Mastering spaCyDéborah Mesquita, Duygu Altinok (Packt Publishing, 2025)Build structured NLP solutions with custom components and models powered by LLMs. By end of the book you will be empowered to build robust NLP pipelines and integrate them with web applications to build end-to-end solutions.
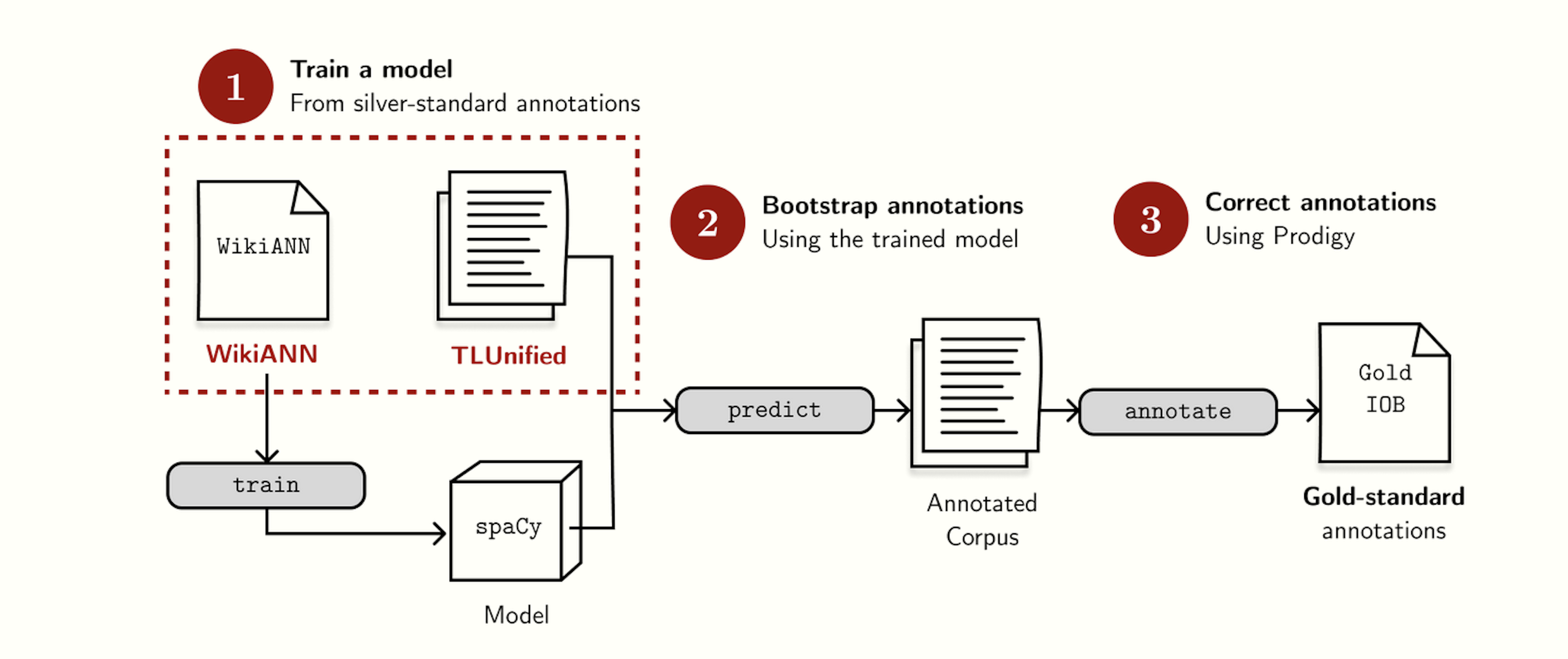
Towards a Tagalog NLP pipelineIn this blog post, Lj talks about how he built an NER pipeline for Tagalog, the gold-standard dataset, benchmarking results, and his hopes for the future of Tagalog NLP.
Compact word vectors with Bloom embeddingsAn introduction to the compact word vectors with Bloom embeddings used in Thinc, spaCy and floret.
Introducing spaCy v3.0spaCy v3.0 is a huge release! It features new transformer-based pipelines that get spaCy's accuracy right up to the current state-of-the-art, and a new workflow system to help you take projects from prototype to production. It's much easier to configure and train your pipeline, and there are lots of new and improved integrations with the rest of the NLP ecosystem.
spaCy meets Transformers: Fine-tune BERT, XLNet and GPT-2Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. You can now use these models in spaCy, via a new interface library we've developed that connects spaCy to Hugging Face's awesome implementations.
spaCy’s entity recognition model: incremental parsing with Bloom embeddings & residual CNNsspaCy v2.0’s Named Entity Recognition system features a sophisticated word embedding strategy using subword features and "Bloom" embeddings, a deep convolutional neural network with residual connections, and a novel transition-based approach to named entity parsing.
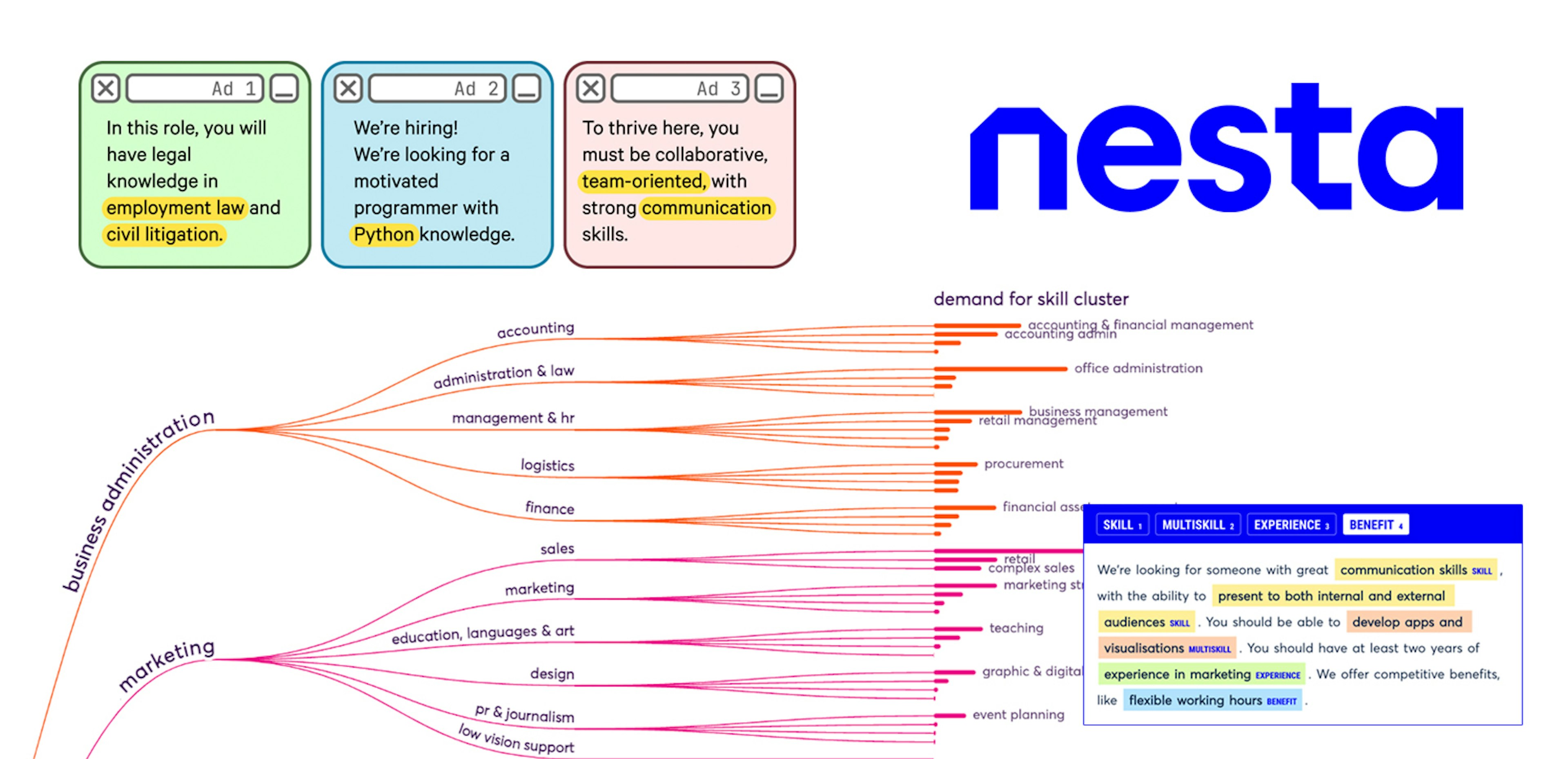
How Nesta uses NLP to process 7m job ads and shed light on the UK’s labor marketA case study on Nesta’s workflow for extracting 7 million job ads to better understand UK skill demand, using a custom mapping step to match skills to any government taxonomy.
🤖 curated-transformers v1.3.0Oct 2, 2023Custom model repositories, NVTX Ranges, store config in models
Multi hash embeddings in spaCyMiranda, Kádár, Boyd, Van Landeghem, Søgaard, Honnibal (2022)In this technical report we lay out a bit of history and introduce the embedding methods in spaCy in detail. Second, we critically evaluate the hash embedding architecture with multi-embeddings on Named Entity Recognition datasets from a variety of domains and languages. The experiments validate most key design choices behind spaCy’s embedders, but we also uncover a few surprising results.
Introducing spaCy v3.2spaCy v3.2 features usability improvements for custom training and scoring, improved performance and support for floret, our new fastText word vectors algorithm.
Introducing spaCy v2.3spaCy now speaks Chinese, Japanese, Danish, Polish and Romanian! Version 2.3 of the spaCy Natural Language Processing library adds models for five new languages. We've also updated all 15 model families with word vectors and improved accuracy, while also decreasing model size and loading times for models with vectors.
Introducing spaCy v2.1Version 2.1 of the spaCy Natural Language Processing library includes a huge number of features, improvements and bug fixes. In this post, we highlight some of the things we're especially pleased with, and explain some of the most challenging parts of preparing this big release.
Embed, encode, attend, predict: The new deep learning formula for state-of-the-art NLP modelsOver the last six months, a powerful new neural network playbook has come together for Natural Language Processing. The new approach can be summarised as a simple four-step formula: embed, encode, attend, predict. This post explains the components of this new approach, and shows how they're put together in two recent systems.
State-of-the-Art Transformer Pipelines in spaCyaiGrunnIn this talk, we will show you how you can use transformer models (from pretrained models such as XLM-RoBERTa to large language models like Llama2) to create state-of-the-art annotation pipelines for text annotation tasks such as named entity recognition.
Finding Video Games with Sense2VecIn this video, we’ll show how you can improve the annotation experience by leveraging sense2vec to pre-fill named entities.
🌸 floret v0.10.0Oct 27, 2021fastText + Bloom embeddings for compact, full-coverage vectors with spaCy
Introduction to Japanese Natural Language ProcessingMasato Hagiwara, Paul O’Leary McCann (2021)A thorough guide for programmers working with Japanese text, covering fundamental issues like tokenization and recent research topics like generating natural language texts.
sense2vec reloaded: contextually-keyed word vectorsIn 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. That work is now due for an update. In this post, we present a new version and a demo NER project that we trained to usable accuracy in just a few hours.
Embed, encode, attend, predictData Science SummitWhile there is a wide literature on developing neural networks for natural language understanding, the networks all have the same general architecture. This talk explains the four components (embed, encode, attend, predict), gives a brief history of approaches to each subproblem, and explains two sophisticated networks in terms of this framework.
Sense2vec with spaCy and GensimIf you were doing text analytics in 2015, you were probably using word2vec. Sense2vec (Trask et. al, 2015) is a new twist on word2vec that lets you learn more interesting, detailed and context-sensitive word vectors. This post motivates the idea, explains our implementation, and comes with an interactive demo that we've found surprisingly addictive.
The Tale of Bloom Embeddings and Unseen EntitiesThe default Bloom embedding layer in spaCy is unconventional, but very powerful and efficient. We wrote about it before and showed the advantages it provides in terms of memory efficiency for our floret embeddings. Now we have released the first technical report by Explosion, where we explain Bloom embeddings in more detail and rigorously compare them to traditional embeddings. In this post we'll highlight some of our results with a special focus on unseen entities.
floret: lightweight, robust word vectorsAn exploration of floret vectors: lightweight vectors for noisy data, novel words, rich morphology and more.
🛸 spacy-transformers v1.1.0Oct 18, 2021Better serialization, full ModelOutput, mixed-precision training and more
Mastering spaCyDuygu Altinok (Packt Publishing, 2021)An end-to-end practical guide to implementing NLP applications using the Python ecosystem. By the end of this book, you'll be able to confidently use spaCy, including its linguistic features, word vectors, and classifiers, to create your own NLP apps.
Using spaCy with Hugging Face TransformersPyCon IndiaTransformer models like BERT have set a new standard for accuracy on almost every NLP leaderboard. However, these models are very new, and most of the software ecosystem surrounding them is oriented towards the many opportunities for further research. In this talk, Matt describes how you can now use these models in spaCy to work on real problems and the many opportunities transfer learningfor production NLP, regardless of which software packages you choose.
More than a Million Pro-Repeal Net Neutrality Comments were Likely FakedHackernoonAnalysis of net neutrality comments by Jeff Kao using spaCy for word vectors.