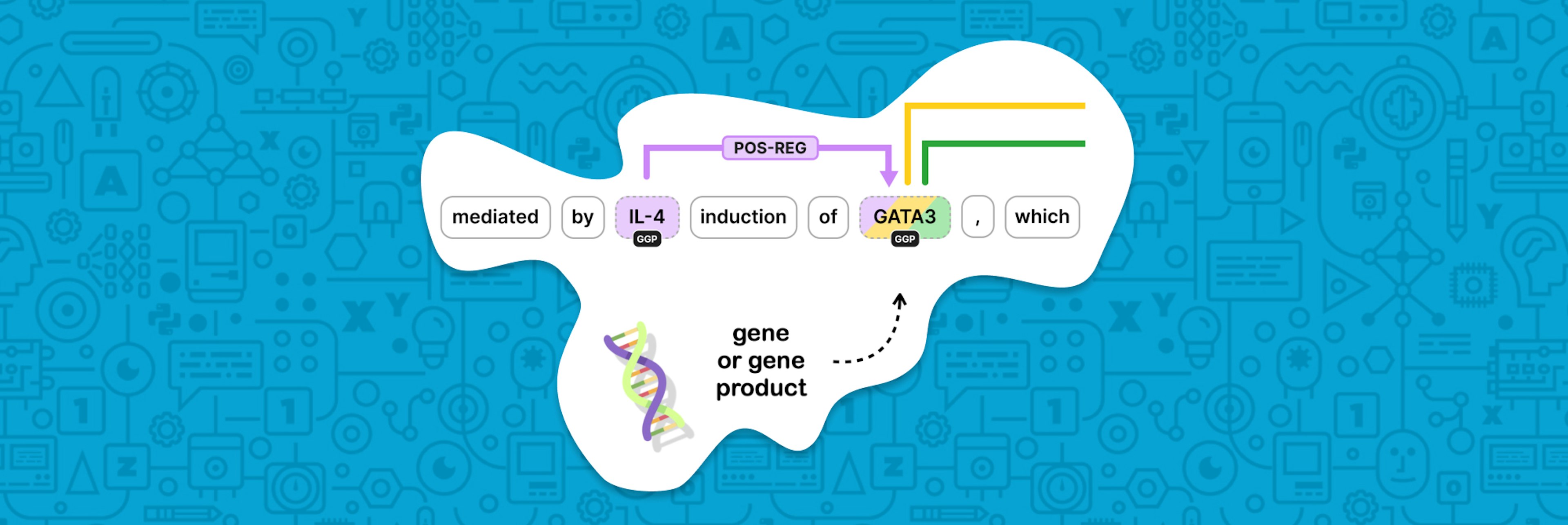
Implementing a custom trainable component for relation extractionRelation extraction refers to the process of predicting and labeling semantic relationships between named entities. In this blog post, we'll go over the process of building a custom relation extraction component using spaCy and Thinc. We'll also add a Hugging Face transformer to improve performance at the end of the post. You'll see how you can utilize Thinc's flexible and customizable system to build an NLP pipeline for biomedical relation extraction.
Rulers, NER, and data iterationAbout the power of Rules + ML and the importance of iteration on your pipeline and your data.
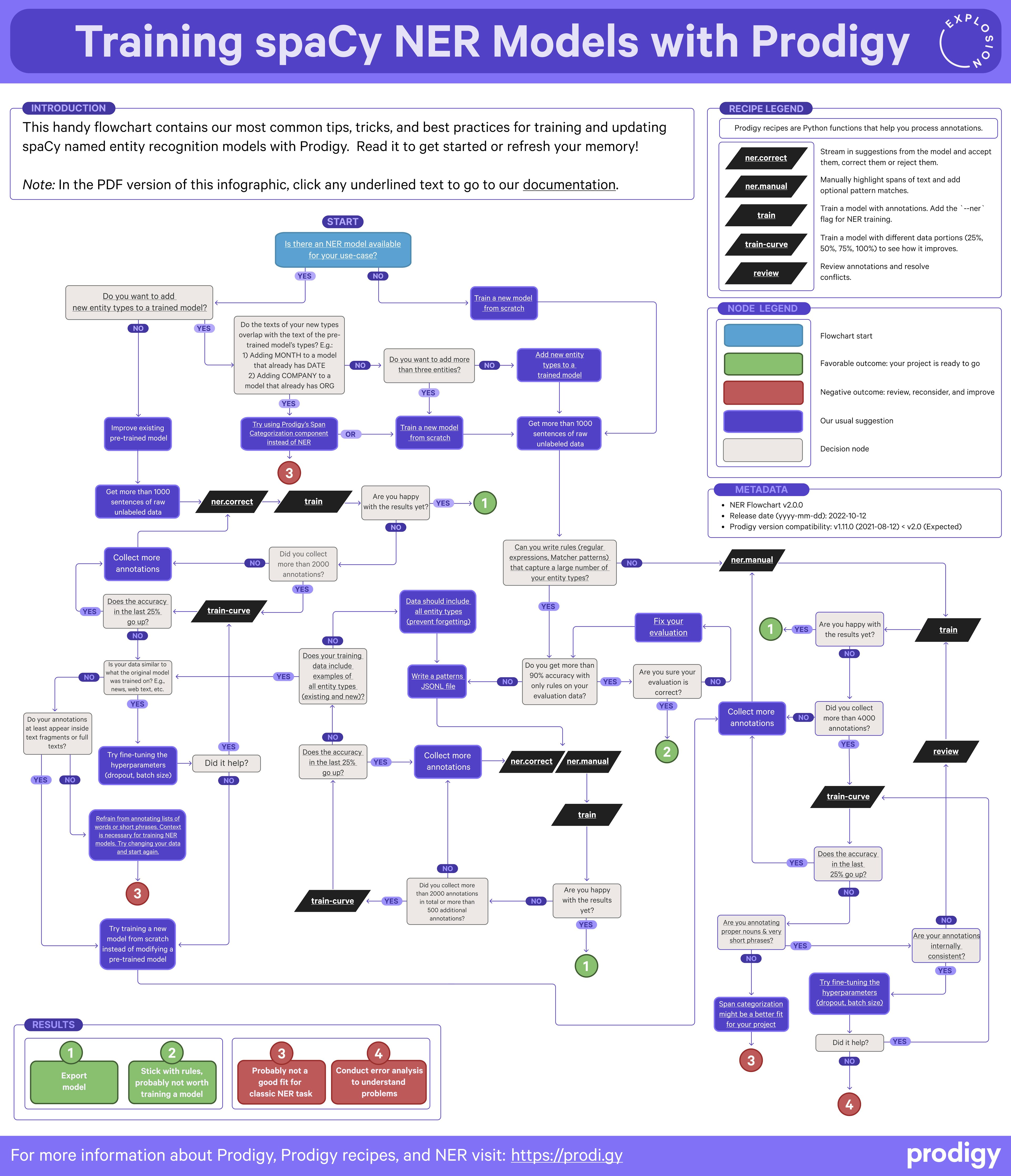
Training spaCy NER Models with ProdigyThis handy flowchart contains our most common tips, tricks, and best practices for training and updating spaCy named entity recognition models with Prodigy.
End-to-end Neural Coreference Resolution in spaCyCoreference resolution is the problem of resolving entities in texts to references such as pronouns. Even if you've never heard of it, it's something we all do constantly every day, and is a key to understanding natural language. We recently added an experimental implementation of an end-to-end neural coreference component to spaCy. This post explains the architecture of our model in detail.
Introducing spaCy v3.6spaCy v3.6 introduces the span finder component and trained pipelines for Slovenian.
You are what you read: Building a personal internet front-page with spaCy and ProdigyPyCon DE & PyData Berlin
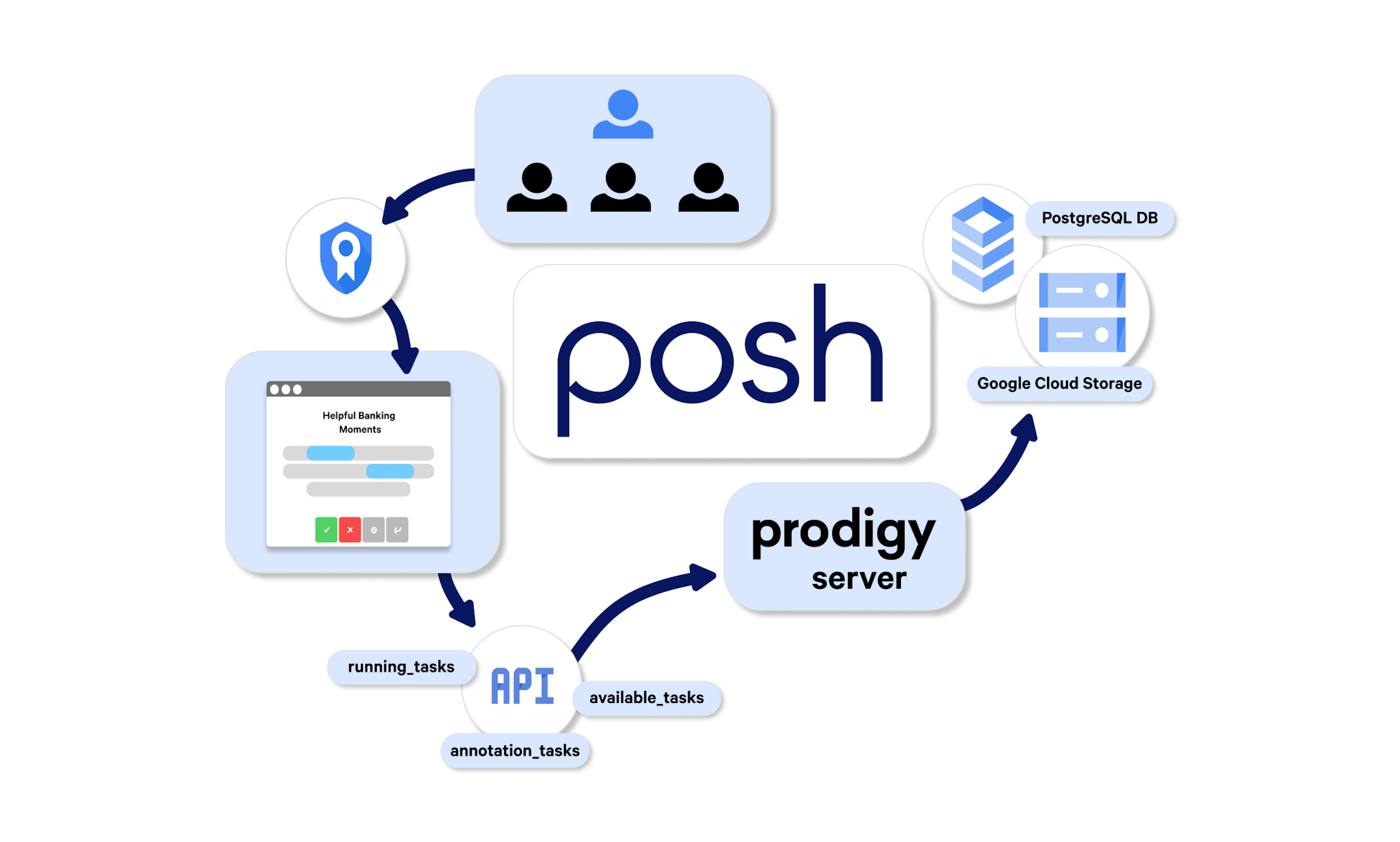
Deploying a Prodigy cloud service for Posh’s financial chatbotsA Prodigy case study of Posh AI's production-ready annotation platform and custom chatbot annotation tasks for banking customers.
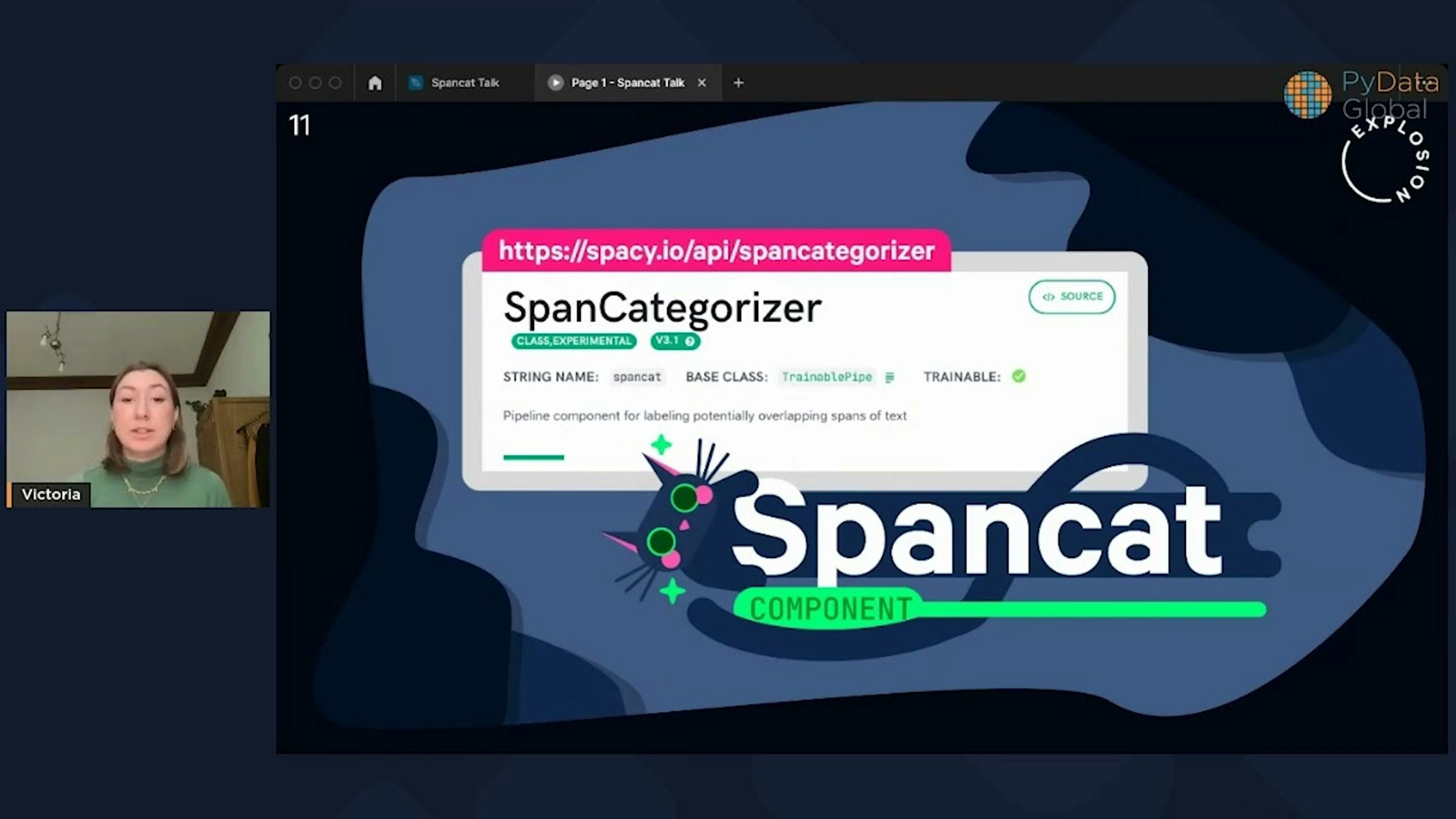
Is it possible to have entities within entities within entities?PyData Global 2022Named entity recognition models might not be able to handle a wide variety of spans, but Spancat certainly can! Dive into named entity recognition, its limitations, and how we’ve solved them with a solution-focused talk and practical applications.
spaCy behind the scenes: library patterns & design concepts explainedDeveloper productivity has been central to our design of spaCy, both in smaller decisions and some of the bigger architectural questions. We believe in embracing the complexities of machine learning, not hiding it away under leaky abstractions, while also maintaining the developer experience. Read on to learn some of the design patterns within the library, how we've implemented them, and most importantly, why.
Efficient Information Extraction From Text With spaCyJetBrains PyCharmThis webinar takes you through building a spaCy project that uses a named entity recognition (NER) model to extract entities of interest from restaurant reviews, like prices, opening hours and ratings.
Introducing spaCy v3.5spaCy v3.5 introduces new CLI commands, fuzzy matching, improvements for entity linking and more.
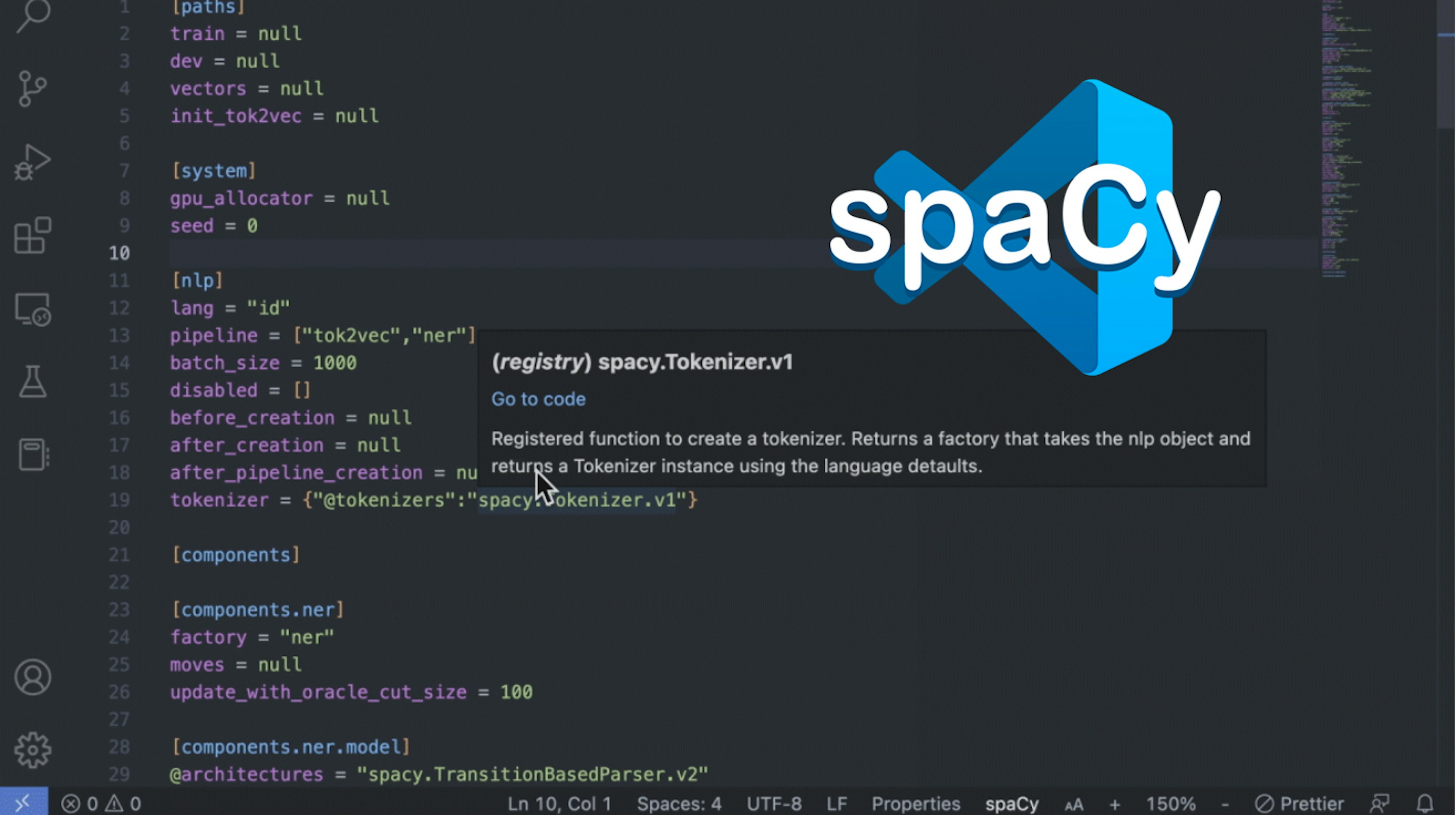
spaCy Plugin for VSCodeThe spaCy VSCode Extension provides additional tooling and features for working with spaCy’s config files. Version 1.0.0 includes hover descriptions for registry functions, variables, and section names within the config as an installable extension.
The Tale of Bloom Embeddings and Unseen EntitiesThe default Bloom embedding layer in spaCy is unconventional, but very powerful and efficient. We wrote about it before and showed the advantages it provides in terms of memory efficiency for our floret embeddings. Now we have released the first technical report by Explosion, where we explain Bloom embeddings in more detail and rigorously compare them to traditional embeddings. In this post we'll highlight some of our results with a special focus on unseen entities.
Explosion in 2022: Our Year in ReviewIt's been another exciting year at Explosion! We've developed a new end-to-end neural coref component for spaCy, improved the speed of our CNN pipelines up to 60%, and published new pre-trained pipelines for Finnish, Korean, Swedish and Croatian. We've also released several updates to Prodigy and introduced new recipes to kickstart annotation with zero- or few-shot learning.
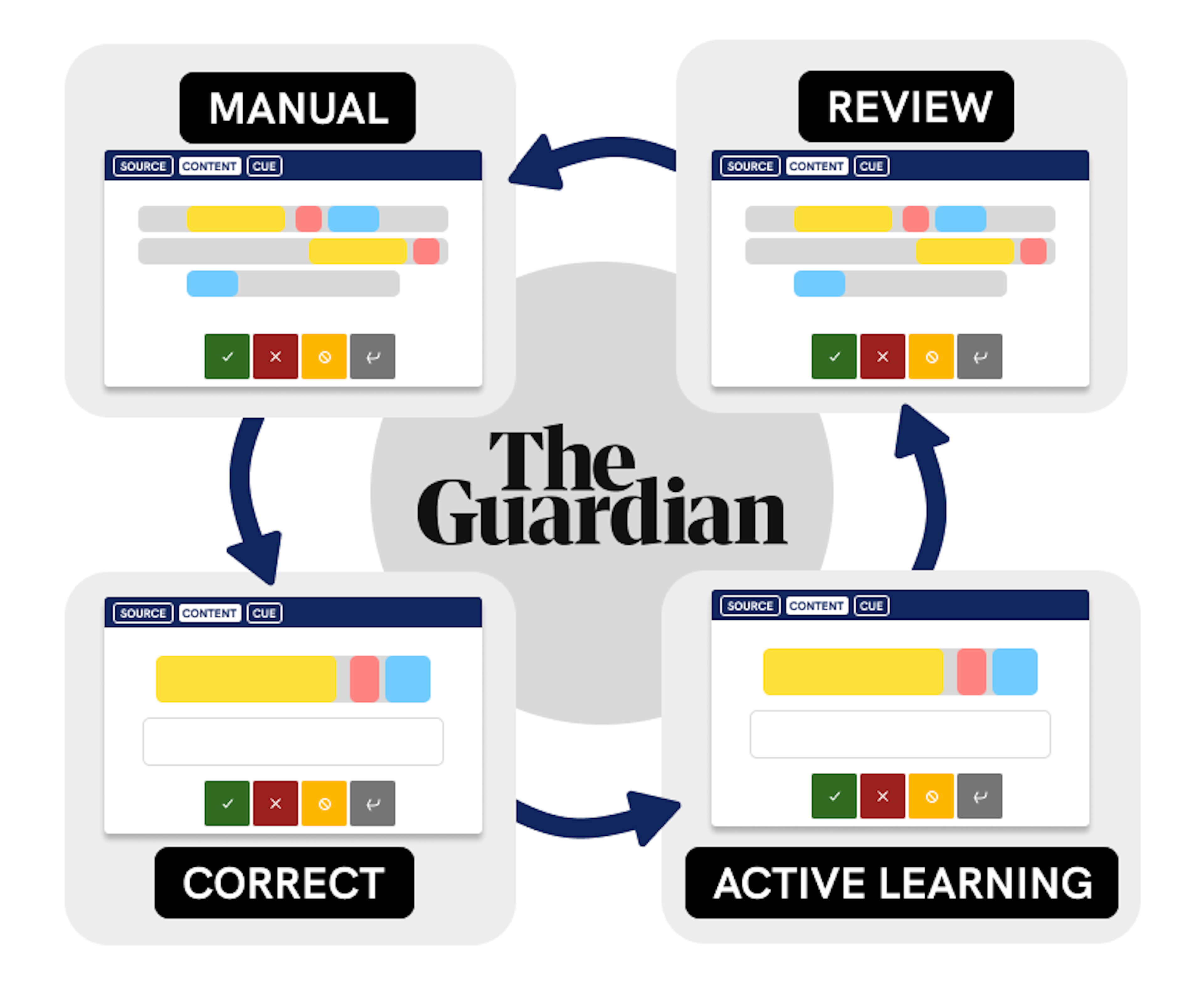
How the Guardian approaches quote extraction with NLPA case study of the Guardian's spaCy-Prodigy workflow to modularize quote extraction for content creation. This study includes iterative annotation guidelines and custom interface functionality.