Mastering spaCyDéborah Mesquita, Duygu Altinok (Packt Publishing, 2025)Build structured NLP solutions with custom components and models powered by LLMs. By end of the book you will be empowered to build robust NLP pipelines and integrate them with web applications to build end-to-end solutions.
Getting Started with NLP and spaCyTalkPython CourseThere is a lot of text data out there and maybe you're interested in getting structured data out of it. There are a lot of options out there and this course will introduce you to the field by focussing on spaCy while also exploring other tools.
Microsoft Presidio v2.2.352Context aware, pluggable and customizable PII de-identification and anonymization service for text and images, featuring a spaCy back-end.
Introducing spaCy v3.5spaCy v3.5 introduces new CLI commands, fuzzy matching, improvements for entity linking and more.
Introducing spaCy v3.0spaCy v3.0 is a huge release! It features new transformer-based pipelines that get spaCy's accuracy right up to the current state-of-the-art, and a new workflow system to help you take projects from prototype to production. It's much easier to configure and train your pipeline, and there are lots of new and improved integrations with the rest of the NLP ecosystem.
Introducing spaCy v2.1Version 2.1 of the spaCy Natural Language Processing library includes a huge number of features, improvements and bug fixes. In this post, we highlight some of the things we're especially pleased with, and explain some of the most challenging parts of preparing this big release.
Combining the Best of Two Worlds: From TF-IDF to Llama LLMOpen Source Summit EuropeTalk by William Arias, Staff Developer Advocate at GitLab, on combining traditional NLP techniques and LLMs to solve hallucination issues and create robust spaCy applications.
spaCyEx v0.0.2Extension for spaCy’s powerful, linguistically-aware pattern matching that introduces a RegEx-like syntax.
scispacy v0.5.3A Python package containing spaCy models for processing biomedical, scientific or clinical text, developed by AI2.
Introducing spaCy v2.2Version 2.2 of the spaCy Natural Language Processing library is leaner, cleaner and even more user-friendly. In addition to new model packages and features for training, evaluation and serialization, we've made lots of bug fixes, improved debugging and error handling, and greatly reduced the size of the library on disk.
Introducing custom pipelines and extensions for spaCy v2.0As the release candidate for spaCy v2.0 gets closer, we've been excited to implement some of the last outstanding features. One of the best improvements is a new system for adding pipeline components and registering extensions to the Doc, Span and Token objects. In this post, we'll introduce you to the new functionality, and finish with an example extension package, spacymoji.
How GitLab uses spaCy to analyze support tickets and empower their communityA case study on GitLab’s large-scale NLP pipelines for extracting actionable insights from support tickets and usage questions.
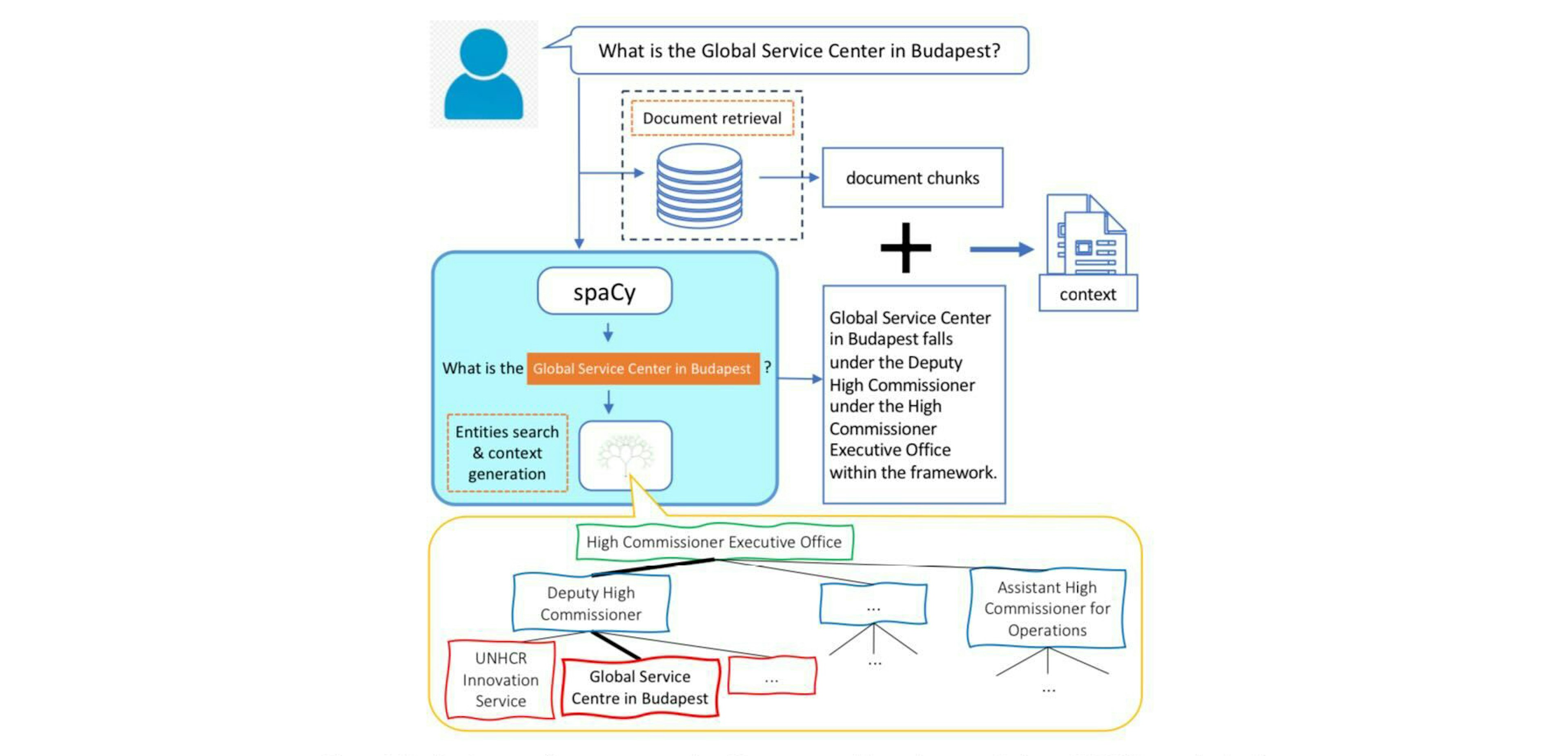
T-RAG: Lessons from the LLM TrenchesFatehkia, Lucas, Chawla (2024)An important application area is question answering over private enterprise documents where the main considerations are data security, which necessitates applications that can be deployed on-prem, [and] limited computational resources. [...] In addition to retrieving contextual documents, we use the spaCy library with custom rules to detect named entities from the organization.
Efficient Information Extraction From Text With spaCyJetBrains PyCharmThis webinar takes you through building a spaCy project that uses a named entity recognition (NER) model to extract entities of interest from restaurant reviews, like prices, opening hours and ratings.
Introducing Holmes 4.0A few weeks ago we released version 4.0 of Holmes, which we are now able to offer under a permissive MIT license. Holmes is a library in the spaCy Universe that runs on top of spaCy and enables information extraction and intelligent search, currently for English and German. Holmes goes beyond simple matching algorithms and allows you to look for a specified idea or ideas in a corpus of documents.
How S&P Global is making markets more transparent with NLP, spaCy and ProdigyA case study on S&P Global’s efficient information extraction pipelines for real-time commodities trading insights in a high-security environment.
KAZU v1.5A biomedical NLP framework designed to handle production workloads, built by AstraZeneca and Korea University and using spaCy under the hood.
Rulers, NER, and data iterationAbout the power of Rules + ML and the importance of iteration on your pipeline and your data.
Mastering spaCyDuygu Altinok (Packt Publishing, 2021)An end-to-end practical guide to implementing NLP applications using the Python ecosystem. By the end of this book, you'll be able to confidently use spaCy, including its linguistic features, word vectors, and classifiers, to create your own NLP apps.
Intro to NLP with spaCy (1): Detecting programming languagesIn this new video series, data science instructor Vincent Warmerdam gets started with spaCy, an open-source library for Natural Language Processing in Python. His mission: building a system to automatically detect programming languages in large volumes of text.