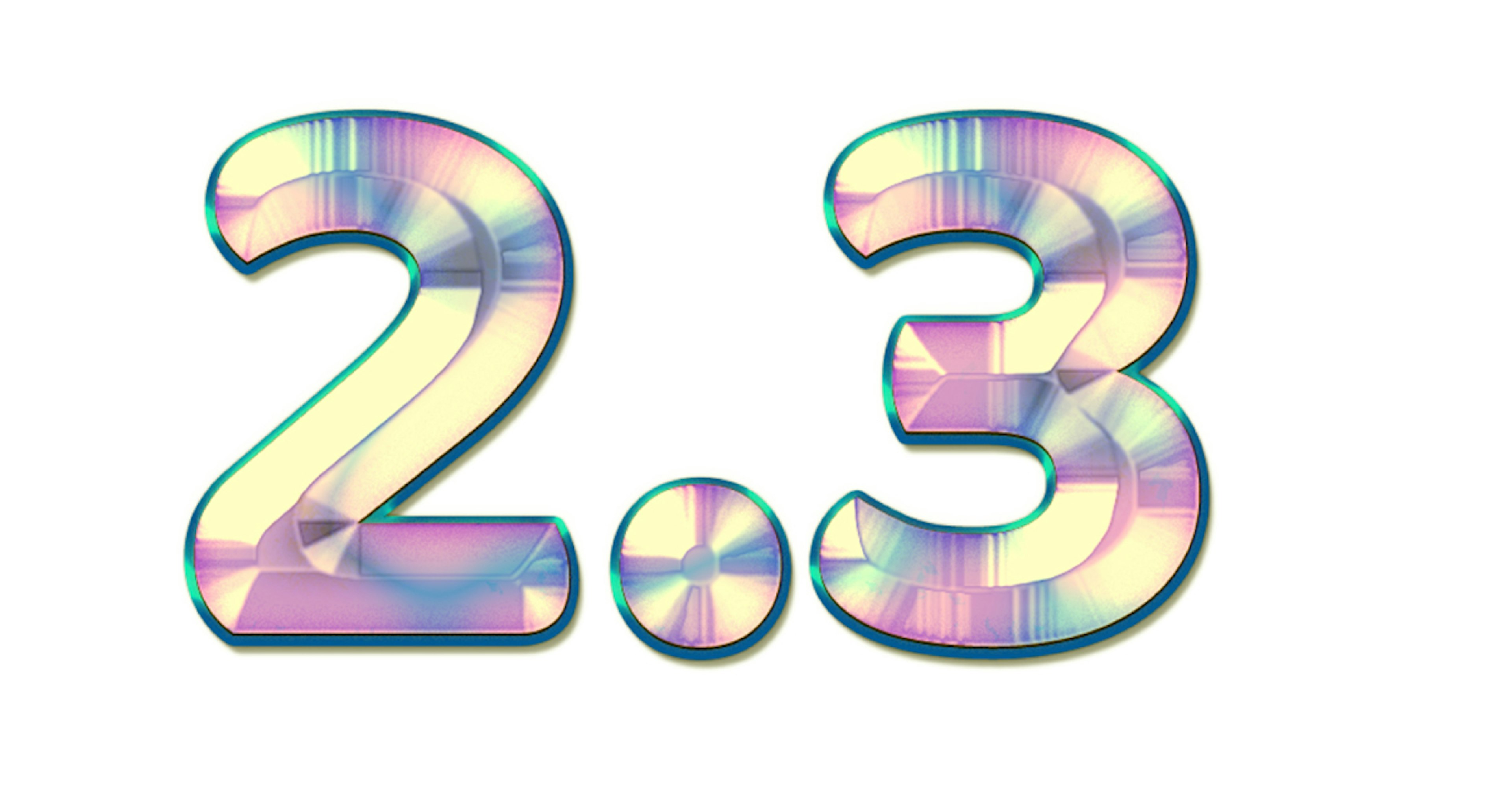
- 9 minute read
- Blog
- spaCy
- Embeddings & Vectors


spaCy now speaks Chinese, Japanese, Danish, Polish and Romanian! Version 2.3 of the spaCy Natural Language Processing library adds models for five new languages. We’ve also updated all 15 model families with word vectors and improved accuracy, while also decreasing model size and loading times for models with vectors.
This is the last major release of v2, by the way. We’ve been working hard on
spaCy v3, which comes with a lot of cool improvements, especially for training,
configuration and custom modeling. We’ll start making prereleases on
spacy-nightly soon, so stay tuned.
New languages
spaCy v2.3 provides new model families for five languages: Chinese, Danish, Japanese, Polish and Romanian. The Chinese and Japanese language models are the first provided models that use external libraries for word segmentation rather than spaCy’s tokenizer.
Chinese
The new Chinese models use pkuseg
for word segmentation and ship with a custom model trained on OntoNotes with a
token accuracy of 94.6%. Users can initialize the tokenizer with both pkuseg
and custom models and customize the user dictionary. Details can be found in the
Chinese docs. The Chinese tokenizer
continues to support jieba as the default word segmenter along with
character-based segmentation as in v2.2.
Japanese
The updated Japanese language class switches to
SudachiPy for word
segmentation and part-of-speech tagging. Using sudachipy greatly simplifies
installing spaCy for Japanese, which is now possible with a single command:
pip install spacy[ja]. More details are in the
Japanese docs.
Model Performance
Following our usual convention, the sm, md and lg models differ in their
word vectors. The lg models include one word vector for most words in the
training data, while the md model prunes the vectors table to only include
entries for the 20,000 most common words, mapping less frequent words to the
most similar vector in the reduced table. The sm models do not use pretrained
vectors.
| Language | Model | Size | TAG | UAS | LAS | ENTS F |
|---|---|---|---|---|---|---|
| Chinese | zh_core_web_sm | 45 MB | 89.63 | 68.55 | 63.21 | 66.57 |
zh_core_web_md | 75 MB | 90.23 | 69.39 | 64.43 | 68.52 | |
zh_core_web_lg | 575 MB | 90.55 | 69.77 | 64.99 | 69.33 | |
| Danish | da_core_news_sm | 16 MB | 92.79 | 80.48 | 75.65 | 72.79 |
da_core_news_md | 46 MB | 94.13 | 82.71 | 78.98 | 81.45 | |
da_core_news_lg | 546 MB | 94.95 | 82.53 | 78.99 | 82.73 | |
| Japanese | ja_core_news_sm | 7 MB | 97.30 | 88.68 | 86.87 | 59.93 |
ja_core_news_md | 37 MB | 97.30 | 89.26 | 87.76 | 67.68 | |
ja_core_news_lg | 526 MB | 97.30 | 88.94 | 87.55 | 70.48 | |
| Polish | pl_core_news_sm | 46 MB | 98.03 | 85.61 | 78.09 | 81.32 |
pl_core_news_md | 76 MB | 98.28 | 90.41 | 84.47 | 84.68 | |
pl_core_news_lg | 576 MB | 98.45 | 90.80 | 85.52 | 85.67 | |
| Romanian | ro_core_news_sm | 13 MB | 95.65 | 87.20 | 79.79 | 71.05 |
ro_core_news_md | 43 MB | 96.32 | 88.69 | 81.77 | 75.42 | |
ro_core_news_lg | 545 MB | 96.78 | 88.87 | 82.05 | 76.71 |
The training data for Danish, Japanese and Romanian is relatively small, so the pretrained word vectors improve accuracy quite a lot, in particular for NER. The Chinese model uses a larger training corpus, but word segmentation errors may make the word vectors less effective. Word segmentation accuracy also explains some of the lower scores for Chinese, as the model has to get the word segmentation correct before it can be scored as accurate on any of the subsequent tasks.
Word vectors for all model families
All model families now include medium and large models with 20k and 500k unique vectors respectively. For most languages, spaCy v2.3 introduces custom word vectors trained using spaCy’s language-specific tokenizers on data from OSCAR and Wikipedia. The vectors are trained using FastText with the same settings as FastText’s word vectors (CBOW, 300 dimensions, character n-grams of length 5).
In particular for languages with smaller training corpora, the addition of word vectors greatly improves the model accuracy. For example, the Lithuanian tagger increases from 81.7% for the small model (no vectors) to 89.3% for the large model. The parser increases by a similar margin and the NER F-score increases from 66.0% to 70.1%. For German, updating the word vectors increases the scores for the medium model for all components by 1.5 percentage points across the board.
Model compatibility
Remember that models trained with v2.2 will be incompatible with the new
version. To find out if you need to update your models, you can run
python -m spacy validate. If you’re using your own custom models, you’ll need
to retrain them with the new version.
Updated training data
All spaCy training corpora based on Universal Dependencies corpora have been updated to UD v2.5 (v2.6 for Japanese, v2.3 for Polish). The updated data improves the quality and size of the training corpora, increasing the tagger and parser accuracy for all provided models. For example, the Dutch training data is extended to include both UD Dutch Alpino and LassySmall, which improves the tagger and parser scores for the small models by 3%, and the addition of the new word vectors improve the scores further by 3-5%.
Fine-grained POS tags
As a result of the updates, many of the fine-grained part-of-speech tag sets will differ from v2.2 models. The coarse-grained tag-set remains the same, although there are some minor differences in how they are calculated from the fine-grained tags.
For French, Italian, Portuguese and Spanish, the fine-grained part-of-speech tag
sets contain new merged tags related to contracted forms, such as ADP_DET for
French "au", which maps to UPOS ADP based on the head "à". This increases
the accuracy of the models by improving the alignment between spaCy’s
tokenization and Universal Dependencies multi-word tokens used for contractions.
Smaller models and faster loading times
The medium model packages with 20k vectors are at least 2× smaller than in
v2.2, the large English model is 120M smaller, and the loading times are
2-4× faster for all models with vectors. To achieve this, models no longer
store derivable lexeme attributes such as lower and is_alpha and the
remaining lexeme attributes (norm, cluster and prob) have been moved to
spacy-lookups-data.
If you’re training new models, you’ll probably want to install
spacy-lookups-data for normalization and lemmatization tables! The provided
models include the norm lookup tables for use with the core pipeline
components, but the optional cluster and prob features are now only
available through spacy-lookups-data.
Free online course and tutorials
We’re also proud to announce updates and translations of our online course, “Advanced NLP with spaCy”. We’ve made a few small updates to the English version, including new videos to go with the interactive exercises. It’s really the translations we’re excited about though. We have translations into Japanese, German and Spanish, with Chinese, French and Russian soon to come.

Speaking of videos, you should also check out Sofie’s tutorial on training a custom entity linking model with spaCy. You can find the code and data in our growing projects repository.
Another cool video to check out is the new episode of Vincent Warmerdam’s “Intro to NLP with spaCy” . The series lets you sit beside Vincent as he works through an example data science project using spaCy. In episode 5, “Rules vs. Machine Learning”, Vincent uses spaCy’s rule-based matcher to probe the decisions of the NER model he trained previously, using the rules to understand the model’s behavior and figure out how to improve the training data to get better results.
What’s next?
spaCy v2.3 is the last big release of v2. We’ve been working hard on v3, which we expect to start publishing prereleases of in the next few weeks. spaCy v3 comes with a lot of cool improvements, especially for training, configuration and custom modeling. The training and data formats are the main thing we’ve taken the opportunity to fix, so v3 will have some breaking changes, but don’t worry — it’s nothing like the big transformations seen in libraries like TensorFlow or Angular. It should be pretty easy to upgrade, but we’ve still tried to backport as much as possible into v2.3, so you can use it right away. We’ll also continue to make maintenance releases of v2.3 with bug fixes as they come in.
We also have a big release of our annotation tool Prodigy
pretty much ready to go. In addition to the spaCy v2.3 update (giving you all
the new models), Prodigy v1.10 comes with a new annotation interface for tasks
like relation extraction and coreference resolution, full-featured
audio and video annotation (including recipes using
pyannote.audio models in the
loop), a new and improved manual image UI, more options for NER annotation, new
recipe callbacks, and lots more. To get notified when it’s ready, follow us
on Twitter!
Resources
- spaCy v2.3: What’s new in v2.3
- Release notes: Detailed overview
- spaCy models directory: Download pretrained models



