The Future of NLP in PythonPyCon Colombia KeynoteThe data community came to Python for the language, and stayed for each other – once it got critical mass, it’s the ecosystem that counts. We’ve been proud to be part of that. So what does the future hold for NLP in Python?
Introducing spaCy v2.1Version 2.1 of the spaCy Natural Language Processing library includes a huge number of features, improvements and bug fixes. In this post, we highlight some of the things we're especially pleased with, and explain some of the most challenging parts of preparing this big release.
Frag deinen Kühlschrank: Wie künstliche Intelligenz die Welt verändertARD alpha Documentary (German)In this documentation we explore what it feels like to work with intelligent machines. At large research centers and small start-ups we meet people who decide how and what AI learns today. Ines Montani teaches machines to understand the meaning of texts. Even for the young programmer, artificial intelligence is not magic, but a technology that everyone should understand.
How to Ignore Most Startup Advice and Build a Decent Software BusinessEuroPython Keynote“In this talk, I’m not going to give you one "weird trick" or tell you to ~* just follow your dreams *~. But I’ll share some of the things we’ve learned from building a successful software company around commercial developer tools and our open-source library spaCy.”
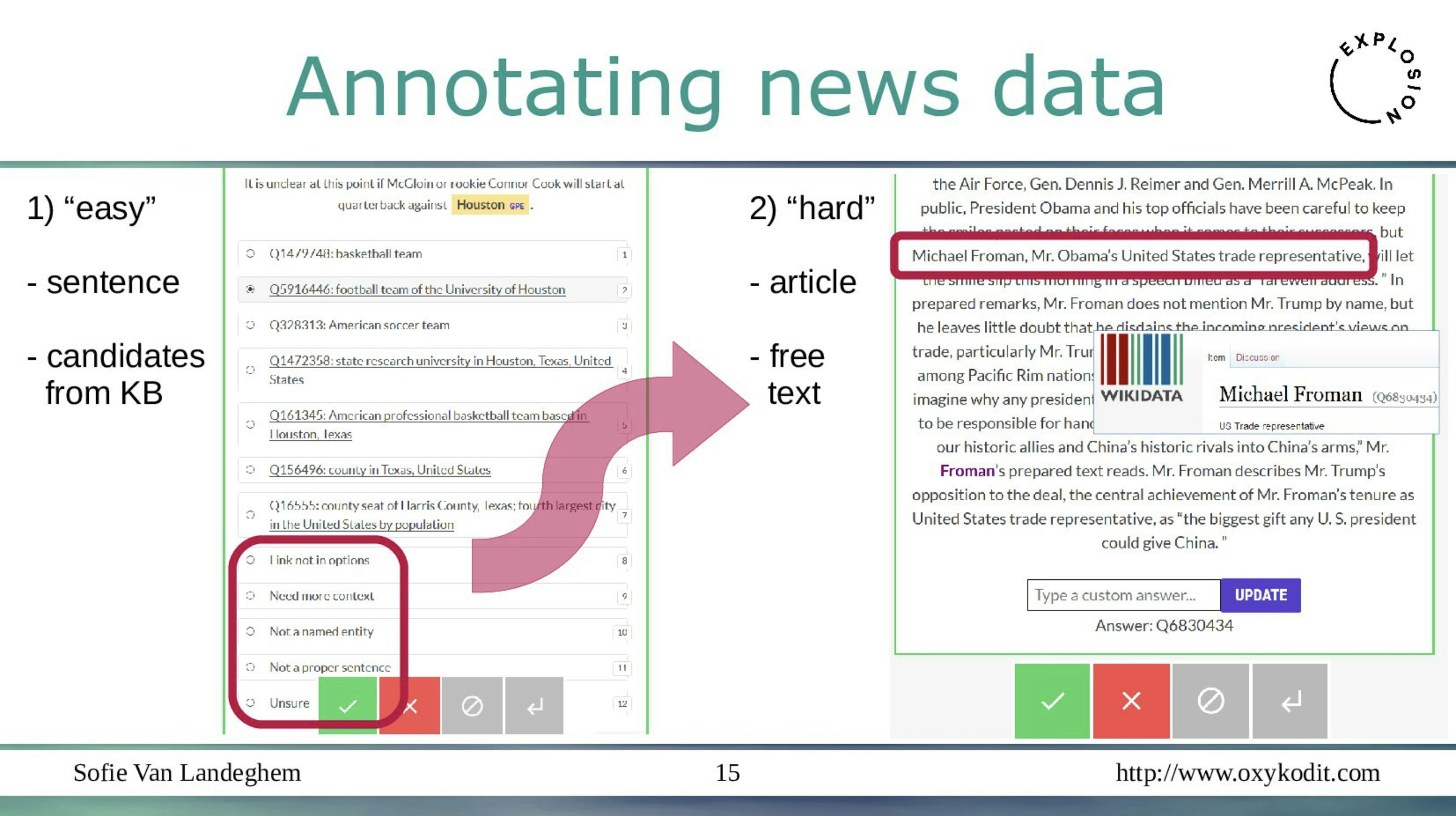
Rapid NLP annotationData Science SummitThis talk presents a fast, flexible and even somewhat fun approach to named entity annotation. Using our approach, a model can be trained for a new entity type in only a few hours, starting from only a feed of unannotated text and a handful of seed terms.
Training a new entity type with Prodigy – annotation powered by active learningIn this video, we’ll show you how to use Prodigy to train a phrase recognition system for a new concept. Specifically, we’ll train a model to detect references to drugs, using text from Reddit.
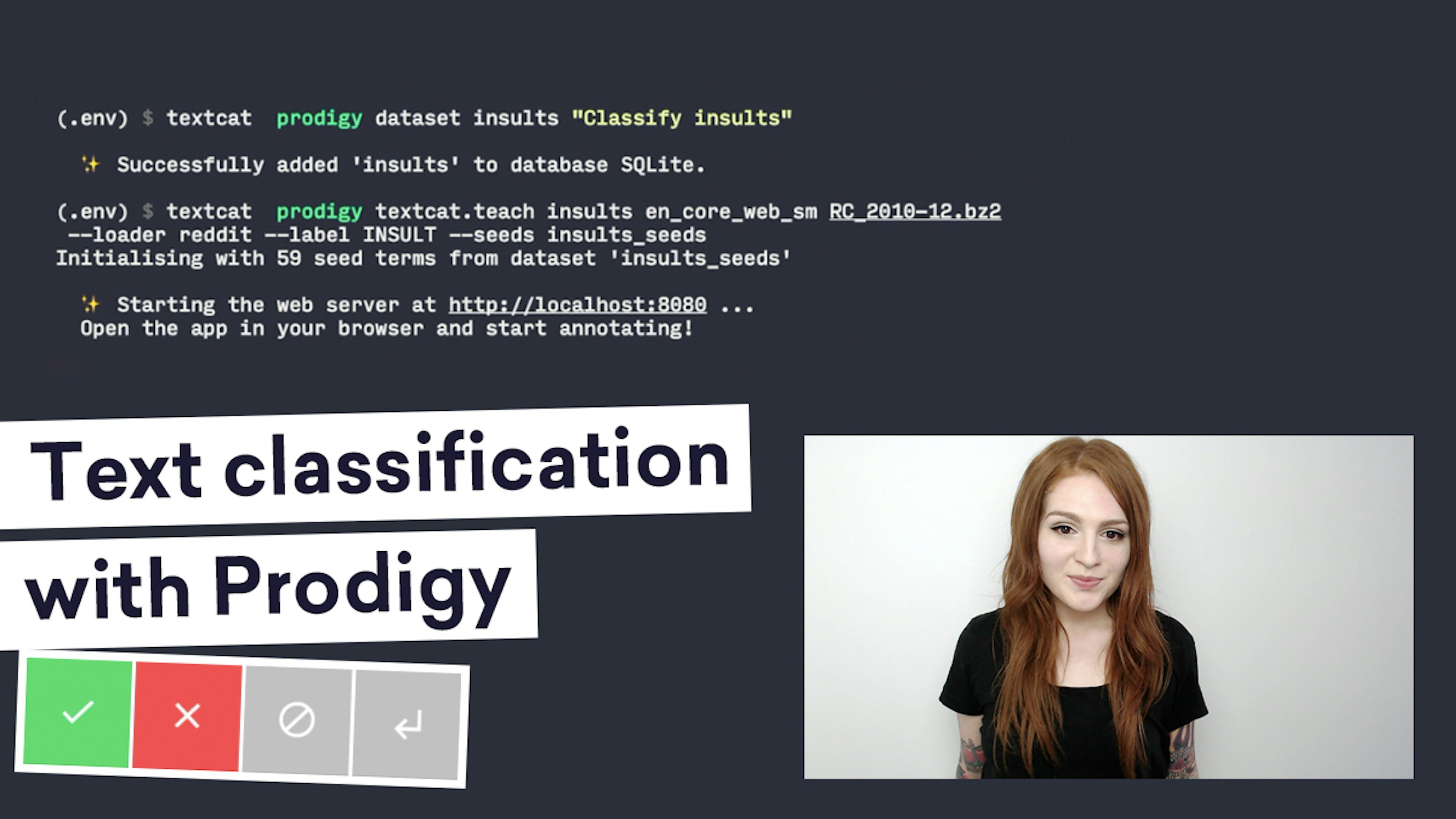
Training an insults classifier with Prodigy in ~1 hourIn this video, we’ll show you how to use Prodigy to train a classifier to detect disparaging or insulting comments. Prodigy makes text classification particularly powerful, because you can try out new ideas very quickly.
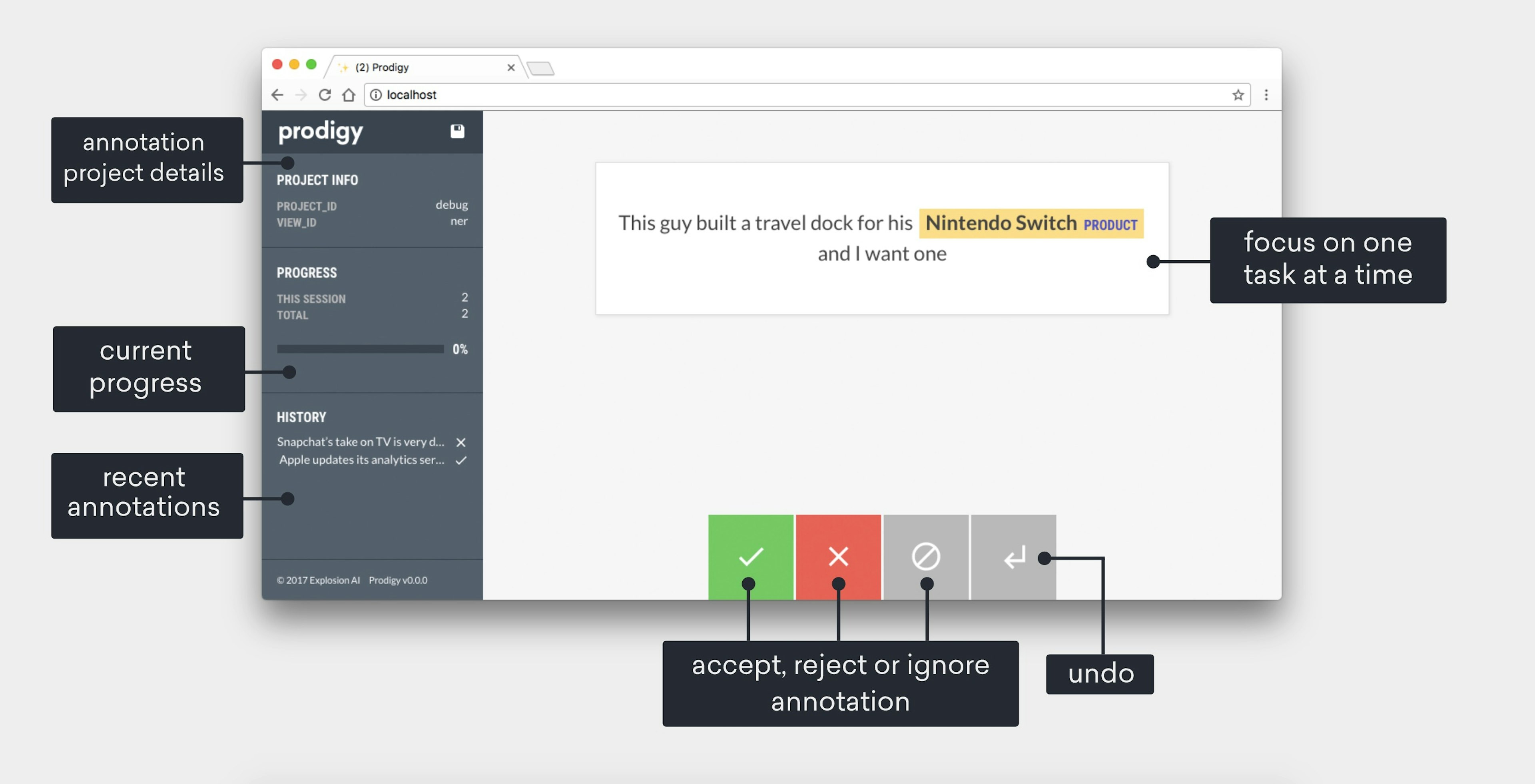
Prodigy: A new tool for radically efficient machine teachingMachine learning systems are built from both code and data. It's easy to reuse the code but hard to reuse the data, so building AI mostly means doing annotation. This is good, because the examples are how you program the behaviour – the learner itself is really just a compiler. What's not good is the current technology for creating the examples. That's why we're pleased to introduce Prodigy, a downloadable tool for radically efficient machine teaching.
Explosion in 2019: Our Year in ReviewAs 2019 draws to a close and we step into the 2020s, we thought we’d take a look back at the year and all we’ve accomplished. And we realized we had so much that we could give you a month-by-month rundown of everything that happened.
sense2vec reloaded: contextually-keyed word vectorsIn 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. That work is now due for an update. In this post, we present a new version and a demo NER project that we trained to usable accuracy in just a few hours.
spaCy meets Transformers: Fine-tune BERT, XLNet and GPT-2Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. You can now use these models in spaCy, via a new interface library we've developed that connects spaCy to Hugging Face's awesome implementations.
What 1.2 million parliamentary speeches can teach us about gender representationThe PuddingAnalysis of parliamentary speeches using spaCy.
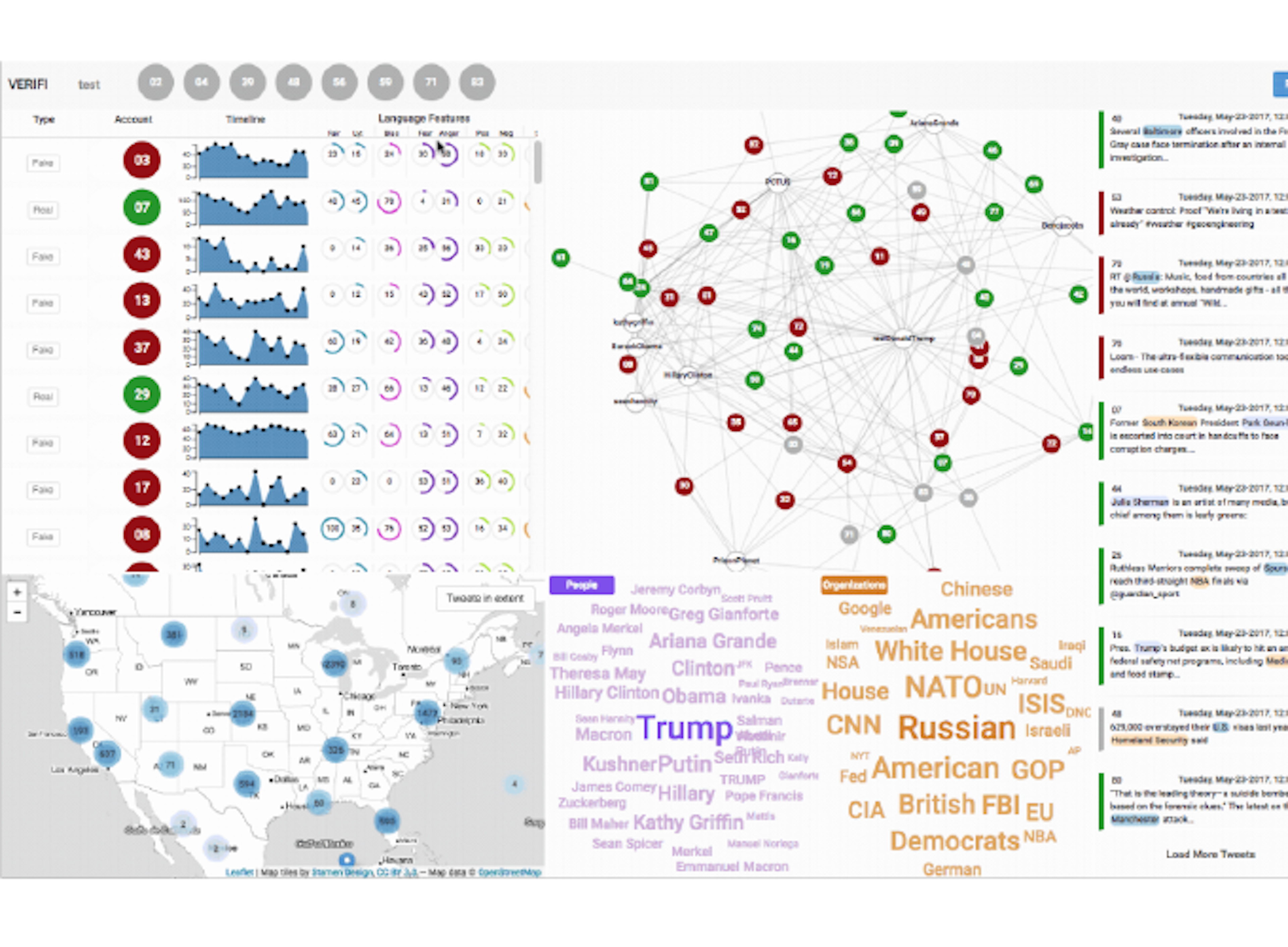
Can You Verifi This? Studying Uncertainty and Decision-Making About MisinformationKarduni, Wesslen, Santhanam, Cho, Volkova, Arendt, Shaikh, Dou (2018)HCI interface to identify misinformation on social media using spaCy for NER.
More than a Million Pro-Repeal Net Neutrality Comments were Likely FakedHackernoonAnalysis of net neutrality comments by Jeff Kao using spaCy for word vectors.
Reflections on running spaCy: commercial open-source NLPines.ioAs more and more people and companies are getting involved with open-source software, balancing the expectations of an open community and a traditional provider vs. consumer relationship is becoming increasingly difficult. Are maintainers becoming too authoritarian? Are users becoming too demanding? Are large companies selling out open-source?
Interview with Ines MontaniSayak PaulInes talks about how she got into programming, how to stay up to date with the latest developments in our field and the ideas behind the PyCon India keynote “Let Them Write Code”.
Explosion awarded META Seal of RecognitionWe’re proud to accept the META Seal of Recognition at META-FORUM in Brussels, along with Mozilla. The META-FORUM is an international conference series backed by the European Union on powerful and innovative Language Technologies for a multilingual information society.
Millennials Kill EverythingThe PuddingAnalysis on media reporting of millenials using spaCy. From napkins to marriage to Applebees, just looking at headlines you’d guess that for the past decade the millennial generation’s been on a rampage.
✨ prodigy v1.8.0May 20, 2019Support for spaCy v2.1, basic auth, multi-user sessions, review workflow & more
FAQ #1: Tips & tricks for NLP, annotation & training with Prodigy and spaCyIn this video, Ines talks about a few frequently asked questions and shares some general tips and tricks for how to structure your NLP annotation projects, how to design your label schemes and how to solve common problems.
The AI Revolution will not be MonopolizedHack TalksWho’s going to "win at AI"? There are now several large companies eager to claim that title. Others say that China will take over, leaving Europe and the US far behind. But short of true Artificial General Intelligence, there’s no reason to believe that machine learning or data science will have a single winner. Instead, AI will follow the same trajectory as other technologies for building software: lots of developers, a rich ecosystem, many failed projects and a few shining success stories.
Building new NLP solutions with spaCy and ProdigyPyData Berlin“Commercial machine learning projects are currently like start-ups: many projects fail, but some are extremely successful, justifying the total investment. While some people will tell you to embrace failure, I say failure sucks — so what can we do to fight it? In this talk, I will discuss how to address some of the most likely causes of failure for new NLP projects.”
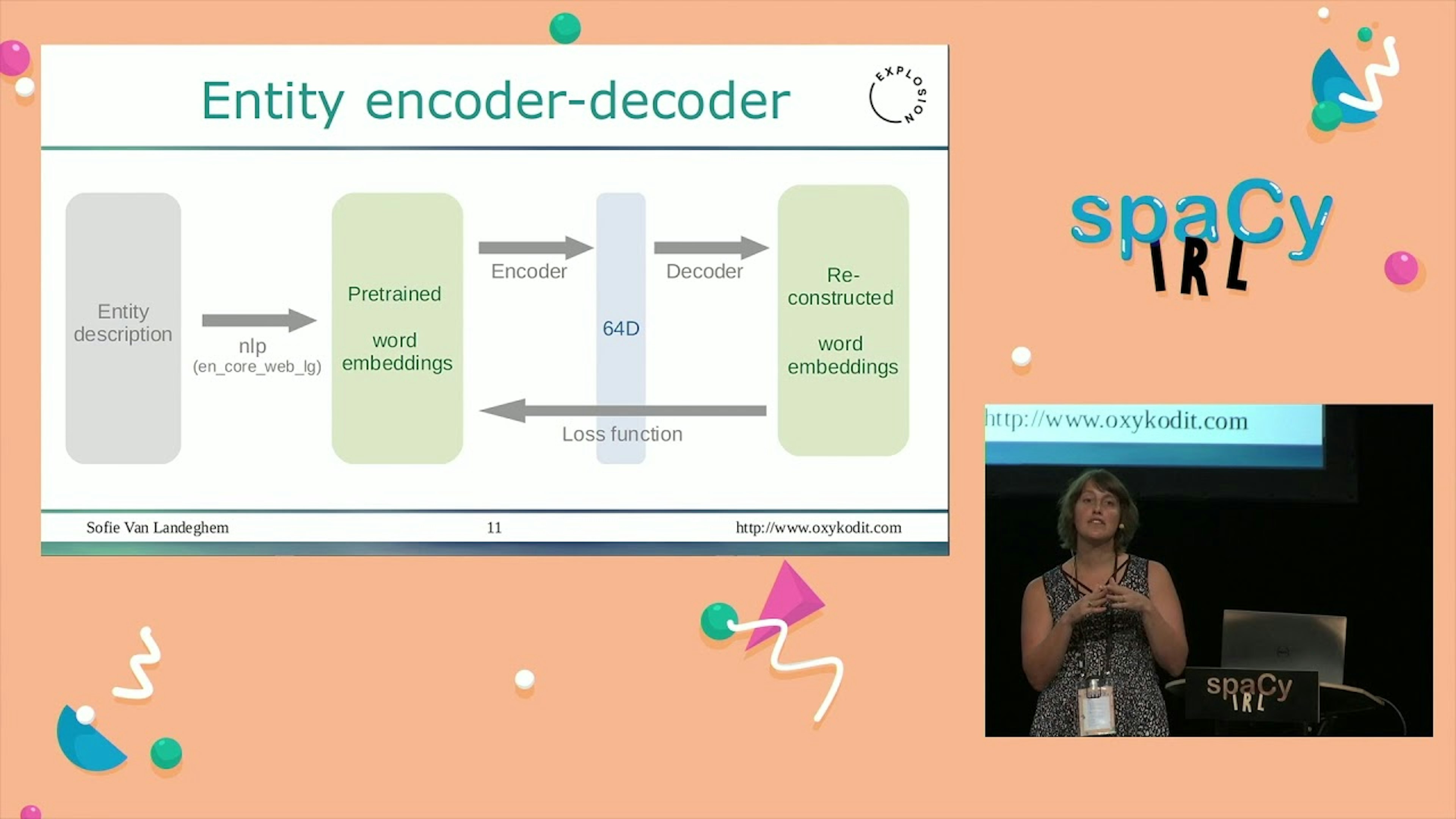
spaCy’s entity recognition model: incremental parsing with Bloom embeddings & residual CNNsspaCy v2.0’s Named Entity Recognition system features a sophisticated word embedding strategy using subword features and "Bloom" embeddings, a deep convolutional neural network with residual connections, and a novel transition-based approach to named entity parsing.
Pseudo-rehearsal: A simple solution to catastrophic forgetting for NLPSometimes you want to fine-tune a pre-trained model to add a new label or correct some specific errors. This can introduce the "catastrophic forgetting" problem. Pseudo-rehearsal is a good solution: use the original model to label examples, and mix them through your fine-tuning updates.
Supervised learning is great — it's data collection that's brokenShort of Artificial General Intelligence, we'll always need some way of specifying what we're trying to compute. Labelled examples are a great way to do that, but the process is often tedious. However, the dissatisfaction with supervised learning is misplaced. Instead of waiting for the unsupervised messiah to arrive, we need to fix the way we're collecting and reusing human knowledge.
Künstliche Intelligenz Beyond the HypeZündfunk Netzkongress (German)“Artificial intelligence” is everywhere in the headlines. Many futuristic-sounding things suddenly seem possible. It’s not easy to judge what all these technological advances mean. What is hype and what really works? And how should we imagine the future?
Using spaCy with Hugging Face TransformersPyCon IndiaTransformer models like BERT have set a new standard for accuracy on almost every NLP leaderboard. However, these models are very new, and most of the software ecosystem surrounding them is oriented towards the many opportunities for further research. In this talk, Matt describes how you can now use these models in spaCy to work on real problems and the many opportunities transfer learningfor production NLP, regardless of which software packages you choose.
Introducing spaCy v2.2Version 2.2 of the spaCy Natural Language Processing library is leaner, cleaner and even more user-friendly. In addition to new model packages and features for training, evaluation and serialization, we've made lots of bug fixes, improved debugging and error handling, and greatly reduced the size of the library on disk.
Intro to NLP with spaCy (1): Detecting programming languagesIn this new video series, data science instructor Vincent Warmerdam gets started with spaCy, an open-source library for Natural Language Processing in Python. His mission: building a system to automatically detect programming languages in large volumes of text.
spaCy IRL 2019: 2 days of NLP in BerlinWe were pleased to invite the spaCy community and other folks working on Natural Language Processing to Berlin this summer for a small and intimate event.
Advanced NLP with spaCy: A free online courseIn this free and interactive online course, you’ll learn how to use spaCy to build advanced natural language understanding systems, using both rule-based and machine learning approaches.
The process: Transforming spaCy’s docsIncrement MagazineMaking your documentation work for users with vastly different needs is a challenge. Here’s how spaCy, an open-source library for natural language processing, did it.
Embed, encode, attend, predictData Science SummitWhile there is a wide literature on developing neural networks for natural language understanding, the networks all have the same general architecture. This talk explains the four components (embed, encode, attend, predict), gives a brief history of approaches to each subproblem, and explains two sophisticated networks in terms of this framework.
Explosion in 2017: Our Year in ReviewWe founded Explosion in October 2016, so this was our first full calendar year in operation. We set ourselves ambitious goals this year, and we're very happy with how we achieved them. Here's what we got done.
Introducing custom pipelines and extensions for spaCy v2.0As the release candidate for spaCy v2.0 gets closer, we've been excited to implement some of the last outstanding features. One of the best improvements is a new system for adding pipeline components and registering extensions to the Doc, Span and Token objects. In this post, we'll introduce you to the new functionality, and finish with an example extension package, spacymoji.
Building Prodigy: Our new tool for efficient machine teachingines.ioThe philosophy behind Prodigy’s features and its cloud-free design.
Supervised similarity: Learning symmetric relations from duplicate question dataSupervised models for text-pair classification let you create software that assigns a label to two texts, based on some relationship between them. When the relationship is symmetric, it can be useful to incorporate this constraint into the model. This post shows how a siamese convolutional neural network performs on two duplicate question data sets with experimental results.