Creating Custom Event Data Without Dictionaries: A Bag-of-TricksHalterman, Schrodt, Beger, Bagozzi, Scarborough (2023)While in the past the process of generating training case has been quite time consuming and tedious, newer approaches such as those incorporated into the web-based Prodigy annotation system allow this to be done much more quickly.
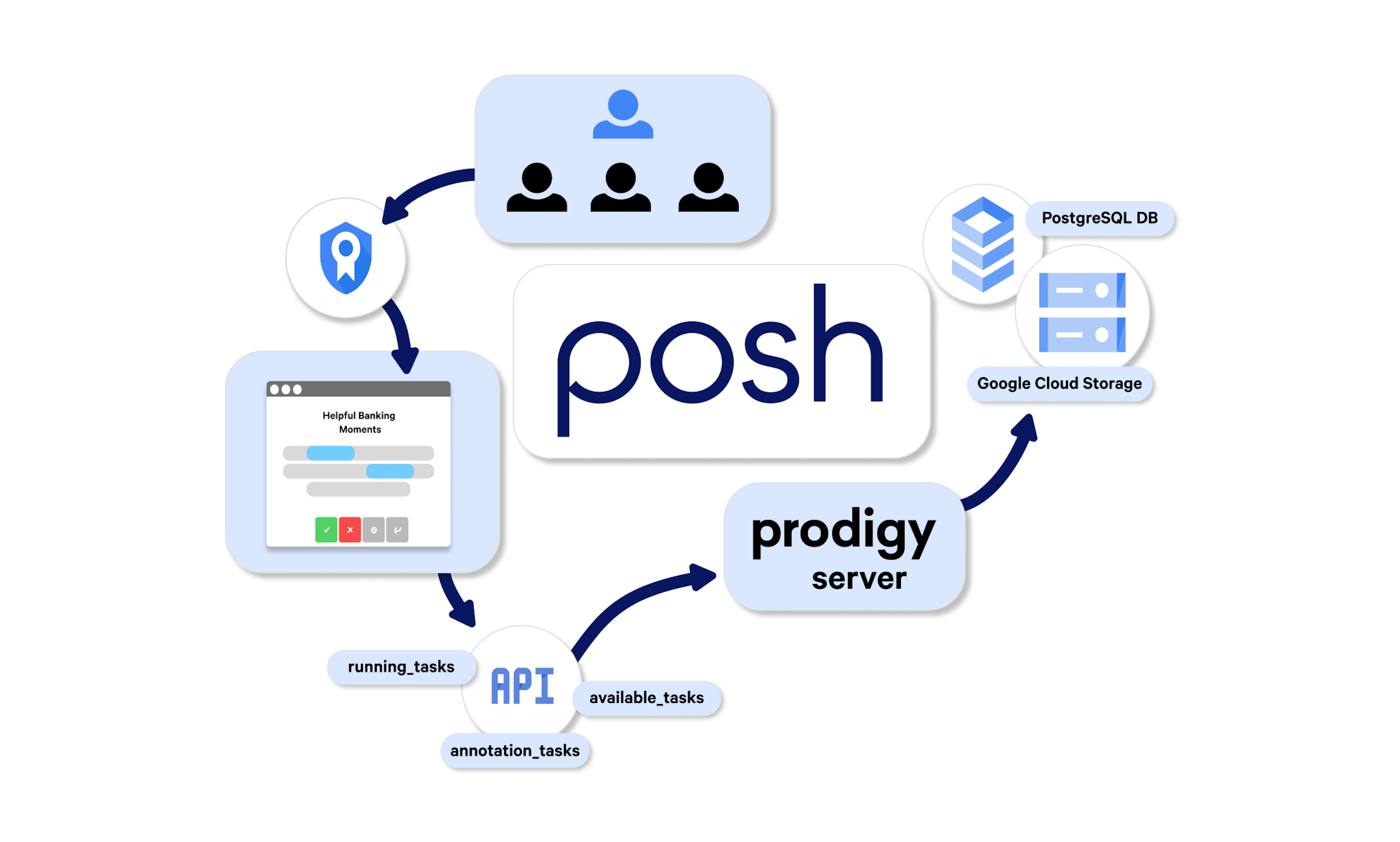
Deploying a Prodigy cloud service for Posh’s financial chatbotsA Prodigy case study of Posh AI's production-ready annotation platform and custom chatbot annotation tasks for banking customers.
Reflections on a year of spaCy consulting at ExplosionIn this post, Peter shares some lessons learned from chatting with practitioners about their NLP challenges, developing production-ready NLP pipelines for clients, and working with an open-source development team.
Multi hash embeddings in spaCyMiranda, Kádár, Boyd, Van Landeghem, Søgaard, Honnibal (2022)In this technical report we lay out a bit of history and introduce the embedding methods in spaCy in detail. Second, we critically evaluate the hash embedding architecture with multi-embeddings on Named Entity Recognition datasets from a variety of domains and languages. The experiments validate most key design choices behind spaCy’s embedders, but we also uncover a few surprising results.
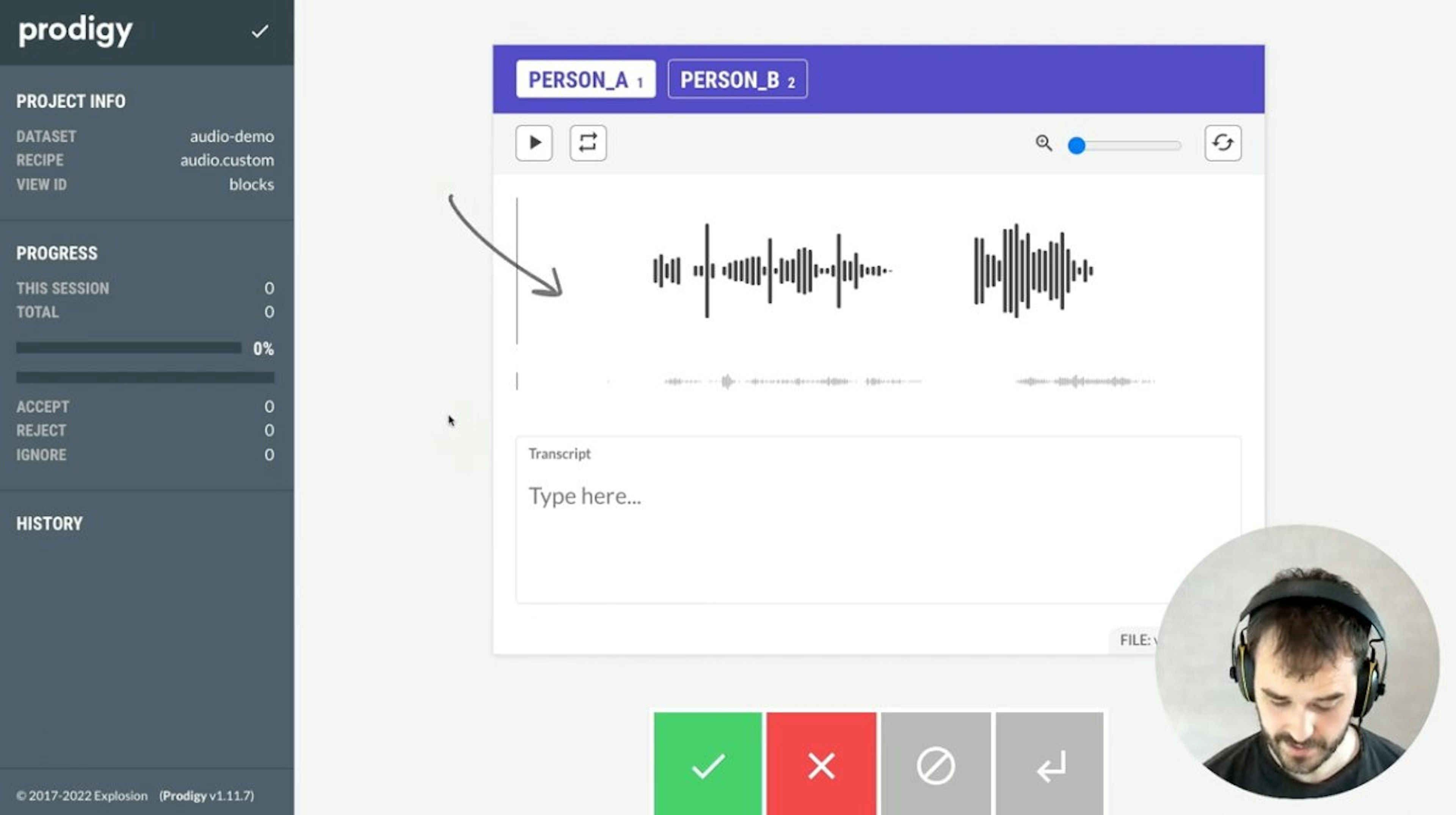
Custom Interfaces with blocksYou can create custom annotation layouts in Prodigy using the annotation widgets that Prodigy provides by using the blocks feature. This video explains how to use this feature by building a custom interface that can manually annotate and transcribe audio.
spaCy behind the scenes: library patterns & design concepts explainedDeveloper productivity has been central to our design of spaCy, both in smaller decisions and some of the bigger architectural questions. We believe in embracing the complexities of machine learning, not hiding it away under leaky abstractions, while also maintaining the developer experience. Read on to learn some of the design patterns within the library, how we've implemented them, and most importantly, why.
Introducing spaCy v3.4spaCy v3.4 brings typing and speed improvements along with new vectors for English CNN pipelines and new trained pipelines for Croatian.
Introducing spaCy v3.3spaCy v3.3 improves the speed of core pipeline components, adds a new trainable lemmatizer, and introduces trained pipelines for Finnish, Korean and Swedish.
Automated Identification of Clinical Procedures in Free-Text Electronic Clinical Records with a Low-Code Named Entity Recognition WorkflowMacri, Teoh, Bacchi, Sun, Selva, Casson, Chan (2022), Methods of Information in MedicineThe use of a low-code annotation software tool [Prodigy] allows the rapid creation of a custom annotation dataset to train a NER model to identify clinical procedures stored in free-text electronic clinical notes.
Introducing spaCy Tailored PipelinesExplosion is pleased to announce a new development services offering, spaCy Tailored Pipelines. We’ll build you a custom natural language processing pipeline, delivered in a standardized format using spaCy’s projects system.
textaCy v0.13.0Utility library for NLP tasks before and after spaCy, including preprocessing, normalization and additional information extraction features.
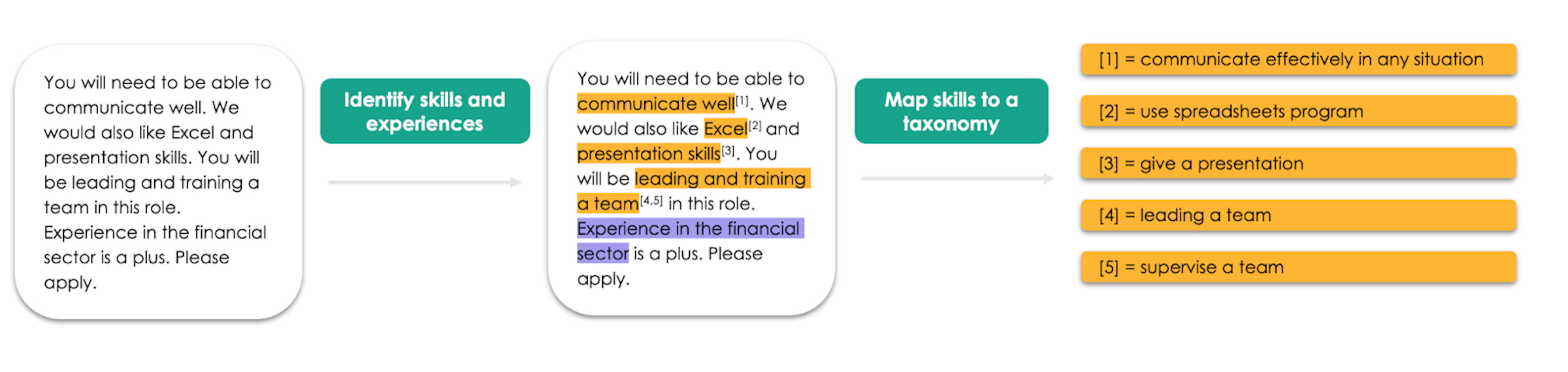
The Nesta Skills Extractor LibraryEconomic Statistics Centre of ExcellenceA new library for extracting skills from job adverts and mapping them to a taxonomy of your choice, built on top of spaCy.
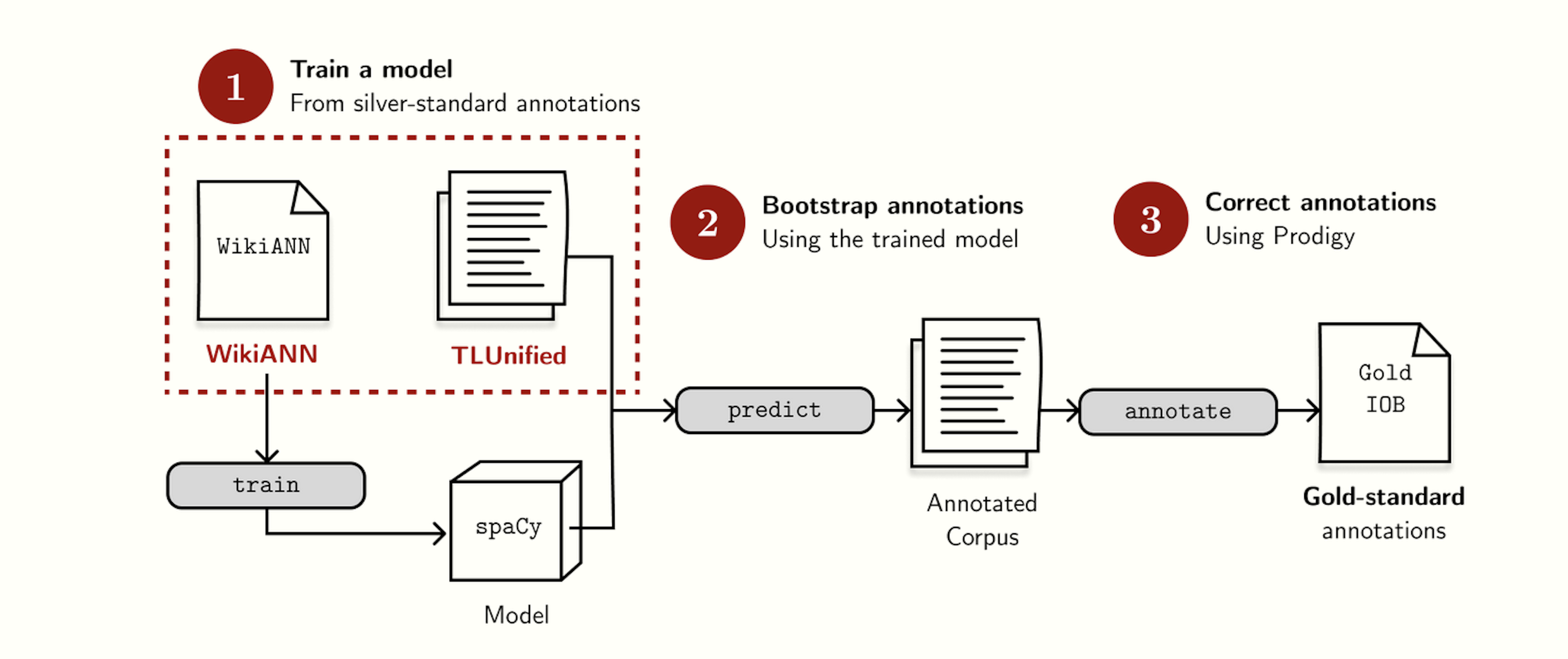
Towards a Tagalog NLP pipelineIn this blog post, Lj talks about how he built an NER pipeline for Tagalog, the gold-standard dataset, benchmarking results, and his hopes for the future of Tagalog NLP.
Explosion in 2022: Our Year in ReviewIt's been another exciting year at Explosion! We've developed a new end-to-end neural coref component for spaCy, improved the speed of our CNN pipelines up to 60%, and published new pre-trained pipelines for Finnish, Korean, Swedish and Croatian. We've also released several updates to Prodigy and introduced new recipes to kickstart annotation with zero- or few-shot learning.
Extracting Structured Information from Greek Legislation DataAlexios (2023)Worth noting is the existence of an application, called Prodigy, which takes advantage of an active learning framework and provides users with an interactive interface for data annotation.
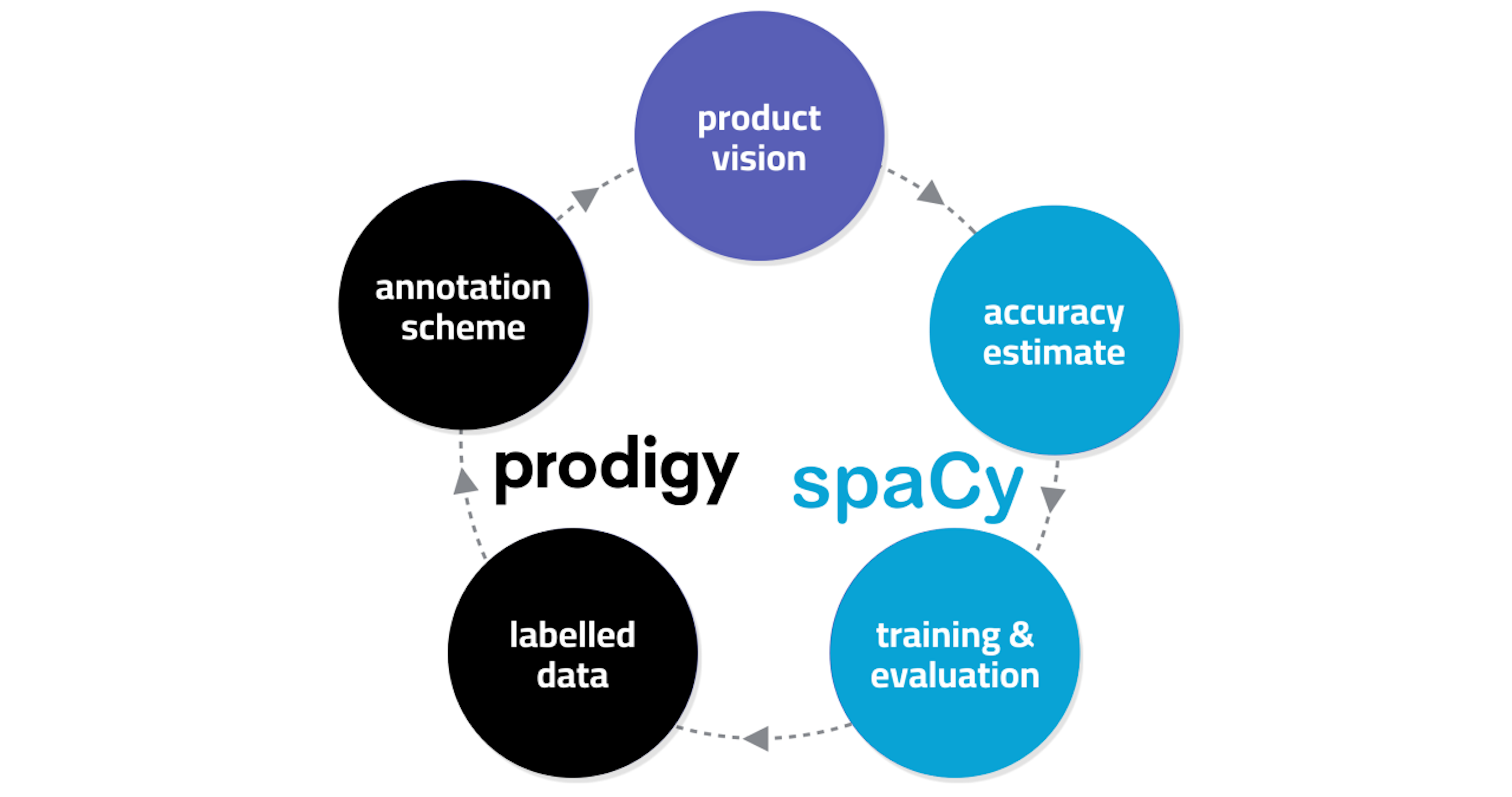
The triangulation of ethical leader signals using qualitative, experimental, and data science methodsBanks, Ross, Toth, Tonidandel, Goloujeh, Dou, Wesslen (2022)This additional text was labeled by the same coding team using Prodigy, [...] a flexible user interface tool built on top of spaCy, a leading open source library in python for natural language processing. We created a spaCy end‐to‐end project workflow including package versioning, data pre‐processing, data ingestion into a database, annotation sessions using Prodigy’s user interface, model training, model evaluation, python packaging, and visual app for testing the model.
Coreference Resolution in spaCyIn everyday conversation, we use pronouns or other expressions to refer to entities in many different ways, but we effortlessly understand these references. In NLP this is a challenging problem known as Coreference Resolution. In this video, we’ll show how to train spaCy’s new component for Coreference Resolution and how to apply the pipeline to resolve references in a text.
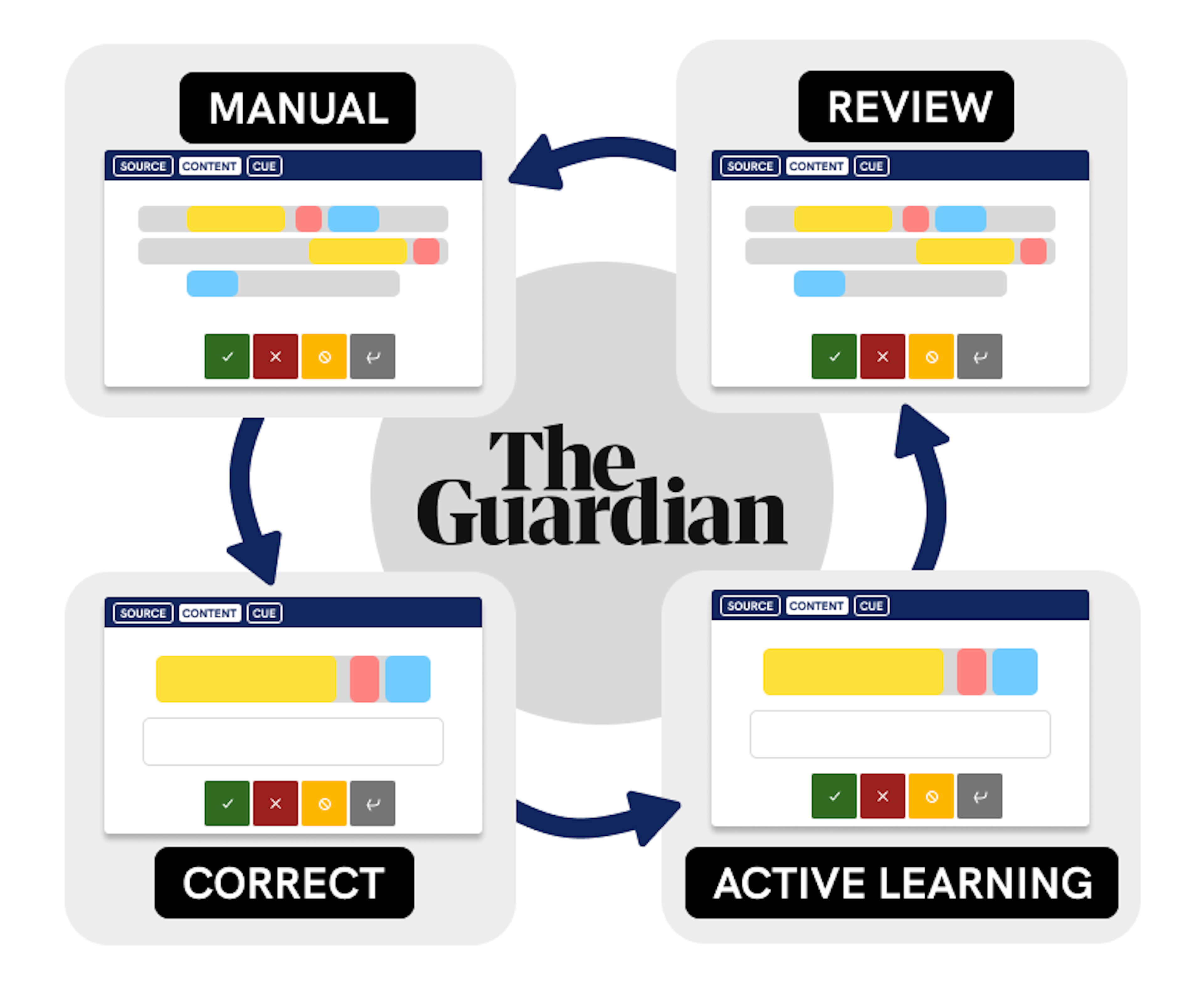
How the Guardian approaches quote extraction with NLPA case study of the Guardian's spaCy-Prodigy workflow to modularize quote extraction for content creation. This study includes iterative annotation guidelines and custom interface functionality.
floret: lightweight, robust word vectorsAn exploration of floret vectors: lightweight vectors for noisy data, novel words, rich morphology and more.
Bulk Labelling and ProdigyIn this video, we’ll show a bulk labelling technique that can help you prepare data for Prodigy.
Finding Bad Labels for Text Classification with Jupyter and Prodigy In this video, we’ll show you how to use set up Prodigy to find bad labels in text classification tasks. While many of the techniques are applied to text classification, they can also be used for classification tasks in general.
How we built a Stack Overflow Community questions analyzerGitLab BlogHow GitLab used spaCy to analyze and better understand Stack Overflow community questions about their tools and products.
Finding Duplicates in Tabular Data with Jupyter and ProdigyIn this video, we’ll show you how to use Prodigy to train a named entity recognition model from scratch, by taking advantage of semi-automatic annotation and modern transfer learning techniques.
Rulers, NER, and data iterationAbout the power of Rules + ML and the importance of iteration on your pipeline and your data.
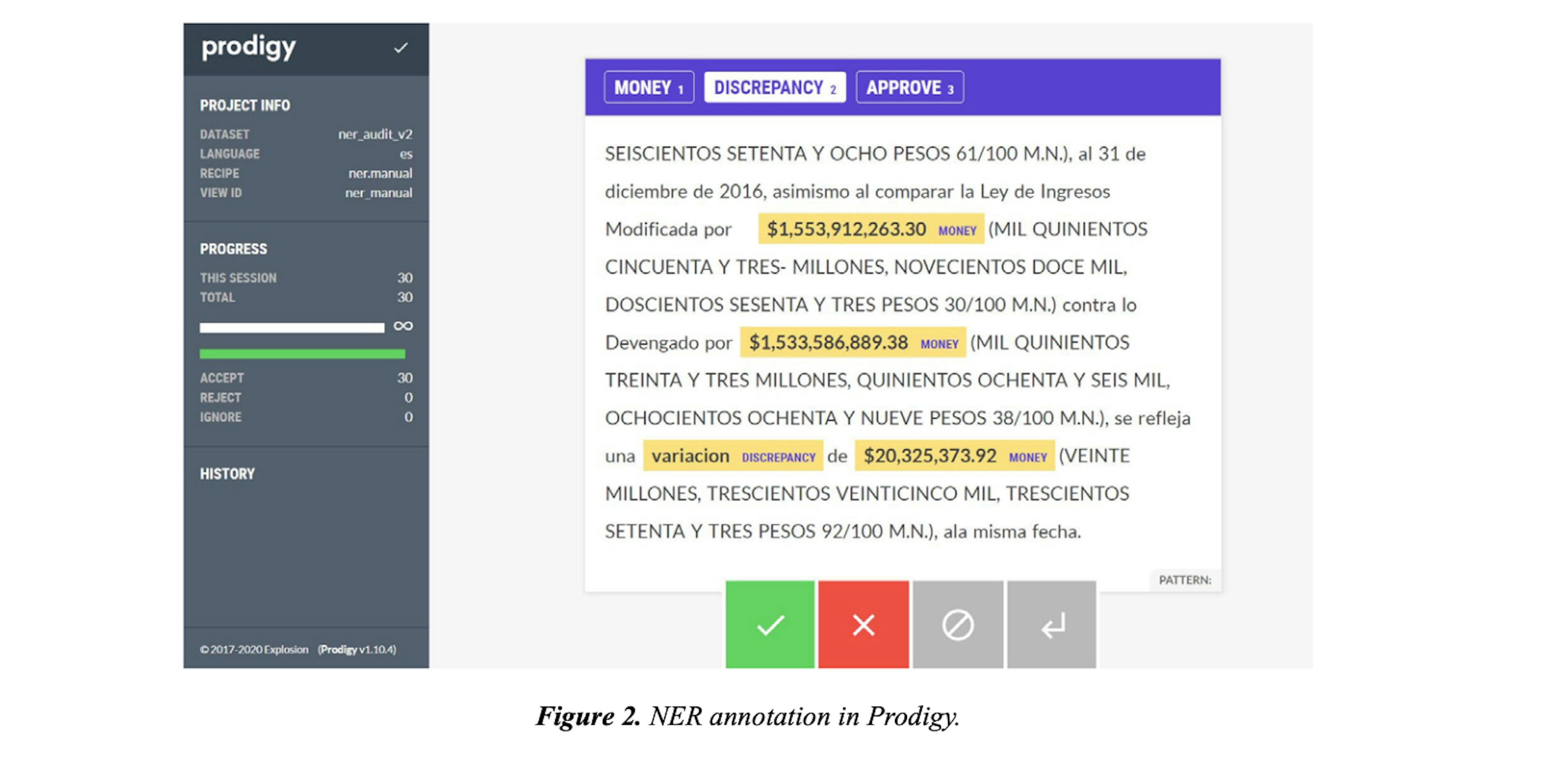
Fiscal data in text: Information extraction from audit reports using Natural Language ProcessingBeltran (2023), Data & Policy, Cambridge University PressI relied on the text annotation software Prodigy in Python that offers a friendly user interface where the reviewer can read the text and assign a label to each paragraph.
Is it possible to have entities within entities within entities?PyData Global 2022Named entity recognition models might not be able to handle a wide variety of spans, but Spancat certainly can! Dive into named entity recognition, its limitations, and how we’ve solved them with a solution-focused talk and practical applications.
Finetuning and Bulk Labelling Images with Prodigy In this video, we’ll show how you might be able to improve the annotation experience by using bulk labelling for image classification.
Finding Video Games with Sense2VecIn this video, we’ll show how you can improve the annotation experience by leveraging sense2vec to pre-fill named entities.
Speech acts in the Dutch COVID-19 Press ConferencesSchueler, Marx (2022), Language Resources and EvaluationWe used the annotation tool Prodigy. Prodigy provides a simple interface in which the annotator sees a sentence and selects the applicable speech acts. The use of Prodigy considerably sped up the annotation process, allowing the annotators to annotate around 200 sentences per hour.
Introducing Span Categorization in Prodigy and spaCyIn this video, we’ll show you how to use Prodigy for spaCy’s Span Categorizer. We’ll be annotating food recipes and looking into ways to help with consistent annotations and speed up the process with patterns and temporary models.
Diary of a spaCy project: Predicting GitHub TagsMany people assume that working on an NLP project involves a lot of machine learning. Our experience is that it's much less about flowing tensors, and more about making a tailored solution. This blogposts demonstrates how a typical spaCy project could be initiated, implemented and executed towards a custom solution.
Finding Bad Image Data using UMAP and ProdigyIn this video, we’ll show you how to use Prodigy to find bad examples in the Google QuickDraw dataset. We will be leveraging a technique that involves UMAP to find strange images semi-automatically.
Slovak Dataset for Multilingual Question AnsweringHládek, Staš, Juhár, Koctúr (2023)We used the Prodigy annotation tool to annotate the questions and answers. One annotation task corresponds to one web application deployment and different configurations.
Introducing spaCy v3.5spaCy v3.5 introduces new CLI commands, fuzzy matching, improvements for entity linking and more.
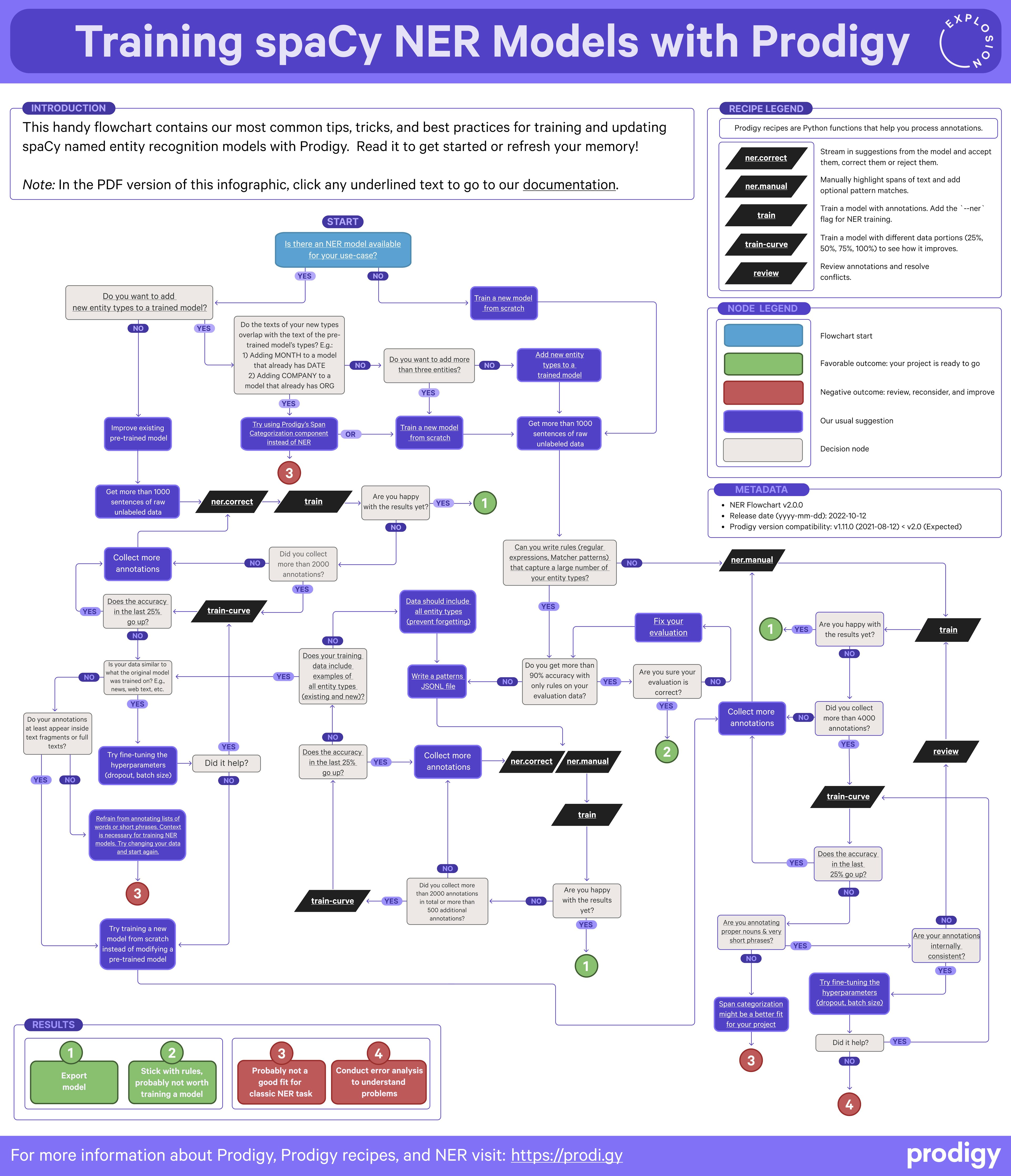
Training spaCy NER Models with ProdigyThis handy flowchart contains our most common tips, tricks, and best practices for training and updating spaCy named entity recognition models with Prodigy.
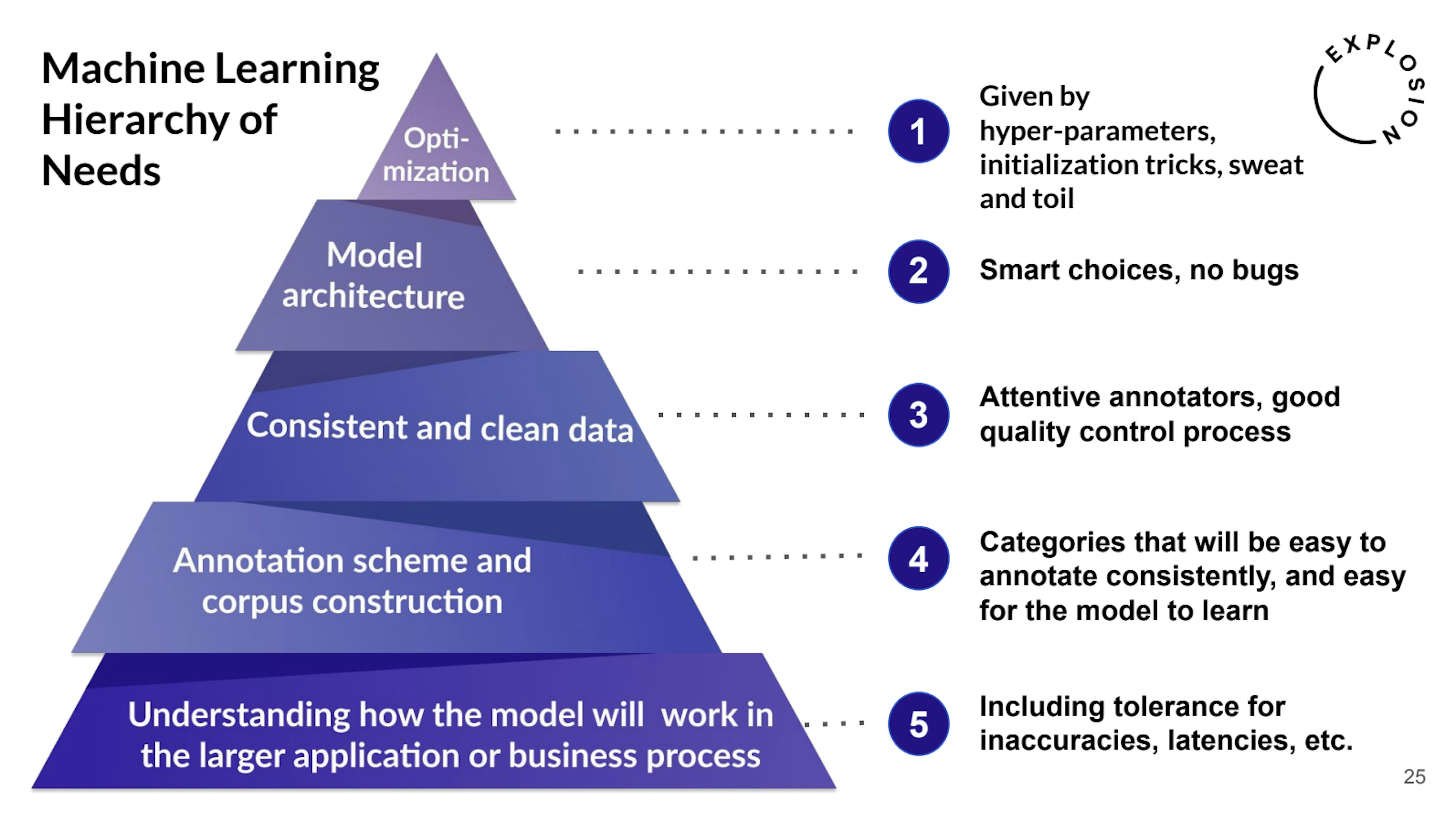
Setting your ML project up for success“What can you do to maximize probability of success for your Machine Learning solution? Throughout my 15 years as data scientist in academia, big pharma and through consulting, one common theme has emerged: the most reliable predictor of success for any NLP or ML-based solution is whether or not you involve the data science team early on.”
Fast transformer inference with Metal Performance ShadersWe are happy to introduce support for Metal Performance Shaders in Thinc PyTorch layers. This makes it possible to run spaCy transformer-based pipelines on GPU on Apple Silicon Macs and improves inference speed up to 4.7 times.
End-to-end Neural Coreference Resolution in spaCyCoreference resolution is the problem of resolving entities in texts to references such as pronouns. Even if you've never heard of it, it's something we all do constantly every day, and is a key to understanding natural language. We recently added an experimental implementation of an end-to-end neural coreference component to spaCy. This post explains the architecture of our model in detail.
Introducing Holmes 4.0A few weeks ago we released version 4.0 of Holmes, which we are now able to offer under a permissive MIT license. Holmes is a library in the spaCy Universe that runs on top of spaCy and enables information extraction and intelligent search, currently for English and German. Holmes goes beyond simple matching algorithms and allows you to look for a specified idea or ideas in a corpus of documents.
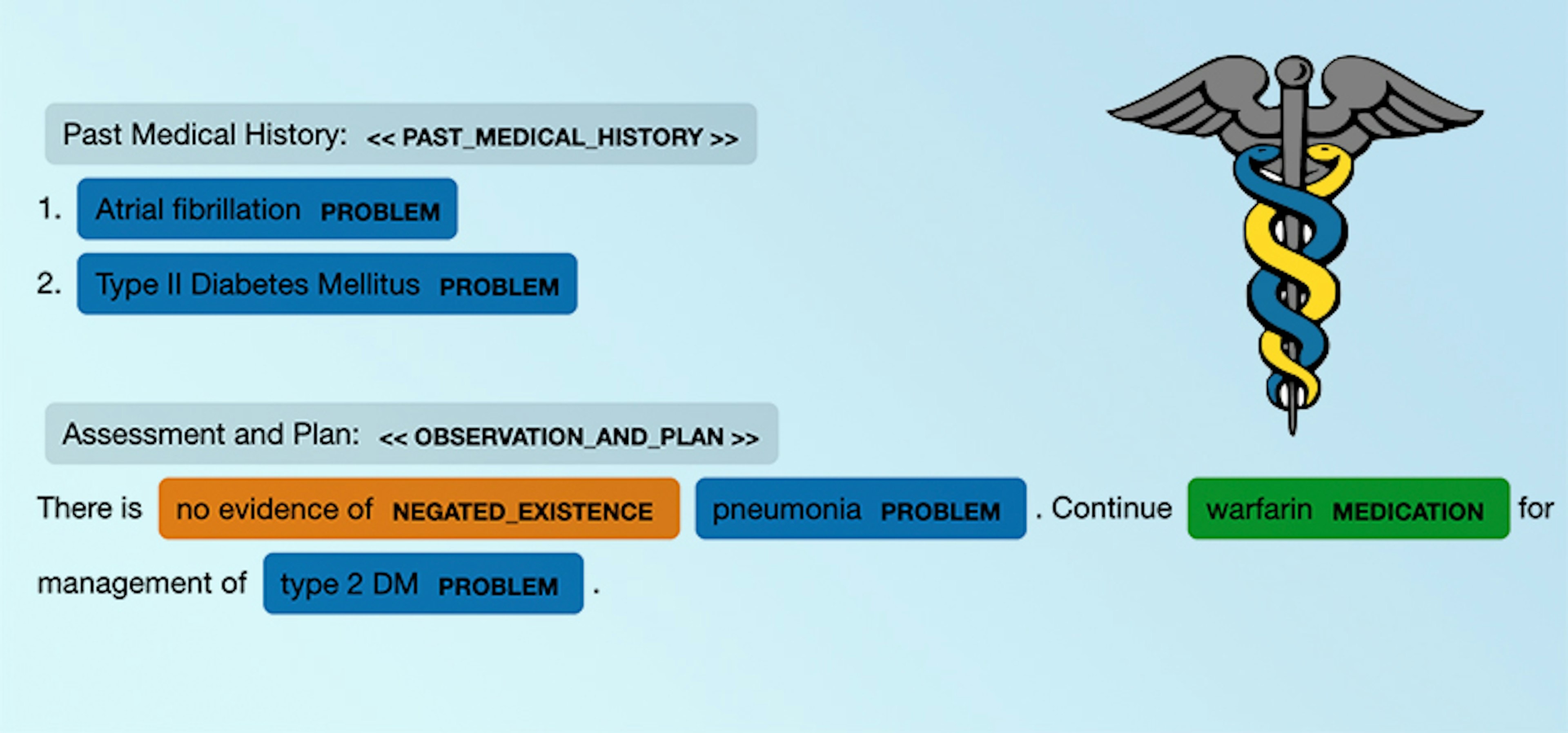
Spancat: a new approach for span labelingThe SpanCategorizer is a spaCy component that answers the NLP community's need to have structured annotation for a wide variety of labeled spans, including long phrases, non-named entities, or overlapping annotations. In this blog post, we're excited to talk more about spancat and showcase new features to help with your span labeling needs!
Solutions for Advanced NLP for Diverse LanguagesNew Languages for NLP KeynoteThis talk discusses spaCy’s philosophy for modern NLP, its extensible design and new recent features to enable the development of advanced natural language processing pipelines for typologically diverse languages.
Compact word vectors with Bloom embeddingsAn introduction to the compact word vectors with Bloom embeddings used in Thinc, spaCy and floret.
Applied Language TechnologyExtensive online course on applied language technology with spaCy by Tuomo Hiippala, designed for students new to NLP and programming.