
- 6 minute read
- Blog


The problem with developing a machine learning model is that you don’t know how well it’ll work until you try — and trying is very expensive. Obviously, this risk is unappealing, but the existing solution in the market, one-size-fits-all cloud services, are even worse. We’re launching Explosion AI to give you a better option.
Update (March 2018)
In December we were pleased to release our first commercial product, our annotation tool Prodigy. In just a few months, we’ve been able to welcome hundreds of developers into our new community. Unfortunately, this means we’re not currently available for new consulting projects. However, we still believe that the best way to do AI is in-house – one-size-fits-all solutions still don’t work, and we don’t see that changing.
For the last two years, we’ve been developing spaCy, one of the leading NLP libraries. Matt left academia to write spaCy in 2014. Ines has been working on it since early 2015. Now dozens of companies are using spaCy in production, in combination with the rest of Python’s awesome open-source ecosystem.
Most companies that use spaCy in production use it for machine learning. Machine learning is now considered a “solved problem”. This is true, but only in a fairly academic sense. If you get good at reading research papers, it’s not too hard to find a suitable design. With enough experience, you’ll also be able to implement the system fairly quickly. If you’re doing research, you’re done now. If you’re not, you can now start working on your problem.
A Digital Studio for AI and NLP
If you want your product to make good use of AI technologies, you’re probably going to need your own training and evaluation data. You’ll also need to pick the right system from the recent literature and adjust an implementation to suit your requirements. The best AI products won’t be built from boxed solutions. Instead, they’ll be built from custom software, and in particular, custom data. However, building these assets in-house is expensive and extremely risky. Here’s what we’re offering instead:
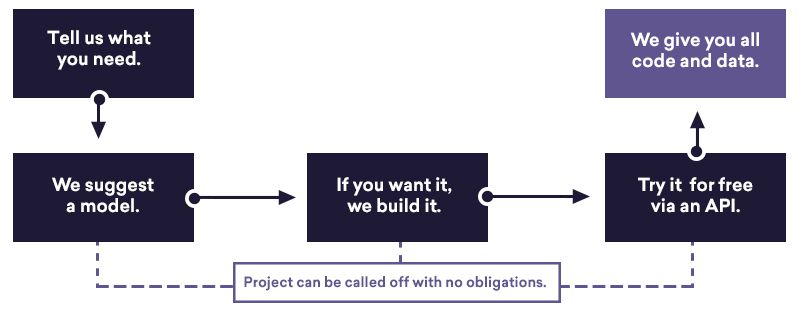
We want to build you custom statistical models. You come to us with a business problem, and we’ll suggest a way to translate it into a machine learning problem. We’ll also figure out whether you need new data assets, and quote you a price. What we can’t do is quote you an accuracy figure, because performance is too difficult to predict. Instead, we’ll give you a trial.
To make this a bit more concrete, here are three examples:
-
Let’s say you’re GitHub. You tell us about a planned feature that will flag duplicate issues. We suggest a model that will take two pieces of text and return a similarity score. You’ll be able to train it on all the public issues users have flagged as duplicate, and then “fine-tune” it for enterprise users. You give us some trial data to work with, along with a deposit. Two months later, we ship you some binaries for onsite testing. If the tests go well, we ship you the source and documentation.
-
Let’s say you’re a startup working on a chatbot that helps companies provide better customer service. You tell us that your bot needs to detect whether the customer is reporting a positive or a negative experience so it can reply accordingly. We annotate some of your data and build you a model that returns a sentiment score between 0 and 1. You test it with live users and find that the behaviour does not work in practice — sarcasm proves particularly problematic. You decide not to buy the solution.
-
Let’s say you’re MailChimp. You tell us that your users often forget to update links in their campaigns and accidentally send their subscribers to the wrong sites. We suggest a model that asks: is that page a likely target for that link? You don’t have annotated examples, but you can’t give us your users’ emails to annotate for you. We implement the classifier and an annotation tool to efficiently train the system in-house. It works great, so we ship you both the front-end and back-end source.
Why we put the risk on ourselves
Commissioning software is usually very different from ordering other types of goods and services. If you ask someone to tailor you a suit, they’re responsible for delivering it according to the agreed specifications, and you’re responsible for paying the agreed price. You’re also responsible for changes to your requirements. If you need a different size or style from what you ordered, you may be able to arrange an alteration — at your expense.
This sort of structure is a poor fit for most software projects, where taking the measurements is harder than making the suit. But for AI projects, the functional requirements are often very easy to describe, at least in informal terms. We don’t need a water-tight specification. Instead, you’ll know project success when you see it.
Commissioning a project from us works a little like commissioning a tattoo. Imagine you want to immortalise your undying love for sloths, so you talk to an artist and come up with a concept. The artist then draws you a design. If it’s not something you can use “in production”, you don’t have to pay. But if you’ve found the sloth of your dreams, it’s yours — forever.
We don’t know whether we’ll be able to take on your project — but we do know how to find out. You don’t have to send us an email or book a phone call. Whether you have an ambitious idea, or a tricky project planned, it’ll only take you a few minutes to fill out our compatibility questionnaire.
Update (March 2018)
In December we were pleased to release our first commercial product, our annotation tool Prodigy. In just a few months, we’ve been able to welcome hundreds of developers into our new community. Unfortunately, this means we’re not currently available for new consulting projects. However, we still believe that the best way to do AI is in-house – one-size-fits-all solutions still don’t work, and we don’t see that changing.



