Taking back control of your AI developmentFeminist AI (PyData London)Short unconference presentation by Ines on the current focus of our work: empowering developers to build AI in-house again.
Applied NLP in the Age of Generative AI: Future-Proof Strategies for Banking and FinanceECONDAT KeynoteA modern approach and mindset for building future-proof NLP pipelines in-house, focusing on use cases from banking, finance and economics.
KI zwischen Freiheit und Kontrolle: The AI Revolution Will Not Be Monopolizeddata:unplugged (German)How should we envision the use of AI in practice? And are we heading further into a black box era with larger and larger models, obscured behind APIs controlled by big tech monopolies?
Accelerate your Career with Open-Source AIdotAIPanel discussion about making a career out of open-source software, featuring Gael Varoquaux (scikit-learn), Steeve Morin (ZML) and Ines.
Applied NLP in the Age of Generative AIPyData Amsterdam KeynoteIn this talk, Ines shares the most important lessons we’ve learned from solving real-world information extraction problems in industry, and shows you a new approach and mindset for designing robust and modular NLP pipelines in the age of Generative AI.
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillationPyData LondonLLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, Ines shows some practical solutions for using the latest models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
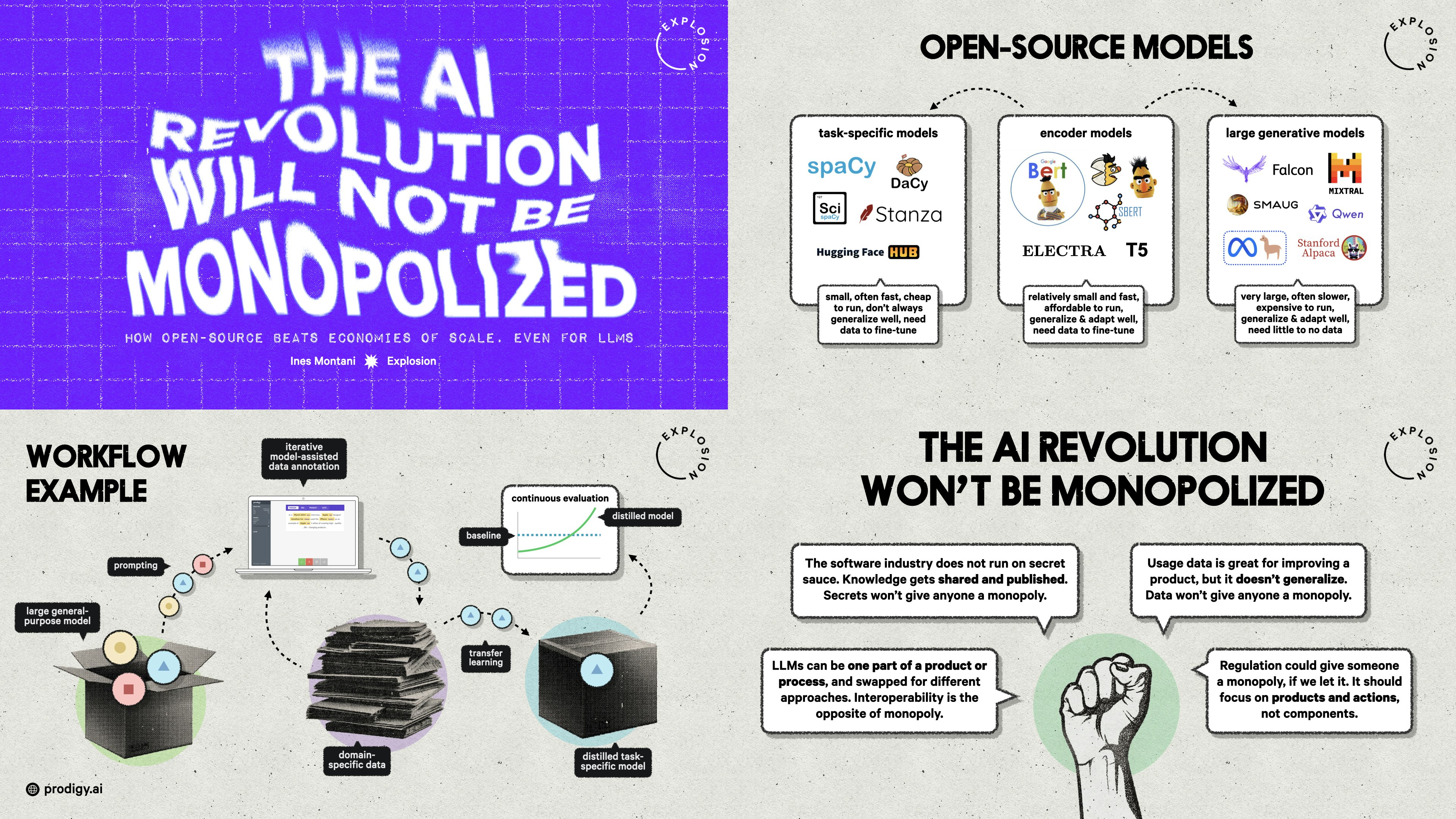
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsPyCon DE & PyData BerlinWith the latest advancements in NLP and LLMs, and big companies like OpenAI dominating the space, many people wonder: Are we heading further into a black box era with larger and larger models, obscured behind APIs controlled by big tech monopolies?
Designing for tomorrow’s programming workflowsPyCon LithuaniaModern editors and AI-powered tools like GitHub Copilot and ChatGPT are changing how people program and are transforming our workflows and developer productivity. But what does this mean for how we should be writing and designing our APIs and libraries?
Half hour of labeling power: Can we beat GPT?PyData NYCLarge Language Models (LLMs) offer a lot of value for modern NLP and can typically achieve surprisingly good accuracy on predictive NLP tasks. But can we do even better than that? In this workshop we show how to use LLMs at development time to create high-quality datasets and train specific, smaller, private and more accurate models for your business problems.
Large Language Models: From Prototype to ProductionEuroPython KeynoteLarge Language Models (LLMs) have shown some impressive capabilities and their impact is the topic of the moment. In this talk, Ines presents visions for NLP in the age of LLMs and a pragmatic, practical approach for how to use Large Language Models to ship more successful NLP projects from prototype to production today.
You are what you read: Building a personal internet front-page with spaCy and ProdigyPyCon DE & PyData Berlin
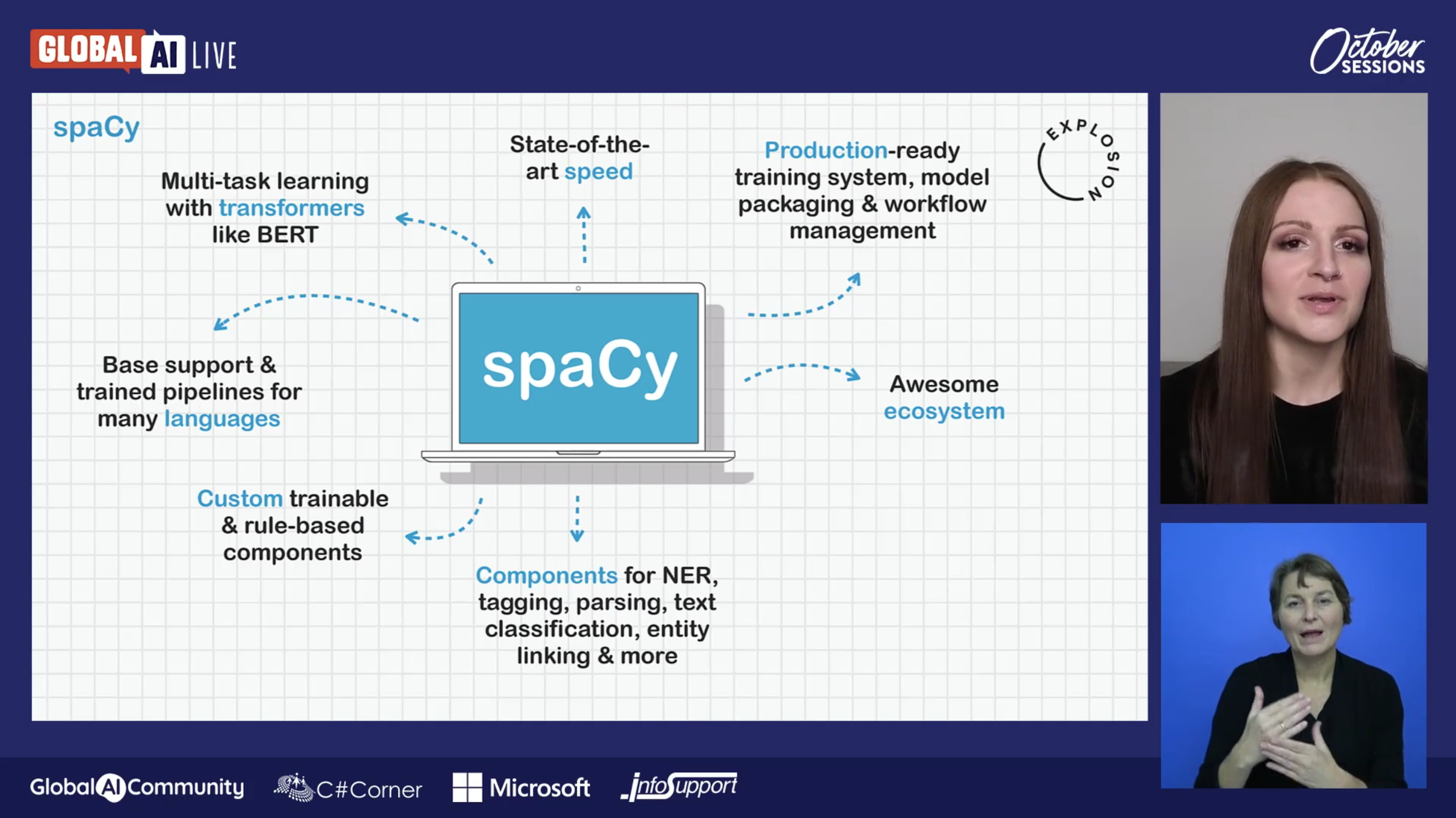
Solutions for Advanced NLP for Diverse LanguagesNew Languages for NLP KeynoteThis talk discusses spaCy’s philosophy for modern NLP, its extensible design and new recent features to enable the development of advanced natural language processing pipelines for typologically diverse languages.
Building new NLP solutions with spaCy and ProdigyPyData Berlin“Commercial machine learning projects are currently like start-ups: many projects fail, but some are extremely successful, justifying the total investment. While some people will tell you to embrace failure, I say failure sucks — so what can we do to fight it? In this talk, I will discuss how to address some of the most likely causes of failure for new NLP projects.”
Vibe NLP for Applied NLPPyCon DE & PyDataWhat if we could take learnings from AI-powered coding agents and apply them to solving real-world NLP problems? In this talk, I’ll show how we’ve built a powerful virtual NLP assistant to help developers create practical and modular solutions that are small, fast and fully data-private.
AI in Reality Fireside Chat: Enterprise AI & Open-Source InnovationPyCon DE & PyDataPanel discussion with Alexander CS Hendorf, Dr. Alexander Beck, Walid Mehanna and Ines.
Künstliche Intelligenz: Technologie der Zukunft – und warum Open Source die Karten neu mischtHeise KI-Woche 2025 (German)German talk on the future of Artificial Intelligence and the impact of open-source software and models.
10 Years of Open Source: Navigating the Next AI RevolutionEuroSciPy KeynoteIn this talk, Ines shares the most important lessons we’ve learned in 10 years of working on open-source software, our core philosophies that helped us adapt to an ever-changing AI landscape and why open source and interoperability still wins over black-box, proprietary APIs.
Towards Structured Data: LLMs from Prototype to ProductionU.S. Census Bureau: Center for Optimization and Data Science SeminarThis talk presents pragmatic and practical approaches for how to use LLMs beyond just chat bots, how to ship more successful NLP projects from prototype to production and how to use the latest state-of-the-art models in real-world applications.
The AI Revolution Will Not Be Monopolized: Behind the scenesOpen Source ML MixerA more in-depth look at the concepts and ideas, academic literature, related experiments and preliminary results for distilled task-specific models.
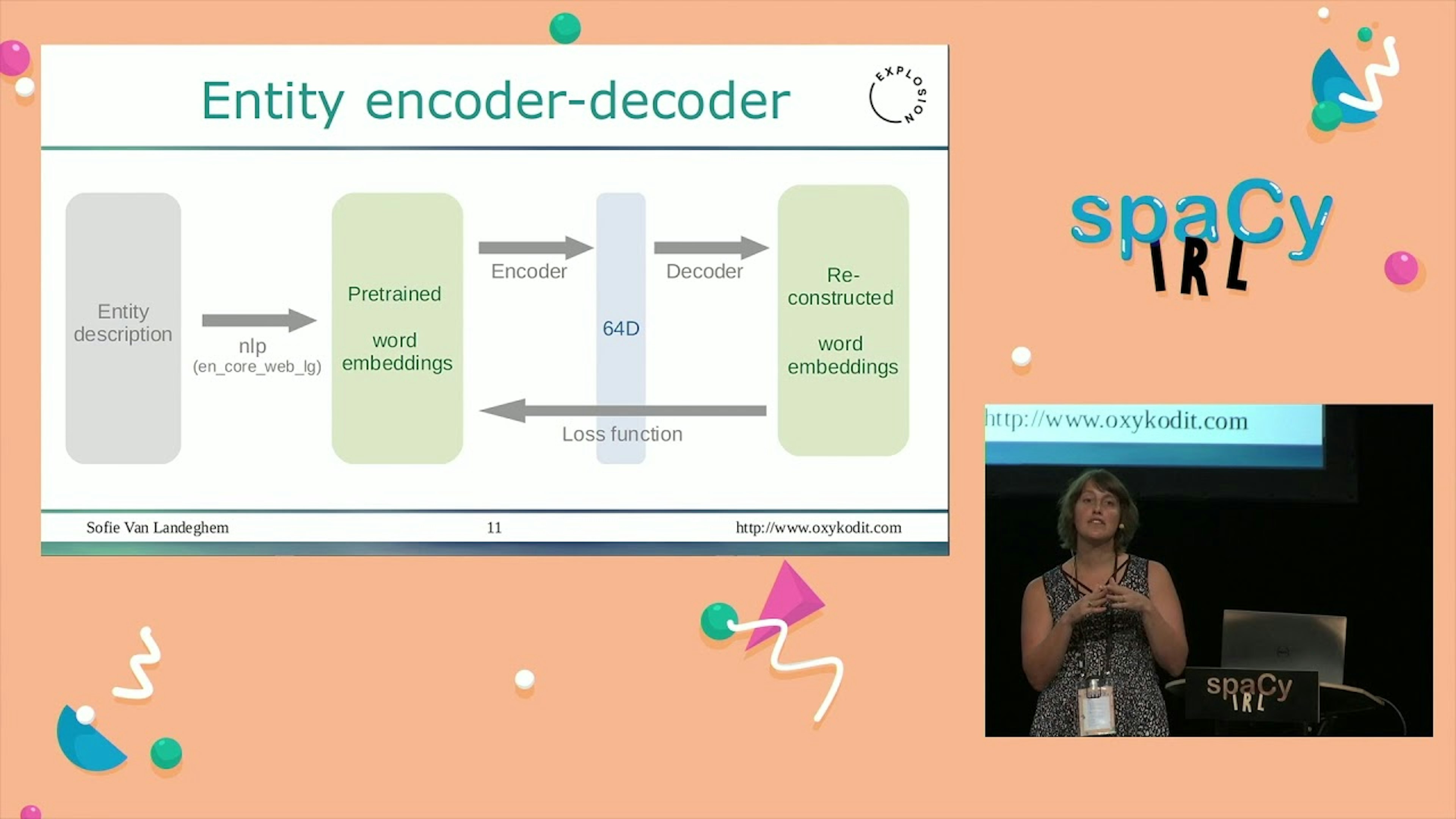
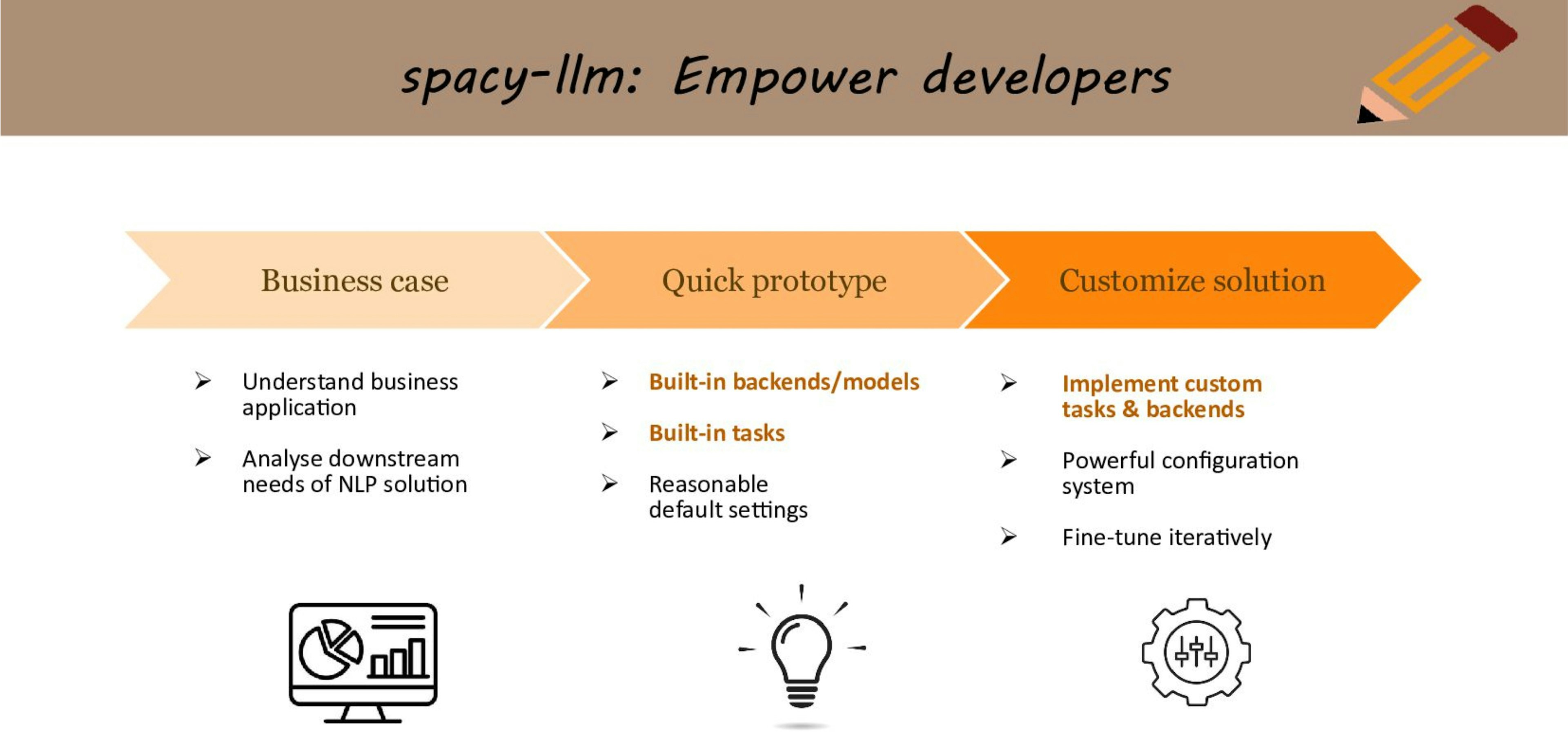
spacy-llm: From quick prototyping with LLMs to more reliable and efficient NLP solutionsAstraZeneca NLP Community of PracticeLLMs are paving the way for fast prototyping of NLP applications. Here, Sofie showcases how to build a structured NLP pipeline to mine clinical trials, using spaCy and spacy-llm. Moving beyond a fast prototype, she offers pragmatic solutions to make the pipeline more reliable and cost efficient.
How many Labelled Examples do you need for a BERT-sized Model to Beat GPT-4 on Predictive Tasks?Generative AI SummitHow does in-context learning compare to supervised approaches on predictive tasks? How many labelled examples do you need on different problems before a BERT-sized model can beat GPT-4 in accuracy? The answer might surprise you: models with fewer than 1b parameters are actually very good at classic predictive NLP, while in-context learning struggles on many problem shapes.
What does “real-world NLP” look like and how can students get ready for it?Teaching NLP at NAACL Keynote
Using spaCy with Hugging Face TransformersPyCon IndiaTransformer models like BERT have set a new standard for accuracy on almost every NLP leaderboard. However, these models are very new, and most of the software ecosystem surrounding them is oriented towards the many opportunities for further research. In this talk, Matt describes how you can now use these models in spaCy to work on real problems and the many opportunities transfer learningfor production NLP, regardless of which software packages you choose.
Embed, encode, attend, predictData Science SummitWhile there is a wide literature on developing neural networks for natural language understanding, the networks all have the same general architecture. This talk explains the four components (embed, encode, attend, predict), gives a brief history of approaches to each subproblem, and explains two sophisticated networks in terms of this framework.
Building AI with AIPyCon Ireland KeynoteAI-powered coding assistants have transformed the way we build software, and AI itself. In this talk, Ines shows why we should use LLMs to build systems instead of as systems, and why code is more important than ever, not less.
Feminist AI LAN PartyPyCon DE & PyDataThree days of workshops, hacking, creating, publishing and connecting locally, featuring a data development workshop with Prodigy and a session on hacking LLMs.
What the history of the web can teach us about the future of AIPyCon+Web KeynoteIn this talk, Ines takes a look at what the history of the web can teach us about the future of AI, and what this means for developers, models, open source and regulation.
Applied NLP with LLMs: Beyond Black-Box MonolithsPyBerlinIn this talk, Ines shows some practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components.
Practical Tips for Bootstrapping Information Extraction PipelinesDataHack SummitThis talk presents approaches for bootstrapping NLP pipelines and retrieval via information extraction, including tips for training, modelling and data annotation.
spaCy meets LLMs: Using Generative AI for Structured DataData+ML Community MeetupThis talk dives deeper into spaCy’s LLM integration, which provides a robust framework for extracting structured information from text, distilling large models into smaller components, and closing the gap between prototype and production.
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsQCon London
Herding LLMs Towards Structured NLPGlobal AI ConferenceThis talk shows how we integrate LLMs into spaCy, leveraging its modular and customizable framework. This allows for cheaper, faster and more robust NLP - driven by cutting-edge LLMs, without compromising on having structured, validated data.
Panel: Large Language ModelsBig PyData BBQwith Ines, Alejandro Saucedo (Zalando, Institute for Ethical AI & ML), Alina Lehnhard (Cerence), Michael Gerz (Heidelberg University), Alexander CS Hendorf (Königsweg)
The Future of NLP in PythonPyCon Colombia KeynoteThe data community came to Python for the language, and stayed for each other – once it got critical mass, it’s the ecosystem that counts. We’ve been proud to be part of that. So what does the future hold for NLP in Python?
The AI Revolution will not be MonopolizedHack TalksWho’s going to "win at AI"? There are now several large companies eager to claim that title. Others say that China will take over, leaving Europe and the US far behind. But short of true Artificial General Intelligence, there’s no reason to believe that machine learning or data science will have a single winner. Instead, AI will follow the same trajectory as other technologies for building software: lots of developers, a rich ecosystem, many failed projects and a few shining success stories.
Rapid NLP annotationData Science SummitThis talk presents a fast, flexible and even somewhat fun approach to named entity annotation. Using our approach, a model can be trained for a new entity type in only a few hours, starting from only a feed of unannotated text and a handful of seed terms.
Conquering PDFs: document understanding beyond plain textPyData LondonIn this talk, Ines presents a new and modular approach for building robust document understanding systems, using state-of-the-art models and the awesome Python ecosystem.
Conquering PDFs: document understanding beyond plain textPyCon DE & PyDataIn this talk, Ines presents a new and modular approach for building robust document understanding systems, using state-of-the-art models and the awesome Python ecosystem.
PyLadies entrepreneurs and career developmentPyLadiesConPanel discussion about career challenges and starting your own business with Cheuk Ting Ho, Tereza Iofciu, Anwesha Das, Una Galyeva and Ines.
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillationInfoQ Dev SummitLLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, Ines shows some practical solutions for using the latest models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
How to uncover and avoid structural biases in evaluating your Machine Learning/NLP projectsPyData LondonThis talk highlights common pitfalls that occur when evaluating ML and NLP approaches. It provides comprehensive advice on how to set up a solid evaluation procedure in general, and dives into a few specific use-cases to demonstrate artificial bias that unknowingly can creep in.
KI – Die künstlerische Intelligenz?Immergut Festival (German)Panelists are discussing the latest developments in Generative AI, hype vs. reality and what those new technologies mean for people, businesses, art, creativity and the music industry.
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsPyCon Lithuania KeynoteWith the latest advancements in NLP and LLMs, and big companies like OpenAI dominating the space, many people wonder: Are we heading further into a black box era with larger and larger models, obscured behind APIs controlled by big tech monopolies?
State-of-the-Art Transformer Pipelines in spaCyaiGrunnIn this talk, we will show you how you can use transformer models (from pretrained models such as XLM-RoBERTa to large language models like Llama2) to create state-of-the-art annotation pipelines for text annotation tasks such as named entity recognition.
Efficient Information Extraction From Text With spaCyJetBrains PyCharmThis webinar takes you through building a spaCy project that uses a named entity recognition (NER) model to extract entities of interest from restaurant reviews, like prices, opening hours and ratings.
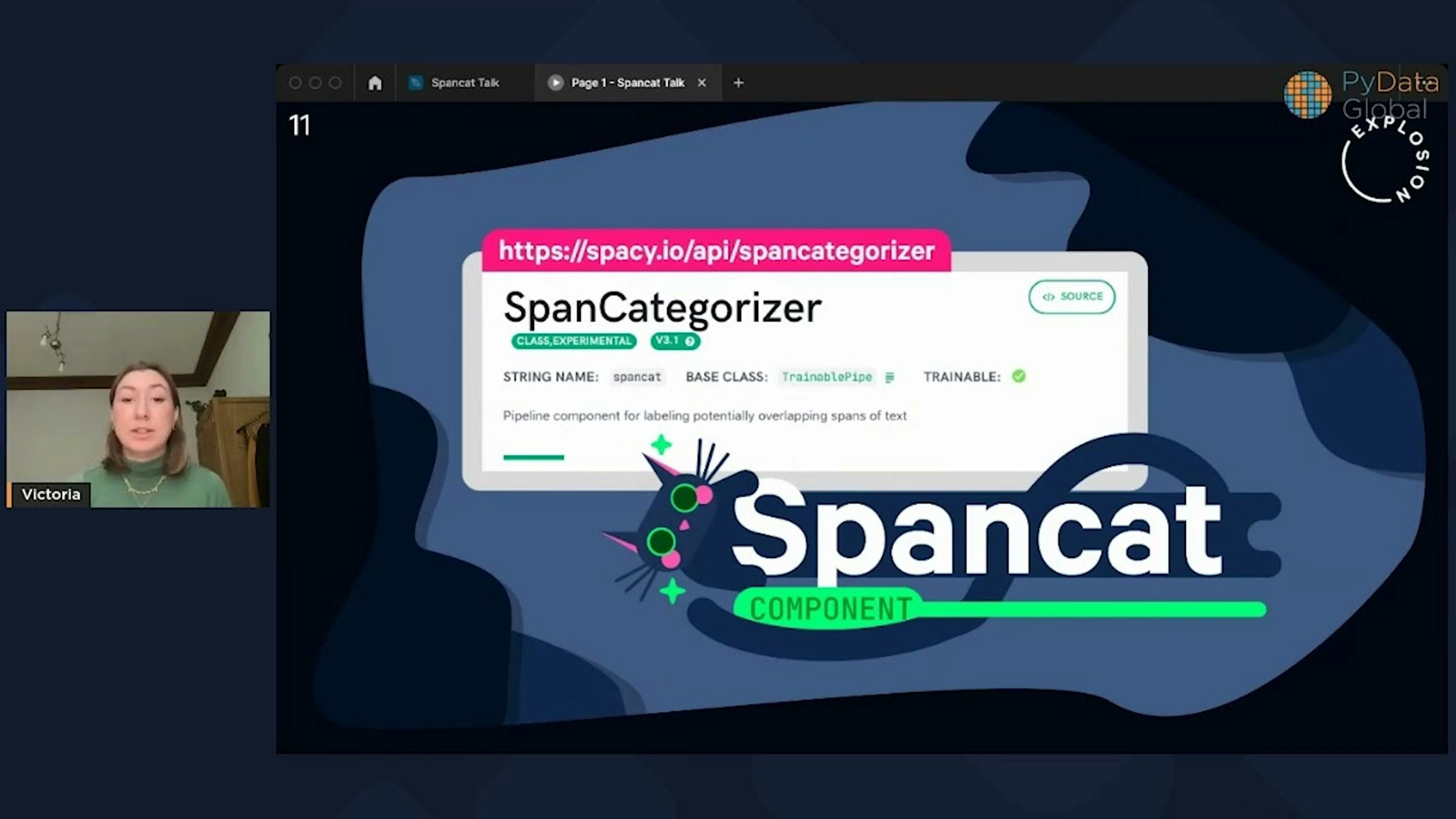
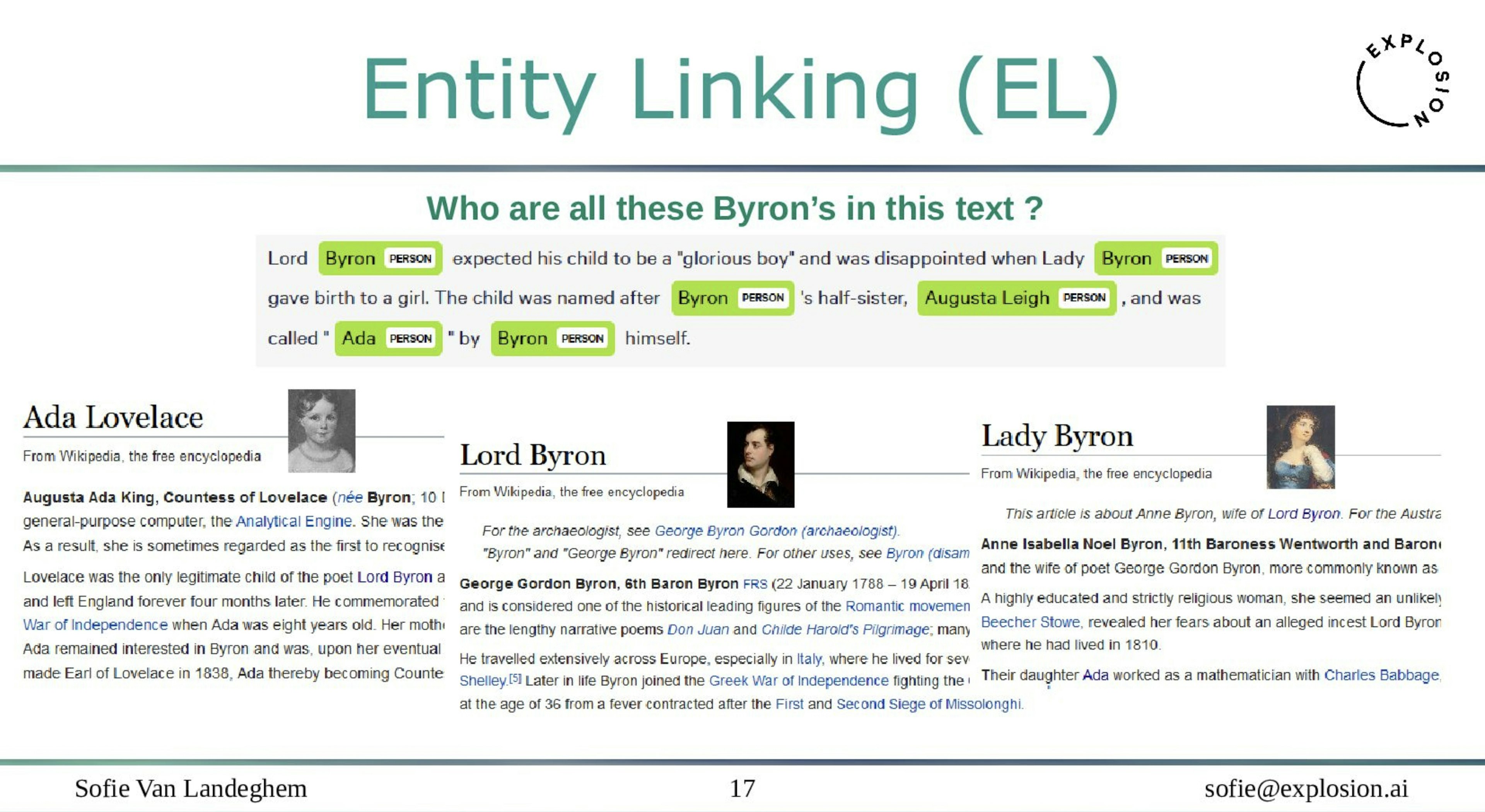
Is it possible to have entities within entities within entities?PyData Global 2022Named entity recognition models might not be able to handle a wide variety of spans, but Spancat certainly can! Dive into named entity recognition, its limitations, and how we’ve solved them with a solution-focused talk and practical applications.
Künstliche Intelligenz Beyond the HypeZündfunk Netzkongress (German)“Artificial intelligence” is everywhere in the headlines. Many futuristic-sounding things suddenly seem possible. It’s not easy to judge what all these technological advances mean. What is hype and what really works? And how should we imagine the future?
How to Ignore Most Startup Advice and Build a Decent Software BusinessEuroPython Keynote“In this talk, I’m not going to give you one "weird trick" or tell you to ~* just follow your dreams *~. But I’ll share some of the things we’ve learned from building a successful software company around commercial developer tools and our open-source library spaCy.”




























































![Natural Intelligence is All You Need[tm]](/_next/image?url=%2Fevents%2Fnatural-intelligence.jpg&w=3840&q=75)