- 17 minute read
- Blog
- Prodigy, Case Study
- Text Classification
- Text Generation
- Finance


As many large financial institutions push to use Natural Language Processing (NLP) to digitize their customer support channels, smaller financial institutions like credit unions and community banks are having a tough time to keep pace. To address this need, Posh AI provides digital and voice AI concierge services targeted to smaller financial institutions who are seeking digital solutions to connect with their customers.

Posh focuses on developing custom NLP models trained on real-world banking conversations and custom models for each client’s unique customer base and product offering. To get their NLP models working effectively, the team needed to emphasize human annotation and experimentation, which is why Posh turned to Prodigy.
Prodigy’s design aspect was key. [With my previous annotation tools], I would get a lot of feedback from annotators, saying ‘it’s really hard, because I have to scroll and scroll and scroll to see the labels. There’s too many labels. There’s too many options.’ When I was looking at Prodigy I liked it because you could customize it.
— Cheyanne Baird, NLP Research Scientist for Posh AI
In a recent interview, Explosion talked with Cheyanne Baird, NLP Research Scientist at Posh, and discussed why Posh chose Prodigy for their annotation needs.
 Try the live demo!
Try the live demo!
In this post, we cover how Cheyanne and her team developed a complex multi-annotator platform around Prodigy with a custom cloud annotation service and annotation hub. We’ll also discuss how Cheyanne extended Prodigy’s interface to improve her annotators’ user experience, how she used the Prodigy community for help, and future work like integrating Prodigy’s OpenAI recipes to bootstrap annotations with zero-shot and few-shot learning.
Can you tell us about your team and what you’re working on?
Posh AI is a Boston, Massachusetts-based conversational AI and NLP technology development company. The company provides digital and voice concierge services for credit unions and community banks to automate customer questions and workflows on the web, SMS, and messaging apps for tasks like checking hours and making payments.
Cheyanne works on Posh’s NLP team, which has an interesting mix of data scientists and engineers with backgrounds in Linguistics, NLP, and AI, along with domain experts with experience working in credit unions.
Having a mix of data scientists with subject-matter experts enables their modelers to work directly on annotation and data collection problems. For example, their data scientists identified data problems like transcription errors and quickly adapted their annotation workflows to identify and correct these problems.
One of the team’s objectives is to think about scale. As Posh works with many banking customers, the team works with collectively millions of chats to discover conversational patterns that generalize “customer intent” across the financial industry. For every customer that works with Posh or interacts with their services, these interactions are fed back into the system and improve the system. In this way, even the smallest bank that works with Posh can leverage the collective insights Cheyanne and her team have discovered through their NLP workflows.
Given the scale of annotations, a lot of Cheyanne’s work is as an administrator of her team’s Annotation Service. Her responsibilities include overseeing the annotation process (e.g., annotation task design, assign annotation tasks, answer annotator questions on Slack), measuring annotator reliability and validating annotations, and maintaing annotation guidelines in an iterative refinement process.
Her workflow starts with annotation guidelines and corpus creation. Annotation guidelines define what the annotators are labeling, including examples to ensure consistency across multiple annotators. The corpus is the unlabeled data that will be annotated (e.g. customer chats or transcripts). Her annotation tasks typically include three people as annotators. The team uses Prodigy’s named multi-user sessions, which identify each annotation session with a unique session ID. Those annotations are evaluated on inter-annotator agreement (IAA) to measure the consistency of the labels.

Then as the administrator, Cheyanne validates tricky cases with domain experts to resolve annotator disagreements using Prodigy’s review recipe. Reconciled annotations are used as create gold standard annotations for model training.
I would say I do a lot of validating, which in a sense is annotating, because I’m going in and changing the labels or editing them.
Cheyanne also ensures her annotation process is as efficient as possible to improve planning and avoid wasting annotators’ time. For example, each annotator has a backup task in the queue with an understanding of the task and access to the guidelines so there are no gaps in annotation if Cheyanne is unavailable. In addition, she monitors annotation speed and relays progress to both annotators and stakeholders.
What are some NLP problems your team works on?
Cheyanne’s team builds the NLP solutions that drive Posh’s products. They use Prodigy for many common NLP tasks like multi-label intent classification, named entity recognition, and sentiment analysis to identify customer problems in data like call center chats or voice transcripts.
One of the team’s more unique use cases is its Helpful Banking Moments initiative, in which annotators categorize whether Posh’s chatbot has been helpful or not. Posh’s goal is to identify 1,000,000,000 Helpful Banking Moments, which means they’ll need a lot of annotations!
To decide on whether a chat was helpful, annotators review the full chat and determine whether their assistant provided helpful guidance. A chat can include multiple requests, or individual “banking moments”. For example, a member could ask for their balance and then ask about the credit unions’ hours. Or, a member could ask for information about a mortgage and then ask for their routing number.

An initial challenge the team had for this task was to design the ideal interface for presenting the chats and meta information. The team created a Prodigy custom recipe using an HTML template to provide a URL link so that annotators could link to the full chats in a different window.
Prodigy Shorts
Want to learn how to customize Prodigy for efficient chatbot annotations? In a recent short, Vincent D. Warmerdam shows how to create a custom Prodigy recipe using blocks for a chatbot annotations for both intent classifiction and span categorization with keyboard shortcuts for faster annotations. This video is part of Vincent’s Prodigy Shorts series, a playlist on our YouTube channel of quick lessons about Prodigy on topics like annotating on mobile phones, building custom interfaces with blocks, and custom labels for image annotation.
Another use case for Prodigy is Custom Intent Calibration. Posh developed a custom intents system known as Semantic FAQ, or SemFAQ. SemFAQ is an index of FAQ utterances stored in an embedding space generated by a language model. Some customers want to calibrate the model for their own purposes (e.g. unique product names or terminology), so the Posh team created Custom Intent Calibration to adapt SemFAQ to each client’s specifications.

To start, Posh’s customers (credit unions) create custom intents and populate them with example questions and custom responses. Then Posh’s NLP team uses cosine similarity to measure the similarity between the member’s utterance and all the FAQ Custom Intent utterances, returning the most similar custom intent for that utterance.
But using unsupervised cut-off similarity scores has limits. Posh’s experiments have found that the embedding space is sensitive to superficial morphological, lexical changes (e.g. punctuation, typos) where the expectation is that semantic similarity should have been preserved. Therefore, the team created this annotation task to “calibrate” the model. They also perform inter-annotator agreement with multiple annotators on the same dataset to evaluate the differences.
Can you describe your Annotation Service and how does Prodigy fit in?
Before Cheyanne joined the team, annotations were mostly done in spreadsheets. With Prodigy, they now have a flexible and efficient system in place to collect, label and manage their annotated data. As the team has become more successful, they’ve added more annotators to keep pace with their customers’ growing appetite for annotations. To handle this growth, they needed an end-to-end service around Prodigy, one built in the cloud so the team could scale up their resources.
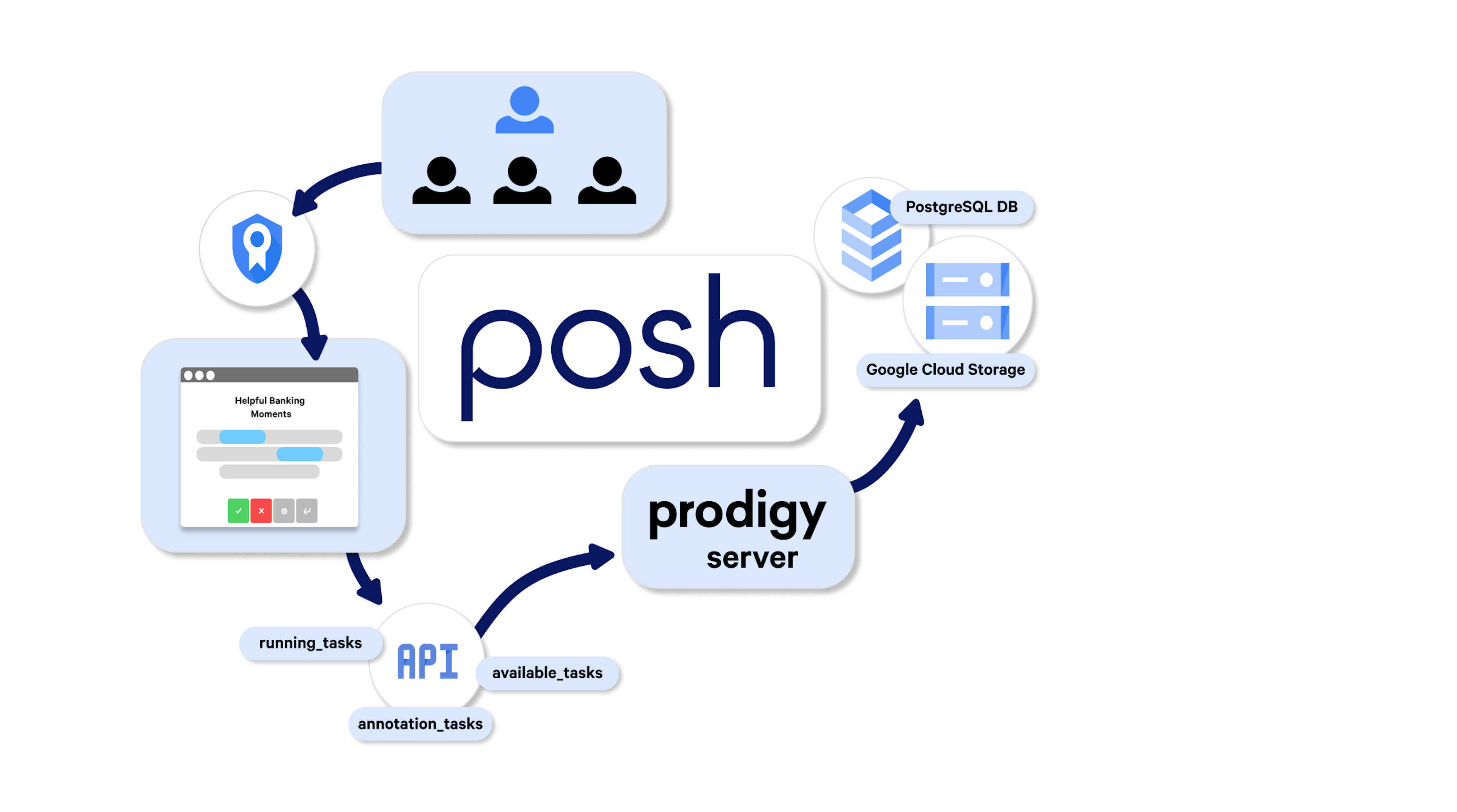
The team developed a custom cloud annotation service around Prodigy. The service runs as a Kubernetes workload on the Google Cloud Platform, deployed with helm via GitLab CI/CD.

Their service has multiple components. Prodigy instances are run on a cloud server that uses Python multiprocessing to start a separate Prodigy instance per annotation task, each served on a separate URL using named multi-named sessions. The team recently expanded their server to run more than five concurrent instances.
On the back-end, the annotations are then saved to a PostgreSQL database within a CloudSQL instance. They also have a dedicated Google Cloud Storage (GCS) bucket that contains the recipe configurations and the input data files, managed with Git and Data Version Control.
For front-end authentication, they created an OAuth2 server to authenticate annotators and administrators with their Google credentials. They also have a FastAPI interface where annotators select their annotation task and where administrators can manage the tasks. Behind their FastAPI interface, the team developed three endpoints that enable annotators to select their tasks and administrators like Cheyanne to manage the tasks.
How do you manage your documentation and the development around your service?
With their annotation service in place, Cheyanne and team found their annotators also needed a central location for documentation like annotation guidelines and task definitions. Such a place is especially important when onboarding new annotators or adding new tasks. Therefore, Cheyanne and her team created an annotation hub, which is a repository for annotation documents and development tracking of their annotation service.

The hub offers video tutorials and general best practices for annotators and data scientists. The tutorials also cover NLP concepts to help annotators understand how their annotations will be used in model training and evaluation.
The annotation guidelines in the hub also include best practices for handling examples from different channels like IVR, web, mobile or banking. This can be particularly useful for dealing with tricky or ambiguous cases as annotators can review examples of how similar cases were annotated in the past.
To track platform issues and upgrades, the hub also includes a Prodigy wishlist and issue tracker with links to open issues on the Prodigy Support forum. This tracking helps Posh’s engineers stay up-to-date on the latest developments with Prodigy and track issues they’ve been troubleshooting.
For tasks where annotators are asked to validate the intent recognition model, the Posh team created a Streamlit app that allows them to search the intent corpus for existing coverage. Since there are frequent edits to the corpus due to bug fixes and redesigns, this process lets the annotators see the most up-to-date coverage without needing access to the repositories or relying on out-of-date documentation.
What annotation tools have you used and why did you choose Prodigy?
Cheyanne’s past experience with annotation was mainly with in-house tools due to data privacy concerns. That experience affected her decision for Prodigy.
[In my past roles], I learned a lot about what I what I don’t like for annotations and what was frustrating about it. For example, it was very hard to change labels. It’s very important for [annotators] to look at something where they get all the information they need, it’s not overwhelming, and it’s easy to understand. And so there was just no design put into it.
Prodigy’s design of simplicity plus extensibility, as well as the existing community around Prodigy stood out for Cheyanne. Specifically, she found Prodigy’s support forum helpful so she wasn’t starting from scratch. The forum currently has over 20,000 posts with nearly 3,000 community users.
I liked that Prodigy had a community [where] you could get answers. It wasn’t going to be hard to find similar problems other people have experienced.
How have you experimented with Prodigy’s interfaces?

As an NLP Research Scientist, Cheyanne’s role is to experiment. A big part of her experimentation is how to design her annotation workflows, such as what information to show, how to display that information, and what information to capture from annotators. Like the custom intent calibration task, Cheyanne developed a custom Prodigy recipe that added custom HTML and CSS and used Prodigy’s blocks feature to combine interfaces.
I really like that [at Posh] we’re creating something that makes people’s lives easier. I love how Posh lets us experiment and do research.
Prodigy is designed for fast, iterative experimentation
Prodigy is a commercial product but has the look and feel of an open source library. It’s a developer’s annotation tool and designed to be extensible and customized. Its design works best with fast experimentation as you may need to reframe the problem to align with the product vision for how it’ll be used. Prodigy enables developers to rapidly iterate on the data to overcome the chicken-and-egg problem. Ines outlined this problem in her “Designing Practice NLP Solutions” talk:
One problem Cheyanne realized in her early annotation workflows was that transcripts had many speech-to-text errors. If ignored, these errors could add noise for downstream modeling. So she decided to expand the information captured by annotators in Prodigy by adding a checkbox to the interface to report errors.
 errors that needed to be identified during annotation. Cheyanne needed to add a checkbox so annotators could reports STT errors.")
To add the checkbox, Cheyanne found Prodigy’s documentation on customizing Prodigy’s interface with HTML templates. But when she tried, the checkbox results didn’t immediately show up in the output as she expected. So she asked for help on Prodigy’s developer support forum, and Vincent helped with a slight variation that worked for Cheyanne.

Like adding checkboxes, Cheyanne used Prodigy Support for other questions that came up designing her custom recipes. Some additions were for design aspects like reducing the text’s font size. Others provided additional user tracking so that annotators could monitor their progress bar, debugging flagging, and adding open-ended text inputs. These issues combined to provide interface extensions within Posh’s custom recipes, enabling the team to capture more annotator information and improve user experience for tasks like custom intent calibration.

What are future goals for your team?
Cheyanne and the Posh NLP team have several future goals to improve their NLP workflows.
The team has started to experiment with generative AI through Prodigy’s OpenAI recipes to develop a gold-standard dataset much faster through zero-shot or few-shot learning. The idea is to use a large language model to generate training data based on prompts and to validate them as correct. This is very similar to Prodigy’s correct recipes like ner.correct and textcat.correct, but they’re using GPT-3 as a backend model to make predictions.
Updates coming to Prodigy in 2023 🚀
In addition to our new Prodigy’s OpenAI recipes, we just released Prodigy v1.11.9 and v1.11.10 for fixes to improve multi-user annotation handling, especially in high latency scenarios, and compatability with spaCy 3.5. But we’ve got a lot more planned in 2023. Our upcoming Prodigy v1.12 will provide:
- improved progress estimation
- data validation
- task stream customization
- integrate OpenAI components for large language models (LLM) These changes will then lead to our release of Prodigy Teams later this year. Prodigy Teams is our hosted version of Prodigy that adds collaboration and production stability features, while maintaining the data privacy and programmability.
Second, they plan to add more time tracking functionality to better estimate how much time each task will take to complete. For example, the team is working on developing a dashboard workflow for annotations on stats on annotator progress and upcoming queues as well as on-demand annotation downloads.
A related goal is to create ways to address flagged examples sooner. Currently, the team uses Prodigy’s flagging functionality to enable annotators to send tricky examples for review. One possible addition is a callback after each annotation to check it for consistency with previously flagged examples. Using Prodigy’s validate_answer callback, they could identify similar text examples from the guidelines via a similarity metric like cosine similarity.
Annotators would then be notified with an alert for inconsistent labels, e.g. if they choose Helpful but the most similar instance was labeled as Not Helpful. This way, the validation callback could double-check annotators’ answers and reduce flagged examples.
Pseudocode of Prodigy recipe with a validation callback
Resources
- Prodigy: A modern annotation tool for NLP and machine learning
- Custom Interfaces with Prodigy: Documentation and examples
- Prodigy OpenAI Recipes: GitHub Repo
- The Guardian Case Study with spaCy and Prodigy: How the Guardian approaches quote extraction with NLP
- Cheyanne Baird’s Posh Employee Spotlight
- Case Studies: Our other real-world case studies from industry



