Building Multimodal Corpora Using Microtask Pipelines and Local AnnotatorsHotti, Vázquez, Jokipohja, Kalliokoski, Paakki, Suviranta, Hiippala (2026)To create the infrastructure needed for supporting this effort, we repurpose an existing commercial annotation tool, Prodigy, which we then enhance with additional components for combining the annotation tasks into pipelines, cross-validating the annotations and supporting annotator access to tasks.
📚 spacy-layout v0.0.12Mar 8, 2025Support processing PDFs with context, add document index tables and more docs
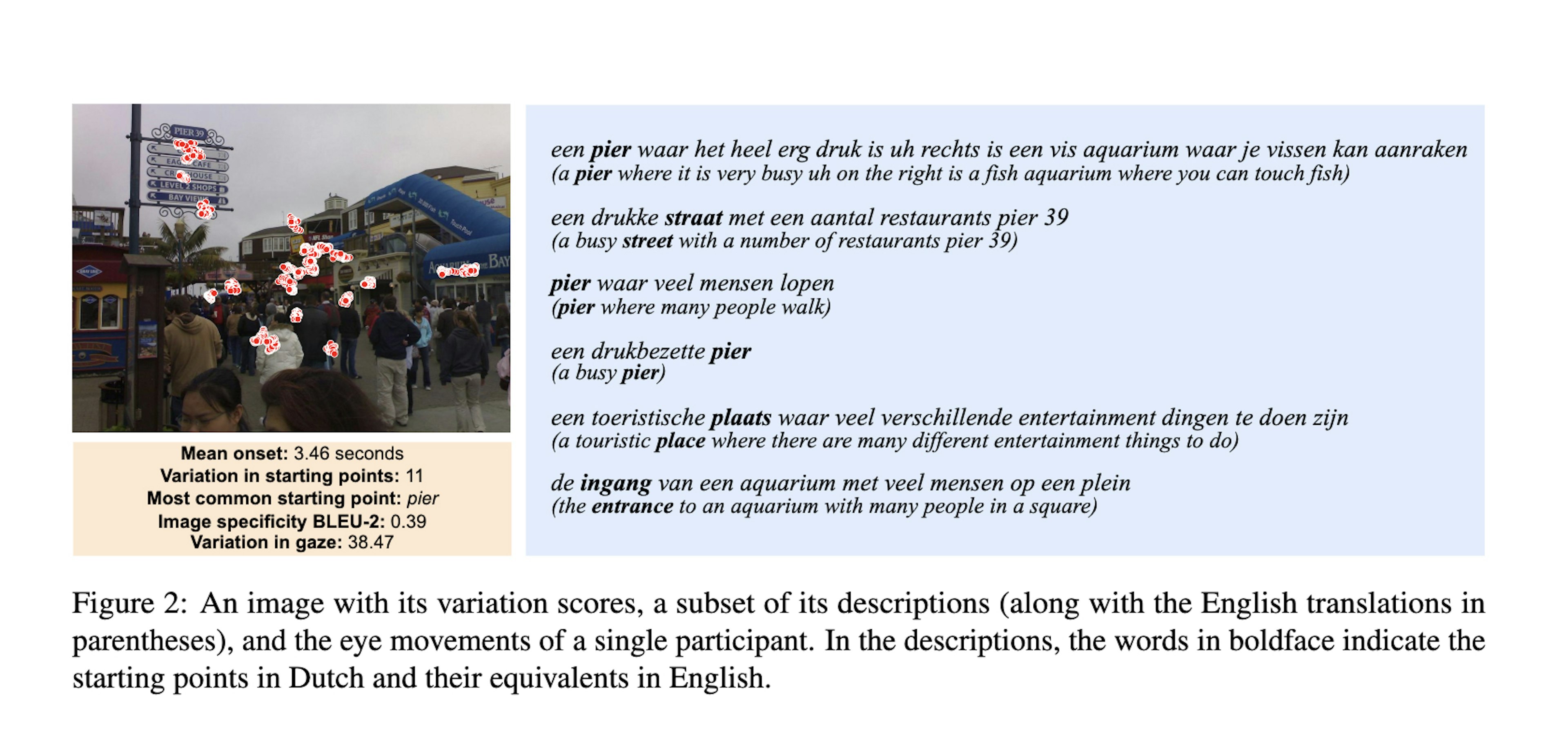
Describing Images Fast and Slow: Quantifying and Predicting the Variation in Human Signals during Visuo-Linguistic ProcessesTakmaz, Pezzelle, Fernández (2024)We use the spaCy library for tokenization, part-of-speech tagging, and lemmatization of the words in the descriptions.
Conquering PDFs: document understanding beyond plain textPyData LondonIn this talk, Ines presents a new and modular approach for building robust document understanding systems, using state-of-the-art models and the awesome Python ecosystem.
Microsoft Presidio v2.2.352Context aware, pluggable and customizable PII de-identification and anonymization service for text and images, featuring a spaCy back-end.
Conquering PDFs: document understanding beyond plain textPyCon DE & PyDataIn this talk, Ines presents a new and modular approach for building robust document understanding systems, using state-of-the-art models and the awesome Python ecosystem.
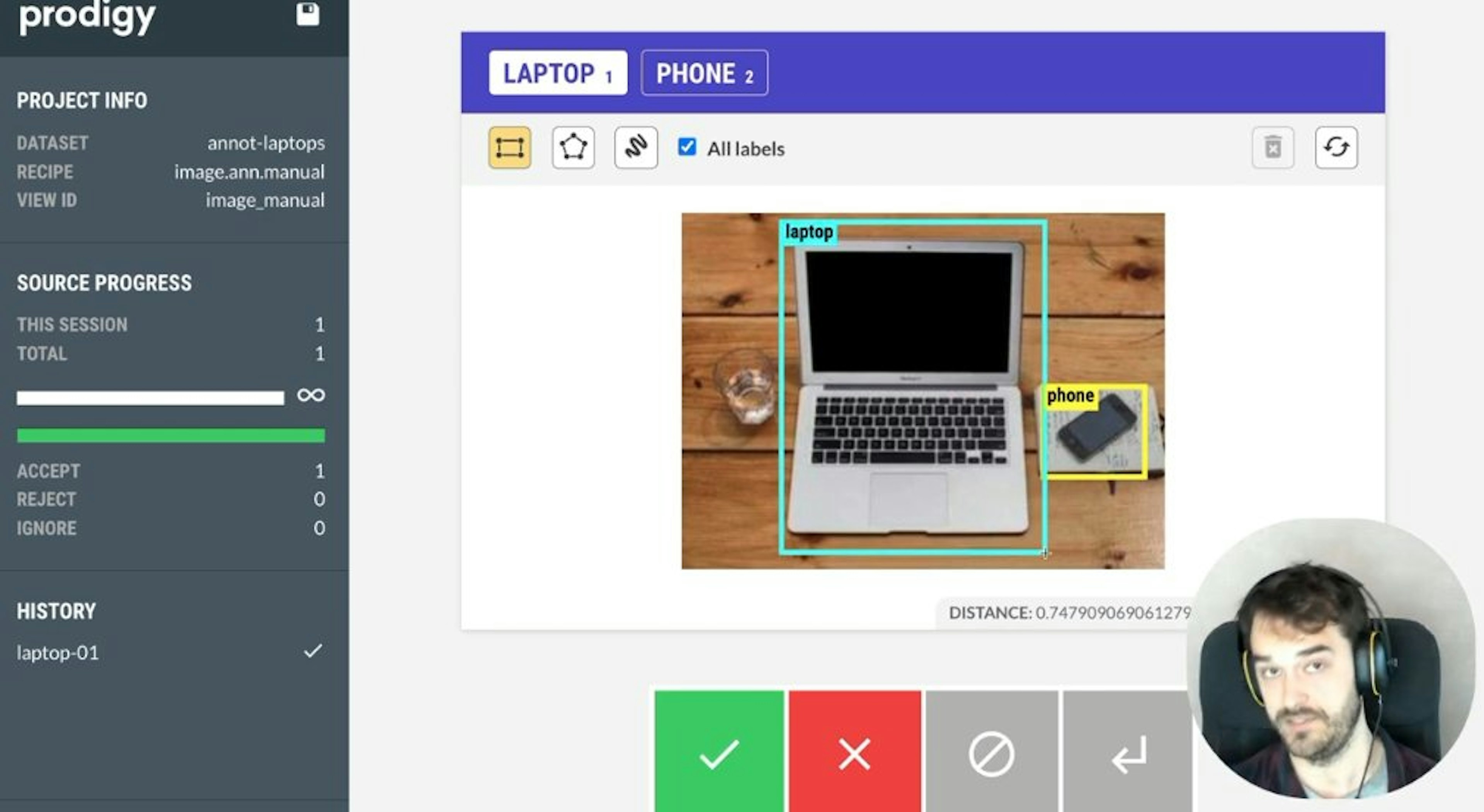
Prodigy-ANN for Image Retrieval via CLIPDealing with a huge bucket of images that you want to annotate? The new image retrieval features in Prodigy-ANN (approximate nearest neighbors) might help!
From PDFs to AI-ready structured data: a deep diveThis blog post presents a new modular workflow for converting PDFs and similar documents to structured data and shows you how to build end-to-end document understanding and information extraction pipelines for industry use cases.
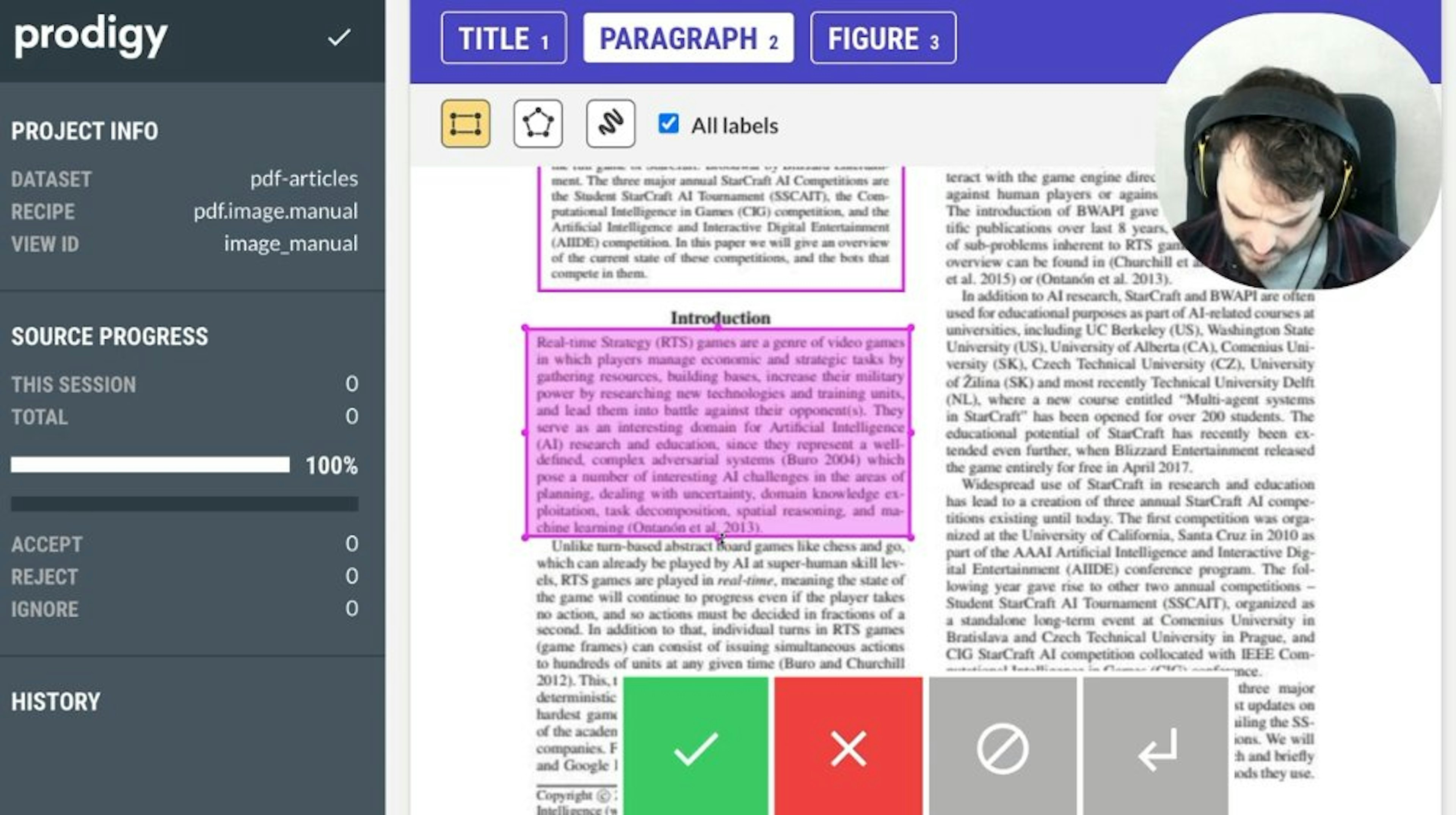
Prodigy-PDF for PDF annotation and OCRWant to annotate PDF files? Our new Prodigy plugin can help with that! To explain how to use PDF segmentation and OCR, Vincent made a small demo video.