
- 11 minute read
- Blog
- spaCy
- Embeddings & Vectors


floret is an extended version of fastText that uses Bloom embeddings to create compact vector tables with both word and subword information. floret brings fastText’s subwords into spaCy pipelines with vectors that are up to 10× smaller than traditional word vectors.
In this blog post, we’re going to dive deeper into these vectors. We’ll explain how they work and show when they’re helpful. If you’re already familiar with how floret works, jump ahead to the comparison of fastText vs. floret.
Vector tables
For many vector tables, including the default vectors in spaCy, the vector table contains entries for a fixed list of words, typically the most common words from the training data. The vector table will have entries for words like newspaper and newspapers, which will be similar vector-wise, but each stored as a completely separate row in the table.
Because the vector table has a limited number of words, at some point you’ll run into infrequent, novel or noisy words like newsspaper or doomscrolling that weren’t seen during training. Typically there’s a special unknown vector that’s used for these words, which in spaCy is an all-zero vector. As a result, while the vectors for newspaper and newspapers are similar, the vector for newsspaper looks completely different, plus its all-zero vector makes it look similar to every other unknown word like AirTag or someverylongdomainname.com.
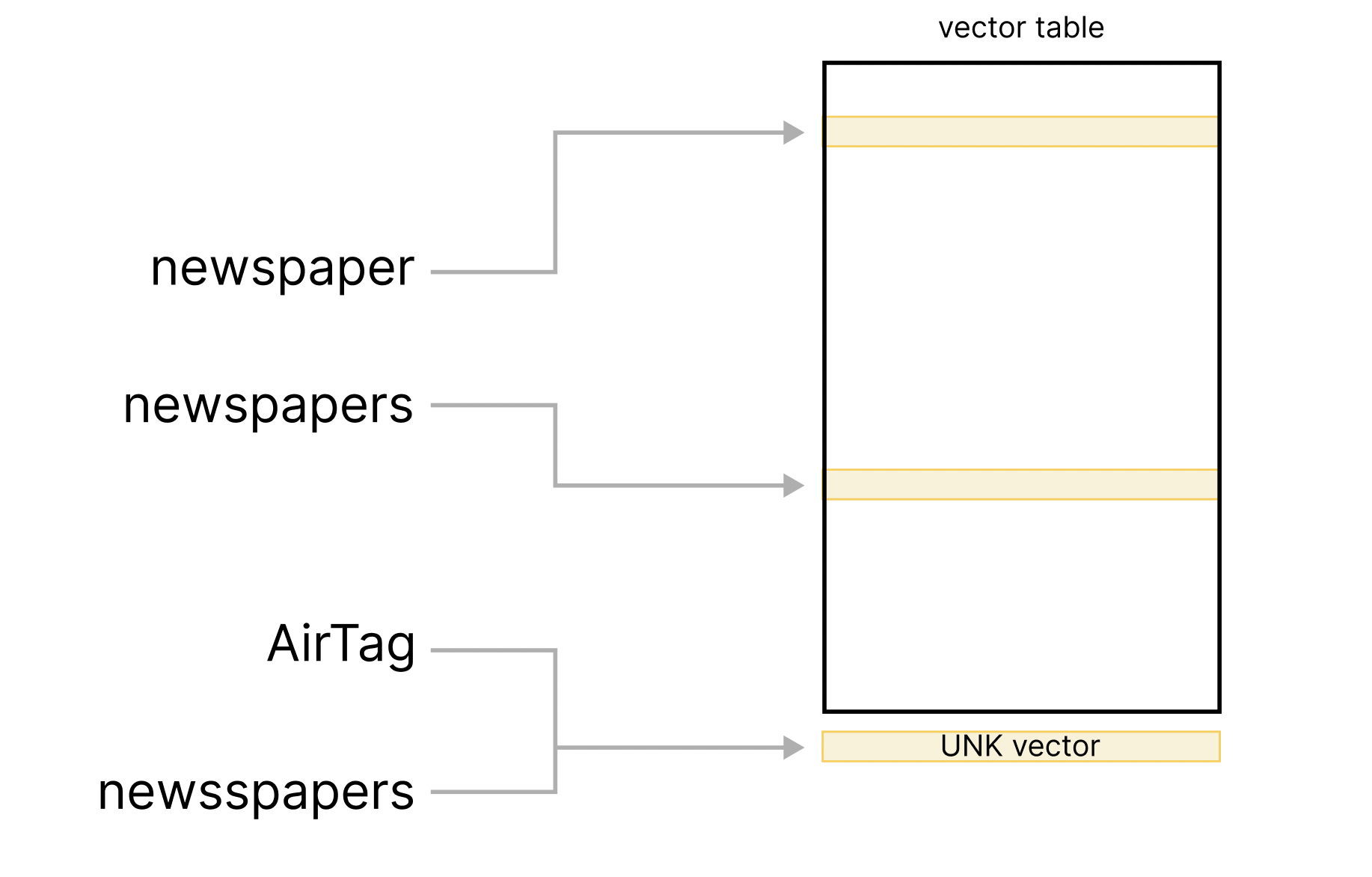
One option for providing more useful vectors for both known and unknown words is
to incorporate subword information, since subwords like news and paper can
be used to relate the vector for a word like newspaper to both known words
like newspapers and unknown words like newsspaper. We’ll take a look at how
fastText uses subword information, explain how floret extends fastText to keep
vector tables small, and explore the advantages of floret vectors.
Vectors with subword information
fastText uses character n-gram subwords: a
word’s final vector is the average of the vector for the full word and the
vectors for all of its subwords. For example, the vector for apple with 4-gram
subwords would be the average of the vectors for the following strings (<
and > are added as word boundary characters):
<apple>,<app,appl,pple,ple>
fastText also supports a range of n-gram sizes, so with 4-6-grams, you’d have:
<apple>,<app,appl,pple,ple>,<appl,apple,pple>,<apple,apple>
By using subwords, fastText models can provide useful vectors for previously
unseen tokens like newsspapers by using subwords like <news and paper.
Instead of having a single UNK-vector, fastText models with subwords can
provide better representations for infrequent, novel and noisy words.
There are many cases that benefit from subword information:
Case 1: Words with many suffixes
Languages like Finnish, Hungarian, Korean or Turkish can build words by adding a large number of suffixes to a single stem.
Hungarian
kalap+om+at (‘hat’ + POSSESSIVE + CASE: ‘my hat’, accusative)
For example, a Hungarian noun can have up to five suffixes related to number, possession and case. Just for example above with exactly two suffixes, there are 6 possessive endings (singular/plural × 1st/2nd/3rd person) and 18 cases, leading to 108 different forms of kalap, compared to English where the only two forms in a vector table would be hat and hats.
Case 2: Words with many inflections
Some languages have a large number of inflected forms per stem.
Finnish
Inflected forms of valo (‘light’) include: valo, valon, valoa, valossa, valosta, valoon, valoon, valolla, valolta, valolle, … and we haven’t even gotten to the plural forms yet.
In Finnish, many inflected form of nouns correspond to phrases that would use
prepositions in English, such as ‘in the light’, ‘with the light’, ‘as a light’,
‘of the lights’, etc. So while English vectors would need two entries for
‘light’ and ‘lights’, the Finnish vectors might have 20+ entries for different
forms of ‘light’ and you typically wouldn’t see all possible forms of each word
in your training data. Subwords that capture parts of the stem like valo and
suffixes like lle> can help provide more meaningful vectors for previously
unseen words.
Case 3: Long compounds
Some languages like German and Dutch form compounds by building very long single words.
German
Bundesausbildungsförderungsgesetz (‘Federal Education and Training Assistance Act’)
Long compounds can often be novel or very infrequent, so subwords for each unit in the compound improve the vectors, e.g. for Bund, ausbild, förder, gesetz (‘federal’, ‘education’, ‘assist’, ‘law’).
Case 4: Misspellings and new words
English
univercities (vs. universities), apparrently (vs. apparently)
tweetstorm, gerrymeandering
Noisy and novel words contain subwords that overlap with related known words like apparent, university and gerrymander.
Adding subword support in spaCy
Internally fastText stores word and subword vectors in two separate, large
tables. The .vec file that’s typically imported into a spaCy pipeline is only
the word table, so although subwords might have been used while training
fastText vectors, a default spaCy pipeline only ends up supporting the
fixed-size vocabulary from the word table and not out-of-vocabulary tokens
through subwords.

One possibility would be to directly support the large subword table in spaCy, but this would bloat spaCy pipelines to 2GB+ for typical configurations. Since this is impractical, we turn to an approach that’s already used by Thinc and spaCy: Bloom embeddings. With Bloom embeddings we can both support subwords and greatly reduce the size of the vector table.
We implemented floret by extending fastText to add these two options:
- store both word and subword vectors in the same hash table

- hash each entry into more than one row to make it possible to reduce the size of the hash table

Let’s compare fastText and floret vectors and explore the advantages of compact floret vectors!
fastText vs. floret for in-vocabulary words
The biggest difference between fastText and floret is the size of the vector table. With floret, we’re going from 2-3 million vectors to <200K vectors, which reduces the size of the vectors from 3GB to <300MB. Do the floret vectors for known words look still similar to the original fastText vectors?
To compare directly, we trained fastText and floret vectors on the same English texts to be able to look at both word and subword vectors.
First, we’ll look at the cosine similarity for pairs of subwords in related and unrelated terms:

We can see that floret keeps the correlation between subtokens intact, despite
using a much smaller hashing table. Although the cosine similarities are closer
to 0 in general for the floret vectors, the heat maps show very similar patterns
for individual pairs of subwords like the dark red in the righthand example for
raphy and ology that indicate similarity between related suffixes or the
white for the unrelated subwords circu and osaur in the center example.
Next, we’ll look at the most similar words for known words.
Example: dinosaur
| fastText | score | floret | score |
|---|---|---|---|
| dinosaurs | 0.916 | dinosaurs | 0.886 |
| stegosaur | 0.890 | Dinosaur | 0.784 |
| dinosaurian | 0.888 | Dinosaurs | 0.758 |
| Carnosaur | 0.861 | dinosaurian | 0.728 |
| titanosaur | 0.860 | Carnosaur | 0.726 |
Example: radiology
| fastText | score | floret | score |
|---|---|---|---|
| teleradiology | 0.935 | Radiology | 0.896 |
| neuroradiology | 0.920 | teleradiology | 0.870 |
| Neuroradiology | 0.911 | Neuroradiology | 0.865 |
| radiologic | 0.907 | radiologic | 0.859 |
| radiobiology | 0.906 | radiobiology | 0.840 |
For all of these examples we can confirm that, while there are some differences between nearest neighbors from floret and the fastText ones, they still overlap more than they differ. So even though the floret embeddings are significantly smaller, it does appear like they still carry much of the same information as fastText.
floret for out-of-vocabulary words
A big advantage of floret vs. default spaCy vectors is that subwords can used to
create vectors for out-of-vocabulary words. The words newsspaper (should be
newspaper) and univercities (should be universities) are all examples of
misspelled words that do not appear in the embedding tables of en_core_web_lg.
That means that these words would all get the same 0-vector and the most “similar” words are all unrelated for default spaCy vectors. On the other hand, floret vectors are able to find nearest neighbors via the overlapping subtokens. The table below shows some examples.
Nearest neighbors for misspelled words with floret
| newsspaper | score | univercities | score |
|---|---|---|---|
| newspaper | 0.711 | universities | 0.799 |
| newspapers | 0.673 | institutions | 0.793 |
| Newspaper | 0.661 | generalities | 0.780 |
| paper | 0.635 | individualities | 0.773 |
| newspapermen | 0.630 | practicalities | 0.769 |
But spelling errors aren’t the only out-of-vocabulary words that you may encounter.
Nearest neighbors for unknown words with floret
| shrinkflation | score | biomatosis | score |
|---|---|---|---|
| inflation | 0.841 | carcinomatosis | 0.850 |
| Deflation | 0.840 | myxomatosis | 0.822 |
| Oblation | 0.831 | neurofibromatosis | 0.817 |
| stabilization | 0.828 | hemochromatosis | 0.815 |
| deflation | 0.827 | fibromatosis | 0.794 |
When you look at the nearest neighbors you may notice how floret is able to pick up on an important subword. In many cases this allows it to find related words, but other times it can overfit on it. The word “decapitation” overlaps with “shrinkflation” because of the “-ation” at the end. But that doesn’t imply that the two words have a similar meaning.
You can explore floret vectors for English further in this colab notebook!
Default vs. floret vectors in spaCy
Comparing default word-only fastText vectors vs. floret vectors for UD English EWT, we see that the performance is very similar for both types of vectors for English:
UD English EWT for default vs. floret
| Vectors | TAG | POS | DEP UAS | DEP LAS |
|---|---|---|---|---|
en_vectors_fasttext_lg (500K vectors/keys) | 94.1 | 94.7 | 83.5 | 80.0 |
en_vectors_floret_lg (200K vectors; minn 5, maxn 5) | 93.9 | 94.5 | 83.8 | 80.2 |
Other languages with more complex morphology than English see much more noticeable differences with floret, with Korean as the highlight of our experiments so far, where floret vectors outperform much larger default vectors by wide margins.
UD Korean Kaist for default vs. floret vectors
| Vectors | TAG | POS | DEP UAS | DEP LAS |
|---|---|---|---|---|
| default (800K vectors/keys) | 79.0 | 90.3 | 79.4 | 73.9 |
| floret (50K vectors, no OOV) | 82.8 | 94.1 | 83.5 | 80.5 |
Try it out
floret vectors are supported in spaCy v3.2+ and since spaCy v3.3 we’ve started shipping trained pipelines that use these vectors. With spaCy v3.4, you can see floret vectors in action in the provided trained pipelines for Croatian, Finnish, Korean, Swedish and Ukrainian.
Download floret vectors for English
We’ve published the English fastText and floret vector-only pipelines used in this post.
You can explore these vectors for English in this colab notebook!
You can install the prebuilt spaCy vectors-only pipelines with the following
commands and use these directly spacy train:
# en_vectors_fasttext_lgpip install https://github.com/explosion/spacy-vectors-builder/releases/download/en-3.4.0/en_vectors_fasttext_lg-0.0.1-py3-none-any.whl# en_vectors_floret_mdpip install https://github.com/explosion/spacy-vectors-builder/releases/download/en-3.4.0/en_vectors_floret_md-0.0.1-py3-none-any.whl# en_vectors_floret_lgpip install https://github.com/explosion/spacy-vectors-builder/releases/download/en-3.4.0/en_vectors_floret_lg-0.0.1-py3-none-any.whl
# use with spacy train in place of en_core_web_lgspacy train config.cfg --paths.vectors en_vectors_floret_mdTrain floret vectors for any language
In addition, you can train floret vectors yourself following these spaCy projects:
pipelines/floret_vectors_demo: train and import toy English vectorspipelines/floret_wiki_oscar_vectors: train vectors on Wikipedia and OSCAR for any supported language
Thanks for reading about floret! We look forward to experimenting with floret for other languages and applications in the future. You can star the spaCy or floret repos to get notified about releases on GitHub, and if you have any questions or have done something cool with floret you can let us know in our discussion forum!



