- 9 minute read
- Blog
- Text Classification
- Question Answering

Supervised models for text-pair classification let you create software that assigns a label to two texts, based on some relationship between them. When the relationship is symmetric, it can be useful to incorporate this constraint into the model. This post shows how a siamese convolutional neural network performs on two duplicate question data sets.
The task of detecting duplicate content occurs on many different platforms. We see it all the time on the spaCy issue tracker, where we’re always trying to figure out which threads can be merged. Duplicate detection is also relevant to most discussion forums, where the same questions are asked repeatedly. Fortunately, there are now labelled data sets from two large community question answering sites: the recently-released Quora data set and the StackExchange corpus compiled by researchers from Melbourne University.
Update (November 7, 2017)
This post previously linked to an online demo of the similarity model. Following the release of spaCy v2.0, we’re currently working on a new version of the model that will hopefully achieve much better accuracy than the previous one.
For comparison, we’ve also included an unsupervised baseline in the demo, which computes a simple word vector average, using vectors from the GloVe common crawl model. The superised models learn a very different similarity definition from this unsupervised baseline, which roughly represents the overlap in topics between the documents. Supervision is often discussed as a disadvantage, because it makes you use labelled data. However, it’s also a crucial advantage: it lets you use labelled data, to customize the relationships being classified. Without supervision, you’re stuck with whatever default relationship the unsupervised algorithm happens to recover.
Siamese networks for symmetric classification
The Quora and StackExchange data sets are labelled according to whether two
questions are duplicates. This relationship should be both commutative and
transitive. We don’t want to compute different results for is_dup(A, B) and
is_dup(B, A) — this is the same question, and the model should treat it as
such. Similarly, if we know is_dup(A, B) and is_dup(B, C), it should hold
that is_dup(A, C).
We can learn a function that obeys these constraints by using a “Siamese” architecture (for the record, I hate this name). The difference in architecture from the asymmetric model I’ve discussed previously is fairly small. As before, we first encode the sentences separately, but instead of an arbitrary non-linearity, we use a distance function to produce the prediction. Here’s a sketch of how the model is put together:
Siamese network outline
The Siamese function above takes two functions, text2vec and
similarity_metric. It uses the text2vec function to separately encode each
text in the input, and then uses similarity_metric to compare them. Each
function is assumed to return a callback to complete its backward pass. Given
this, the backpropagation logic of the Siamese network is very simple. Each
callback returns the gradient with respect to the original function’s inputs,
given the gradient of the original function’s output. For the similarity metric,
I’ve been using a distance function taken from
Chen (2013),
which he terms Cauchy Similarity:
Cauchy Similarity
For the text2vec function, I’ve been using the convolutional layer I
introduced in the previous post, Maxout Window Encoding. The MWE layer has the
same aim as the BiLSTM: extract better word features. It rewrites the vector for
each word based on the surrounding context. This is useful, because it gets
around a major limitation of word vectors. We know that a word like “duck” can
have multiple meanings, and we’d like a vector that reflects the meaning in
context.

The figure above shows how a single MWE block rewrites the vector for each word given evidence for the two words immediately surrounding it. You can think of the output as trigram vectors — they’re built on the information from a three-word window. By simply adding another layer, we’ll get vectors computed from 5-grams — the receptive field widens with each layer we go deeper. Here’s the full model definition, using Thinc, the library I’ve been developing for spaCy 2.0’s neural network models:
Model definition
After the MWE layer, we have two matrices, one for each text. The matrices may be of different lengths, and we need to output a single similarity score. The next step is the weakest part of the model: to compare these matrices, we reduce them to two vectors, by taking their elementwise mean and their elementwise max. Of the two operations, the max tends to be more informative — but using both tends to be slightly better than just using the max.
Results and notable examples
The table below shows development set accuracies on the Quora and StackExchange data. Since neither corpus comes with a designated train/dev/test split, I’ve been using a random 10% and a random 30% partition. All results are still preliminary, and the models’ hyper-parameters have not been tuned successfully.
| Symmetric | Asymmetric | |||
|---|---|---|---|---|
| MWE Depth 0 | MWE Depth 2 | MWE Depth 0 | MWE Depth 2 | |
| Quora | 82.4 | 84.7 | 82.9 | 83.6 |
| StackExchange | 80.2 | 78.0 | 74.9 | 75.2 |
Despite these caveats, the improvement in accuracy from the symmetric network has been quite consistent. On the Quora data, accuracy improves by 2.3% — a bigger improvement than I’ve seen from anything else I’ve been trying. The Maxout Window Encoding layers also seem to help, although the inconsistency of the results makes it difficult to be sure.
It’s interesting to compare the outputs of the two models, especially in comparison to a simple unweighted mean of the GloVe vector assigned to each word. Take a look at the following examples:
| Text 1 | Text 2 | Baseline | Quora | StackExchange |
|---|---|---|---|---|
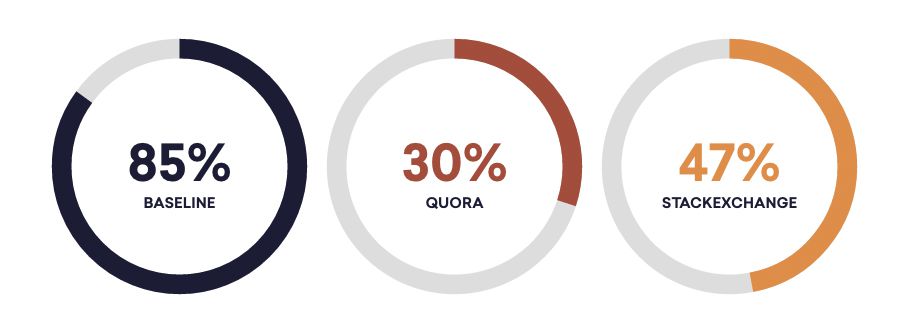
| How to manage success dependency between unit tests | How to structure tests where one test is another test’s setup? | 86% | 12% | 47% |
| Design pattern for overlapping actions and animations? | How do you handle multiple users editing the same piece of data in a webapp? | 79% | 8% | 15% |
| How can I get really good at web development? | What should I do to become an amazing programmer? | 93% | 64% | 100% |
| Where can I find a place to eat pizza? | What’s the closest Italian restaurant? | 84% | 6% | 46% |
| Which companies pay the best in Nebraska? | Which companies pay the best in Montana? | 98% | 8% | 69% |
The default similarity model, which takes a simple vector average, skewed high on most of the examples we tried. Much of the difference in output of the Quora and StackExchange models can be explained by the different domains of the text they were trained on. You can also see the effect of the moderation policy, as this controls the definition of duplicates. For instance, questions which differ in details, such as place, are never regarded as duplicates in the Quora data, so the model learns to pay attention to single named entities.
None of these models are doing a better or worse job at uncovering the “true” similarity of the text pairs they’re classifying — there’s no such thing. Because meaning is so multi-dimensional, pieces of text are always similar in some respects and different in others. The labelling you need will therefore always depend on which relationships are important to your application.
If what you’re trying to get out of a similarity score is an intent label, you probably want to regard two sentences with the same verb but different object as similar — they will both trigger the same function. Alternatively, if you’re trying to cluster opinions in product reviews, the object is probably the decisive dimension. There’s no way for the algorithm to guess what you want, unless you tell it — with example data. That’s why supervised methods are so useful.



