Mastering spaCyDéborah Mesquita, Duygu Altinok (Packt Publishing, 2025)Build structured NLP solutions with custom components and models powered by LLMs. By end of the book you will be empowered to build robust NLP pipelines and integrate them with web applications to build end-to-end solutions.
🦙 spacy-llm v0.3.0Jun 14, 2023Cohere, Anthropic, OpenLLaMa, StableLM, logging, streamlit demo, lemmatization task
Introducing spaCy v3.3spaCy v3.3 improves the speed of core pipeline components, adds a new trainable lemmatizer, and introduces trained pipelines for Finnish, Korean and Swedish.
Mastering spaCyDuygu Altinok (Packt Publishing, 2021)An end-to-end practical guide to implementing NLP applications using the Python ecosystem. By the end of this book, you'll be able to confidently use spaCy, including its linguistic features, word vectors, and classifiers, to create your own NLP apps.
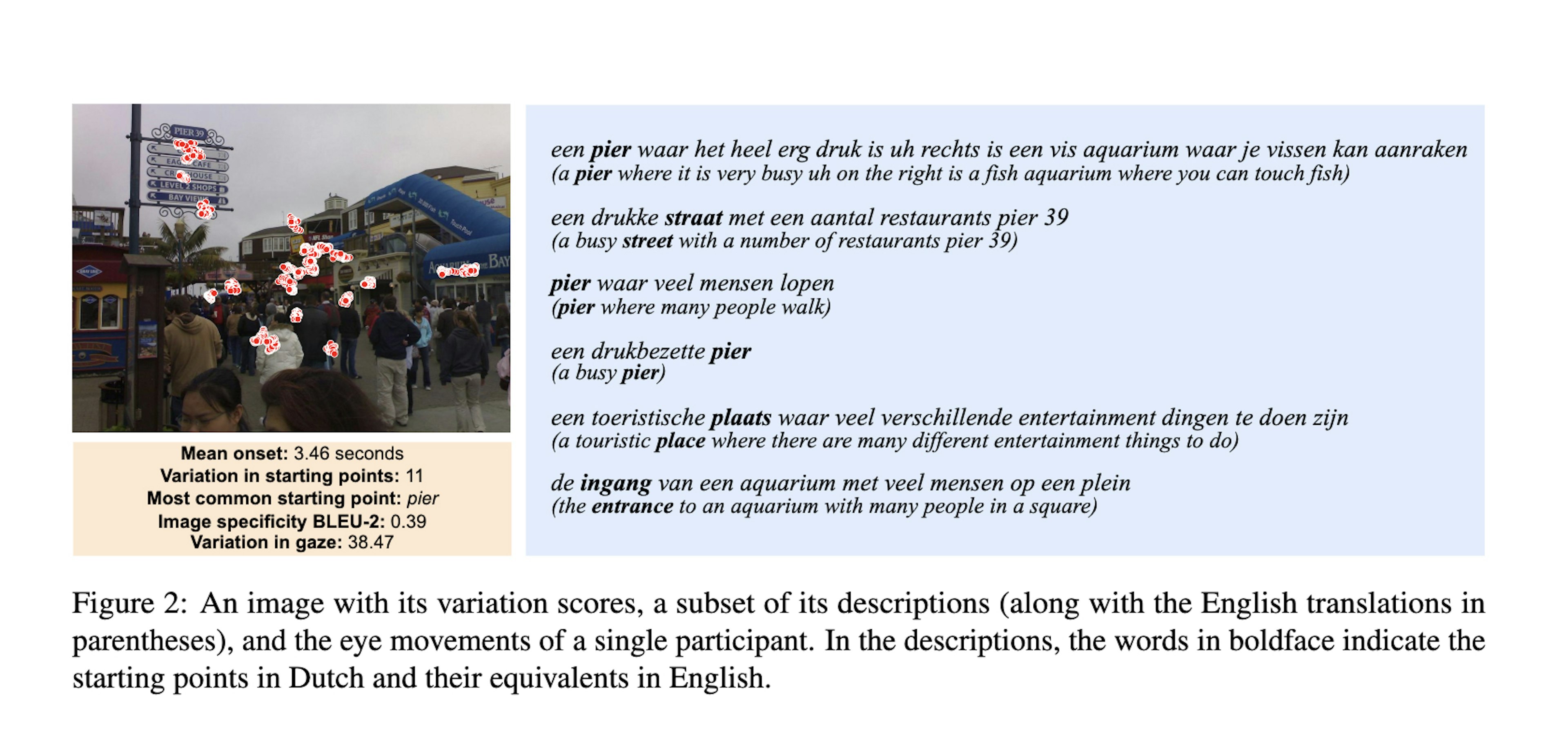
Describing Images Fast and Slow: Quantifying and Predicting the Variation in Human Signals during Visuo-Linguistic ProcessesTakmaz, Pezzelle, Fernández (2024)We use the spaCy library for tokenization, part-of-speech tagging, and lemmatization of the words in the descriptions.
Universal Dependencies v2.5 Benchmarks for spaCyWe present Universal Dependencies v2.5 benchmarks for spaCy v3.2 that show the competitive performance of spaCy in a direct comparison with Stanza and Trankit using the end-to-end evaluation from the CoNLL 2018 Shared Task.
Neural edit-tree lemmatization for spaCyWe are happy to introduce a new, experimental, machine learning-based lemmatizer that posts accuracies above 95% for many languages. This lemmatizer learns to predict lemmatization rules from a corpus of examples and removes the need to write an exhaustive set of per-language lemmatization rules.
How Good is the Model in Model-in-the-loop Event Coreference Resolution Annotation?Ahmed, Nath, Regan, Pollins, Krishnaswamy, Martin (2023)Figure 6 illustrates the interface design of the annotation methodology on the popular model-in-the-loop annotation tool - Prodigy. We use this tool for the simplicity it offers in plugging in the various ranking methods we explained.
Introduction to Japanese Natural Language ProcessingMasato Hagiwara, Paul O’Leary McCann (2021)A thorough guide for programmers working with Japanese text, covering fundamental issues like tokenization and recent research topics like generating natural language texts.