
It’s been another exciting year at Explosion! We’ve developed a new end-to-end neural coref component for spaCy, improved the speed of our CNN pipelines up to 60%, and published new pre-trained pipelines for Finnish, Korean, Swedish, Croatian and Ukrainian. We’ve also released several updates to Prodigy and introduced new recipes to kickstart annotation with zero- or few-shot learning.
During 2022, we also launched two popular new services – spaCy Tailored Pipelines and spaCy Tailored Analysis. We’ve published several technical blog posts and reports, and created a bunch of new videos covering many tips and tricks to get the most out of our developer tools. We can’t wait to show you what we’re building in 2023 for the next chapters of spaCy and Prodigy, but for now, here’s our look back at 2022. Happy reading!
New spaCy pipeline components

As part of our spaCy v3.3 release in April, we’ve added a trainable lemmatizer to spaCy. It uses edit trees to transform tokens into lemmas and it’s included in the new Finnish, Korean and Swedish pipelines introduced with v3.3, as well as in the new Croatian and Ukrainian pipelines released for spaCy v3.4 in July. We’ve also updated the pipelines for Danish, Dutch, German, Greek, Italian, Lithuanian, Norwegian Bokmål, Polish, Portuguese and Romanian to switch from the lookup or rule-based lemmatizers to the new trainable one.
Furthermore, we’ve implemented a new end-to-end neural
coreference resolution component in
spacy-experimental’s
v0.6.0 release.
The release includes an
experimental English coref pipeline
and a
sample project
that shows how to train a coref model for spaCy. You can read all about this new
coref component in our blog post by Ákos,
Paul and team that outlines why you want to do coreference resolution in the
first place and explains some of the crucial architecture choices of our
end-to-end neural system in detail. Finally, Edi recorded
a video on our coref component showing how to
train a coreference resolution model with spaCy projects and then applies the
trained pipeline to resolve references in a text. Use these resources to
jump-start your experiments with coref, and let us know how you go on the
discussion forum!
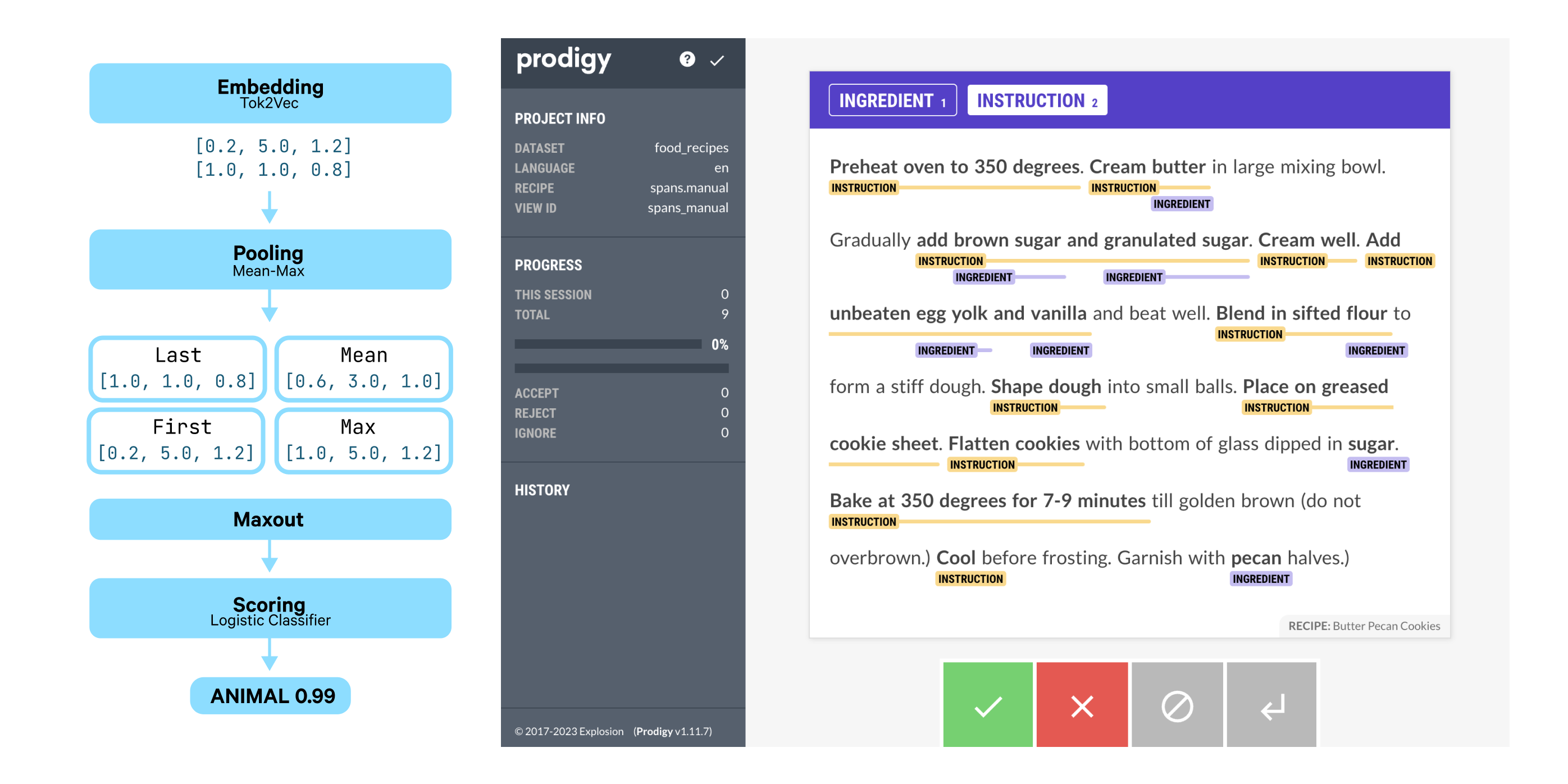
Finally, we’ve spent some time running various experiments and implementing
extensions to our new SpanCategorizer
component. The spancat is a spaCy component that answers the need to handle
arbitrary and overlapping spans, which can be used for long phrases,
non-named entities or overlapping annotations. We added some useful span
suggesters to
spacy-experimental v0.5.0
that identify candidate spans by inspecting annotations from the tagger and
parser, and then marking relevant subtrees, noun chunks, or sentences. Edi, Lj
and team have written a comprehensive
blog post covering full details of the
spancat implementation as well as an architecture case study on nested NER. In
his most recent video, Edi shows how to use
Prodigy for spaCy’s spancat component, annotating food recipes and sharing best
practices around annotation consistency and efficiency.
Performance improvements in our open-source stack
We’ve been focusing heavily on speed improvements across our open-source stack for two years now, including spaCy and Thinc. We fixed a lot of the low-hanging fruit in 2021, improving transformer training performance by up to 62%. We’ve achieved further improvements in 2022 by systematically profiling training and inference and eliminating bottlenecks where we could. There were too many improvements to summarize here, so we will highlight three changes:
- The Thinc
Softmaxlayer is used by many models to compute a probability distribution over classes. This function is quite expensive due to its use of the exponentiation function. During inference, we usually do not care about the actual class probabilities but rather what the most probable class is. Since softmax is a monotonic function, we can find the most probable class from the raw inputs to the softmax function (the so-called logits). In spaCy v3.3, we started using logits during inference, which resulted in speedups of 27% when using a tagging + parsing pipeline. - The transition-based parser extracts features for the transition model to predict the next transition. One function that is used in feature extraction looks up the n-th most recent left-arc of a head. In order to do so, it would first extract all arcs with that particular head from a table of all left-arcs. Since the number of left-arcs correlates with the document length, doing this for each transition unfortunately degraded the complexity of the parser to quadratic-time. In spaCy v3.3, we rewrote this function to perform the lookup in constant-time, restoring the parser’s overall complexity to linear time again. This resulted in large speedups on long documents.
- One of the operations involved in the training of a pipeline component is the
calculation of the loss between the model’s predictions and the gold-standard
labels, which requires computing the alignment between the two. Originally,
the alignment function manually iterated through arrays using a
for-loop and compared the entries individually. In spaCy v3.4, we vectorized those operations which increased GPU throughput and reduced training time by 20%.
Thanks to the aforementioned changes and a myriad other, smaller optimizations, we’ve been able to squeeze out significant improvements in both inference and training performance. In the tables below, we compare the inference and training performance of spaCy on January 1, 2022 and January 1, 2023 for a German pipeline with the tagger, morphologizer, parser and attribute ruler components. The results show improvements across the board, but are most visible in pipelines that are not dominated by matrix multiplication.
Inference performance on Ryzen 5950X/GeForce RTX3090
| Pipeline | Device | January 2022 (words/s) | January 2023 (words/s) | Delta |
|---|---|---|---|---|
| Convolution | CPU | 25,421 | 25,573 | +0.6% |
| Convolution | GPU | 96,291 | 121,623 | +26.3% |
| Transformer | CPU | 1,743 | 1,779 | +2.0% |
| Transformer | GPU | 20,381 | 20,297 | -0.4% |
Training performance on Ryzen 5950X/GeForce RTX3090
| Pipeline | Device | January 2022 (words/s) | January 2023 (words/s) | Delta |
|---|---|---|---|---|
| Convolution | CPU | 5,139 | 6,359 | +23.7% |
| Convolution | GPU | 4,667 | 5,139 | +10.0% |
| Transformer | GPU | 3,327 | 3,575 | +7.5% |
We also made two large optimizations that primarily benefit Apple Silicon Macs.
In 2021, we released
thinc-apple-ops.
With this add-on package, Thinc uses Apple’s Accelerate framework for matrix
multiplication. Accelerate uses special matrix multiplication units (AMX) on
Apple Silicon Macs, resulting in large speedups. However, spaCy’s dependency
parser did not use Thinc for matrix multiplication in low-level Cython code. The
first optimization was to define a C BLAS interface in Thinc and use this in
the dependency parser to leverage the AMX units. This leads to large
improvements in training and inference speeds as shown in the tables below.
The second optimization was to leverage the support for Metal Performance Shaders that was added to PyTorch to speed up transformer models. Madeesh and Daniël have written a blog post about fast transformer inference using Metal Performance Shaders. The performance impact can also be seen in the results below.
Inference performance on M1 Max
| Pipeline | Device | January 2022 (words/s) | January 2023 (words/s) | Delta |
|---|---|---|---|---|
| Convolution | CPU | 35,818 | 57,376 | +60.1% |
| Transformer | CPU | 1,883 | 1,887 | 0.0% |
| Transformer | GPU | See CPU | 7,660 | +406.9% |
Training performance on M1 Max
| Pipeline | Device | January 2022 (words/s) | January 2023 (words/s) | Delta |
|---|---|---|---|---|
| Convolution | CPU | 7,593 | 9975 | +31.4% |
All in all, it has been a great year for performance! Nevertheless, we have more improvements in the works - particularly with respect to transformer models - that we hope to show you in the following months.
Prodigy updates
We released Prodigy v1.11.7 and Prodigy v1.11.8. These releases include various bug fixes, usability improvements and extended support to the latest spaCy versions, as well as many other small improvements.
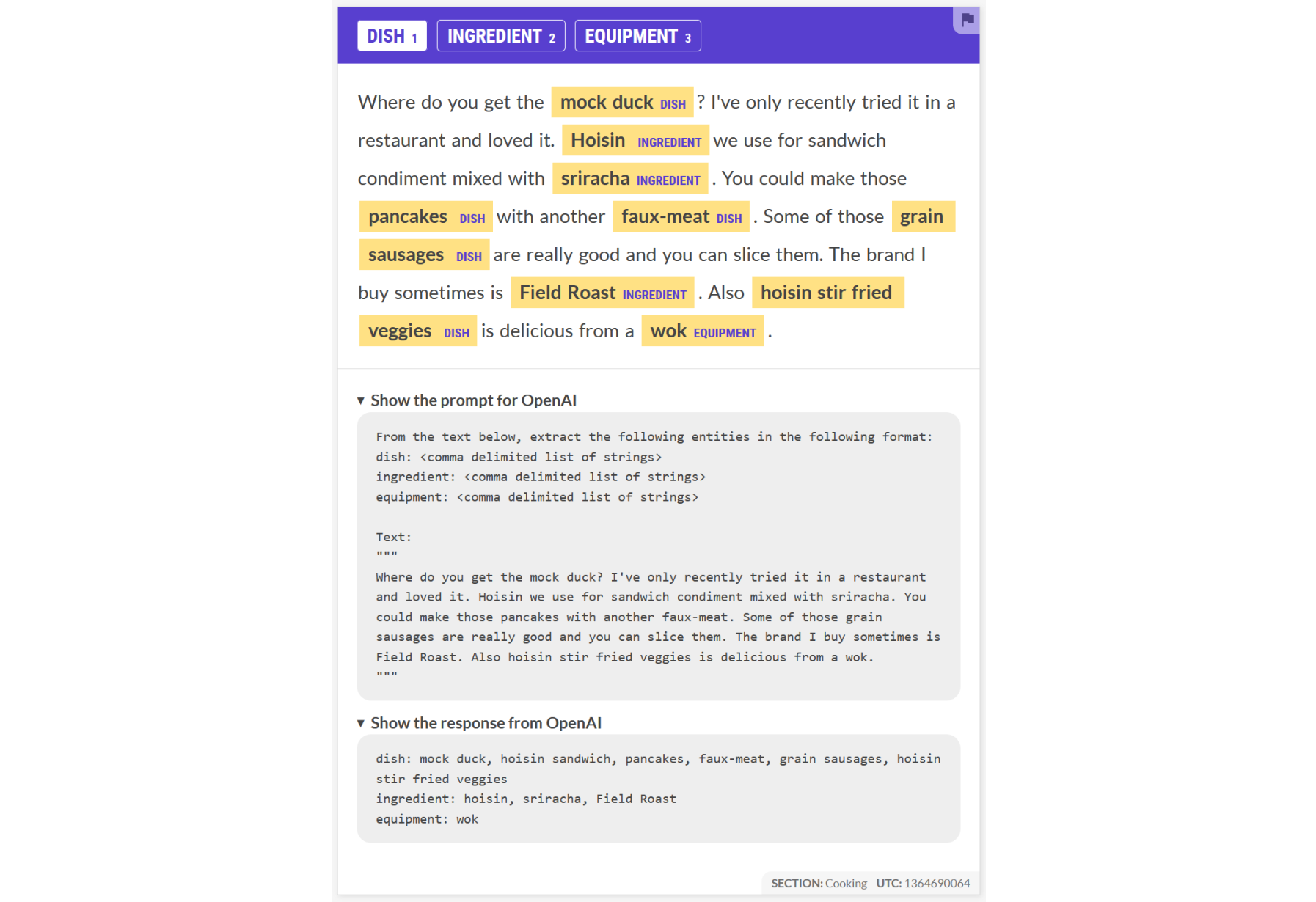
Further, we’ve been working on new Prodigy workflows that use the OpenAI API to kickstart your annotations, via zero- or few-shot learning. We published the first recipe, for NER annotation, at the end of December. Keep an eye on this repo as more exciting recipes will be published soon!
Launching our consultancy offerings
In 2022, we launched two brand new consulting services! February saw the launch of spaCy Tailored Pipelines, where we offer custom-made solutions by spaCy’s core developers for your NLP problems. By the summer we had already engaged with several companies on a variety of interesting use cases, including Patent Bots’ legal information extraction pipeline. It now handles training, packaging and deployment in a spaCy project structure that is easy to maintain and update in the future.

In November, we followed up with the launch of our second new service: spaCy Tailored Analysis. People often ask us for help with problem solving, strategy and analysis for their applied NLP projects, so we designed this new service to help with exactly these types of problems.
Open-source stack
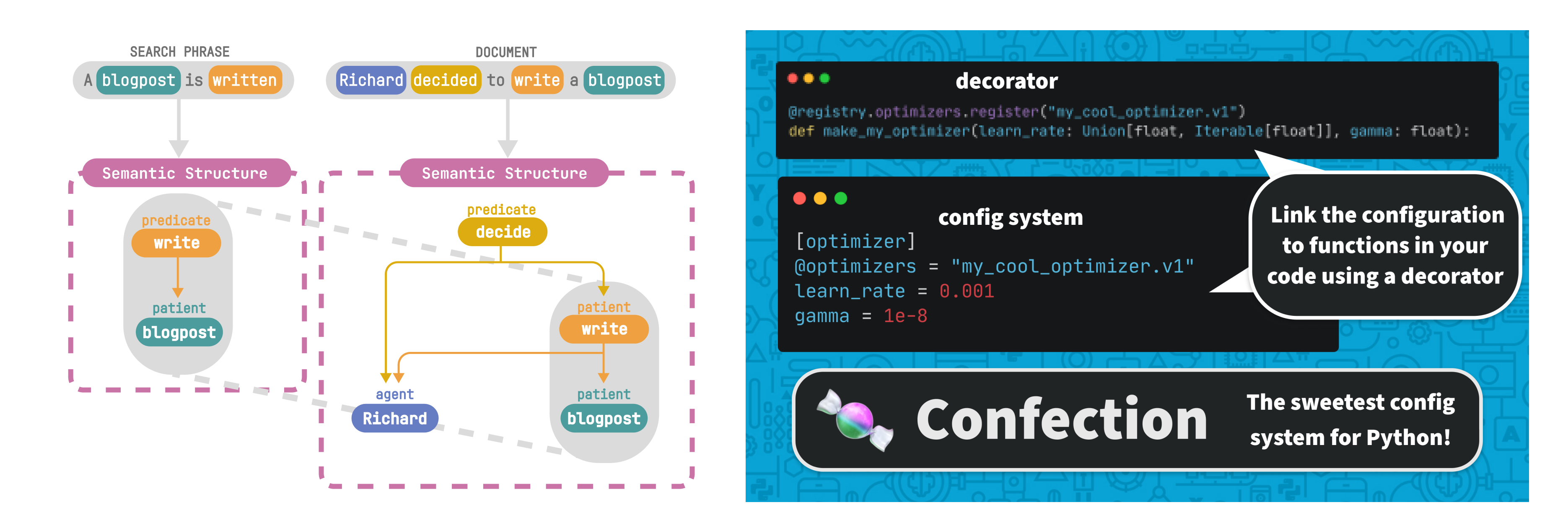
In August, we released the config system used by spaCy and Thinc as its own
lightweight package: confection!
Confection, our battle-tested config system for Python, can now easily be
included in any Python project without having to install Thinc.
We’ve also added support for spaCy v3.4 for English, German and Polish in the v1.3.0 release of the Coreferee library. Holmes, an information extraction component based on predicate logic, was also updated to support spaCy v3.4 in its v4.1.0 release.
User resources and documentation
We’ve worked hard on creating more resources that explain spaCy’s
implementation and architecture choices in further detail. On top of the
content produced for coref and spancat, Adriane has written an
interesting
blog post explaining floret, which
combines fastText and Bloom embeddings to create compact vector tables with both
word and subword information and enables vectors that are up to 10× smaller than
traditional word vectors. Additionally, Lj, Ákos et al. published
a technical report that benchmarks spaCy’s
hashing trick on various NER datasets in different scenarios. Finally, this
LinkedIn thread
by Vincent explains you all you need to know about spaCy’s Vocab object and
its vectors.

Only just getting started with spaCy or Prodigy? Our ever-popular “Advanced NLP with spaCy” course has got you covered, and is now available en français on top of our current languages: English, German, Spanish, Portuguese, Japanese and Chinese. We’ve also created a spaCy cheat sheet, packed with great features and practical tips so you can create projects at lightning speed, and we revamped Ines’ flowchart containing our best practices for annotating and training Named Entity Recognition models with Prodigy. The PDF version includes clickable links for context and additional information.

Already a pro? You might be pretty interested in The Guardian case study report that Ryan and team wrote. In order to modularize content for reuse, The Guardian’s data science team developed a spaCy-Prodigy NER workflow for quote extraction. We talked with The Guardian’s lead data scientist Anna Vissens about the project for a fascinating blog post. And on the topic of expert content, our machine learning engineer Lj shows how to integrate HuggingFace’s LayoutLMv3 model with Prodigy to tackle the challenge of extracting information from PDFs.
Videos

We’ve expanded our YouTube channel with two new playlists:
spaCy Shorts and Prodigy Shorts. As part of the
spaCy Shorts
series, Vincent walks you through various quick lessons on how to
speed up your pipeline execution via nlp.pipe,
how to
leverage linguistic features in a rule-based approach,
and much more. The bite-sized videos in the
Prodigy Shorts
playlist demonstrate how to configure the Prodigy UI for efficient annotations,
and
how to exploit Prodigy’s core scriptability design.
Interested in more nitty gritty details? In one of his first videos with Explosion, Vincent explains how to use Prodigy to train a named entity recognition model from scratch by taking advantage of semi-automatic annotation and modern transfer learning techniques. On the topic of efficient labeling, this recent Prodigy video shows how you can use a bulk labeling technique to prepare data for Prodigy and illustrates that a pre-trained language model can help you annotate data. Finally, this Prodigy video shows how you might be able to improve the annotation experience by leveraging sense2vec to pre-fill named entities.
Talks
We are always excited to talk about our vision on implementing developer tools, general design choices or new features that we released. In January, Ines appeared on ZenML’s podcast Pipeline Conversations and talked about creating tools that spark joy. She also gave the keynote at the New Languages for NLP conference at Princeton in May. Her talk covered the challenges for non-English NLP and how spaCy allows you to develop advanced NLP pipelines, including for typologically diverse languages. In June, she presented a nice recap of spaCy’s changes over time on Deepak John Reji’s D4 Data Podcast.

Over at the Data-aware Distributed Computing (DADC) conference in July, Damian and Magda gave a talk on collecting high-quality adversarial data for machine reading comprehension tasks with humans and models in the loop. Victoria and Damian also both gave talks at PyData Global in the beginning of December.
If you were ever curious about what some of us get up to at Explosion, as of December we’ve added an events page to our website where you can see upcoming and past talks from us. If you want to meet us in person and learn about our tools, maybe grab some stickers, check it out!
With the community and the team continuing to grow, we look forward to making 2023 even better. Thanks for all your support!



