The ultimate guide to optimizing annotation workflowsThis blog post collects tips and advice for how to build efficient human-in-the-loop data development workflows, break down business problems into actionable annotation steps and make the most of automation and model assistance.
Herding LLMs Towards Structured NLPGlobal AI ConferenceThis talk shows how we integrate LLMs into spaCy, leveraging its modular and customizable framework. This allows for cheaper, faster and more robust NLP - driven by cutting-edge LLMs, without compromising on having structured, validated data.
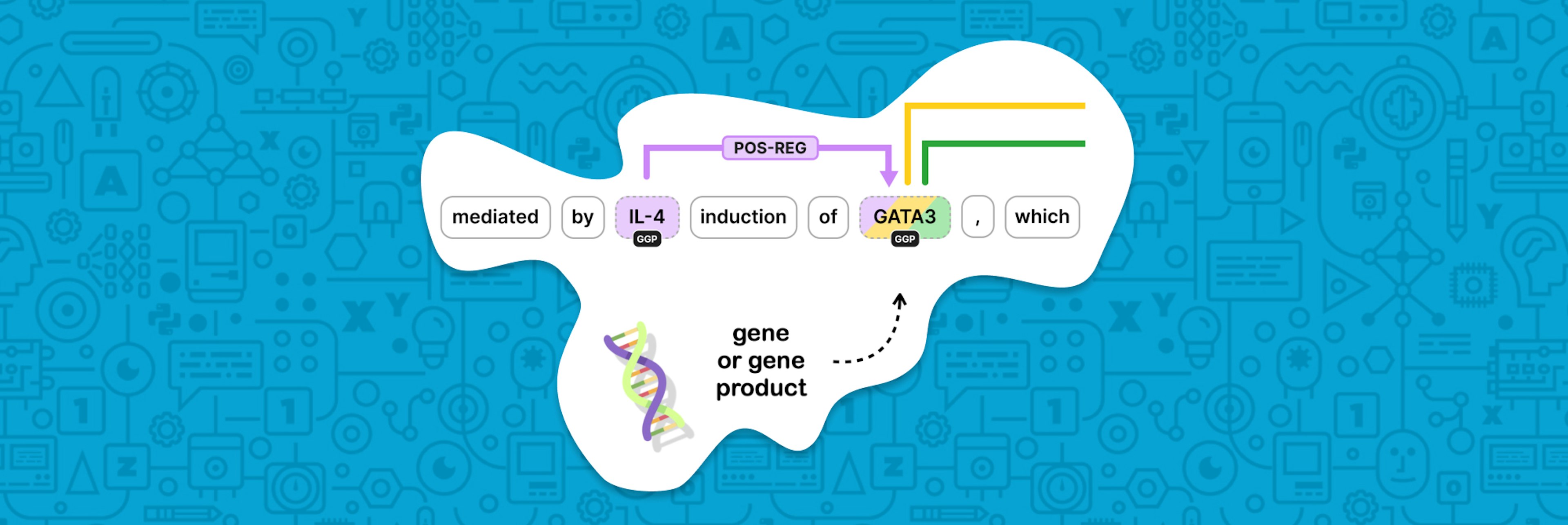
Implementing a custom trainable component for relation extractionRelation extraction refers to the process of predicting and labeling semantic relationships between named entities. In this blog post, we'll go over the process of building a custom relation extraction component using spaCy and Thinc. We'll also add a Hugging Face transformer to improve performance at the end of the post. You'll see how you can utilize Thinc's flexible and customizable system to build an NLP pipeline for biomedical relation extraction.
RiCoRecA: rich cooking recipe annotation schemaVentirozos, Jacob-Romero, Alrdahi, Clinch, Batista-Navarro (2026)The annotation process consists of two sections. Firstly, the annotator utilized a customized Prodigy interface to complete the NER and RC annotation tasks.
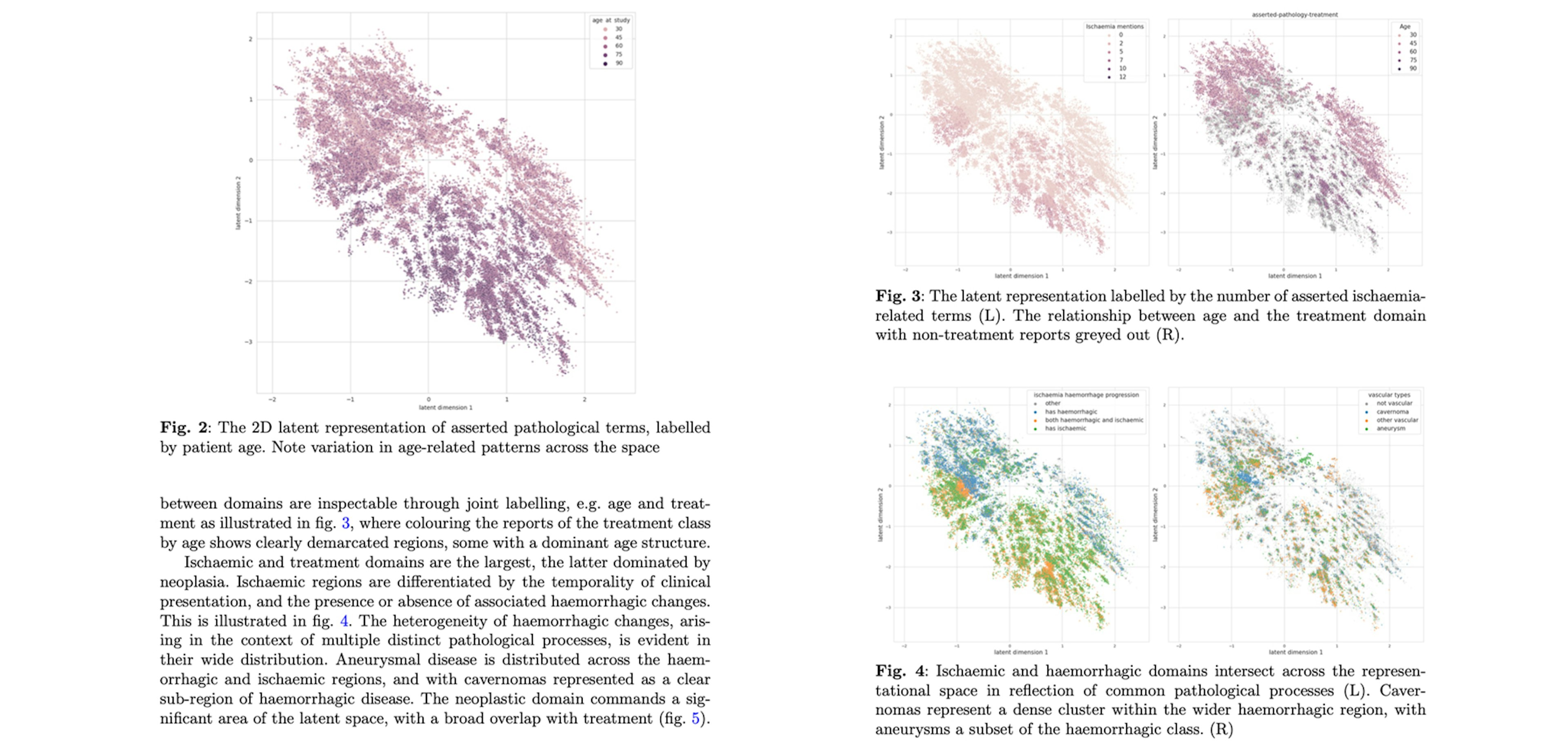
Neuradicon: operational representation learning of neuroimaging reportsWatkins, Gray, Julius, Mah, Pinaya, Wright, Jha, Engleitner, Cardoso, Ourselin, Rees, Jaeger, Nachev (2023)Labelled data for each task was produced using the Prodigy labelling tool. Each report was labelled in a paired-annotation manner. [...] We used the grammatical dependency parse produced by the spaCy parser as input and implemented the patterns using the spaCy dependency matcher.
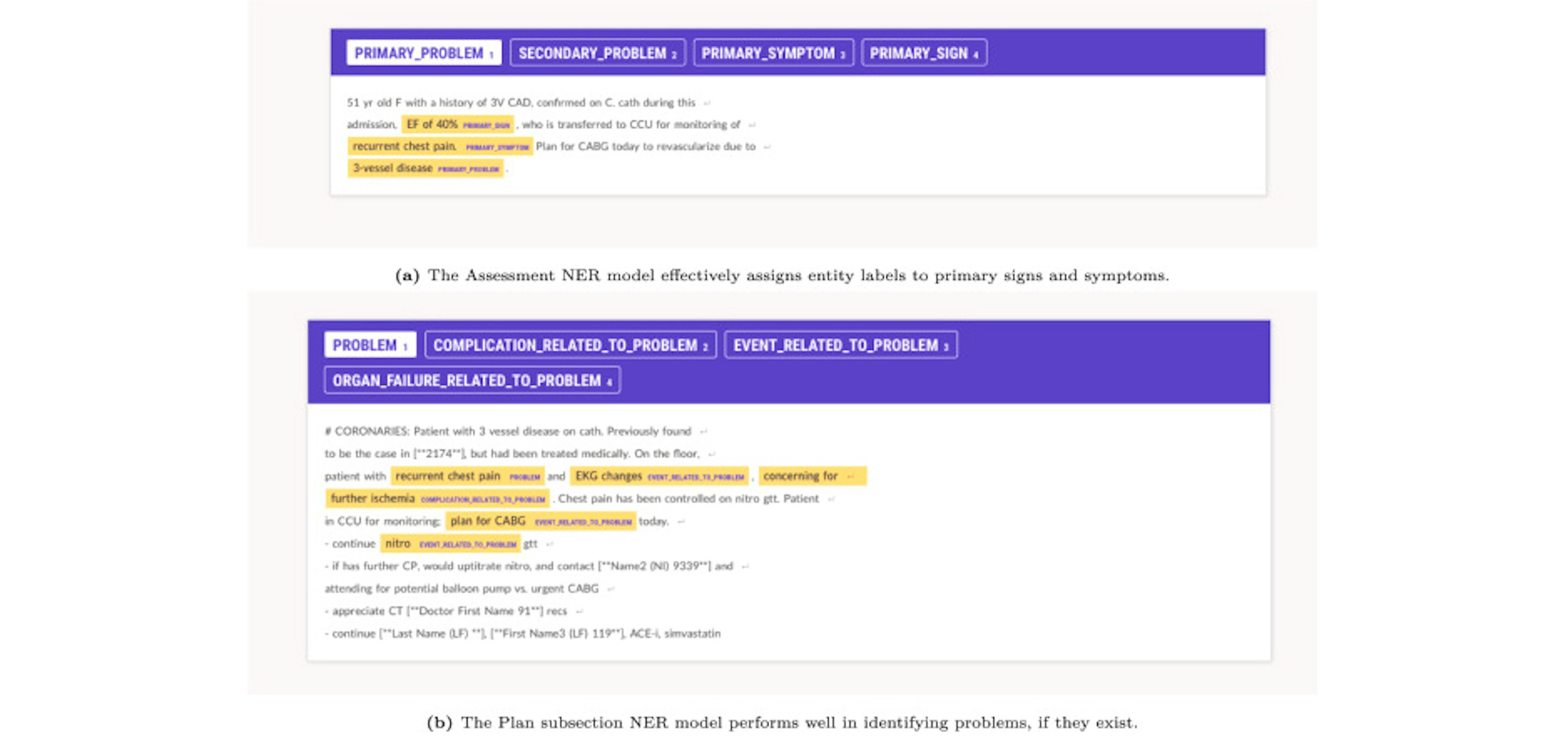
Predicting relations between SOAP note sections: The value of incorporating a clinical information modelSocrates, Gilson, Lopez, Chi, Taylor, Chartash (2023), Journal of Biomedical InformaticsTo support human annotation, we first annotate 100 Assessment and Plan subsections manually using Prodigy, and then use spacy-transformers to fine-tune a general domain RoBERTa-base model pretrained on OntoNotes 5 for both the Assessment and Plan section NER tagging.
✨ prodigy v1.10.0Jun 16, 2020Dependency and relation annotation, audio, video, character-based NER & more
How to uncover and avoid structural biases in evaluating your Machine Learning/NLP projectsPyData LondonThis talk highlights common pitfalls that occur when evaluating ML and NLP approaches. It provides comprehensive advice on how to set up a solid evaluation procedure in general, and dives into a few specific use-cases to demonstrate artificial bias that unknowingly can creep in.
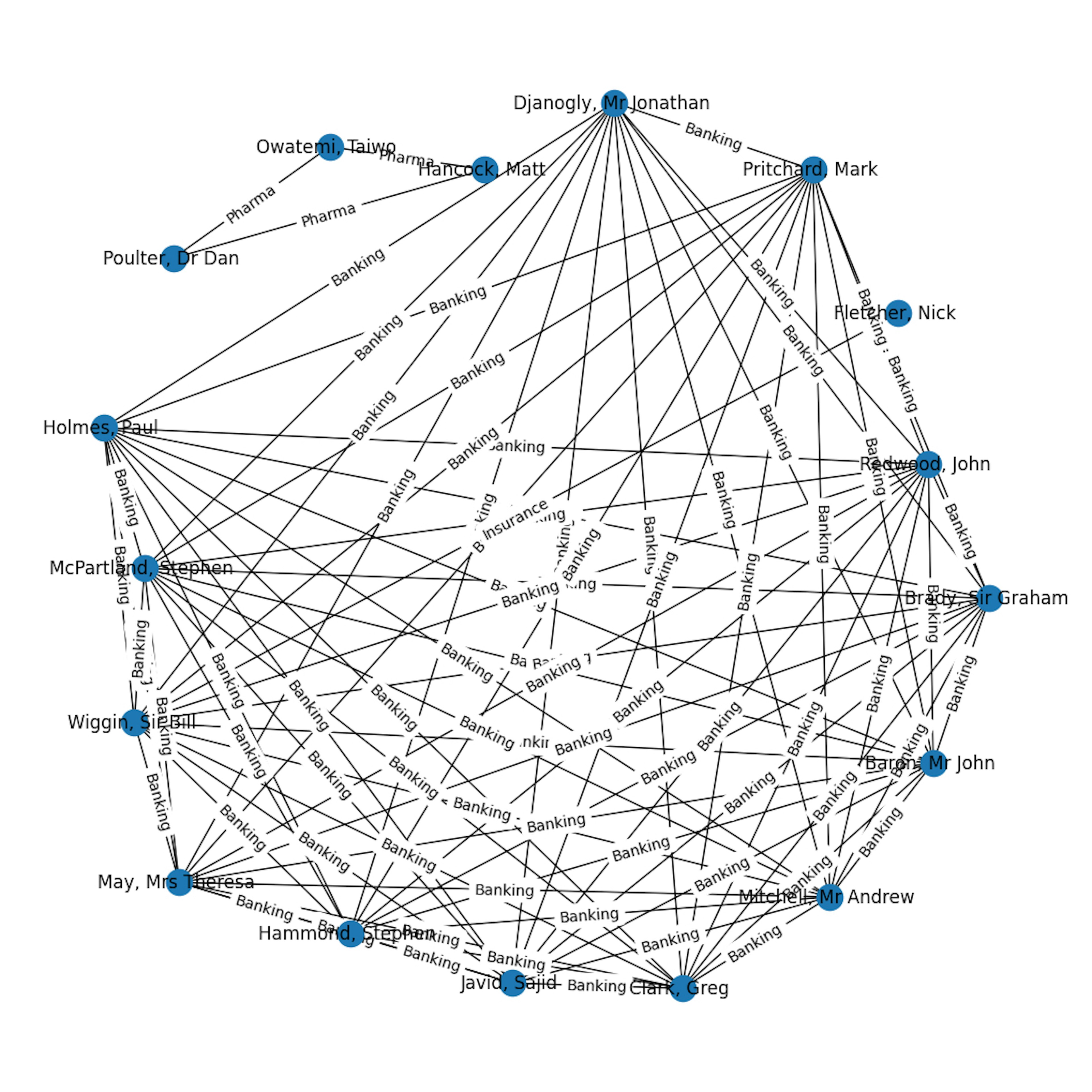
MP Interests Tracker: Utilising GenAI to uncover insights in the UK Register of Financial InterestJournalismAI BlogProject from teams at The Times and BBC using spacy-llm to make complex financial interests data more accessible.
spaCy v3: Custom trainable relation extraction componentspaCy v3.0 features new transformer-based pipelines that get spaCy’s accuracy right up to the current state-of-the-art, and a new training config and workflow system to help you take projects from prototype to production. In this video, Sofie shows you how to apply all these new features when implementing a custom trainable component from scratch.
spacy-llm: From quick prototyping with LLMs to more reliable and efficient NLP solutionsAstraZeneca NLP Community of PracticeLLMs are paving the way for fast prototyping of NLP applications. Here, Sofie showcases how to build a structured NLP pipeline to mine clinical trials, using spaCy and spacy-llm. Moving beyond a fast prototype, she offers pragmatic solutions to make the pipeline more reliable and cost efficient.
Concepts and measures of bureaucratic constraints in European Union laws from hand-coding to machine-learningFranchino, Migliorati, Pagano, Vignoli (2023)The models “learn” the relations between the text tokens and the entity categories from two randomly selected samples of sentences that are extracted from a pre-processed corpus and have been manually annotated using the Python-implemented platform “Prodigy”.
Prodigy v1.10: Dependencies, relations, audio, video & moreVersion 1.10 of Prodigy includes tons of new features, including manual dependency and relation annotation, audio and video annotation, a new and improved image UI, new recipe callbacks, more settings for manual NER, plus various new config options and settings.