Szczecin stolicą programowaniaTVP3 SzczecinNews segment about EuroSciPy 2024 on local Polish television, featuring Ines’ talk and interviews with the organizers.
spaCy Chunks v0.0.2spaCy extension and pipeline component for generating overlapping chunks of sentences or tokens from a document.
Back to our roots: Company update and future plansWe’re back to running Explosion as a smaller, independent-minded and self-sufficient company. spaCy and Prodigy will stay stable and sustainable, maintained by their original authors. We’ll keep updating our stack wth the latest technologies, without changing its core identity or purpose.
Once a Maintainer: Sofie Van LandeghemInterview with Sofie about her work as a core maintainer of spaCy, the evolution of NLP, and why dependency management in Python is so terrible.
How to uncover and avoid structural biases in evaluating your Machine Learning/NLP projectsPyData LondonThis talk highlights common pitfalls that occur when evaluating ML and NLP approaches. It provides comprehensive advice on how to set up a solid evaluation procedure in general, and dives into a few specific use-cases to demonstrate artificial bias that unknowingly can creep in.
spaCy meets LLMs: Using Generative AI for Structured DataData+ML Community MeetupThis talk dives deeper into spaCy’s LLM integration, which provides a robust framework for extracting structured information from text, distilling large models into smaller components, and closing the gap between prototype and production.
Getting Started with NLP and spaCyTalkPython CourseThere is a lot of text data out there and maybe you're interested in getting structured data out of it. There are a lot of options out there and this course will introduce you to the field by focussing on spaCy while also exploring other tools.
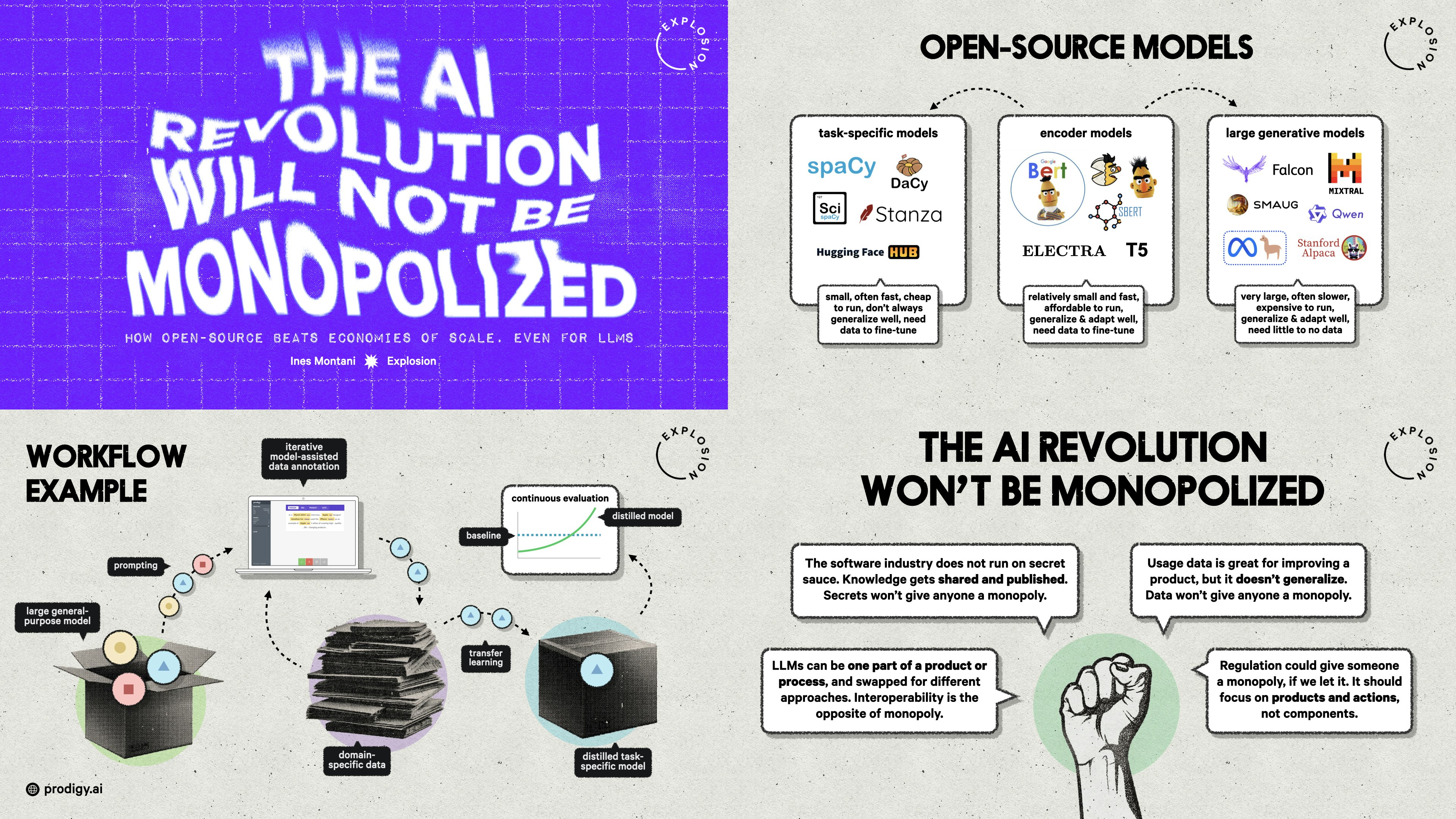
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsPyCon DE & PyData BerlinWith the latest advancements in NLP and LLMs, and big companies like OpenAI dominating the space, many people wonder: Are we heading further into a black box era with larger and larger models, obscured behind APIs controlled by big tech monopolies?
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsPyCon Lithuania KeynoteWith the latest advancements in NLP and LLMs, and big companies like OpenAI dominating the space, many people wonder: Are we heading further into a black box era with larger and larger models, obscured behind APIs controlled by big tech monopolies?
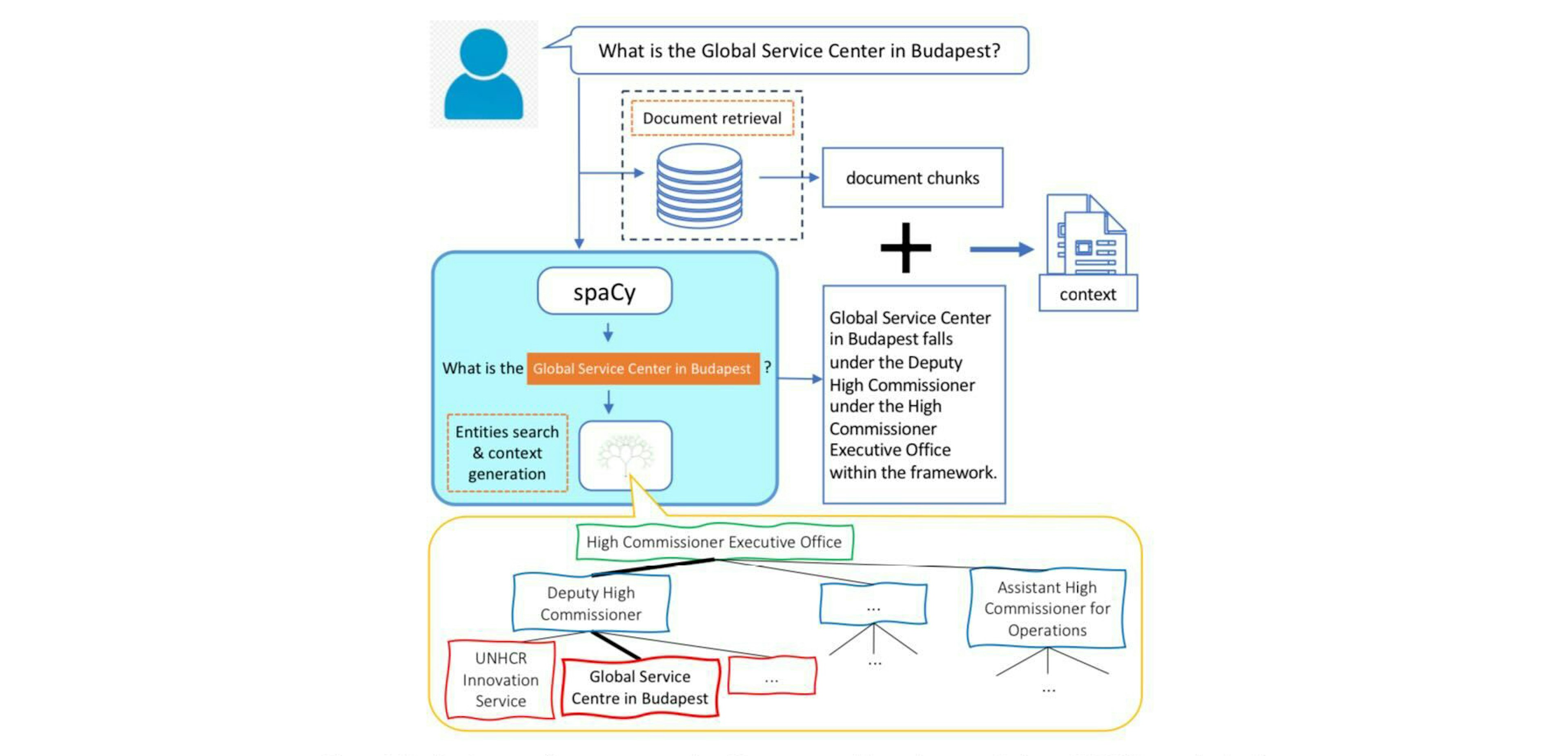
T-RAG: Lessons from the LLM TrenchesFatehkia, Lucas, Chawla (2024)An important application area is question answering over private enterprise documents where the main considerations are data security, which necessitates applications that can be deployed on-prem, [and] limited computational resources. [...] In addition to retrieving contextual documents, we use the spaCy library with custom rules to detect named entities from the organization.
spacy-llm: From quick prototyping with LLMs to more reliable and efficient NLP solutionsAstraZeneca NLP Community of PracticeLLMs are paving the way for fast prototyping of NLP applications. Here, Sofie showcases how to build a structured NLP pipeline to mine clinical trials, using spaCy and spacy-llm. Moving beyond a fast prototype, she offers pragmatic solutions to make the pipeline more reliable and cost efficient.
Herding LLMs Towards Structured NLPGlobal AI ConferenceThis talk shows how we integrate LLMs into spaCy, leveraging its modular and customizable framework. This allows for cheaper, faster and more robust NLP - driven by cutting-edge LLMs, without compromising on having structured, validated data.
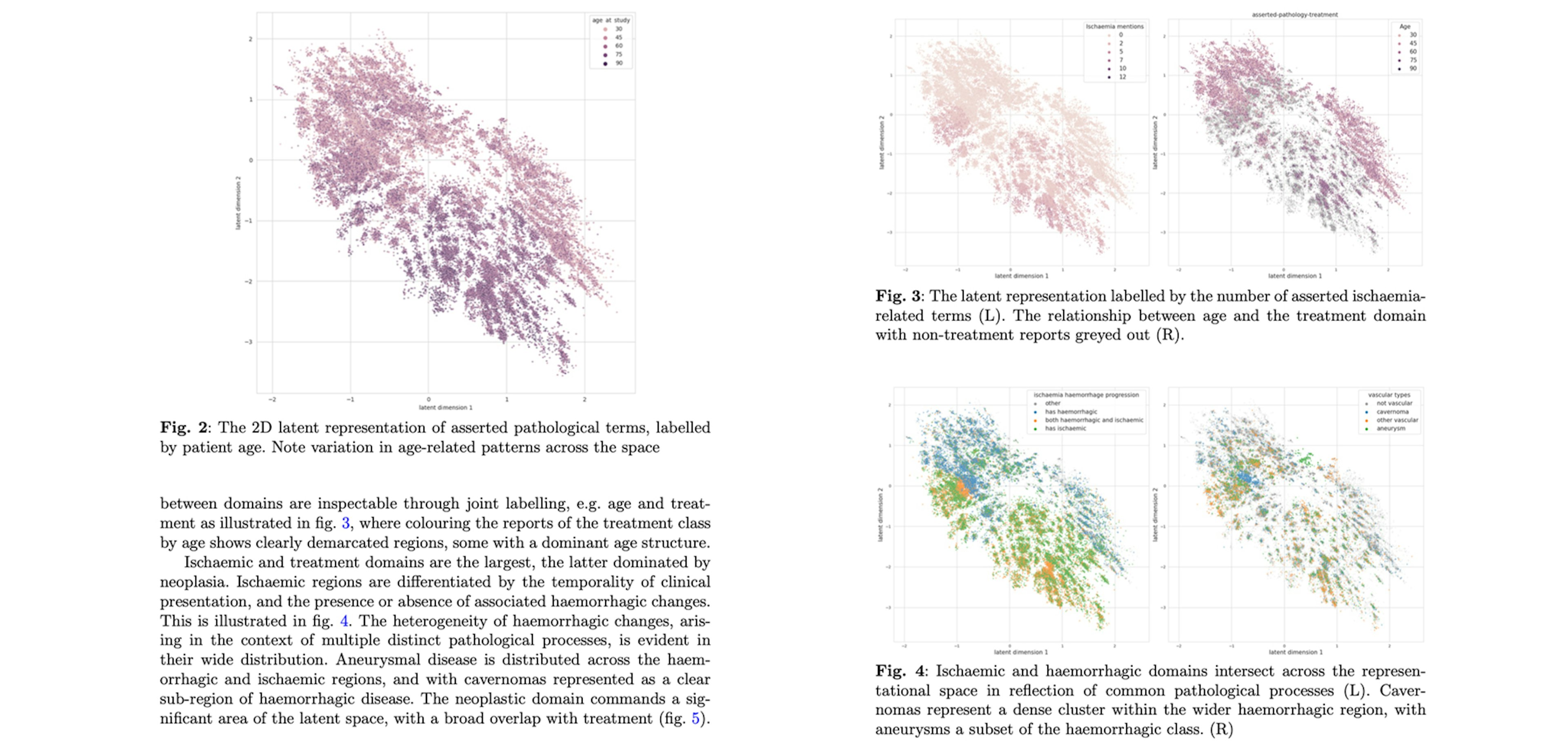
Neuradicon: operational representation learning of neuroimaging reportsWatkins, Gray, Julius, Mah, Pinaya, Wright, Jha, Engleitner, Cardoso, Ourselin, Rees, Jaeger, Nachev (2023)Labelled data for each task was produced using the Prodigy labelling tool. Each report was labelled in a paired-annotation manner. [...] We used the grammatical dependency parse produced by the spaCy parser as input and implemented the patterns using the spaCy dependency matcher.
calamanCy: A Tagalog Natural Language Processing ToolkitMiranda (2023), EMNLP 2023We introduce calamanCy, an open-source toolkit for constructing NLP pipelines for Tagalog. It is built on top of spaCy, enabling easy experimentation and integration with other frameworks.
10 Years of Open Source: Navigating the Next AI RevolutionEuroSciPy KeynoteIn this talk, Ines shares the most important lessons we’ve learned in 10 years of working on open-source software, our core philosophies that helped us adapt to an ever-changing AI landscape and why open source and interoperability still wins over black-box, proprietary APIs.
Practical Tips for Bootstrapping Information Extraction PipelinesDataHack SummitThis talk presents approaches for bootstrapping NLP pipelines and retrieval via information extraction, including tips for training, modelling and data annotation.
A practical guide to human-in-the-loop distillationThis blog post presents practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillationPyData LondonLLMs have enormous potential, but also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, Ines shows some practical solutions for using the latest models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
The AI Revolution Won’t Be MonopolizedTalkPython PodcastThere hasn’t been a boom like the AI boom since the .com days. And it may look like a space destined to be controlled by a couple of tech giants. But Ines Montani thinks open source will play an important role in the future of AI.
The application of natural language processing for the extraction of mechanistic information in toxicologyConradi, Luechtefeld, de Haan, Pieters, Freedman, Vanhaecke, Vinken, Teunis (2024)All steps were conducted using the open-source Python package spaCy. Specifically, the NER model was trained using scispaCy en-core-sci-lg (Neumann et al., 2019) as a starting point, which allowed for a vocabulary (word vectors) and grammar trained on scientific literature.
The AI Revolution Will Not Be Monopolized: Behind the scenesOpen Source ML MixerA more in-depth look at the concepts and ideas, academic literature, related experiments and preliminary results for distilled task-specific models.
Designing for tomorrow’s programming workflowsPyCon LithuaniaModern editors and AI-powered tools like GitHub Copilot and ChatGPT are changing how people program and are transforming our workflows and developer productivity. But what does this mean for how we should be writing and designing our APIs and libraries?
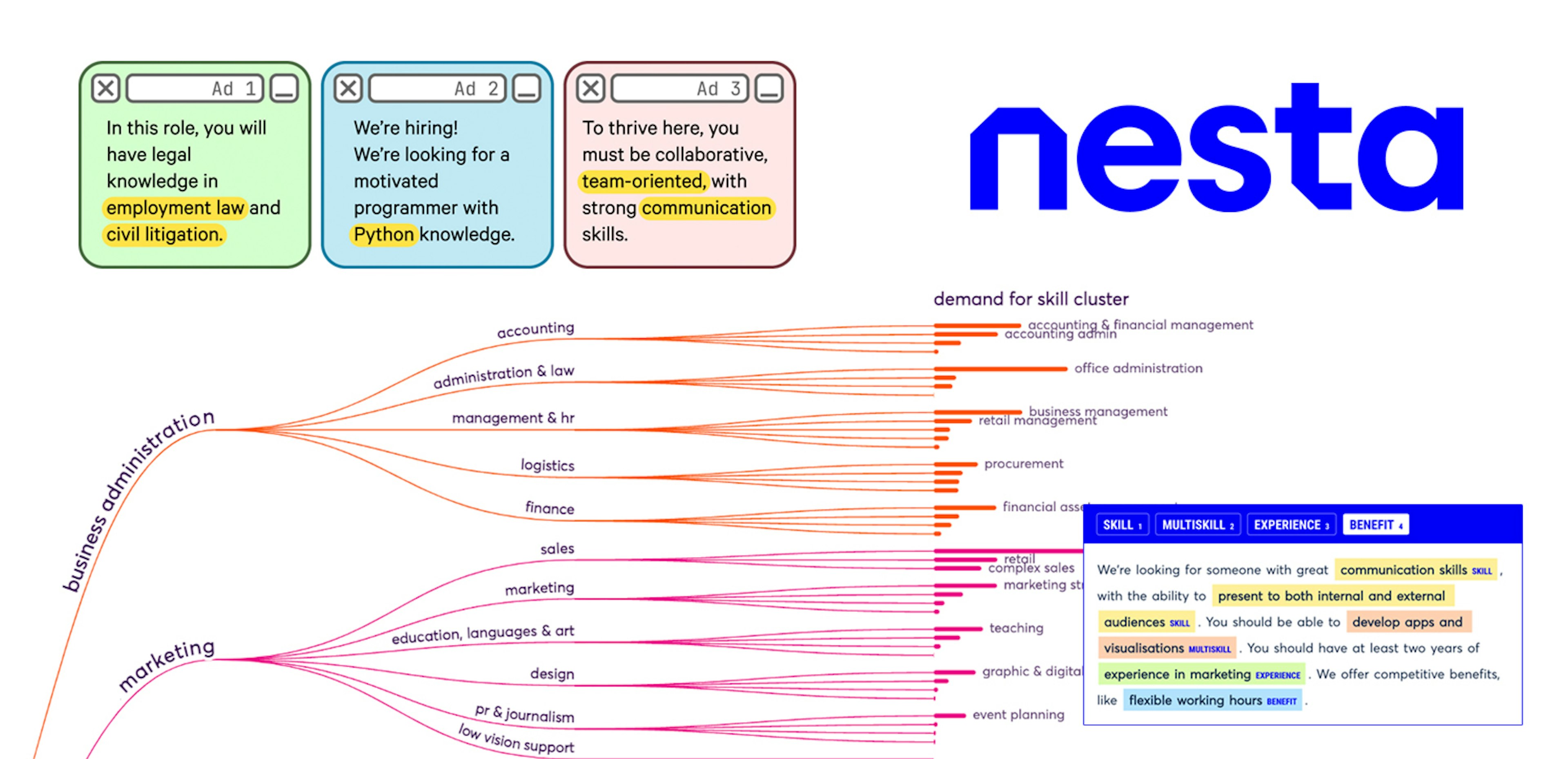
How Nesta uses NLP to process 7m job ads and shed light on the UK’s labor marketA case study on Nesta’s workflow for extracting 7 million job ads to better understand UK skill demand, using a custom mapping step to match skills to any government taxonomy.
Microsoft Presidio v2.2.352Context aware, pluggable and customizable PII de-identification and anonymization service for text and images, featuring a spaCy back-end.
DeepZensols: A Deep Learning Natural Language Processing Framework for Experimentation and ReproducibilityLandes, Di Eugenio, Caragea (2023)A linguistic feature mapper that translates spaCy to wordpieces, which are token sub-units with associated vectors, is also accessible as an easy to configure module.
Who said what: using machine learning to correctly attribute quotesThe Guardian Engineering BlogHow the Guardian uses spaCy and Prodigy to train a custom coreference resolution model.
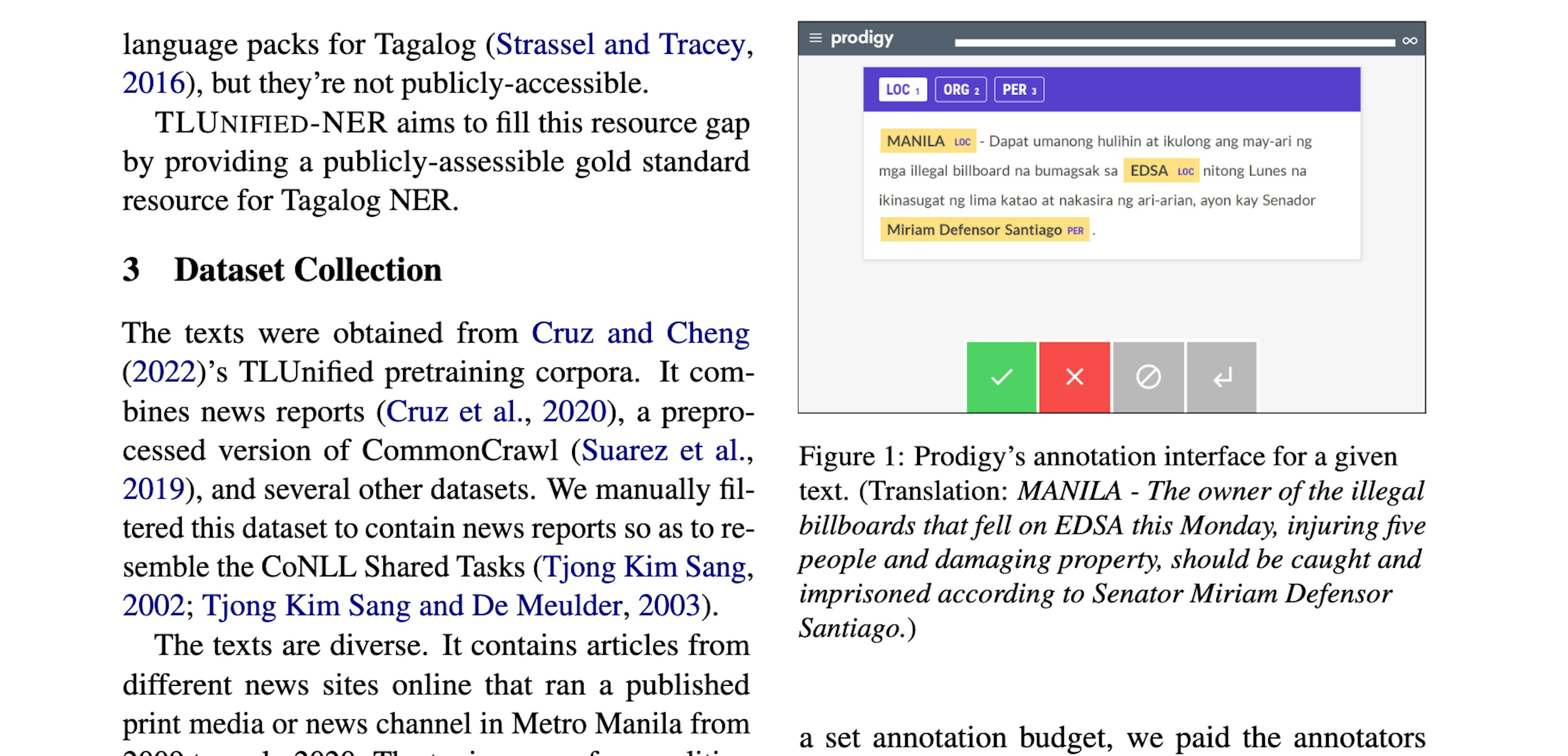
Developing a Named Entity Recognition Dataset for TagalogMiranda (2023), IJCNLP-AACL 2023We used Prodigy as our annotation tool. We set up a web server on the Google Cloud Platform and routed the examples through Prodigy’s built-in task router.
Assessing Fine-Tuned NER Models with Limited Data in French: Automating Detection of New Technologies, Technological Domains, and Startup Names in Renewable EnergyMacLean, Cavallucci (2024)In order to assure the uniformity of the process of fine-tuning each model, we decided to use the spaCy library. This library, one of the most widely used for NLP tasks, allows us to directly modify a simple configuration file in order to define the model.
The Window-Knocking Machine TestHow will technology shape our world going forward? And what tools and products should we build? When imagining what the future could look like, it helps to look back in time and compare past visions to our reality today.
Happy 10th Birthday, spaCy!10 years ago today Matt pushed the first commit to spaCy. Since then, the library has evolved as the field moved forward, but also stayed true to its core mission: industrial-strength NLP.
How S&P Global is making markets more transparent with NLP, spaCy and ProdigyA case study on S&P Global’s efficient information extraction pipelines for real-time commodities trading insights in a high-security environment.
Simply Simplify LanguageInteractive app by the Canton of Zurich, Switzerland, using LLMs and spaCy to analyze and simplify institutional communication and make bureaucratic German more inclusive.
KI – Die künstlerische Intelligenz?Immergut Festival (German)Panelists are discussing the latest developments in Generative AI, hype vs. reality and what those new technologies mean for people, businesses, art, creativity and the music industry.
Economies of Scale Can’t Monopolise the AI RevolutionInfoQ MagazineDuring her presentation at QCon London, Ines Montani stated that economies of scale are not enough to create monopolies in the AI space and that open-source techniques and models will allow everybody to keep up with the “Gen AI revolution”.
Ines Montani on Natural Language ProcessingSoftware Engineering RadioInes speaks with host Jeremy Jung about solving problems using natural language processing. They cover generative vs. predictive tasks, creating a pipeline and breaking down problems, labeling examples for training, fine-tuning models, using LLMs to label data and build prototypes, and the spaCy NLP library.
Zero-Shot NER with GliNER and spaCy Python Tutorials for Digital HumanitiesTutorial by WJB Mattingly on how to integrate the generalist GLiNER model for Named Entity Recognition with spaCy's versatile NLP environment.
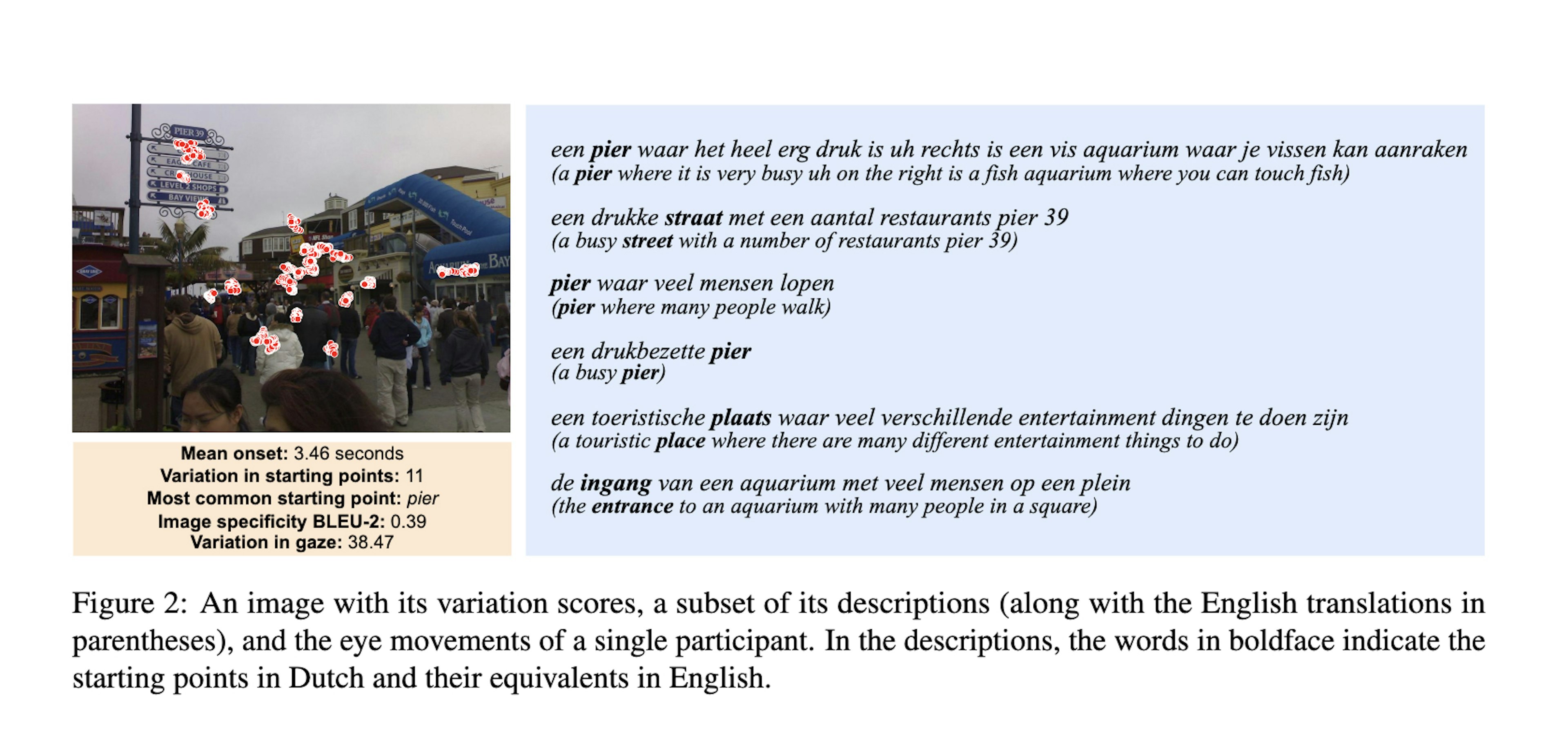
Describing Images Fast and Slow: Quantifying and Predicting the Variation in Human Signals during Visuo-Linguistic ProcessesTakmaz, Pezzelle, Fernández (2024)We use the spaCy library for tokenization, part-of-speech tagging, and lemmatization of the words in the descriptions.
Muted: Multilingual Targeted Offensive Speech Identification and VisualizationTillmann, Trivedi, Rosenthal, Borse, Zhang, Sil, Bhattacharjee (2023)Muted can leverage any transformer-based HAP-classification model [...] to identify toxic spans, without further fine-tuning. In addition, we use the spaCy library to identify the specific targets and arguments for the words predicted by the attention heatmaps.
On the Creation of Classifiers to Support Assessment of E-PortfoliosGantikow, Isking, Libbrecht, Müller, Rebholz (2023)In this workflow, Prodigy selects and presents text examples that were classified with a very low degree of certainty. The annotator reviews the proposed classifications and corrects them, if necessary.
Launching the Explosion Merch StoreSpread the love and support us and our open-source work with some of our unique, custom-designed swag. All orders come with free shipping and stickers!
The NLP and AI Revolution with the spaCy CreatorsVanishing GradientsIn this interview with Hugo Bowne-Anderson, we delve into the forefront of NLP and the future of AI development, covering topics like human-in-the-loop distillation, open-source AI and Explosion’s journey.
Toward Automatic Summarization of Hospital Discharge NotesLandes (2024)For NLP tasks, vectorizers include spaCy token features such as part of speech (POS) tags, named entity recognition (NER) tags, dependency head relations and depth.
The AI Revolution Will Not Be MonopolizedInfoQOpen-source initiatives are pivotal in democratizing AI technology, offering transparent, extensible tools that empower users. Daniel Dominguez summarizes the key takeaways from Ines’ recent talk for InfoQ.
Exploring the AI nexus with the mind behind spaCyLeading With Data PodcastIn this episode, Matt takes you on a deep dive into the future of data and the challenges facing current Large Language Models (LLMs).
Towards Structured Data: LLMs from Prototype to ProductionU.S. Census Bureau: Center for Optimization and Data Science SeminarThis talk presents pragmatic and practical approaches for how to use LLMs beyond just chat bots, how to ship more successful NLP projects from prototype to production and how to use the latest state-of-the-art models in real-world applications.
ZenML v0.58.0New out-of-the-box Prodigy integration in ZenML for LLMs and beyond, to make data development and annotation a core part of your MLOps lifecycle.
spaCyEx v0.0.2Extension for spaCy’s powerful, linguistically-aware pattern matching that introduces a RegEx-like syntax.
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMsQCon London
Constructing a knowledge base with spaCy and spacy-llmMantisNLP BlogThis blog post shows how to use spaCy and LLMs to extract entities and relationships from text and quickly tackle the complex problem of constructing a knowledge base graph from a corpus.
KAZU v1.5A biomedical NLP framework designed to handle production workloads, built by AstraZeneca and Korea University and using spaCy under the hood.
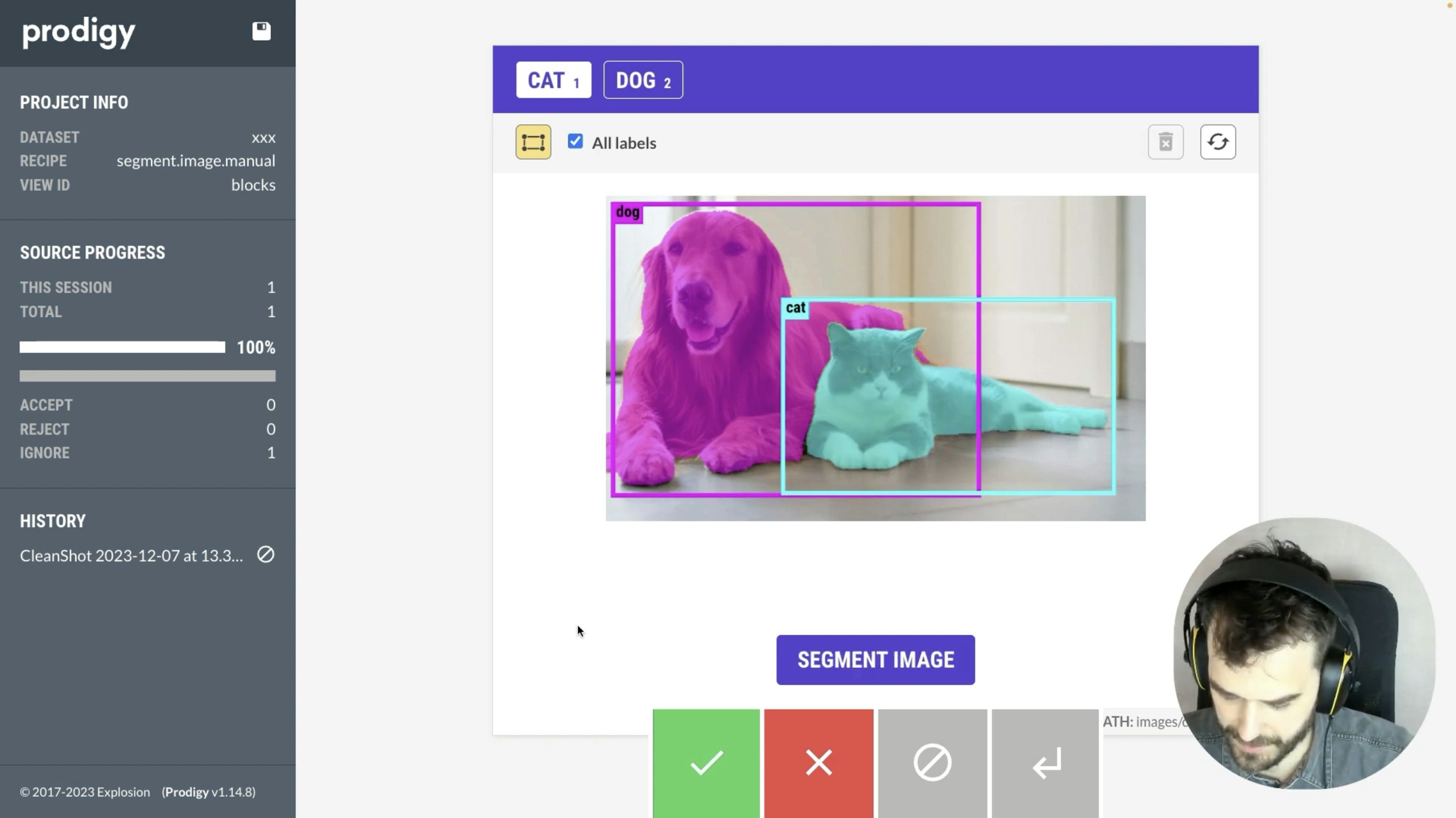
Prodigy-Segment for Pixel SegmentationUse Meta’s “Segment Anything” model in Prodigy to help you select the right pixels in images.
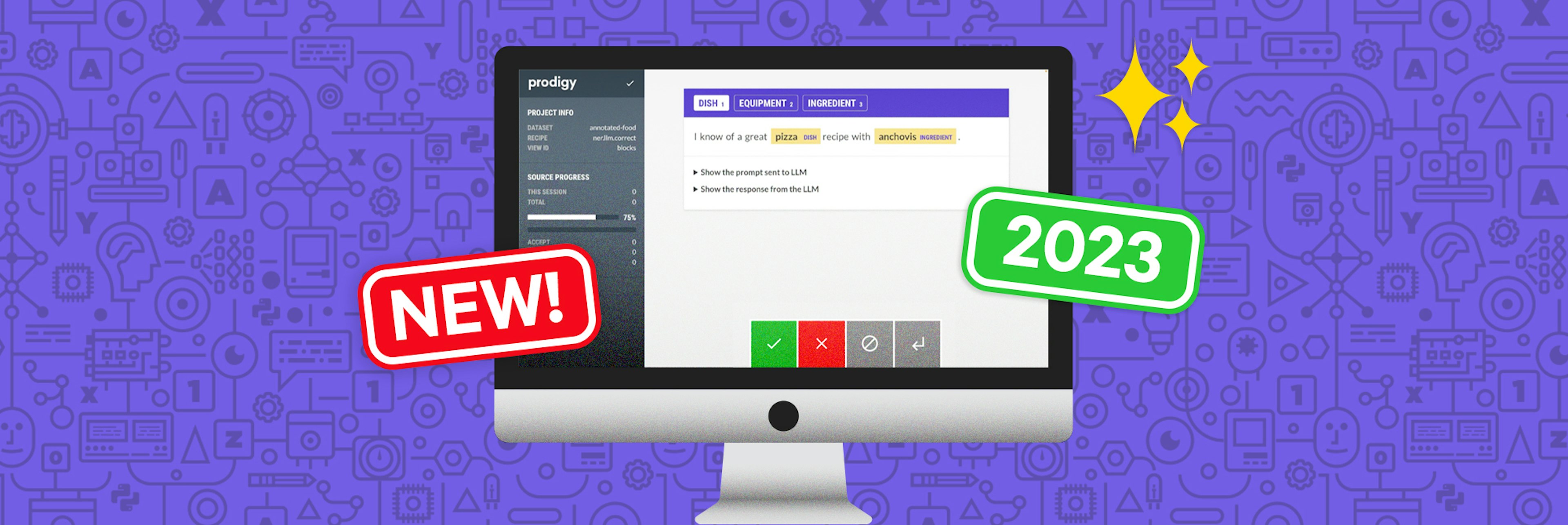
Prodigy in 2023: LLMs, task routers, QA and pluginsWe have made a ton of new updates in Prodigy this year with v1.12, v1.13, and v1.14 releases. So we decided to write a post about them.
Impoliteness and morality as instruments of destructive informal social control in online harassment targeting Swedish journalistsBjörkenfeldt, Gustafsson (2023)In the annotation tool Prodigy used for this process, the tweets directed towards journalists were displayed alongside the initial tweet that initiated the conversation thread and the subsequent reply from the journalist.