Once a Maintainer: Sofie Van LandeghemInterview with Sofie about her work as a core maintainer of spaCy, the evolution of NLP, and why dependency management in Python is so terrible.
Explosion in 2022: Our Year in ReviewIt's been another exciting year at Explosion! We've developed a new end-to-end neural coref component for spaCy, improved the speed of our CNN pipelines up to 60%, and published new pre-trained pipelines for Finnish, Korean, Swedish and Croatian. We've also released several updates to Prodigy and introduced new recipes to kickstart annotation with zero- or few-shot learning.
Introducing spaCy v3.4spaCy v3.4 brings typing and speed improvements along with new vectors for English CNN pipelines and new trained pipelines for Croatian.
Explosion in 2021: Our Year in ReviewThe year 2021 is coming to an end, and like the previous year, it was shaped by unique challenges that impacted our work together. For Explosion, it was a very productive year. We found an investor that fits our strategy, the work on Prodigy Teams is in full swing, and the team has grown a lot. So here's our look back at our highlights of the year 2021.
Introducing spaCy v3.0spaCy v3.0 is a huge release! It features new transformer-based pipelines that get spaCy's accuracy right up to the current state-of-the-art, and a new workflow system to help you take projects from prototype to production. It's much easier to configure and train your pipeline, and there are lots of new and improved integrations with the rest of the NLP ecosystem.
How to uncover and avoid structural biases in evaluating your Machine Learning/NLP projectsPyData LondonThis talk highlights common pitfalls that occur when evaluating ML and NLP approaches. It provides comprehensive advice on how to set up a solid evaluation procedure in general, and dives into a few specific use-cases to demonstrate artificial bias that unknowingly can creep in.
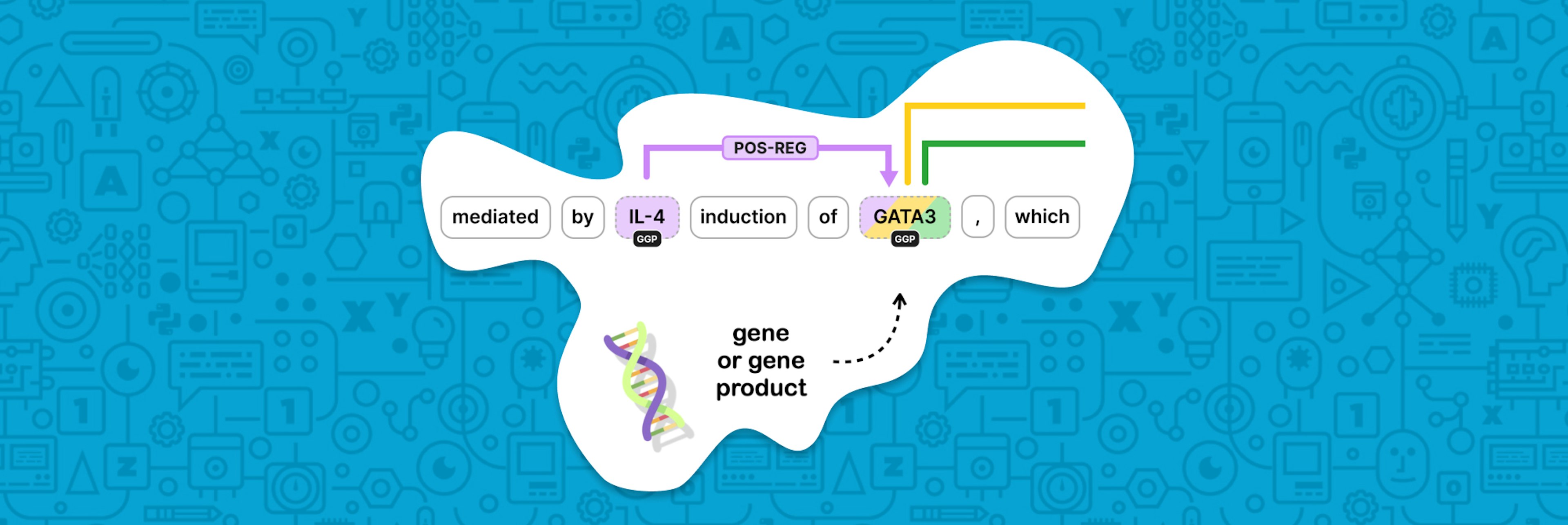
Implementing a custom trainable component for relation extractionRelation extraction refers to the process of predicting and labeling semantic relationships between named entities. In this blog post, we'll go over the process of building a custom relation extraction component using spaCy and Thinc. We'll also add a Hugging Face transformer to improve performance at the end of the post. You'll see how you can utilize Thinc's flexible and customizable system to build an NLP pipeline for biomedical relation extraction.
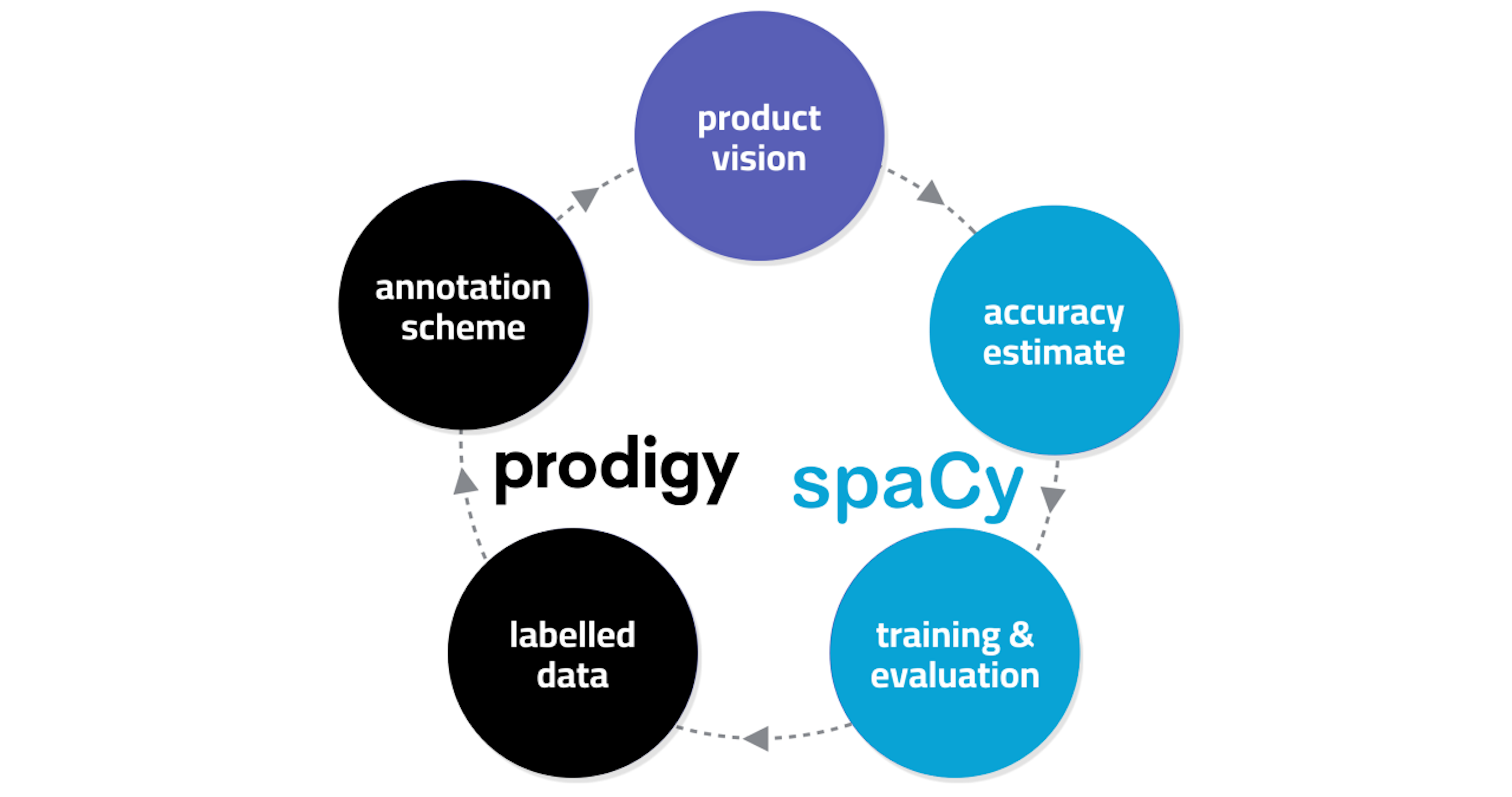
Setting your ML project up for success“What can you do to maximize probability of success for your Machine Learning solution? Throughout my 15 years as data scientist in academia, big pharma and through consulting, one common theme has emerged: the most reliable predictor of success for any NLP or ML-based solution is whether or not you involve the data science team early on.”
Spancat: a new approach for span labelingThe SpanCategorizer is a spaCy component that answers the NLP community's need to have structured annotation for a wide variety of labeled spans, including long phrases, non-named entities, or overlapping annotations. In this blog post, we're excited to talk more about spancat and showcase new features to help with your span labeling needs!
Introducing spaCy v3.2spaCy v3.2 features usability improvements for custom training and scoring, improved performance and support for floret, our new fastText word vectors algorithm.
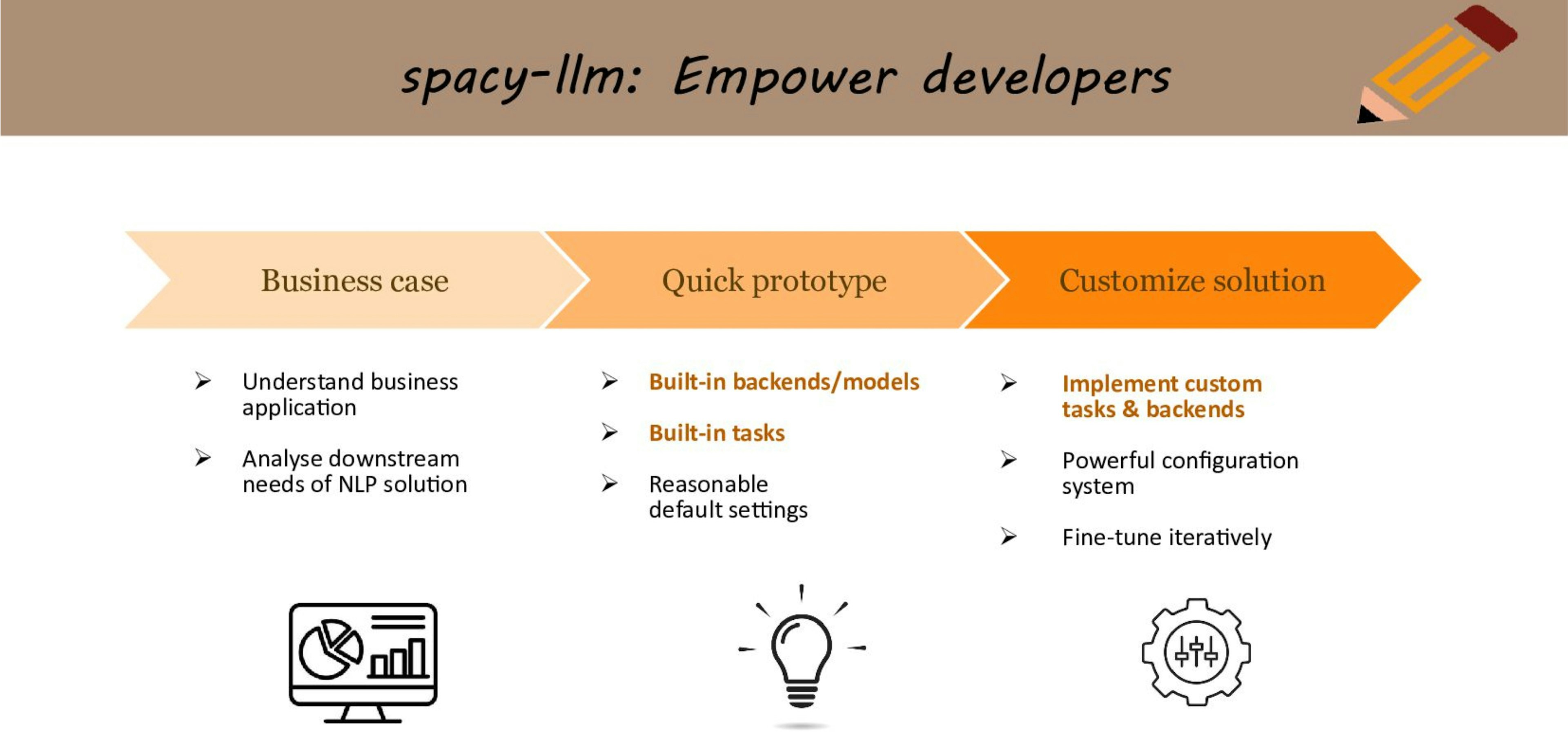
spacy-llm: From quick prototyping with LLMs to more reliable and efficient NLP solutionsAstraZeneca NLP Community of PracticeLLMs are paving the way for fast prototyping of NLP applications. Here, Sofie showcases how to build a structured NLP pipeline to mine clinical trials, using spaCy and spacy-llm. Moving beyond a fast prototype, she offers pragmatic solutions to make the pipeline more reliable and cost efficient.
The Tale of Bloom Embeddings and Unseen EntitiesThe default Bloom embedding layer in spaCy is unconventional, but very powerful and efficient. We wrote about it before and showed the advantages it provides in terms of memory efficiency for our floret embeddings. Now we have released the first technical report by Explosion, where we explain Bloom embeddings in more detail and rigorously compare them to traditional embeddings. In this post we'll highlight some of our results with a special focus on unseen entities.
Multi hash embeddings in spaCyMiranda, Kádár, Boyd, Van Landeghem, Søgaard, Honnibal (2022)In this technical report we lay out a bit of history and introduce the embedding methods in spaCy in detail. Second, we critically evaluate the hash embedding architecture with multi-embeddings on Named Entity Recognition datasets from a variety of domains and languages. The experiments validate most key design choices behind spaCy’s embedders, but we also uncover a few surprising results.
Diary of a spaCy project: Predicting GitHub TagsMany people assume that working on an NLP project involves a lot of machine learning. Our experience is that it's much less about flowing tensors, and more about making a tailored solution. This blogposts demonstrates how a typical spaCy project could be initiated, implemented and executed towards a custom solution.
Introducing spaCy v3.1It’s been great to see the adoption of spaCy v3, which introduced transformer-based pipelines, a new training system and more. Version 3.1 adds more on top of it, including the ability to use predicted annotations during training, a component for predicting arbitrary and overlapping spans and new pipelines for Catalan and Danish.
Introducing spaCy v3.6spaCy v3.6 introduces the span finder component and trained pipelines for Slovenian.
Introducing spaCy v3.5spaCy v3.5 introduces new CLI commands, fuzzy matching, improvements for entity linking and more.
End-to-end Neural Coreference Resolution in spaCyCoreference resolution is the problem of resolving entities in texts to references such as pronouns. Even if you've never heard of it, it's something we all do constantly every day, and is a key to understanding natural language. We recently added an experimental implementation of an end-to-end neural coreference component to spaCy. This post explains the architecture of our model in detail.
Introducing spaCy v3.3spaCy v3.3 improves the speed of core pipeline components, adds a new trainable lemmatizer, and introduces trained pipelines for Finnish, Korean and Swedish.
spaCy v3: Custom trainable relation extraction componentspaCy v3.0 features new transformer-based pipelines that get spaCy’s accuracy right up to the current state-of-the-art, and a new training config and workflow system to help you take projects from prototype to production. In this video, Sofie shows you how to apply all these new features when implementing a custom trainable component from scratch.
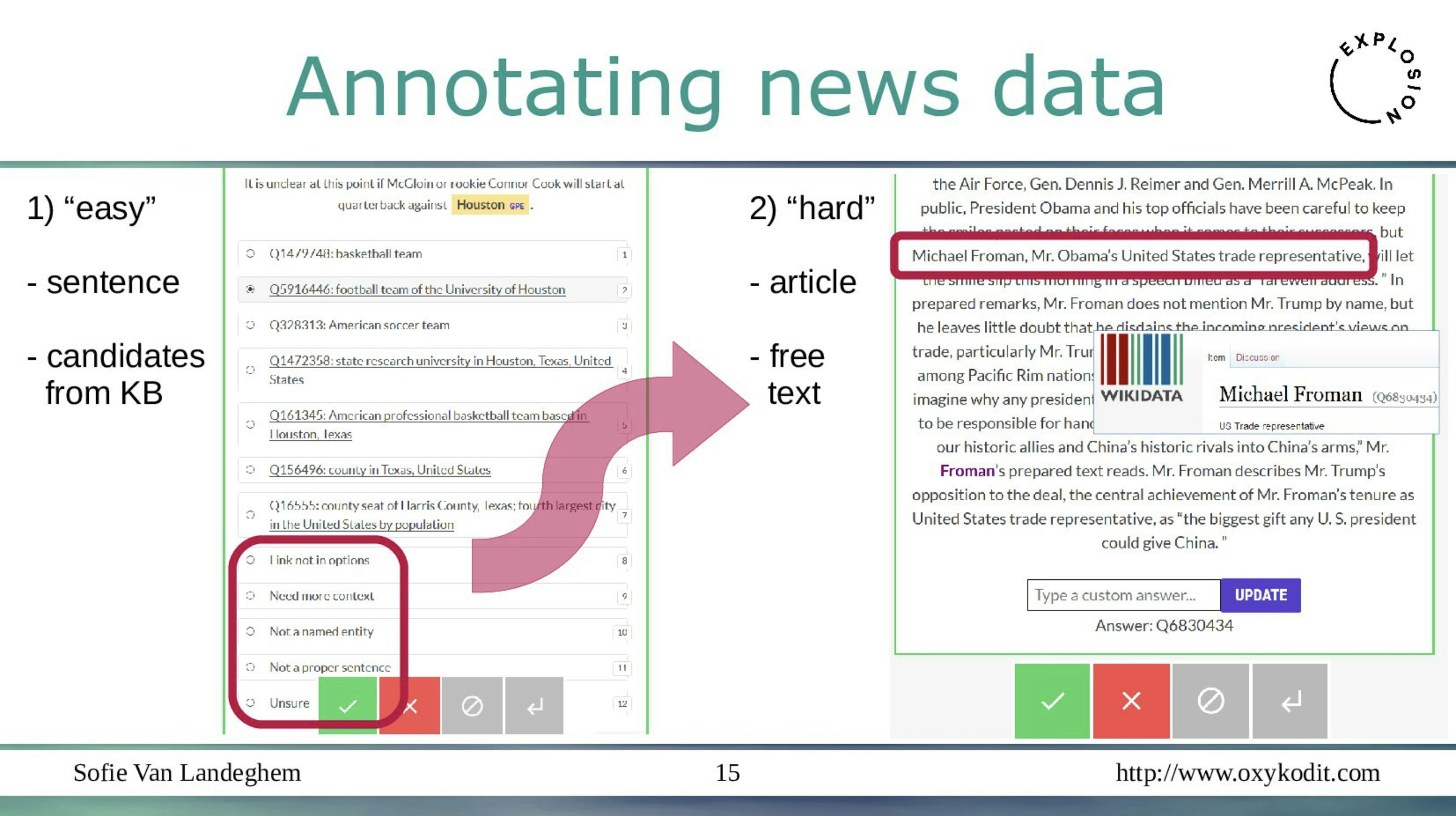
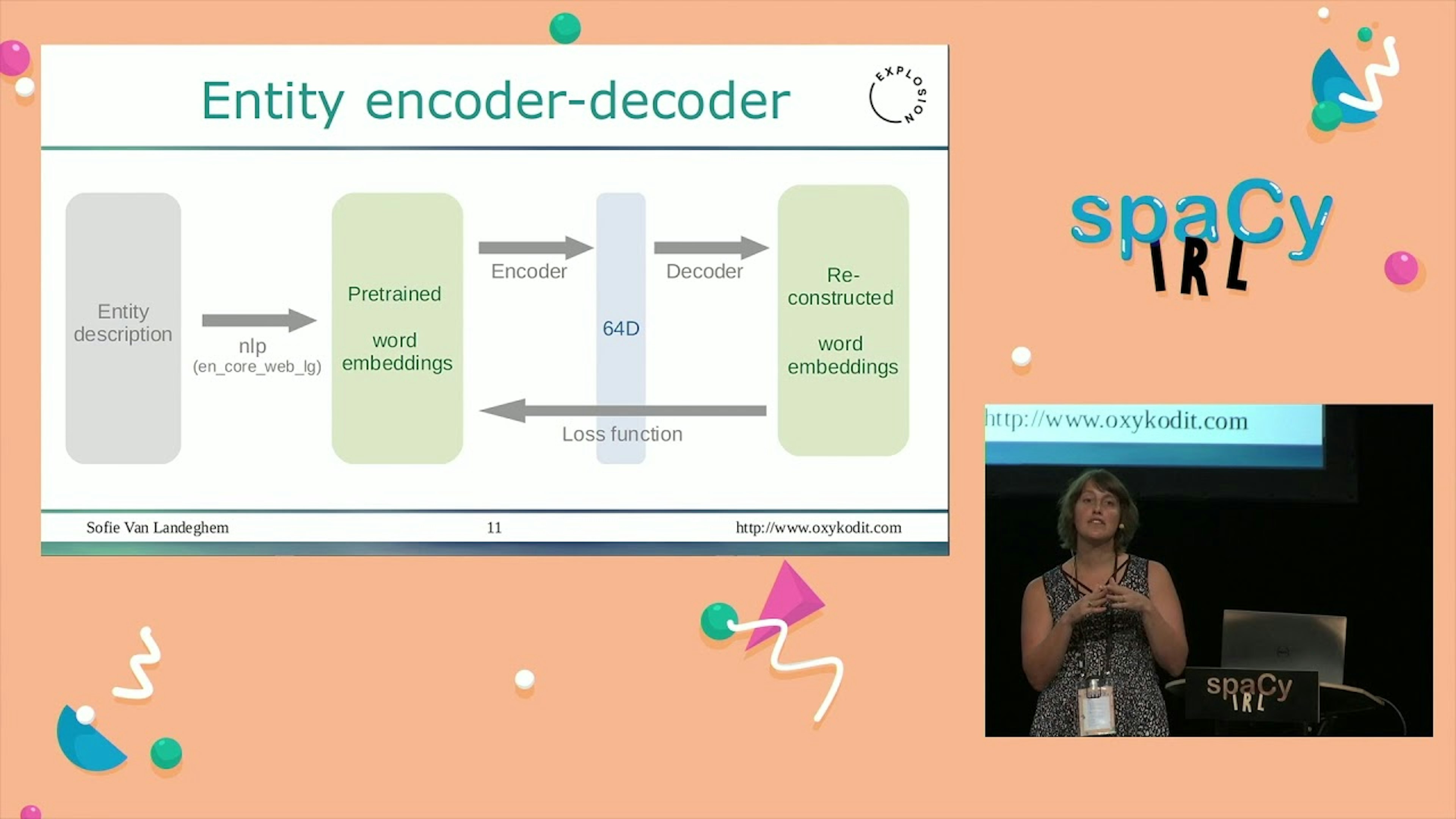
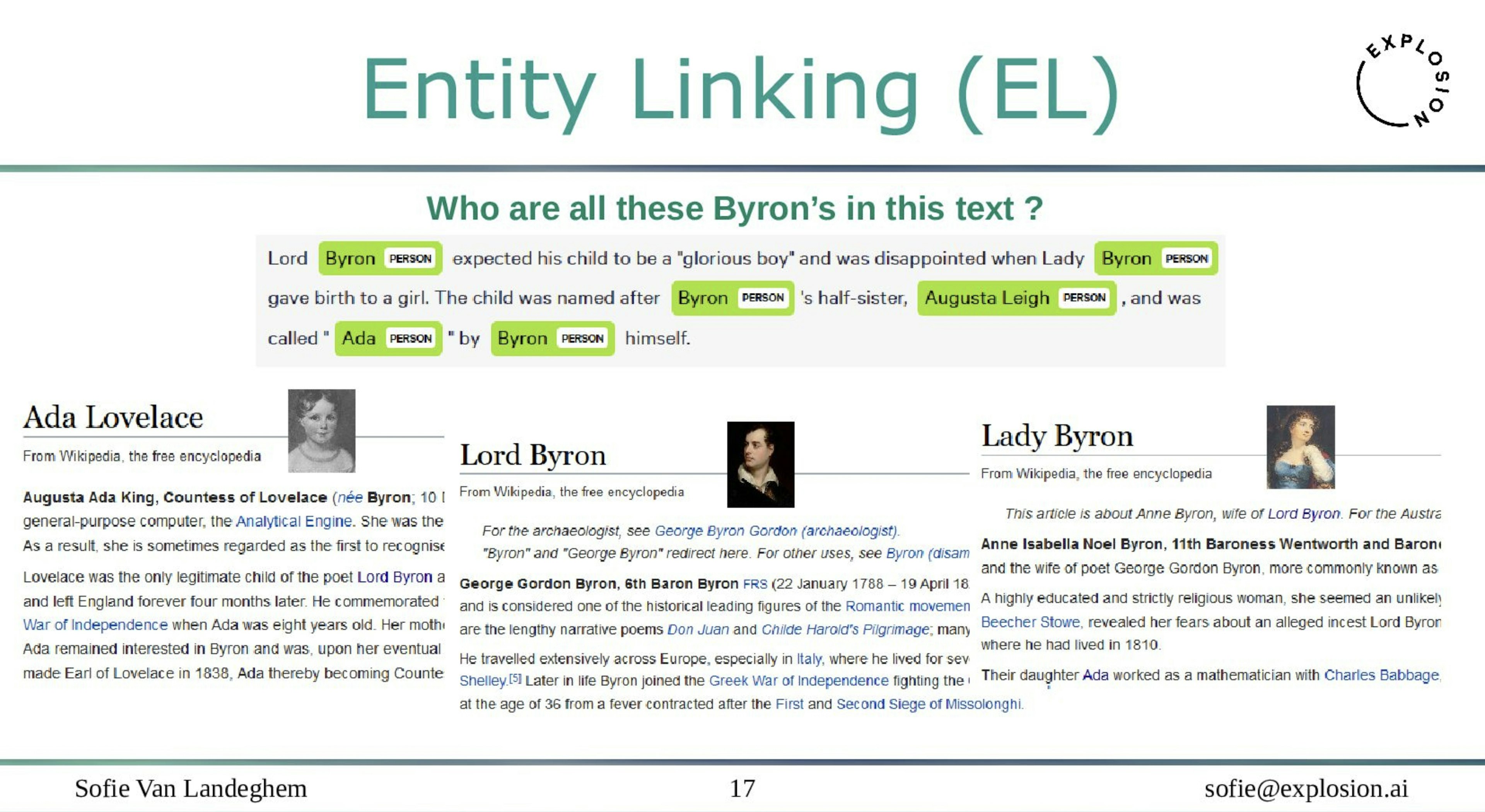
Training a custom entity linking model with spaCyIn this video, we show you how to create a custom Entity Linking model in spaCy to disambiguate different mentions of the person “Emerson” to unique identifiers in a knowledge base.