the project requires tooling that’s highly customizable: the pipeline needs to be able to define its own rules for tokenization to handle the unusual punctuation and combine the predictive named entity recognition model with rules to improve accuracy. The data development process needs to include the model and rules in the loop, and automate annotation wherever possible to allow experts to move through the data quickly, without requiring too much fine-grained clicking.
Prodigy lets us automate as much as possible and focus on valuable decisions and less clicking. I can stream in the model’s predictions and rule-based matches and make corrections in a single click.
— Christopher Ewen, Senior Product Manager
The powerful end-to-end workflow
The end-to-end workflow the team developed starts with defining a taxonomy of attributes per market, distinguishing between attributes whose value can be enumerated and thus handled with rules, and attributes that require predictions by a named entity recognition model. In a first step, around 100 examples are annotated manually, enough to fine-tune an intermediate model, which is then improved further and used to pre-annotate attributes. The data is then combined to train and evaluate a final market-specific pipeline.

The workflow for creating training and evaluation data originally consisted of streaming in the heards for a given market and labelling the respective spans with the available up to 32 attributes from the taxonomy. This seemed reasonable at first, because it meant that a single heard had to only be seen, annotated and corrected once. However, the cognitive load from having to consider this many attributes at the same time made the process incredibly tedious and too slow to be practical.

So the team tried something else: focusing on a single label at a time and making multiple passes over the heards data, once per attribute. Although this sounded like more work at first, it drastically sped up annotation time by over 10×. Focusing on a single concept, Chris was able to move through the data in mere seconds per example, quickly labelling an initial set of 100 examples that were sufficient to train a first decent-enough pipeline that could then be used to further speed up annotation by pre-annotating the remaining data. Now data could be created even faster and mostly required pressing A to accept correct annotations and making the occasional edit.
Best practices for optimizing annotation workflows
For more tips and advice for how to build efficient human-in-the-loop data development workflows, break down business problems into actionable annotation steps and make the most of automation and model assistance, see our blog post on optimizing annotation workflows.
Human-in-the-loop distillation with LLMs
One of the biggest bottlenecks for expanding to more markets is still the creation of the initial ~100 examples of ground truth needed to train a temporary pipeline that can then help with automation. This requires significant domain expertise and time, so the team is using Prodigy’s built-in LLM recipes to let gpt-35-turbo-16k, available via their Azure deployment, take over the pre-annotation, which then only needs to be reviewed and corrected.
This also means that the LLM is only used during development time, which is not only more cost-effective, but also ensures no real-world runtime data has to be sent to external model APIs or slow generative models. In production, the system only uses the distilled task-specific pipeline that’s more accurate, faster and fully private.
Working with spaCy means we have flexibility to adapt to new situations quickly and constantly iterate while using state-of-the-art technology and without being locked in to one specific way of doing things.
— Christopher Ewen, Senior Product Manager
config.cfg (excerpt)
Although general-purpose LLMs struggle with the specifics of the heard structure and terminology, the label_definitions available for spaCy’s LLM-powered named entity recognition component help bridge the gap and provide better instructions and results.
Human-in-the-loop distillation
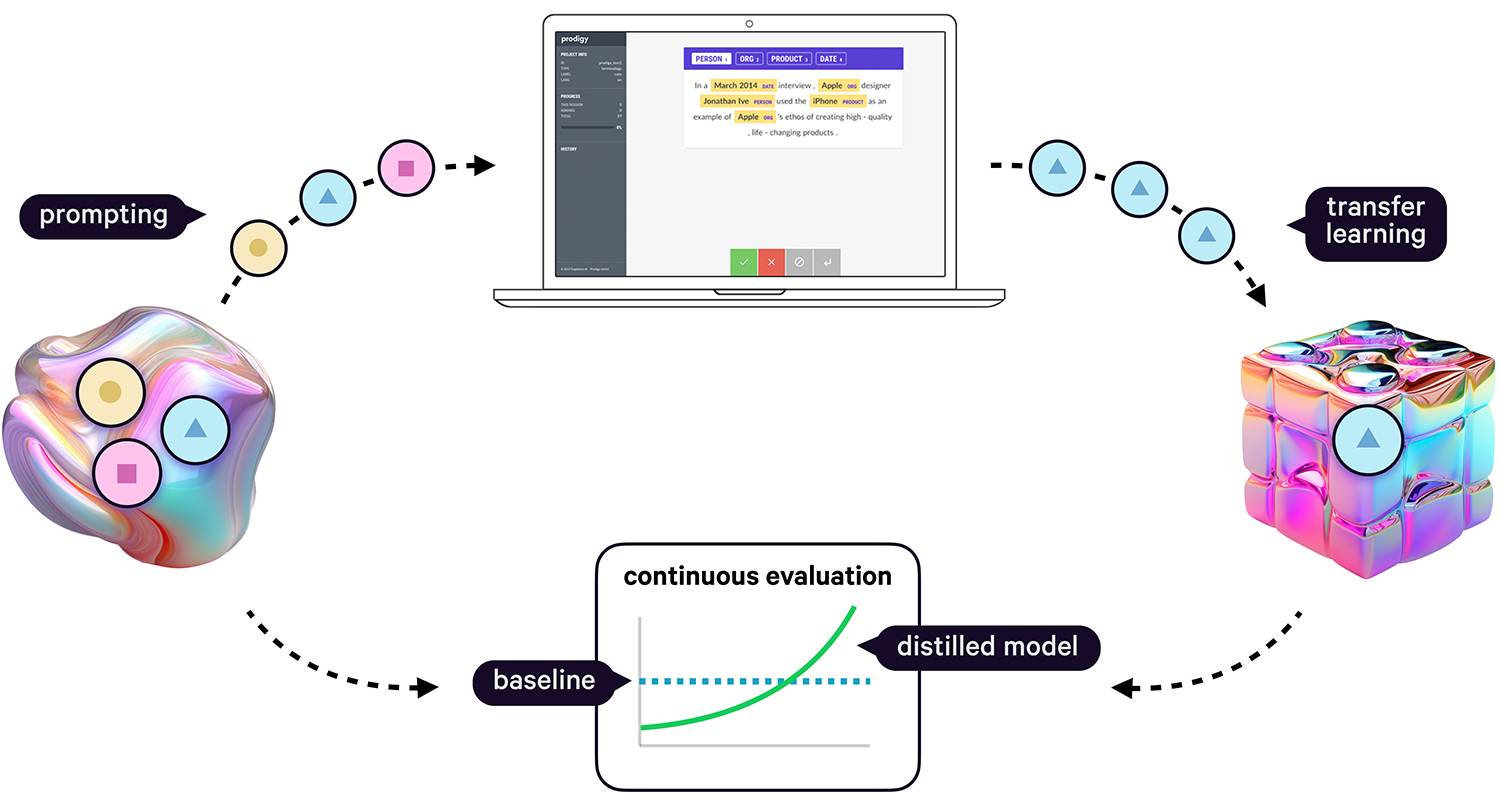
LLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. This blog post shows some practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
Project management and reproducible experiments
To manage the project work and data assets, as well as their custom workflows and training pipelines, the commodities team uses spaCy’s projects system, which helps with orchestrating end-to-end NLP workflows, provides a single place for commands, data and code, and allows reproducible and version-controlled experiments that can be shared across the whole team.

The project integrates with Prodigy and includes both data annotation and conversion workflows, as well as training commands and custom data analysis tooling.
Results and evaluation
Using the outlined workflow, the team was able to develop robust, highly accurate, small and very fast pipelines that can run entirely in-house. As new data comes in, the models can be improved iteratively, requiring only minimal time and effort spent by domain experts on annotation and evaluation.

| Global Carbon Credits | Americas Crude Oil | Asia Steel Rebar | |
|---|---|---|---|
| Accuracy (F-score) | 0.95 | 0.96 | 0.99 |
| Speed (words/second) | 15,730 | 13,908 | 16,015 |
| Model Size | 6 MB | 6 MB | 6 MB |
| Training Examples | 1,598 | 1,695 | 1,368 |
| Evaluation Examples | 211 | 200 | 345 |
| Data Development Time | ~15h | ~15h | ~15h |
The project is a great example of the strengths of supervised learning for highly valuable and very domain-specific tasks. By taking advantage of transfer learning, the pipelines require relatively few labelled examples and little annotation effort to achieve both high accuracy and lightning-fast inference speed at low training, runtime and development cost.
In-context learning vs. supervised learning for predictive tasks
How many labelled examples do you need on different problems before a BERT-sized model can beat GPT-4 in accuracy? The answer might surprise you: models with fewer than 1b parameters are actually very good at classic predictive NLP, while in-context learning struggles on many problem shapes. To learn more about the approach, check out this talk by Matt.
Future plans
Going forward, there’s no shortage of plans to further improve the data collection process, ship pipelines for more markets to production and make commodities markets more transparent in the process.
For selected attributes, the pipelines rely on rules, which makes their performance in production very easy to understand and analyze. But rules do have a weakness: data drift. If the data changes and the heards start to include new things not covered by the rules, how will the team know? One solution is to train an additional model on the data, and use it offline for analysis. If the model predicts an entity but the rules don’t capture it, it can be flagged for manual review.
Some markets only have a limited number of heards available, or imbalanced data with few examples for rare attributes, making it difficult to even generate enough examples for an initial model or useful prompt. To work around this, the team is experimenting with creating synthetic data with LLMs and rules. Synthetic data won’t be available to the end user, but can balance the training set and helps the model recognize rarer heard attributes and possible values, which are possible but have not yet been heard in practice.
Finally, breaking the annotation decisions down into binary questions can further help with getting more domain experts involved by focusing on the minimum and most valuable information required to collect initial ground trouth. Binary decisions can often be made in a second, one of the most efficient ways to use the human expert’s time.
Resources
- Prodigy: A modern annotation tool for NLP and machine learning
- A practical guide to human-in-the-loop distillation: How to distill LLMs into smaller, faster, private and more accurate components
- Large Language Models in spaCy: Use LLM-powered components for a variety of NLP tasks in your pipeline
- Large Language Models in Prodigy: Use LLMs to automate annotation and data creation for distilled task-specific models
- Named Entity Recognition with Prodigy: Documentation and workflows
- Combining models and rules: Improve accuracy with custom business logic
- The ultimate guide to optimizing annotation workflows: How to build efficient human-in-the-loop data development workflows
- S&P Global Commodities Insights: More details on the commodities data products
- Case Studies: Our other real-world case studies from industry



