calamanCy: A Tagalog Natural Language Processing ToolkitMiranda (2023), EMNLP 2023We introduce calamanCy, an open-source toolkit for constructing NLP pipelines for Tagalog. It is built on top of spaCy, enabling easy experimentation and integration with other frameworks.
Introducing spaCy v3.5spaCy v3.5 introduces new CLI commands, fuzzy matching, improvements for entity linking and more.
Introducing spaCy v3.3spaCy v3.3 improves the speed of core pipeline components, adds a new trainable lemmatizer, and introduces trained pipelines for Finnish, Korean and Swedish.
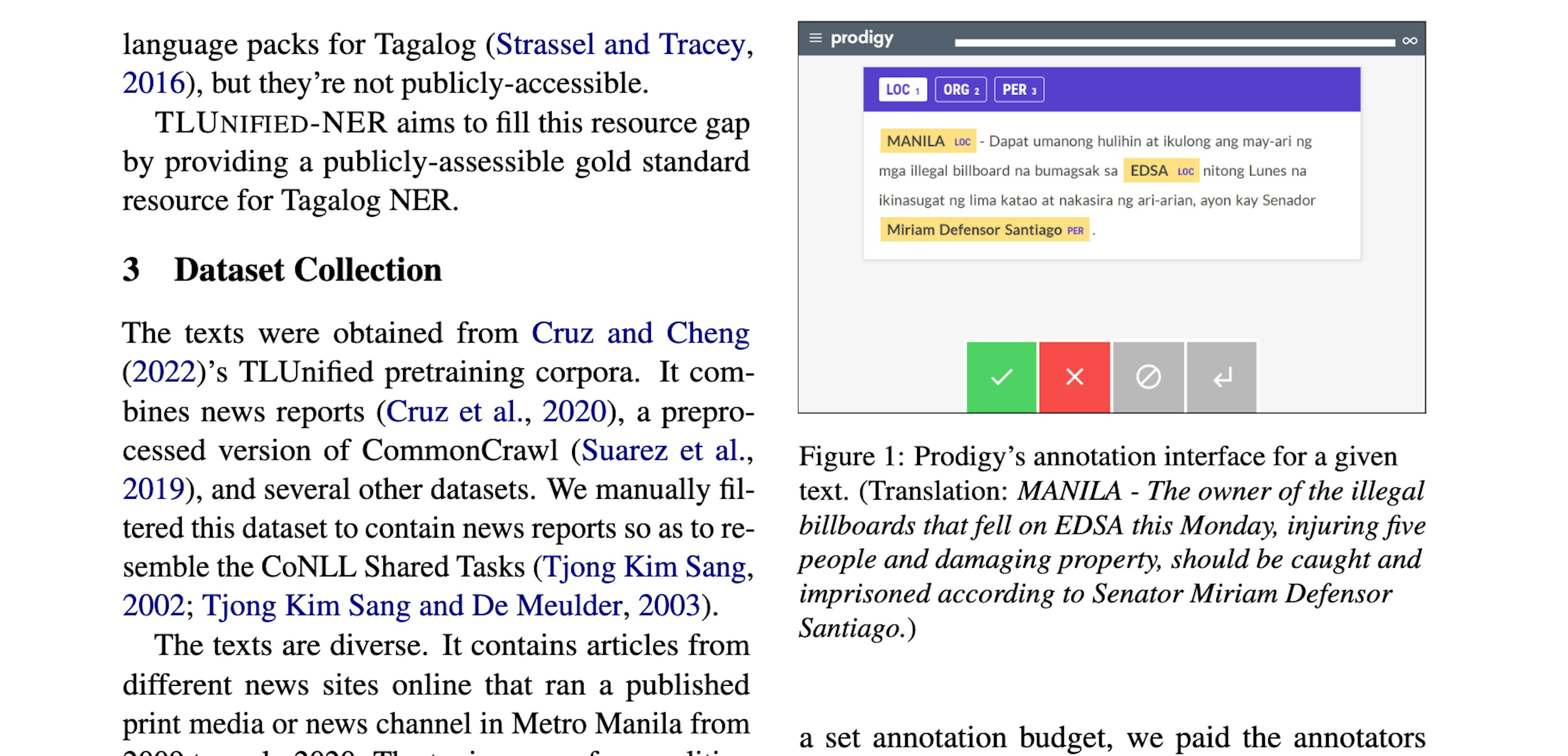
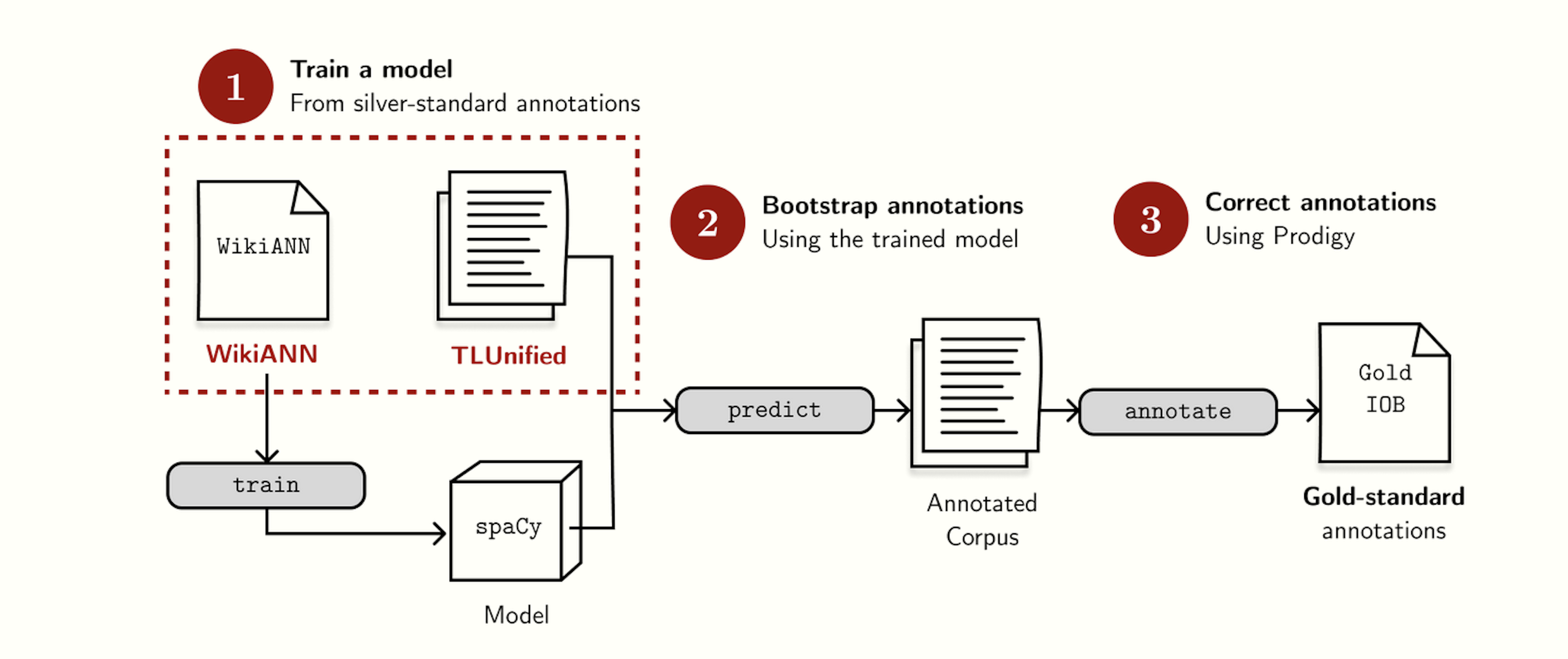
Developing a Named Entity Recognition Dataset for TagalogMiranda (2023), IJCNLP-AACL 2023We used Prodigy as our annotation tool. We set up a web server on the Google Cloud Platform and routed the examples through Prodigy’s built-in task router.
Multi hash embeddings in spaCyMiranda, Kádár, Boyd, Van Landeghem, Søgaard, Honnibal (2022)In this technical report we lay out a bit of history and introduce the embedding methods in spaCy in detail. Second, we critically evaluate the hash embedding architecture with multi-embeddings on Named Entity Recognition datasets from a variety of domains and languages. The experiments validate most key design choices behind spaCy’s embedders, but we also uncover a few surprising results.
spaCy v3's project and config systems are pretty greatThe road to production has become increasingly harder. Machine Learning Engineers who turn prototypes into production-ready software face difficulties with the lack of tooling and best-practices. spaCy v3, with its configuration and project system, introduced a way to solve this problem. Here's my take on how it works, and how it can ramp-up your team!
The Tale of Bloom Embeddings and Unseen EntitiesThe default Bloom embedding layer in spaCy is unconventional, but very powerful and efficient. We wrote about it before and showed the advantages it provides in terms of memory efficiency for our floret embeddings. Now we have released the first technical report by Explosion, where we explain Bloom embeddings in more detail and rigorously compare them to traditional embeddings. In this post we'll highlight some of our results with a special focus on unseen entities.
Introducing spaCy v3.4spaCy v3.4 brings typing and speed improvements along with new vectors for English CNN pipelines and new trained pipelines for Croatian.
Introducing spaCy v3.2spaCy v3.2 features usability improvements for custom training and scoring, improved performance and support for floret, our new fastText word vectors algorithm.
Towards a Tagalog NLP pipelineIn this blog post, Lj talks about how he built an NER pipeline for Tagalog, the gold-standard dataset, benchmarking results, and his hopes for the future of Tagalog NLP.
Spancat: a new approach for span labelingThe SpanCategorizer is a spaCy component that answers the NLP community's need to have structured annotation for a wide variety of labeled spans, including long phrases, non-named entities, or overlapping annotations. In this blog post, we're excited to talk more about spancat and showcase new features to help with your span labeling needs!