
- 19 minute read
- Blog
- Evaluation
- NLP Strategy

We’ve been running Explosion for about five years now, which has given us a lot of insights into what Natural Language Processing looks like in industry contexts. In this blog post, I’m going to discuss some of the biggest challenges for applied NLP and translating business problems into machine learning solutions.
When you’re starting out in the field and are facing real problems to solve, it’s easy to feel a bit lost. Even though you understand the fundamentals of machine learning, know your way around the industry-standard libraries and have experience in programming and training your own models, you might still feel like something is missing. The right intuition, the right mindset, a different way to reason about what to do. I call this “Applied NLP Thinking”.
Applied NLP Thinking: an analogy
It’s a fairly abstract idea, but while I was writing this, I think I came up with a pretty fitting analogy. Like most of the world, I spent even more time indoors in 2020 than I usually do. Maybe I just missed restaurants, but for a while, I got really into watching cooking shows. I was particularly interested in the business side of running a restaurant, and how it ties in with the actual craft of cooking itself.
There’s a lot to learn when it comes to cooking: you need to know many skills and techniques, and be able to reproduce recipes and use all kinds of different equipment. You need to understand the ingredients and how to present your dish, and on top of that, there are fundamentals of nutrition, chemistry and food science. You don’t need to be a food scientist to be a good cook, but understanding how egg, mustard and oil turn into mayonnaise certainly helps.
But there’s more to a restaurant than just the cooking. A restaurant kitchen is basically a little factory. In order to give your factory any chance of success, the menu needs to be designed carefully. The dishes and flavors need to work together and you need to be able to source the ingredients reliably. Every dish needs to be prepared consistently, every single time, without mistakes. The menu also needs to serve the market well and allow a sufficient profit margin so the restaurant can be successful.
| Cooking | Menu design |
|---|---|
| skills and techniques | select combination of flavors and dishes |
| reproduce recipes | source ingredients |
| use equipment | ensure reliability |
| work with ingredients | understand market and type of cuisine |
| food presentation | optimize profit |
| nutrition, chemistry and food science |
Now, I’m not a chef, but I’d be surprised if someone could design a good restaurant menu without also knowing how to cook. You can’t abstract away the details of how everything is done and what adaptions you could make. All of those details matter. But the activity of designing the menu is also quite different from implementing it. The activity of deciding what to do is different from just carrying out the plan.
What vs. How
Applied NLP is more about deciding what to cook, and less about how to cook it. Actually, a big part is even deciding whether to cook – finding the right projects where NLP might be feasible and productive. The process of understanding the project requirements and translating them into the system design is harder to learn because you can’t really get to the “what” before you have a good grasp of the “how”.
| How | What |
|---|---|
| implement models | when to use ML |
| ML fundamentals | decide what models and components to train |
| training and evaluation | understand what application will use outputs for |
| improve accuracy | find best trade-offs |
| use library APIs | select resources and libraries |
| Python and DevOps |
The “how” is everything that helps you execute the plan. This includes knowing how to implement models and how they work and various machine learning fundamentals that help you understand what’s going on under the hood. It also includes knowing how to train and evaluate your models, and what to do to improve your results. And of course, you should be familiar with the standard libraries and proficient at programming and software engineering more generally. All of this is the “how”, and it’s what you can learn from books and courses.
The “what” is translating the application goals into your machine learning requirements, to design what the system should do and how you’re going to evaluate it. It includes deciding when to use machine learning in the first place, and whether to use other approaches like rule-based systems instead. It also includes choosing the types of components and models to train that are most likely to get the job done. This requires a deep understanding of what the outputs will be used for in the larger application context. You also need to be able to find the right trade-offs, for instance between speed and accuracy or convenience and flexibility. This includes knowing what resources and libraries are available, and what to use when. The “what” is what matters most for applied NLP – and you can’t solve it without the “how”. But just the “how“ itself is not enough.
To give you an example, here’s an application context you may encounter. Imagine you’re working at a large company, and the IT desk gets a lot of support tickets. Your organization wants the tickets to be answered more quickly and efficiently, and they want to understand what the most common problems are to better prevent them in the future. There are lots of different ways you could address these requirements with NLP. So where do you start?
The computer won’t turn on.
During the boot sequence, it hits an error and goes to the debug console.
I keep trying to turn the computer on, but it goes black and resets.
Maybe you could sort the support tickets into categories, by type of problem, and try to predict that? Or cluster them first, and see if the clustering ends up being useful to determine who to assign a ticket to? If you have data about how long it takes to resolve tickets, maybe you can do regression on that — having cost estimation on tickets can be really helpful in balancing work queues, staffing, or maybe just setting expectations. You could also try and extract key phrases that are likely indicators of a problem. If you can predict those, it could help with pre-sorting the tickets, and you’d be able to point out specific references. However, the boundaries are very unclear, and the key phrases are possibly disjoint. The less consistent your data, the harder it will be to train a model. So you might need a different approach.
Maybe there’s a way to jumpstart the process with custom embeddings that are more specific to the domain and terminology, to squeeze out a higher accuracy. But the system also needs to be useful, so how are you going to measure that? Is your organization tracking the response times, so you can test your NLP system against that? At the end of your brainstorming session, you may end up with a preliminary to-do list: start with the label scheme and get the IT support team involved so you can explain what’s possible to automate and what isn’t. And maybe train a text classifier baseline, bootstrapped with some keywords.

It’s really the answer to the “what” question that will determine whether the project succeeds or fails. It doesn’t matter whether you build a model that achieves high accuracy on your test data if you’ve framed the problem in a way that doesn’t actually address the relevant problems for the application. So how can you get better at answering the “what”?
First, you can’t do applied NLP without thinking about the application. You need to really engage with the purpose of the system you’re trying to build. You can’t just say, “Product decisions are the product people’s job” – unless the “product people” know more about NLP than you do.
You also shouldn’t expect the “what” to be trivial. A problem we see sometimes is that people assume that the “what” is trivial, simply because there’s not much discussion of it, and all you ever hear about is the “how”. If you assume that translating application requirements into a machine learning design is really easy and that the problem is really easy, you may also assume that the first idea that comes to mind is probably the correct one. That can cause some expensive mistakes. Instead, it’s better to assume that the first idea you have is probably not ideal, or might not work at all. It can take some iteration to come up with a successful design.
Utility vs. Accuracy
So how do you know your design is successful? In applied NLP, it’s important to pay attention to the difference between utility and accuracy. “Accuracy” here stands for any objective score you can calculate on a test set — even if the calculation involves some manual effort, like it does for human quality assessments. This is a figure you can track, and if all goes well, that figure should go up. In contrast, the “utility” of the model is its impact in the application or project. This is a lot harder to measure, and always depends on the application context.
Hopefully, your evaluation metric should be at least correlated with utility — if it’s not, you’re really in trouble. But the correlation doesn’t have to be perfect, nor does the relationship have to be linear. I’m using “utility” here in the same sense it’s used in economics or ethics. In economics it’s important to introduce this idea of “utility” to remind people that money isn’t everything. In applied NLP, or applied machine learning more generally, we need to point out that the evaluation measure isn’t everything.
Evaluation measures are important for both research and applications, but their role isn’t exactly the same. It comes back to the different purposes that you have. Research is basically about building a commons of knowledge, and the idea is that this commons overall should be useful. For that to happen, research needs to generalize at least a little bit. It can’t be specific to just one situation. Application is kind of the inverse: you take the general, and adapt it to your specific context.
| Research | Application |
|---|---|
| build a commons of knowledge | learn from commons of knowledge |
| find context-independent solutions that generalize | adapt general solutions to specific contexts |
| make direct comparisons using standard evaluations | align evaluation to project goals |
| standardize everything that isn’t novel | do whatever works |
Another difference is that in research, you’re mostly concerned with figuring out whether your conclusions are true, and maybe quantifying uncertainty about that. In an application, the bottom-line is whether the project is useful. So when you conduct an evaluation in research, you’re trying to isolate your new idea, and you usually want to evaluate exactly the same way as prior work. That way you can test whether your change did what you were hoping it would do. In an application, you’re mostly using the evaluation to choose which systems to try out in production. You’re hoping that a system that scores better on your evaluation should be better in your application. In other words, you’re using the evaluation as a proxy for utility — you’re hoping that the two are well correlated. Often they really are! But you also get to choose the evaluation — that’s a totally legitimate and useful thing to do. In research, changing the evaluation is really painful, because it makes it much harder to compare to previous work.
What “utility” means is different for every application. In our example of a system for processing IT support tickets, a successful application will result in faster processes, as it allows the right person to be assigned quicker. In turn, this can lead to a higher satisfaction: users with problems get help quicker, and IT support staff has to spend less time waiting around, or dealing with tickets outside their core expertise. Categorizing tickets automatically also helps with discovering common problems and knowing what to fix. All of this can lead to higher revenue, or save the company a bunch of money.
People often discuss machine learning as a cost-cutting measure – it can “replace human labour”. But it’s pretty difficult to make this actually work well, because reliability is often much more important than price. If you’ve got a plan that consists of lots of separate steps, the total cost is going to be additive, while the risk multiplies. Something going wrong at any of the steps is going to affect the whole plan. So for applied NLP within business processes, the utility is mostly about reducing variance. Humans and models both make mistakes, but they’re very different mistakes. Humans can easily catch mistakes made by a model, and a model can be great at correcting human errors caused by inattention.
Without the idea of “utility”, it’s hard to talk about why you would prefer one evaluation over another. Let’s say you have two evaluation metrics and they result in different orderings over systems you’ve trained. Which evaluation metric should you prefer? The answer is, “whichever one is better correlated with utility”.
Linguistics can help
We’ve seen that for applied NLP, it’s really important to think about what to do, not just how to do it. And we’ve seen that we can’t get too focussed on just optimizing an evaluation figure — we need to think about utility. So how can we give people a better toolkit to do this? What should we teach people to make their NLP applications more likely to succeed? I think linguistics is an important part of the answer here that’s often neglected.
There are lots of different areas that someone doing NLP can focus on, either to work on research or applications. If you’ve ever played a role-playing game, you can think of it like investing points in different skill trees. Let’s say you want to build your character up for “applied NLP” and you know you don’t want to do research. How should you allocate your points?
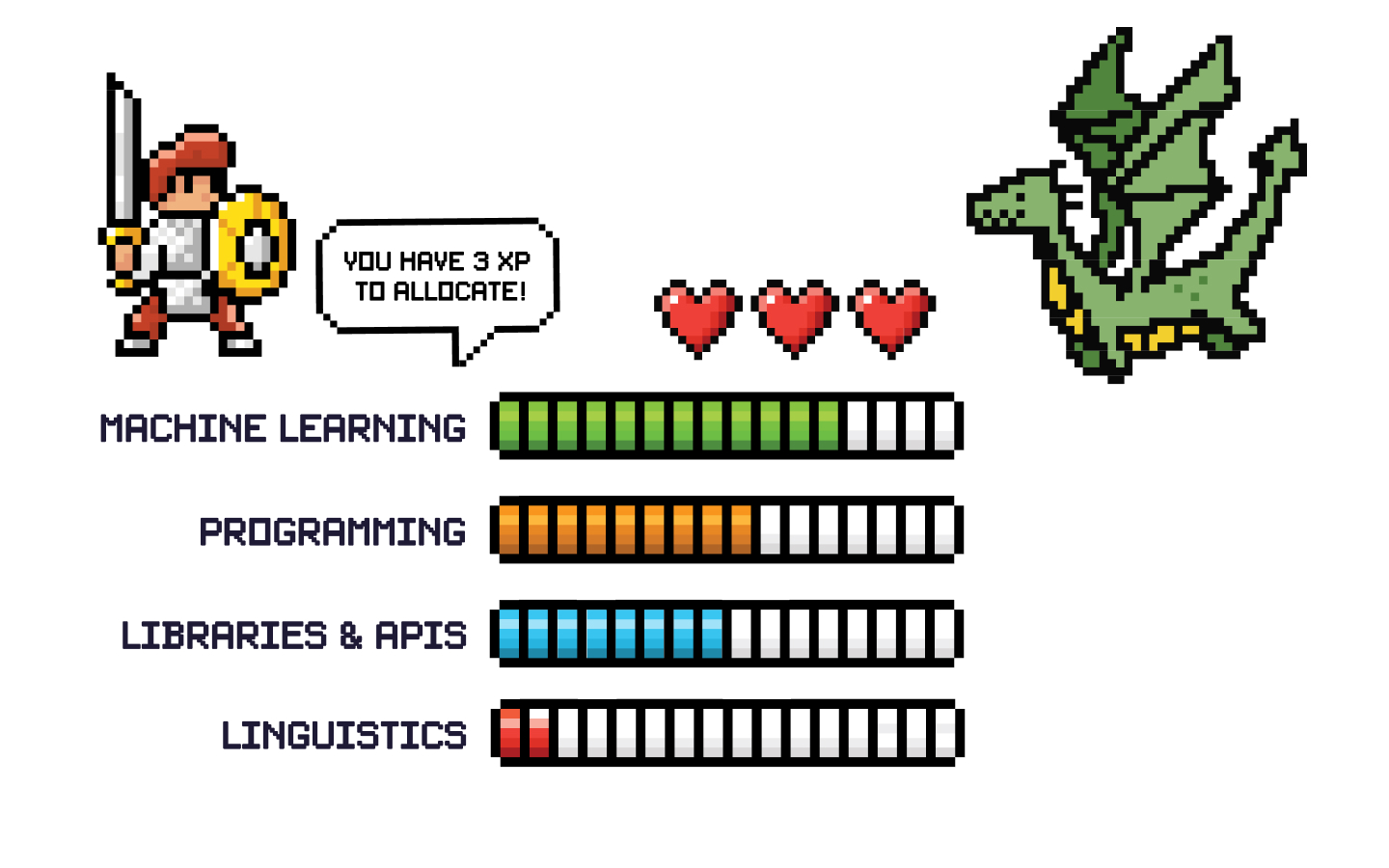
A common suggestion would be to rank linguistics as the lowest priority. And if you’re going to be allocating your first points, it’s definitely more important to know a bit about programming and machine learning. As for libraries and APIs, this one is a bit special: it turns out the game just gives you points here as you play. You’ll find yourself accidentally fluent in whatever tools are required for your work, so no need to spend any of your points on this explicitly.
For applied NLP, a little bit of linguistics knowledge can go a long way and prevent some expensive mistakes. I’m not saying that you should sink all of your points into maxing out on linguistics – there are diminishing returns. But knowing nothing about linguistics really holds people back. Here are a few examples of linguistic concepts that I think anyone working on applied NLP should be aware of.
Lexical types, tokens and morphology
Let’s go back to the IT support tickets. You’re working on the task, and someone suggests extracting keywords from the tickets, which can then act like topic tags. The support team will be able to click the topic, and see other tickets with it. You know all about LDA and topic modeling, so you go ahead and create the clusters easily. The unigram topics aren’t very satisfying, though, so you include bigrams and trigrams. Now you have topics like “n’t turn”, which is very common in the data, but not very useful. How do you get topics like “turn on” and “resets”, but not “, but it”?

If you’ve never thought much about language before, it’s normal to expect “a word” to be a simple thing to define and work with. This is especially true if your native language is a language like English where most lexical items are whitespace-delimited and the morphology is relatively simple.
However, even in English there are lots of multi-word expressions: lexical types that have spaces in them and might not even be contiguous, for example, phrasal verbs. The morphology often matters, too. It doesn’t take a lot of learning to understand the difference between a lexical type and a token, and to think about which of them your application should be working with. It’s especially important to understand Zipf’s law, as the numeric relationship between the number of types and the number of tokens in a sample of text is often very relevant. So knowing linguistics can help you constrain your system’s output and make your application more useful.
Compositional syntax and semantics
Another topic that deserves more attention is compositional syntax and semantics. This is especially relevant when you’re designing annotation schemes and figuring out how you want to frame your task.
For instance, let’s take a look at the IT support tickets again. A really common instinct we see people have is that they want their model to identify subsequences of text. For instance, someone might suggest: Let’s label the phrases that indicate the problem and train an entity recognizer on that! The issue here is that “the problem” isn’t reliably going to be expressed as any particular constituent. It might not even be within a single predicate-argument structure. This means that the spans of text you’ll be annotating are really arbitrary. Your annotators will never agree closely on what to annotate, and at the end of it all, what are you even going to do with the output? If you’re not returning phrases of a specific type, it will be very difficult to do anything with the extracted spans at the end.

In this example, one solution is to model the problem as a text classification task. This will be a lot more intuitive to annotate consistently, and you’ll only need to collect one decision per label per text. This also makes it easier to get subject matter experts involved – like your IT support team. The model you train will only have to predict labels over the whole text, and the output it produces will be more useful for the downstream application.

Sometimes, a flat label really isn’t enough, though. For instance, in most chat bot contexts, you want to take the text and resolve it to a function call, including the arguments. It’s really important to have some understanding of syntax and semantics if you’re doing that. Syntax will help you define the argument boundaries properly, because you really want your arguments to be syntactic constituents – it’s the only way to make them consistent. And semantics will help you understand why the actual texts will be much more complicated than the subject-verb-object examples your team might be thinking up.
Conclusion
There’s much less written about applied NLP than about NLP research, which can make it hard for people to guess what applied NLP will be like. In a lot of research contexts, you’ll implement a baseline and then implement a new model that beats it. So it’s kind of natural to guess that applied NLP will be like that, except without the “new model” part. That’s not entirely untrue, but it leaves out some really important things. Research has a very different goal, which requires a different mindset. If you imagine doing applied NLP without changing that mindset, you’ll come away with a pretty incorrect impression.
The most important thing for applied NLP is to come in thinking about the product or application goals. You can’t abstract those away and just grind on an optimization problem. You’ll never ship anything valuable that way, and you might even ship something harmful. Instead, you need to try out different ideas for the data, model implementation and even evaluation. You shouldn’t expect deciding what to do to be trivial or obvious, and you especially shouldn’t assume your first idea will be the best one.
You should also keep in mind that evaluation will have a different role within your project. However you’re evaluating your models, the held-out score is only evidence that the model is better than another. You need to go and verify that. Accuracy isn’t the same thing as utility. You should expect to check the utility of multiple models, which means you’ll need to have a smooth path from prototype to production. You shouldn’t expect to just work in Jupyter notebooks on your local machine.
Applied NLP gives you a lot of decisions to make, and these decisions are often hard. It’s important to iterate, but it’s also important to build a better intuition about what might work and what might not. There are some topics in linguistics that can really help here. Obviously, there’s a lot of other things to learn as well, but it’s worth putting some points into the linguistics skill tree, once you’re up to speed with solid programming skills and a good conceptual overview of machine learning.
Applied NLP isn’t just like research NLP but with less novelty and less thinking. It requires a different thinking: applied NLP thinking.



