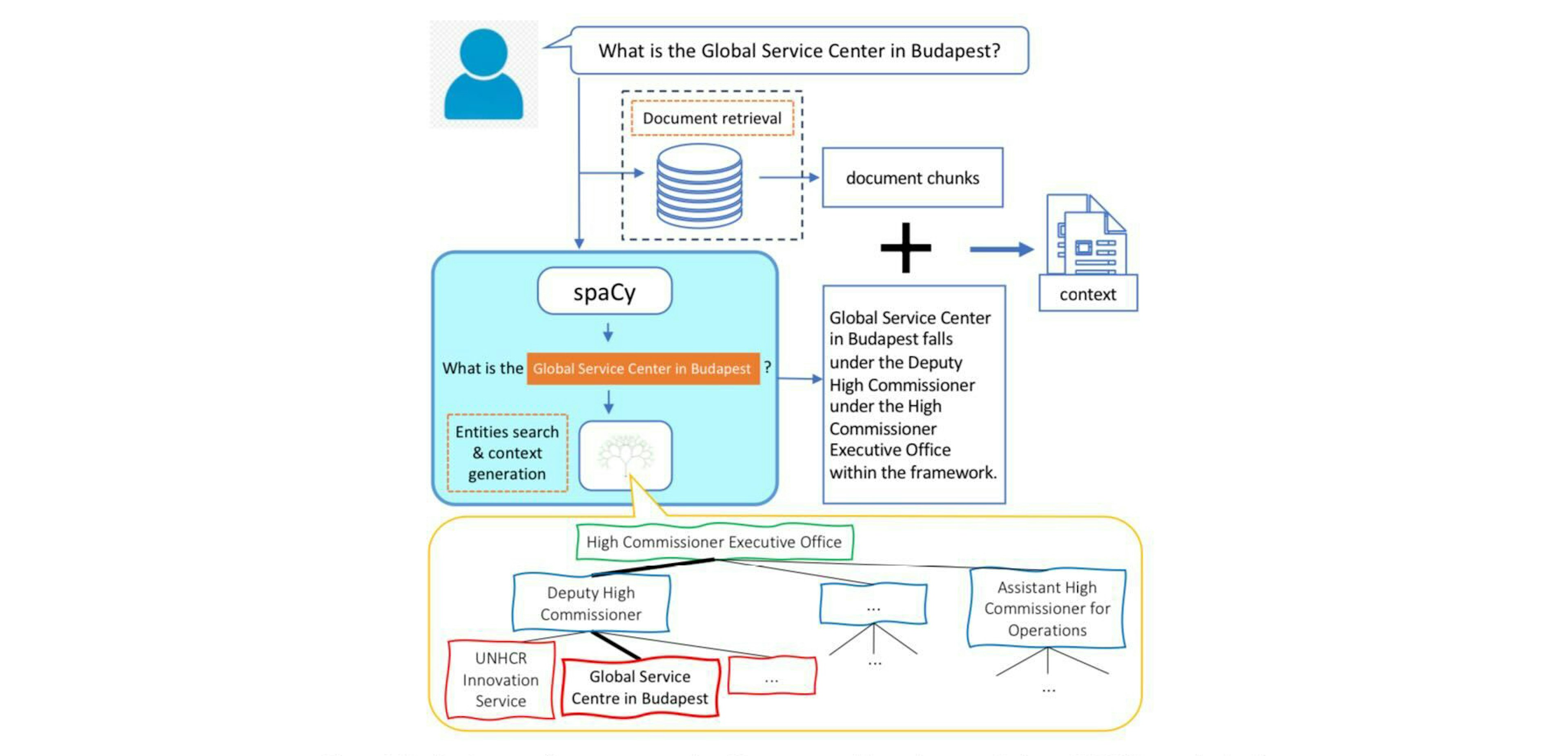
T-RAG: Lessons from the LLM TrenchesFatehkia, Lucas, Chawla (2024)An important application area is question answering over private enterprise documents where the main considerations are data security, which necessitates applications that can be deployed on-prem, [and] limited computational resources. [...] In addition to retrieving contextual documents, we use the spaCy library with custom rules to detect named entities from the organization.
Deep text-pair classification with Quora's 2017 question datasetQuora recently released the first dataset from their platform: a set of 400,000 question pairs, with annotations indicating whether the questions request the same information. This data set is large, real, and relevant — a rare combination. In this post, I'll explain how to solve text-pair tasks with deep learning, using both new and established tips and technologies.
Slovak Dataset for Multilingual Question AnsweringHládek, Staš, Juhár, Koctúr (2023)We used the Prodigy annotation tool to annotate the questions and answers. One annotation task corresponds to one web application deployment and different configurations.
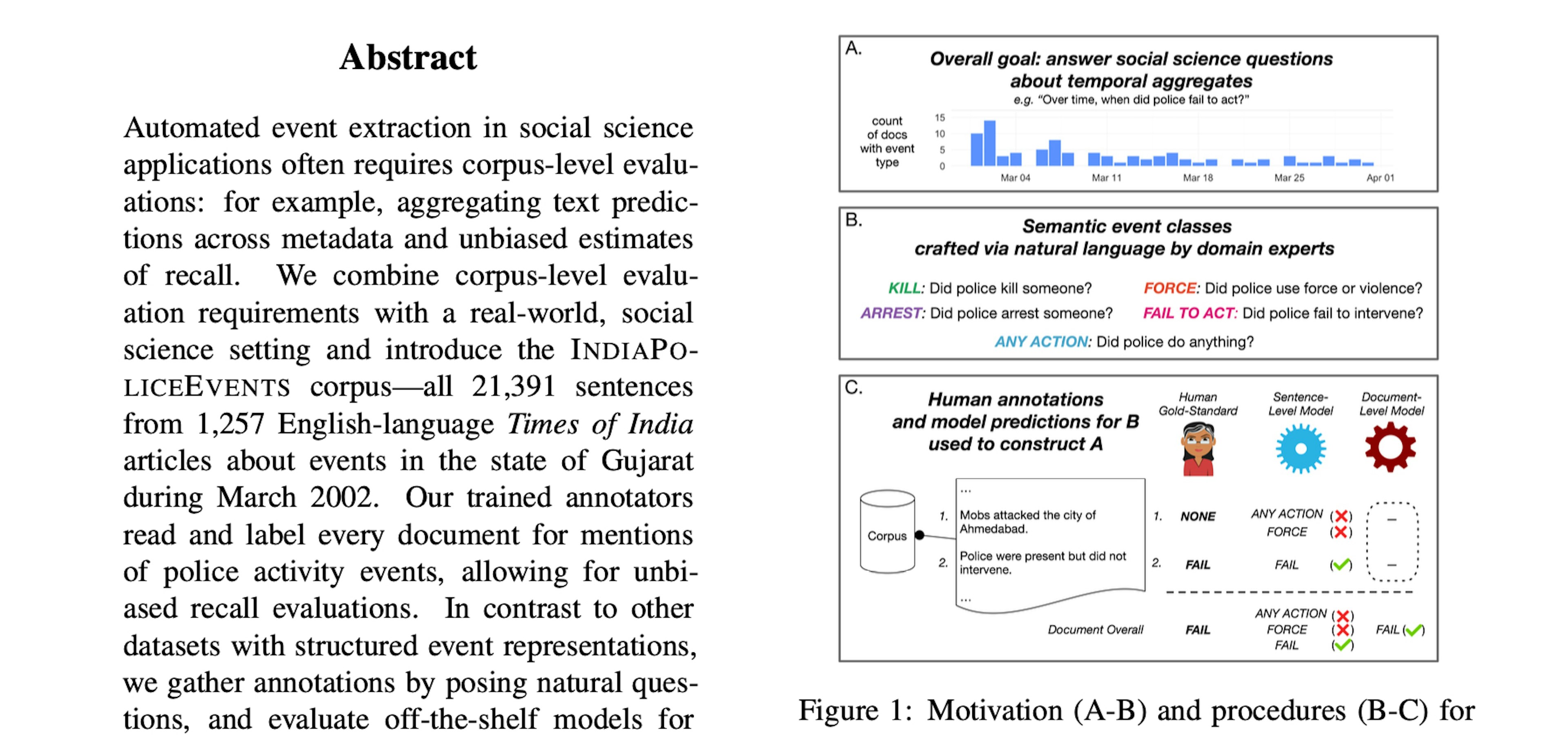
Corpus-Level Evaluation for Event QA: The IndiaPoliceEvents Corpus Covering the 2002 Gujarat ViolenceHalterman, Keith, Sarwar, O’Connor (2021), ACL 2021Figure A2 shows a stylized version of the custom interface we built using the Prodigy annotation tool. Annotators are presented with an entire document, with sentences sequentially highlighted.
Supervised similarity: Learning symmetric relations from duplicate question dataSupervised models for text-pair classification let you create software that assigns a label to two texts, based on some relationship between them. When the relationship is symmetric, it can be useful to incorporate this constraint into the model. This post shows how a siamese convolutional neural network performs on two duplicate question data sets with experimental results.