
- 13 minute read
- Blog
- Prodigy
- Annotation


Machine learning systems are built from both code and data. It’s easy to reuse the code but hard to reuse the data, so building AI mostly means doing annotation. This is good, because the examples are how you program the behaviour – the learner itself is really just a compiler. What’s not good is the current technology for creating the examples. That’s why we’re pleased to introduce Prodigy, a downloadable tool for radically efficient machine teaching.
We’ve been working on Prodigy since we first launched Explosion last year, alongside our open-source NLP library spaCy and our consulting projects (it’s been a busy year!). During that time, spaCy has grown into the most popular library of its type, giving us a lot of insight into what’s driving success and failure for language understanding technologies. Most of those insights have been used to make spaCy better: AI DevOps was hard, so we made sure models could be installed via pip. Large models made CI tricky, so the new models are less than 1/10th the size.
Prodigy addresses the big remaining problem: annotation and training. The typical approach to annotation forces projects into an uncomfortable waterfall process. The experiments can’t begin until the first batch of annotations are complete, but the annotation team can’t start until they receive the annotation manuals. To produce the annotation manuals, you need to know what statistical models will be required for the features you’re trying to build. Machine learning is an inherently uncertain technology, but the waterfall annotation process relies on accurate upfront planning. The net result is a lot of wasted effort.
Prodigy solves this problem by letting data scientists conduct their own annotations, for rapid prototyping. Ideas can be tested faster than the first planning meeting could even be scheduled. We also expect Prodigy to reduce costs for larger projects, but it’s the increased agility we’re most excited about. Data science projects are said to have uneven returns, like start-ups: a minority of projects are very successful, recouping costs for a larger number of failures. If so, the most important problem is to find more winners. Prodigy helps you do that, because you get to try things much faster.
Prodigy’s recipe for efficient annotation
Most annotation tools avoid making any suggestions to the user, to avoid biasing the annotations. Prodigy takes the opposite approach: ask the user as little as possible, and try to guess the rest. Prodigy puts the model in the loop, so that it can actively participate in the training process and learns as you go. The model uses what it already knows to figure out what to ask you next. As you answer the questions, the model is updated, influencing which examples it asks you about next. In order to take full advantage of this strategy, Prodigy is provided as a Python library and command line utility, with a flexible web application. There’s a thin, and optional hosted component to make it easy to share annotation queues, but the tool itself is entirely under your control.
Prodigy comes with built-in recipes for training and evaluating text classification, named entity recognition, image classification and word vector models. There’s also a neat built-in component for doing A/B evaluations, which we expect to be particularly useful for developing generative models and translation systems. To keep the system requirements to a minimum, data is stored in an SQLite database by default. It’s easy to use a different SQL backend, or to specify a custom storage solution.

The components are wired togther into a recipe, by adding the @recipe
decorator to any Python function. The decorator lets you invoke your function
from the command-line, as a prodigy subcommand. Recipes can start the web
service by return a dictionary of components. The recipe system provides a good
balance of declarative and procedural approaches. If yo just need to wire
together built-in components, return a Python dictionary is no more typing than
the equivalent JSON representation. But the Python function also lets you
implement more complicated behaviours, and reuse logic across your recipes.
recipe.py
UX-driven data collection with Prodigy
When humans interact with machines, their experience is what decides about the success of the interaction. Most annotation tools avoid making suggestions to the user, to avoid biasing the annotations. Prodigy takes the opposite approach: ask the user as little as possible. The more complicated the structure your model has to produce, the more benefit you can get from Prodigy’s binary interface. The web app lets you annotate text, entities, classification, images and custom HTML tasks straight from your browser – even on mobile devices.
 Try the live demo!
Try the live demo!
Human time and attention is precious. Instead of presenting the annotators with a span of text that contains an entity, asking them to highlight it, select one of many labels from a dropdown and confirm, you can break the whole interaction down into a simple binary decision. You’ll have to ask more questions to get the same information, but each question will be simple and focused. You’ll collect more user actions, giving you lots of smaller pieces to learn from, and a much tighter feedback loop between the human and the model.
Why machine learning systems need annotated examples
Most AI systems today rely on supervised learning: you provide labelled input and output pairs, and get a program that can perform analogous computation for new data. Supervised learning algorithms have been improving quickly, leading many people to anticipate a new wave of entirely unsupervised algorithms: algorithms so “advanced” they can compute whatever you want, without you specifying what that might be. This is like hoping for a programming language so advanced you don’t even need to write a program.


Unsupervised algorithms return meaning representations, based on the internal structure of the data. By definition, you can’t directly control what the process returns. Sometimes the meaning representation will directly address a useful question. If you’re looking for suspicious activity on your platform, you might find that an outlier detection process is all you need. However, the unsupervised algorithm won’t usually return clusters that map neatly to the labels you care about. With the right feature weightings, you might be able to come up with a model that sorts your data more usefully, but doing this by hand is unproductive: this is exactly the problem supervised learning is designed to solve.
Example: Text Classification
Text classification models can be trained to perform a wide variety of useful tasks, including sentiment analysis, chatbot intent detection, and flagging abusive or fraudulent content. One of the problems with text classification is that it’s usually hard to guess how accurately the system will perform. Some problems turn out to be unexpectedly easy, while others are so difficult the intended functionality needs to be redesigned. Prodigy lets you perform very rapid prototyping, so that you can quickly find out which ideas are worth further exploration.
Text classification really shines when the task would otherwise be performed by hand. For instance, we regularly categorise GitHub issues for our library, spaCy. Keeping the issue tracker tidy is something many open source projects struggle with – so automated tools could definitely be helpful. How easy would it be to create a bot to tag the issues automatically?
Getting started with Prodigy
Prodigy is a Python library, so it’s easy to stream in data from any source —
all you have to do is create a generator that yields out your examples. Prodigy
also includes several built-in API loaders,
including one for the GitHub API. To get
started, we’ll want to search for a query that returns a decent number of
documentation issues. The model can’t know what we’re looking for until we’ve
said “yes” to some examples. To find a good query, it’s useful to pipe the
stream into less, so we can look at the results:
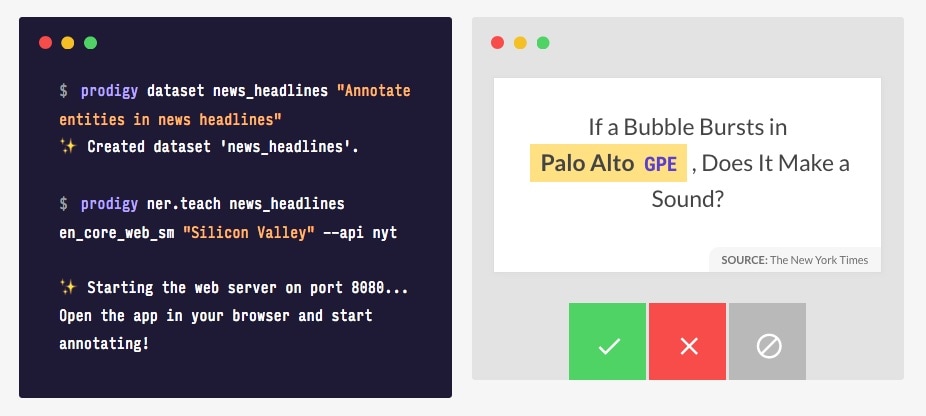
prodigy textcat.print-stream "docs" --api github --label DOCS | less -r
Now it’s time to start annotating. We first add initialise a new dataset, adding
a quick description for future reference. The next command starts the annotation
server. The textcat.teach subcommand tells prodigy to run the built-in recipe
function teach(), using the rest of the arguments supplied on the command
line.
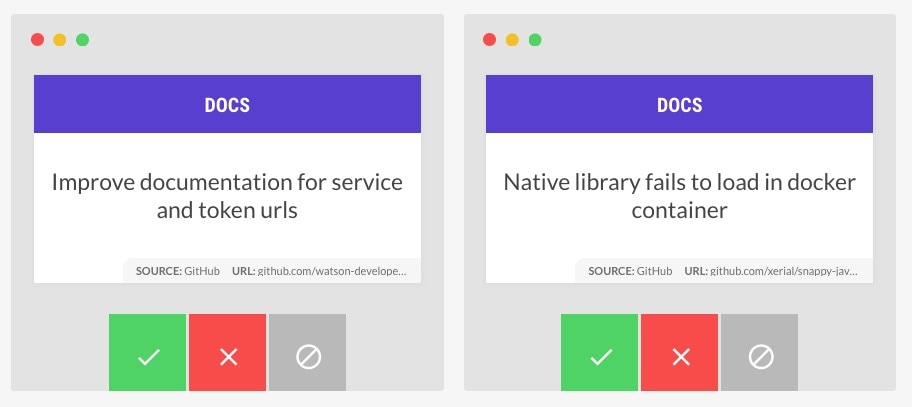
prodigy dataset gh_issues "Classify issues on GitHub"prodigy textcat.teach gh_issues en_core_web_sm "docs" --api github --label DOCSOpening localhost:8080, we get a sequence of recent GitHub issue titles,
displayed with our category as the title. If the category is correct, click
accept, press a, or swipe left on a touch interface. If
the category does not apply, click reject, press x, or
swipe right. Some examples are unclear or exceptions that you don’t want the
model to learn from. In these cases, you can click ignore or press
space.
Prodigy trains a model during annotation, on the answers you’re providing. This lets Prodigy rank the examples in the stream, to ask less redundant questions. Learning from streaming data is a tricky problem, so we can usually get better results by training a new from scratch, once all the annotations are collected. This also lets us study the model in more detail, and try different hyper-parameters.
After around 40 minutes of annotating the stream of issue titles for the search queries “docs”, “documentation”, “readme” and “instructions”, we end up with a total of 830 annotations that break down as follows:
| Decision | Count |
|---|---|
| accept | 261 |
| reject | 525 |
| ignore | 44 |
| total | 830 |
prodigy textcat.print-dataset gh_issues | less -r
By default, Prodigy uses spaCy v2.0’s new text classification system (currently in alpha). The model is a convolutional neural network stacked with a unigram bag-of-words. The bag-of-words model learns quickly, while the convolutional network lets the model pick up cues from longer phrases, once a few hundred examples are available.
Using a different text classification strategy with Prodigy is very easy. If you
want to keep using spaCy, you can simply pass a new model instance to the
TextClassifier component. For an entirely custom NLP solution, you only need
to provide two functions: one which assigns scores to the text, and another
which updates the model on a new batch of examples. If your text classification
solution only supports batch training, you can use the built-in model during
annotation, and then export the annotations to train your solution separately.
Evaluating the model
Within the first hour of annotation, the system classified 140 out of the 156 evaluation issues correctly. To put this into some context, we have to look at the class balance of the data. In the evaluation data, 65% of the examples were labelled reject, i.e. they were tagged as not documentation issues. This gives a baseline accuracy of 65%, which the classifier easily exceeded. We can get some sense of how the system will improve as more data is annotated by retraining the system with fewer examples.
prodigy textcat.train-curve gh_issues --label DOCS --eval-split 0.2
% ACCURACY25% 0.73 +0.7350% 0.82 +0.0975% 0.84 +0.02100% 0.87 +0.03The train curve shows the accuracy achieved with 10%, 25%, 50% and 75% of the training data. The last 25% of the training data brought 3% improvement in accuracy, indicating that further training will improve the system. Similar logic is used to estimate the progress indicator during training.
Exporting and using the model
After training the model, Prodigy outputs a ready-to-use
spaCy model, making it easy to put
into production. spaCy comes with a handy package
command that converts a model
directory into a Python package, allowing the data dependency to be specified in
your requirements.txt. This gives a smooth path from prototype to production,
making it easy to really test the model, in the context of a larger system.
Model training and packaging
Usage in spaCy v2.0.0 alpha+
If annotation projects are expensive to start, you have to guess which ideas look promising. These guesses will often be wrong, because it’s difficult to predict the performance of a statistical model before the data has been collected. Prodigy helps you break through this bottleneck by dramatically reducing the cost of investigating new ideas. The whole annotation process is cheaper with Prodigy, but it’s the time-to-first-evidence that’s most important. There’s no shortage of ideas that would be incredibly valuable if they could be made to work. The shortage is in time to investigate those opportunities – which is exactly what Prodigy gives you more of.
Try Prodigy!


