Explosion builds developer tools for AI, Machine Learning and Natural Language Processing. →
Consulting
Consulting










🛸 spacy-transformers v1.1.0
Better serialization, full ModelOutput, mixed-precision training and more
















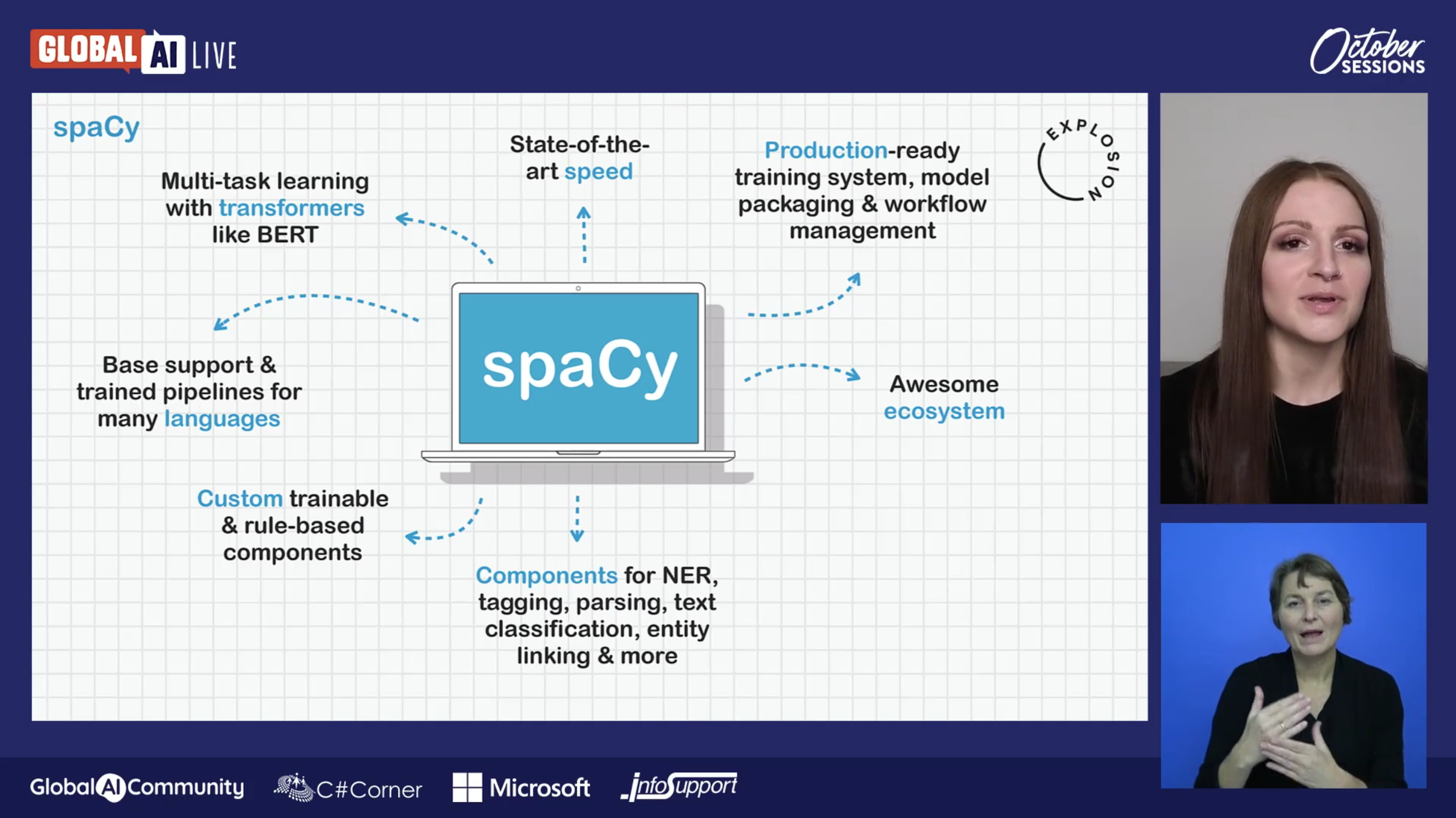

Better serialization, full ModelOutput, mixed-precision training and more