
- 17 minute read
- Blog
- Ellf
- Distillation
- Evaluation
- NLP Strategy, LLMs

Applied Natural Language Processing is about breaking complex business problems down into small parts you can build, test, and trust on their own – and doing it again and again. The best framework I’ve found for thinking about this comes from an unlikely place: web design.
Atomic Design is a popular methodology for creating and designing interfaces for the web, developed and published by Brad Frost. I still remember the buzz around it when the book came out, and it immediately spoke to me: instead of designing pages, you designed a system – a set of small, reusable parts that combined into larger ones. It was hugely impactful, and it really paved the way for modern design systems and web application architecture.
As we’ve been working on our new tool Ellf, talking to teams about their workflows and distilling our best practices for solving NLP problems, I couldn’t help but notice the parallels. The way Atomic Design talks about components, composition, separation of concerns, and iteration maps almost one-to-one onto the way we’ve been thinking about applied NLP.
The atomic hierarchy
Atomic Design borrows its vocabulary from chemistry. You start with the smallest indivisible units and build up: atoms combine into molecules, molecules into organisms, organisms arrange into templates and pages. Each level has a clear responsibility, and you can reason about the whole system or zoom into single parts.
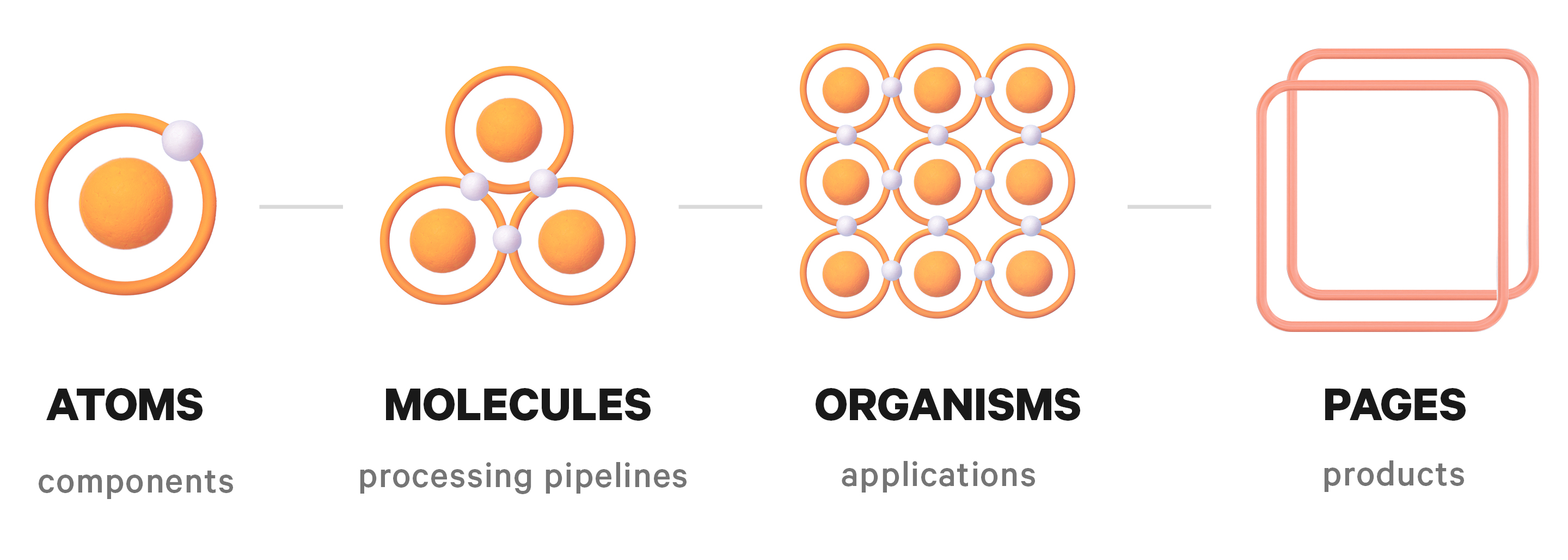
Atoms: NLP components
On the web, atoms are the basic HTML elements that can’t be broken down any further – for example, an input field or a button. In NLP, atoms are components: single, self-contained units that do one thing, like a text classification model or a dictionary lookup. (In spaCy for instance, these map pretty directly to pipeline components. Each one takes a document, annotates it, and passes it along.) An atom isn’t necessarily a model, it’s the smallest meaningful unit of work in the system.
Creating simple components helps UI designers and developers adhere to the single responsibility principle, an age-old computer science precept that encourages a “do one thing and do it well” mentality. Burdening a single pattern with too much complexity makes software unwieldy. — Atomic Design
The same is true for NLP, and even more broadly for AI applications. Dedicated, task-specific components can be developed and distilled with the help of larger LLMs and come with many benefits in practice:
- More accurate: A component with one narrow task can be optimized explicitly, including with task-specific data. A model asked to extract “product name” will reliably beat a model asked to extract “the latest model that has a touchscreen and is currently in stock,” because the latter isn’t really a language problem at all.
- Faster: Large, general-purpose models, especially behind an API, are slow. Small task-specific components run much faster, and you only pay the cost of the heavy machinery on the parts that actually need it.
- More reliable: Every dependency on a third-party provider or a complex piece of infrastructure can go down, rate-limit you, or change underneath you. Small components you run yourself fail in fewer and more predictable ways.
- Cheaper: Companies have started paying a lot more attention to their cloud and API bills, and per-token LLM costs add up fast at scale. If you can answer a question with a smaller component, paying for a frontier-model call on every record can be wasteful. (If expensive models are only used for development, the cost is much easier to control.)
- More transparent: When each step is doing one legible thing, you can look at it, test it, and trust it. A monolithic end-to-end call is a black box – a pipeline of atoms is something you can actually inspect.
- Independent: Running your own components on open-source software keeps your stack under your own control, rather than tied to a handful of big tech providers (and, if you’re in Europe or elsewhere, to US-based infrastructure). You avoid vendor lock-in and your data can stay on your own infrastructure.
Molecules: NLP pipelines
Just like in chemistry, molecules are groups of atoms bonded together to serve a purpose. On the web, that can be a search form: a label atom, an input atom, and a button atom that work together in context. In NLP, molecules are processing pipelines – combinations of component atoms wired into a sequence.
A molecule can contain several instances of the same atom configured differently, like two matchers with different pattern sets, multiple classifiers for different label schemes or LLM calls with different prompts. The molecule is still simple enough to reason about and reuse, but it now does something genuinely useful: process raw text and output structured annotations.
This is also the level where many applied NLP design decisions happen: which parts need a model, which parts are better as rules, and where to use a larger LLM versus a smaller, specialized model. And, just as importantly, it gives you a place to insert quality checks between steps so you can validate and debug each component independently.
Organisms: NLP applications
Organisms are more complex patterns made of molecules, atoms, and sometimes other organisms. On the web, a header might combine a logo atom with a search form molecule and a navigation molecule. In NLP, an organism is an application with a specific purpose.
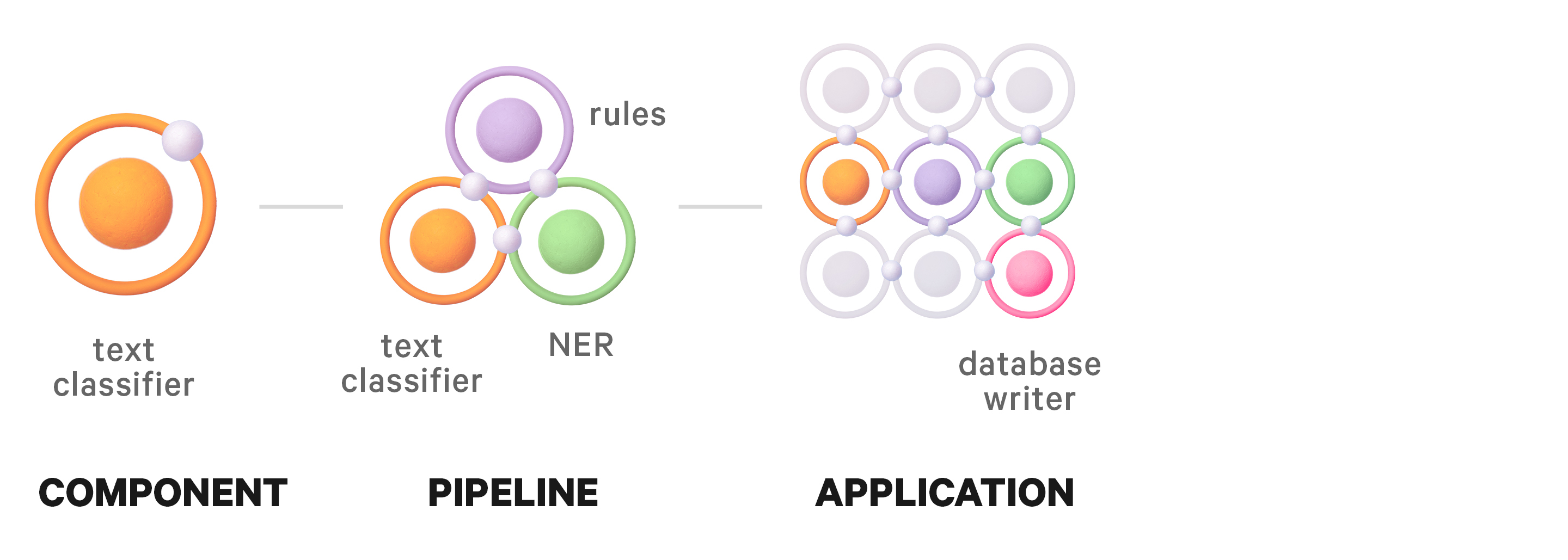
For example, take a system that processes incoming documents and populates a database. It contains a text processing pipeline molecule – say, rule-based matchers plus a text classifier plus an NER component – alongside atoms for loading the data and writing the results to the database. The organism is the thing that does a real job end to end, but it’s still composed of parts you can recognize, swap, and test in isolation.
Pages: NLP-powered products
At the top, Atomic Design has templates and pages – the concrete, real-world thing a user actually touches. In NLP, this is the product: for example, a CRM that surfaces the structured data extracted by the processing organism. This is where the NLP “disappears” into something a business actually uses.
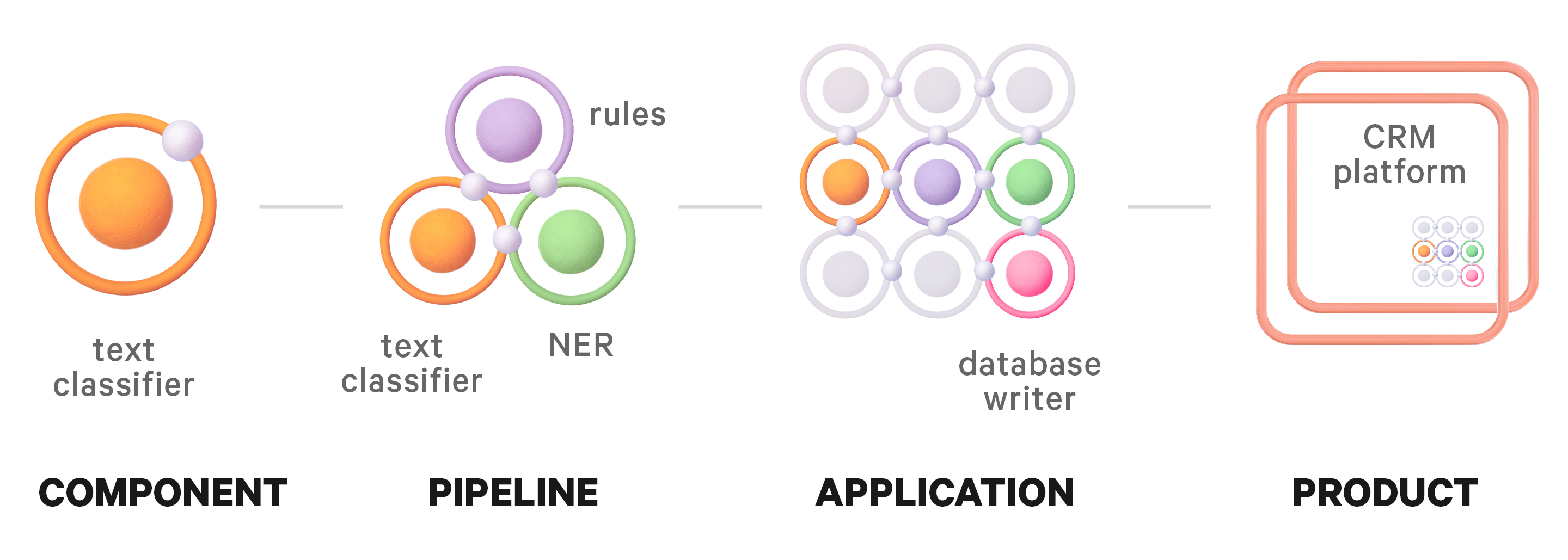
Many business problems come up at the product level. For example, the sales team might want a feature to automatically populate custom fields in the CRM from incoming emails. Your job now as an engineer is to translate it into organisms, molecules, and atoms, like an email extraction system (organism) containing a data cleaning step, followed by a processing pipeline (molecule) that uses an NER component plus business-specific post-processing rules (atoms).
You might start off with a prototype using a single LLM call, then work on optimizing it for accuracy and efficiency by breaking it down into smaller parts and reusing existing components and patterns for a DRY approach.
The benefits of an atomic mindset
Aside from giving you a shared vocabulary to reason about the parts of your system, Atomic NLP also promotes a set of good habits that are very helpful for applied work.
Moving between the abstract and the concrete
One of the biggest advantages atomic design provides is the ability to quickly shift between abstract and concrete. — Atomic Design
In NLP terms, the abstract end is the machine learning methodology: the techniques, model choices, or annotation strategy. This is the “how”. The concrete end is an application solving an actual business problem, the “what”.
A large amount of what makes NLP projects succeed or fail happens in the translation between those two – and the “what” is usually the harder and more neglected half. It’s tempting to jump straight to the “how” (which model, which prompt, which framework) before you’ve nailed down what the system actually needs to do and how you’ll know it’s working. Atomic NLP gives you a structure for moving between the two: you can zoom out to “what business question are we answering” and zoom in to “is this NER component good enough yet”. This is also the core of what we’ve called Applied NLP Thinking.
You also shouldn’t expect the “what” to be trivial. A problem we see sometimes is that people assume that the “what” is trivial, simply because there’s not much discussion of it, and all you ever hear about is the “how”. — Applied NLP Thinking
Separating structure from content
Atomic design provides us a structure to navigate between the parts and the whole of our UIs, which is why it’s crucial to reiterate that atomic design is not a linear process. — Atomic Design
The NLP equivalent is the separation between your machine learning methodology and general-purpose features on one side, and your business logic and specific use cases on the other.
This is one of the most consequential design decisions you make, and it’s easy to get wrong. Asking a model to predict “is this the latest product model?” bakes a fact that changes over time into something that’s expensive and slow to retrain. The better design is to have the model extract a general-purpose, stable feature – “this is a product name” – and then let ordinary business logic (e.g. a database lookup, a date comparison) decide whether it’s the latest one. The model does the language, your code does the facts. When the business question changes, you change a line of logic, not a training set.
This is also where Atomic NLP pushes back against LLM maximalism – the instinct to treat every problem as one giant generative call. A single end-to-end prompt collapses structure and content into one inscrutable blob. You can’t optimize part of it, you can’t test part of it, and you can’t reuse part of it.

Instead of throwing away everything we’ve learned about software design and asking the LLM to do the whole thing all at once, we can break up our problem into pieces, and treat the LLM as just another module in the system. — Against LLM maximalism
None of this means that the maximalist approach is always wrong – some use cases genuinely need a big model, and LLMs are very useful tools, especially for development. It just means “one model to rule them all” shouldn’t be the default at runtime when reliability, cost, and transparency are important factors.
The atomic workflow
The atomic approach comes with a distinct way of working. The most important takeaway here is that deliberate choices pay off. Atomic NLP front-loads some planning, like breaking the larger business problem into steps, deciding what’s a rule and what’s a model, and designing the individual components. That’s more work upfront than firing off a prompt. But it’s exactly that upfront deliberation that makes the later work efficient and the system’s behavior transparent and cost-controlled. This is also where coding assistants shine: they’re very good at managing the resulting complexity once the structure is in place, which lowers the cost of doing things properly.
NLP development is not a linear march from spec to model to deployment. It’s iterative. You build a rough pipeline, look at the data, discover your label scheme was wrong, fix it, retrain, find a new failure mode, and go again. An atomic structure is what makes that iteration cheap: when your system is a set of well-separated parts, you can change one without re-deriving the whole.
The web had the same blind spot in its early days, when it was treated as a fixed, print-like medium:
This print-like perspective of the web reinforced the notion that web designs, like their offline counterparts, could and should look the same in every environment. — Atomic Design
It took years for the field to let go of that and embrace the web as a fluid, responsive medium. AI is going through its own version of this shift right now. We’re moving from a static, artifact-like view of a “model” toward something defined by human action and interaction – systems that sit inside real workflows, get used by real people, and have to keep working as the world around them moves. Good NLP, like good web design, isn’t a finished object you ship once.
The hard part: tooling and “NLP debt”
If an atomic approach is so obviously better, why don’t we all work this way? Why don’t we build more custom classifiers, and why is the maximalist approach so tempting and widespread?
I believe that the biggest bottlenecks aren’t conceptual – they’re time and resources. Even when you know exactly what the best practices are, following them is operationally annoying. Setting up annotation, wiring components together, standing up an evaluation harness, reviewing results, keeping data and code in sync across a team – each of these introduces friction. As a result, teams often cut corners.
Over time, this accumulates into something you could call NLP debt, the machine learning cousin of tech debt. With every change, you become a little less confident that what you’re doing is actually improving the results. As the application grows, it becomes harder and harder to reason about, until eventually nobody wants to touch the thing that’s quietly making decisions in production.
A lot of MLOps tooling only starts at the training step – it assumes the data already exists, fully formed, and just needs a model trained on it. But in applied work, the data is the project. The valuable and high-leverage work is in data development: deciding what to annotate, breaking annotation into small and fast decisions, iterating on the label scheme, and keeping a robust evaluation set.
What the atomic approach actually needs from its tooling is:
- Treat data development as a first-class step, not an afterthought to training, and make it efficient and automated.
- Make it easy to run and monitor lots of stuff and give agents the ability to plan and execute things for you.
- Keep a shared state of the steps and progress and allow cross-disciplinary collaboration.
- Integrate with what developers already use: IDEs, AI-powered coding assistants, and the open-source ecosystem.
(This is also more or less what we’ve been building with Ellf: a platform that runs compute and stores data on your own infrastructure, ships with Prodigy for annotation, provides auto-annotation agents, plugs into coding assistants like Claude Code, has access to NLP expertise and best practices, and treats the full lifecycle – data, annotation, training, evaluation, iteration – as one connected workflow rather than a pile of disconnected steps.)
You can’t escape evaluation
Many of the problems developers are facing, like NLP debt and the creeping loss of confidence, could “easily” be solved by setting up a proper evaluation. It’s the step everyone knows they should do, but in practice, it’s often skipped or glossed over.
The problem is, vibes-based testing and LLM-as-a-judge can only take you so far. Trying out a handful of examples you happened to think of doesn’t reflect the cases that actually matter in production. Using another LLM to grade your LLM can easily create a feedback loop with no outside reference point – it’s a bit like evaluating a model on its own training data.
Ultimately, you need labelled data: examples that match your runtime data and that you definitively know the answer to. That’s the only thing that lets you tell whether a change is a real improvement or just a different flavor of wrong.
Even if you’ve gone the maximalist route and built your whole system around a single end-to-end LLM call, you still need to know how it’s performing on your data. There is no architecture clever enough to free you from having to check whether it works.
The atomic approach doesn’t get you out of evaluation, but it can give you separable parts and can tell you which atom to fix when the number drops.
Maintaining and future-proofing solutions
Another aspect Atomic NLP covers and many projects underestimate is that the work doesn’t end at deployment or launch. AI systems aren’t static. The world changes, your input data drifts, and your requirements expand. A model that was great last quarter can quietly degrade without anything visibly “breaking”. An atomic system is one you can actually maintain: re-annotate one component’s data, retrain it, re-run the evaluation, ship it, without disturbing the rest.
Maintenance is also fundamentally cross-disciplinary. For NLP projects, this includes subject matter experts who actually know what the label scheme means, the project and product managers who keep the “what” in focus, and the stakeholders who decide which business questions need answers. Atomic NLP gives a mixed team a shared language for talking about the parts and the whole, and collaborating effectively on the end-to-end system.
Bringing it together
Atomic Design gave web development a way to think clearly about parts and wholes, move between the abstract and the concrete, iterate instead of waterfall, and keep structure separate from content. All of these ideas are very relevant to NLP development today, arguably more than ever, as the gravitational pull of “just ask the big model” makes it easy to cut corners or skip NLP engineering altogether.
At the end of the day, Atomic NLP is really just a name for doing the unglamorous thing well: small components that do one thing, composed deliberately into pipelines and applications, measured honestly against labelled data, and maintained by a team that shares a vocabulary. Giving it a shape – atoms, molecules, and organisms – makes it a lot easier to see what you’re building, and ship better and more ambitious NLP solutions.
💌 Work with us
If you’re looking to implement an atomic workflow for your project or want to test our new tool Ellf for agentic NLP development, get in touch! We currently have availability to take on new projects, and we want to work on as many as possible to improve our tools and solutions along the way.
Resources
- Atomic Design (Brad Frost, 2016): A methodology for creating design systems for the web
- Ellf: Our new virtual assistant and platform for agentic NLP development and atomic workflows
Blog posts
- Applied NLP Thinking: How to translate business problems into machine learning solutions
- Against LLM maximalism: LLMs beyond “one model to rule them all”
- A practical guide to human-in-the-loop distillation: How to distill LLMs into smaller, faster, private, and more accurate components
- The ultimate guide to optimizing annotation workflows: How to build efficient human-in-the-loop data development workflows
- What the history of the web can teach us about the future of AI: How developer tooling makes it possible to develop AI features in house
Talks
- Vibe NLP for Applied NLP: How to use agentic development to create practical and modular NLP solutions
- Building AI with AI: Why we should use LLMs to build systems instead of as systems and why code is more important than ever



